
Day 1 of 30 days of Data Engineering
With examples and projects…
Welcome back peeps! Hope all is going well. So, after receiving a great response ( and some really good feedback and inputs) for 60 days of Data Science and ML with projects series, I’m excited to share that I’m starting a new Series — 30 days of Data Engineering with (amazing) projects. PS: I’ll be writing as and when I’m free out of my busy work schedule.
What’s Covered in 30 days of Data Engineering with Projects Series till now —
Day 3 : Complete Advanced Python for Data Engineering — Part 2
Day 18 : Data Visualization basics, Data Visualization Projects, Data Visualization using Plotly and Bokeh, Data Profiling, Summary Functions, Indexing, Grouping, Linear Regression, Multi Linear Regression, Polynomial Regression, Regression, Support Vector Regression, Decision Tree Regression, Random Forest Regression, Feature Engineering, GroupBy Features, Categorical and Numerical Features, Missing Value Analysis, Fill the missing Values, Unique Value Analysis, Univariate Analysis, Bivariate Analysis, Multivariate Analysis, Correlation Analysis, Spearman’s ρ, Pearson’s r, Kendall’s τ, Cramér’s V (φc), Phik (φk)
Day 20 : ETL ( Extract, Tranform and Load) basics, Why ETL is important?, How ETL works, ETL Tools
Day 21 : Structured Data, Semi Structured Data, Unstructured Data, Data Warehouse, Data Mart, Data Lake
Day 25: Docker, Docker vs Virtual Machines, Most important Docker commands, Kubernetes, Snowflake
Day 26 : Data Pipelines, Transformation, Processing, Workflow, Monitoring, Airflow, DAG
Day 29 : Data Engineering on cloud, AWS, AWS Services, Google Cloud Platform, GCP services
Complete Data Structures and Algorithm Series
Github —
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Another series that I’m starting along with Data Engineering is Machine Learning Ops — 30 days of Machine Learning Ops
60 Days of Data Science and Machine Learning with projects Series —
The main aim of 30 days of Data Engineering with (amazing) projects series to understand Data Engineering from a practical perspective and get hands on practice by implementing projects (without falling in the rabbit hole of too much theory)
Solved System Design Case Studies
Design Instagram
Design Netflix
Design Reddit
Design Amazon
Design Messenger App
Design Twitter
Design URL Shortener
Design Dropbox
Design Youtube
Design API Rate Limiter
Design Web Crawler
Design Amazon Prime Video
Design Yelp
Design Uber
Design Tinder
Design Tiktok
Design Whatsapp
Most Popular System Design Questions
Mega Compilation : Solved System Design Case studies
Let’s get started!
I’l be covering only the most important topics in Data Engineering with projects ( written below) —
1. Data Engineering
2. Python for Data Engineering
3. SQL Basics
4. Aggregations
5. Window Functions
6. BigQuery
7. Advanced Functions
8. Performance Tuning SQL Queries
9. MySQL, PostgreSQL and MongoDB
10. Scripting and Automation
11. Relational Databases and SQL
12. NoSQL Data bases and Map Reduce
13.Data Analysis
14. Data Processing Techniques
15. Big Data
16. Data Pipelines and WorkFlows
17. Infrastructure
18. Power BI
19. Cloud Data Engineering
20. Machine Learning Algorithms
Let’s dive in!
Data Engineering
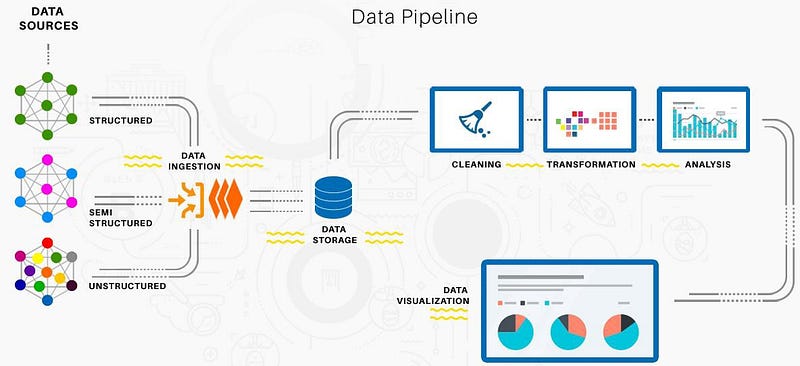
Data engineering is the process of preparing data for use in analysis, machine learning, and other applications. This includes tasks such as data ingestion, cleaning, and transformation, as well as building and maintaining the infrastructure and systems needed to store, process, and access the data.
The purpose of data engineering is to make sure that data is in a form that can be easily used and understood by other members of the data team, such as data scientists and machine learning engineers.
In simple words, Data Engineering is the heart of designing, building for collecting, storing, processing, and analyzing large amount of data at scale.
To put it straight, in data engineering we develop and maintain large scale data processing systems to prepare structured and unstructured data to perform analytical modeling and make data driven decisions.
The aim of data engineering is to make quality data available for analysis and efficient data-driven decision making.
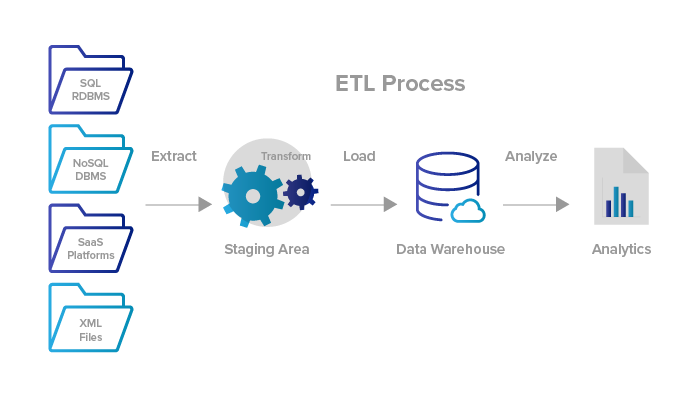
Most importantly, the Data Engineering ecosystem consists of 4 things —
Data — different data types, formats, and sources of data.
Data stores and repositories — Relational and non-relational databases, data warehouses, data marts, data lakes, and big data stores that store and process the data
Data Pipelines — Collect/Gather data from multiple sources, clean, process and transform it into data which can used for analysis,
Analytics and Data driven Decision Making — Make the well processed data available for further business analytics, visualization and data driven decision making.
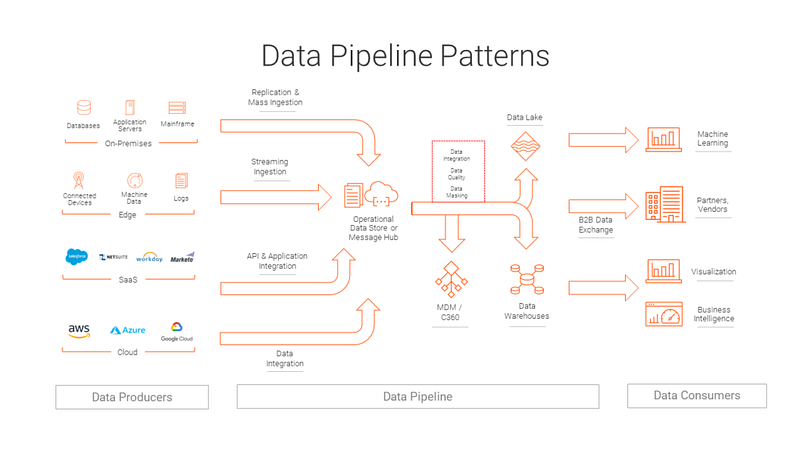
Why Data Engineering?
Data Engineering lifecycle consists of building/architecting data platforms, designing and implementing data stores and repositories, data lakes and gathering, importing, cleaning, pre-processing, querying, analyzing data, performance monitoring, evaluation, optimization and fine tuning the processes and systems.
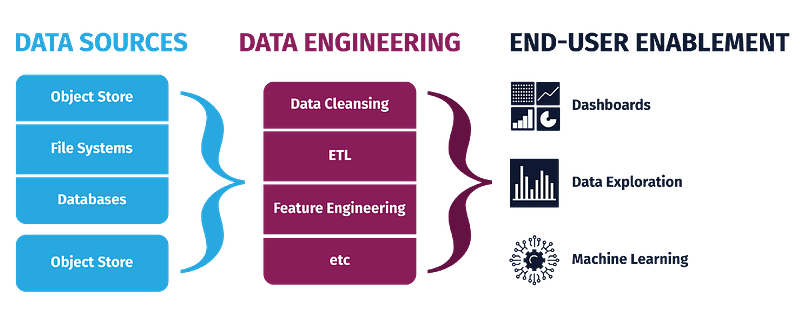
It gives a great edge —
1. To work and process with heterogeneous data formats and in the end get quality data that can be used in production.
2. To be able to work with large amount of data at scale and extract optimal value.
3. To automate the data pipelines and streams.
4. Use meta data efficiently.
5. To be able to derive amazing insights from the real time data ( quality data).
Data engineers play a crucial role in the field of data management and analytics. They are responsible for designing, building, and maintaining the infrastructure required for data acquisition, storage, processing, and delivery. This includes developing robust and scalable data pipelines, integrating and transforming data from various sources, and ensuring data quality and reliability.
To better understand the role of data engineers, let’s compare it with data science:
Data Engineering versus Data Science: Data engineering and data science are two distinct but interconnected fields within the broader realm of data analytics. While data science focuses on extracting insights and knowledge from data, data engineering is concerned with the technical aspects of managing and processing data. Here are some key differences between the two roles:
- Data Engineering: Data engineers primarily work on the infrastructure and data pipelines, ensuring the efficient collection, storage, and processing of data. They focus on building and maintaining the systems that enable data scientists and analysts to work with large volumes of data effectively. Data engineers typically have expertise in data modeling, ETL (Extract, Transform, Load) processes, database systems, and distributed computing.
- Data Science: Data scientists focus on analyzing and interpreting data to uncover patterns, trends, and insights that drive decision-making. They apply statistical and machine learning techniques to extract actionable knowledge from the data. Data scientists often use programming languages like Python or R, and they possess skills in statistical analysis, machine learning algorithms, data visualization, and domain knowledge.
Popular tools used in data engineering:
Apache Hadoop: Hadoop is an open-source framework that allows distributed processing of large datasets across clusters of computers. It consists of two main components: Hadoop Distributed File System (HDFS) for storing data and MapReduce for processing and analyzing data in parallel. Hadoop is widely used for big data processing and is supported by various tools and libraries in the Hadoop ecosystem.
import pydoop.hdfs as hdfs
# Read a file from HDFS
with hdfs.open("/path/to/file.txt") as file:
data = file.read()
print(data)Apache Spark: Spark is another open-source framework that provides an in-memory computing engine for big data processing. It supports various programming languages, including Python, and offers high-level APIs for distributed data processing and machine learning. Spark is known for its speed and scalability and is often used for real-time data streaming, batch processing, and iterative algorithms.
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
# Read a text file
lines = spark.read.text("file:///path/to/file.txt")
# Count the occurrences of each word
word_counts = lines.rdd.flatMap(lambda line: line.value.split()).countByValue()
# Print the word counts
for word, count in word_counts.items():
print(f"{word}: {count}")Apache Kafka: Kafka is a distributed streaming platform that provides a publish-subscribe messaging system for real-time data streaming. It allows data engineers to efficiently collect, process, and transmit large volumes of data between different systems or applications. Kafka is commonly used for building data pipelines, event-driven architectures, and real-time analytics.
from kafka import KafkaProducer, KafkaConsumer
# Create a Kafka producer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# Produce a message to a topic
producer.send('my_topic', b'Hello, Kafka!')
# Create a Kafka consumer
consumer = KafkaConsumer('my_topic', bootstrap_servers='localhost:9092')
# Consume messages from a topic
for message in consumer:
print(message.value.decode('utf-8'))Apache Airflow: Airflow is an open-source platform for orchestrating and scheduling data workflows. It allows data engineers to define, schedule, and monitor complex data pipelines as directed acyclic graphs (DAGs). Airflow supports various data sources and destinations, and it integrates well with other tools in the data engineering ecosystem.
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
# Define the DAG
dag = DAG(
'my_dag',
description='A simple DAG',
start_date=datetime(2023, 1, 1),
schedule_interval='@daily',
)
# Define the tasks
task1 = BashOperator(
task_id='task1',
bash_command='echo "Task 1"',
dag=dag,
)
task2 = BashOperator(
task_id='task2',
bash_command='echo "Task 2"',
dag=dag,
)
# Set task dependencies
task1 >> task2Complete Code —
import pydoop.hdfs as hdfs
from pyspark.sql import SparkSession
from kafka import KafkaProducer, KafkaConsumer
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
# Apache Hadoop - Reading a file from HDFS
def read_file_from_hdfs():
with hdfs.open("/path/to/file.txt") as file:
data = file.read()
print(data)
# Apache Spark - Word count example
def word_count_with_spark():
spark = SparkSession.builder.appName("WordCount").getOrCreate()
lines = spark.read.text("file:///path/to/file.txt")
word_counts = lines.rdd.flatMap(lambda line: line.value.split()).countByValue()
for word, count in word_counts.items():
print(f"{word}: {count}")
# Apache Kafka - Producing and consuming messages
def produce_and_consume_messages():
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my_topic', b'Hello, Kafka!')
consumer = KafkaConsumer('my_topic', bootstrap_servers='localhost:9092')
for message in consumer:
print(message.value.decode('utf-8'))
# Apache Airflow - Defining a DAG and tasks
def my_function():
print("Hello, Airflow!")
dag = DAG(
'data_engineering_pipeline',
description='Example data engineering pipeline',
schedule_interval='0 0 * * *', # Runs daily at midnight
start_date=datetime(2023, 5, 17),
catchup=False
)
read_file_task = PythonOperator(
task_id='read_file_from_hdfs',
python_callable=read_file_from_hdfs,
dag=dag
)
word_count_task = PythonOperator(
task_id='word_count_with_spark',
python_callable=word_count_with_spark,
dag=dag
)
produce_consume_task = PythonOperator(
task_id='produce_and_consume_messages',
python_callable=produce_and_consume_messages,
dag=dag
)
my_function_task = PythonOperator(
task_id='my_function_task',
python_callable=my_function,
dag=dag
)
read_file_task >> word_count_task >> produce_consume_task >> my_function_taskHow Data Engineers are different from ML Engineers and Data Scientists?
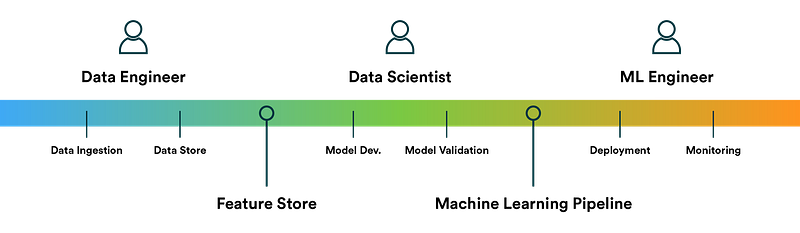
Data Engineers — To put it straight, data engineer is responsible for making quality data available from various resources, maintain databases, build data pipelines, query data, data preprocessing, Feature Engineering, Apache hadoop and spark, Develop data workflows using Airflow etc
Data Scientists and ML Engineers — On the other hand, ML Engineers and Data Scientists are responsible for building ML algorithms, building data and ML models and deploy them, have statistical and mathematical knowledge and measure, optimize and improve results.
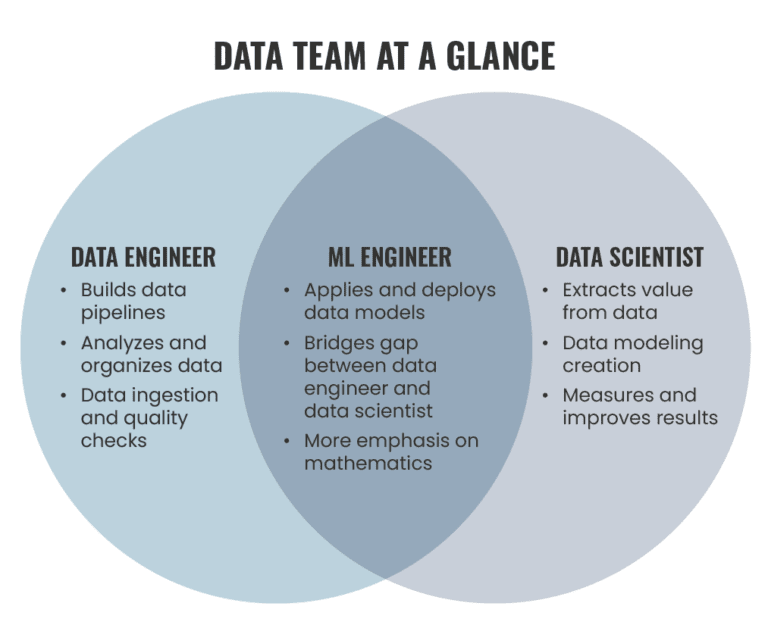
Data engineers and machine learning engineers are two distinct roles, although there is some overlap between the two. Data engineers are responsible for designing and building the infrastructure and systems that store and process data, while machine learning engineers are responsible for building and deploying machine learning models. Data scientists are responsible for analyzing and interpreting data to gain insights and make decisions.
Purpose, Scope and Responsibilities
The scope of data engineering includes a wide range of tasks, from data pipeline design and data warehousing to working with big data technologies such as Hadoop and Spark. Data engineers also work closely with data scientists and machine learning engineers to ensure that the data is in a form that can be easily used and understood by these other members of the data team.
Data Engineers are responsible for building the most efficient data infrastructure in order to process large amount of data coming from various sources.

The purpose and scope of 30 days of Data Engineering has already been discussed above.
To re-iterate, the goal of this series is to give practical hands-on exposure while covering bits and pieces of important theory concepts.
Join me in this journey!! :)
That’s it for now!
Day 2:
System Design Case Studies — In Depth
Design Instagram
Design Messenger App
Design Twitter
Design URL Shortener
Design Dropbox
Design Youtube
Design API Rate Limiter
Design Web Crawler
Design Facebook’s Newsfeed
Most Popular System Design Questions
Mega Compilation : Solved System Design Case studies
Complete Data Structures and Algorithm Series
Github —
Complete System Design Series Parts —
6. Networking, How Browsers work, Content Network Delivery ( CDN)
Github —
Keep learning and coding :)
Advanced SQL Series
Day 2 : SQL Basics, Query Structure, Built In functions Conditions
Day 4 : Set Theory Operations, Stored Procedures and CASE statements in SQL
Day 6 : Subqueries, Group by, order by and Having clauses in SQL and Analytical Functions
Day 7 : Window Functions, Grouping Sets and Constraints in SQL
Day 8 : BigQuery Basics, SELECT, FROM, WHERE and Date and Extract in BigQuery
Day 9 : Common Expression Table, UNNEST Clause, SQL vs NoSQL Databases
Day 10 : Triggers, Pivot and Cursors in SQL
Day 14 : MySQL in Depth
Day 15 : PostgreSQL inDepth
Anyways, For Day 15 of 15 days of Advanced SQL, we will cover —
PostgreSQL inDepth
Github for Advanced SQL that you can follow —
All the projects, data structures, algorithms, system design, Data Science and ML, Data Engineering, MLOps and Deep Learning videos will be published on our youtube channel ( just launched).
Subscribe today!
System Design Case Studies — In Depth
Complete Data Structures and Algorithm Series
Github —
30 days of Data Analytics Series —
Day 1 : Data Analytics basics and kickstart of Data analytics with projects series
Day 3 : Data Analytics Ecosystem — Data Life Cycle, Data Analysis complete process ( most important things)
Day 5 : Statistics
Day 6 : Basic and Advanced SQL
Day 8 : Pandas and Numpy
Day 9 : Data Manipulation
Day 10 : Data Visualization — Part 1
Day 11 : Project 1 : Data Visualization — Part 2
Day 12 : Data Visualization — Part 3
Day 13: Tableau — Part 1
Day 14: Tableau — Part 2
Day 15: Tableau — Part 3
Day 16 : Data Analysis Project 2
Day 17 : Data Analysis Project 3
Day 18: Data Analysis Project 4
Day 20 : Data Analysis Project 6
Day 21 : Data Analysis Project 7
Take Complete Hands On Tableau Course : Link
Some of the other best Series —
How to solve any System Design Question ( approach that you can take)?
30 days of Data Structures and Algorithms and System Design Simplified
Data Science and Machine Learning Research ( papers) Simplified **
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding! Some of the links are affiliates.
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras





