
Part 10— Complete System Design Series
System Design Made Easy…
Welcome back peeps. In the last part ( links below) we covered in detail ( with examples) —
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Solved System Design Case Studies — In depth
Design Instagram
Design Messenger App
Design Twitter
Design URL Shortener
Design Dropbox
Design Youtube
Design API Rate Limiter
Design Web Crawler
Design Facebook’s Newsfeed
Design Yelp
Design Uber
Design Tinder
Design Tiktok
Design Whatsapp
Most Popular System Design Questions
Mega Compilation : Solved System Design Case studies
All the Complete System Design Series Parts —
6. Networking, How Browsers work, Content Network Delivery ( CDN)
Moving forward, this is the part 10 of the system design series where we will be covering —
- Map Reduce
- Patterns and Microservices
Part 1 of this series can be found here —
Part 2 of this series can be found here —
Part 3 of this series can be found here —
Part 4 of this series can be found here —
Part 5 of this series can be found here —
Part 6 of this series can be found here —
Part 7 of this series can be found here —
Part 8 of this series can be found here —
Part 9 of this series can be found here —
And Most popular System Design Questions —
Let’s dive in!
Note : Please read System Design Important Terms you MUST know before reading this post.
Map Reduce
Pasta Resto Case:
So as the next step, you as an owner decided to take bulk orders for your pasta resto. As soon as the bulk order comes you as a master, map the orders to different chefs ( slaves) who then cook the assigned order to them. As soon as all the orders are cooked, you assemble all the items and pack them together and give it to the delivery guy. This way you are able to do distributed cooking which helps in parallel processing of the task on hand.
System Design Analogy:
Taking the same analogy, In system design map reduce ( hadoop systems) is a batch processing technique in which the engine takes huge amounts of data, processes ( map and reduce) and gives the output.
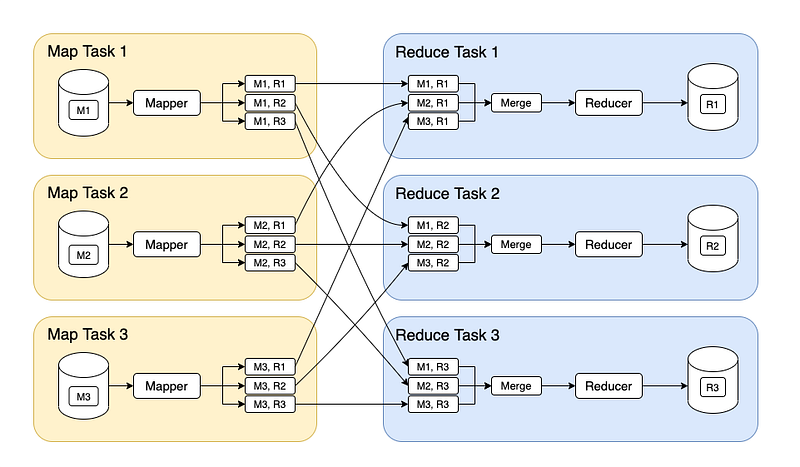
There are 2 stages of Map Reduce —
Map — the mapper takes the input, divides it into different tiny jobs and processes it as key-value pair( i.e the input data is stored in HDFS and given to the mapper)
Reduce, Shuffle and Sort — the reducer takes the data from mapper and processes the results which can be stored in HDFS. The combined or aggregated key-value pairs are shuffled, sorted and grouped together and sent as the output
Apart from this, to track the progress of each job — task tracker and job tracker are used. Job tracker manages all the resources and jobs and schedules across the cluster. The task tracker are called slaves that work on the directives of job trackers and deployed on each node in the cluster.
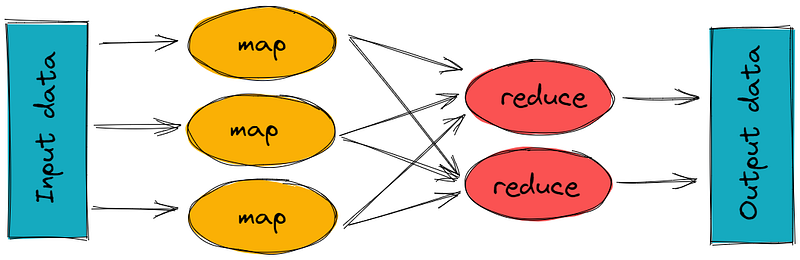
The MapReduce programming model consists of two main functions: the map function and the reduce function. The map function takes an input pair (key, value) and produces a set of intermediate key-value pairs. The reduce function takes an intermediate key and a set of values and combines them to produce a final output.
The MapReduce algorithm is typically executed in two stages: the Map stage and the Reduce stage.
- The Map stage: In this stage, the input data is divided into small chunks and distributed to multiple nodes in the cluster. The map function is then applied to each chunk of data in parallel by each node, resulting in a set of intermediate key-value pairs.
- The Reduce stage: In this stage, the intermediate key-value pairs are grouped by key and sent to the reduce function, which is applied to each group of values in parallel by the nodes. The reduce function produces a final output that is written to the output file.
The key feature of MapReduce is that it automatically handles the partitioning of data, the scheduling of tasks, and the handling of failures. The user only needs to specify the map and reduce functions.
It consists of two operations: Map and Reduce. The Map operation takes a dataset as input and applies a function to each item in the dataset, producing a new dataset. The Reduce operation takes the output of the Map operation and aggregates the data into a single result.
Here’s an example of a simple implementation of the MapReduce pattern in Python:
def map_func(item):
# Apply the map function to each item in the dataset
return item * 2def reduce_func(item1, item2):
# Apply the reduce function to the results of the map function
return item1 + item2def map_reduce(dataset):
# Apply the map function to the dataset
mapped = map(map_func, dataset)
# Apply the reduce function to the results of the map function
reduced = reduce(reduce_func, mapped)
return reduced# Example dataset
dataset = [1, 2, 3, 4, 5]# Apply the map reduce function to the dataset
result = map_reduce(dataset)
print(result) # Output: 30MapReduce is commonly used for processing large data sets, such as log files and scientific data, and for distributed data processing tasks like full-text indexing, data mining and machine learning.
In summary, MapReduce is a programming model and an associated implementation for processing and generating large data sets in a parallel and distributed way. It consist in two main functions the map and the reduce, the map function takes an input pair and produces a set of intermediate key-value pairs, while the reduce function takes an intermediate key and a set of values and combines them to produce a final output. MapReduce is commonly used for processing large data sets and distributed data processing tasks.
Why Map Reduce?
Helps in scalability
Helps in processing large amount of data in short amount of time
Helps is parallel processing
Extremely cost effective
Faster execution ( for both unstructured and semi-structured data)
Improves resilience and availability
Examples — Amazon’s Elastic Map Reduce and GCP’s Cloud Dataproc
Patterns and Microservices
Pasta Resto Case:
In your pasta resto, in order to make processes efficient you thought of implementing a microservices architecture — divide the whole resto in smaller sub-systems and these sub-systems can communicate with each other and share the resources. This helps in synchronizing the multiple processes efficiently.
System Design Analogy:
On the same lines, In system design microservices architecture is used to build enterprise level applications which helps in structuring the whole application as a collection of tiny autonomous, self contained services for each task ( service) that you want/are allowed to perform.
Microservices patterns are common solutions to the challenges that arise when building and deploying microservices. These patterns provide a way to build and organize microservices in a consistent and maintainable way.
Here are some common microservices patterns:
- Service Discovery: Allows services to discover each other at runtime and removes the need to hardcode service locations.
- API Gateway: A single entry point for all client requests, which routes requests to the appropriate service and abstracts the underlying microservices architecture from the client.
- Circuit Breaker: Helps prevent cascading failures in a distributed system by providing a way to stop a service from making further requests to a failed service.
- Service Proxy: Allows services to communicate with each other without having to know the location of the service.
- Service Chaining: Allows multiple services to be combined to form a single service, which is useful for building complex workflows.
- Bounded Context: A way to organize related microservices into a single business domain, which helps to reduce complexity and improve maintainability.
- Event-Driven Architecture: Allows services to communicate with each other by sending and receiving events, which decouples services from each other and makes them more resilient to change.
Each service is responsible for a specific business capability and communicates with other services through APIs. This allows for greater scalability, resiliency, and easier maintenance of the system.
Here’s an example of how you could implement a simple microservices architecture in Python:
# User service
def create_user(user_data):
# Create a new user
passdef get_user(user_id):
# Get user data
pass# Order service
def create_order(order_data):
# Create a new order
passdef get_order(order_id):
# Get order data
pass# API Gateway
def handle_request(request):
# Route the request to the appropriate service
if request['endpoint'] == 'users':
if request['method'] == 'POST':
return create_user(request['data'])
elif request['method'] == 'GET':
return get_user(request['data']['user_id'])
elif request['endpoint'] == 'orders':
if request['method'] == 'POST':
return create_order(request['data'])
elif request['method'] == 'GET':
return get_order(request['data']['order_id'])# Example request
request = {
'endpoint': 'users',
'method': 'POST',
'data': {'username': 'johndoe', 'email': '[email protected]'}
}# Handle the request
result = handle_request(request)In summary, Microservices architecture is a way of building and structuring software applications as a collection of small, independently deployable services that communicate with each other through APIs. Microservices patterns are common solutions to the challenges that arise when building and deploying microservices, these patterns provide a way to build and organize microservices in a consistent and maintainable way, Examples of microservices patterns are Service Discovery, API Gateway, Circuit Breaker, Service Proxy, Service Chaining, Bounded Context and Event-Driven Architecture.
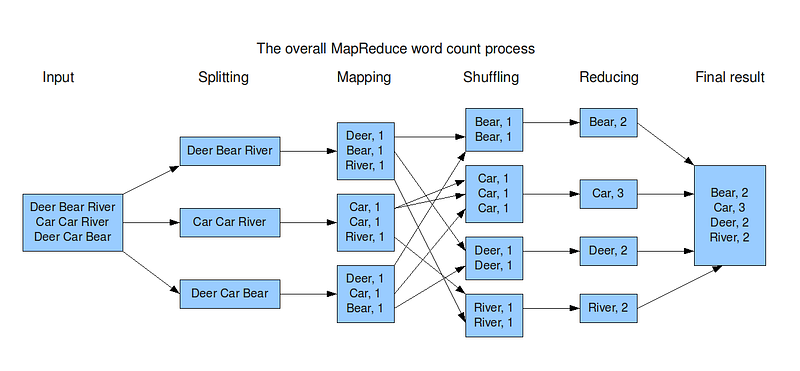
Implementation of word count in MapReduce using Python:
from mrjob.job import MRJob
import reclass MRWordCount(MRJob):def mapper(self, _, line):
words = re.findall(r'\w+', line)
for word in words:
yield word.lower(), 1def reducer(self, word, counts):
yield word, sum(counts)if __name__ == '__main__':
MRWordCount.run()In this implementation, the mapper function takes a line of text as input, splits it into individual words using a regular expression, and emits a key-value pair for each word with a count of 1. The reducer function receives these key-value pairs and sums the counts for each word, emitting the final count for each word.
Implementation of a simple microservice using Python:
from flask import Flask, jsonifyapp = Flask(__name__)@app.route('/hello')
def hello():
return jsonify({'message': 'Hello, world!'})if __name__ == '__main__':
app.run()In this implementation, we define a single route /hello that returns a JSON response with a "message" field containing the text "Hello, world!". The application is launched using the Flask web framework's built-in development server by calling app.run().
More on Map Reduce and Patterns in Microservices —
MapReduce:
MapReduce is a programming model and framework used for processing large-scale data sets in a distributed and parallel manner. It was introduced by Google and is designed to simplify the development of distributed data processing applications. The key benefits of MapReduce include scalability, fault tolerance, and the ability to process large amounts of data efficiently.
MapReduce Workflow: The MapReduce workflow consists of several sequential steps:
Input data is divided into chunks and distributed across multiple nodes in a cluster.
The mapper function is applied to each chunk independently, transforming the input data into intermediate key-value pairs.
The intermediate key-value pairs are shuffled and sorted based on the keys.
The reducer function is applied to groups of intermediate key-value pairs with the same key, producing the final output.
Data Partitioning: Data partitioning is the process of dividing data across multiple nodes in a distributed system for parallel processing in MapReduce. Common techniques for data partitioning include range-based partitioning, hash partitioning, and round-robin partitioning. These techniques ensure that data is evenly distributed among nodes, allowing for efficient parallel processing.
Mapper Function: The mapper function in MapReduce is responsible for transforming the input data into intermediate key-value pairs. It processes a subset of the input data independently on each node and emits key-value pairs based on the required transformation. The output of the mapper function becomes the input for the shuffling and sorting phase.
Shuffling and Sorting: Shuffling and sorting is the process of organizing the intermediate key-value pairs generated by the mappers. The intermediate pairs are grouped based on their keys and sorted to prepare them for the reducer function. This step ensures that all pairs with the same key are sent to the same reducer node.
Reducer Function: The reducer function in MapReduce aggregates and summarizes the intermediate key-value pairs produced by the mappers. It processes a group of pairs with the same key and produces the final output. The reducer function performs tasks such as counting, summing, averaging, or any other computation required on the grouped data.
Fault Tolerance and Resilience: MapReduce provides built-in fault tolerance mechanisms to handle node failures in a distributed system. It ensures that if a node fails during the execution, the framework automatically reassigns the failed tasks to other available nodes. This fault tolerance mechanism ensures the reliability and resilience of MapReduce jobs.
Use Cases and Applications: MapReduce is widely used for large-scale data processing tasks, including batch processing, log analysis, data transformation, and extraction. It is used in applications such as data analytics, search engines, recommendation systems, and distributed data processing frameworks like Apache Hadoop and Apache Spark.
Patterns in Microservices:
Introduction to Microservices: Microservices is an architectural style where an application is built as a collection of small, loosely coupled services that are independently deployable and scalable. The key principles of microservices include bounded contexts, single responsibility, autonomy, and decentralized governance. Microservices offer benefits like agility, scalability, and maintainability.
Domain-Driven Design: Domain-Driven Design (DDD) is an approach to software development that focuses on understanding the business domain and using that understanding to design software systems. In the context of microservices, DDD helps identify microservices boundaries by defining bounded contexts, which are specific areas of the business domain that can be encapsulated within individual microservices.
Service Decomposition Patterns: Service decomposition patterns provide strategies for breaking down a monolithic application into microservices. The Strangler Fig pattern involves gradually replacing parts of a monolithic application with microservices. Decompose by Business Capability focuses on identifying business capabilities and creating microservices around them. The Anti-Corruption Layer pattern isolates a microservice from legacy systems by translating between the microservice’s interface and the legacy system’s interface.
Communication Patterns: In microservices architecture, various communication patterns and protocols are used to enable interaction between services. Synchronous RESTful APIs are commonly used for request-response communication. Asynchronous messaging with message queues, such as RabbitMQ or Apache Kafka, is used for event-driven communication. Event-driven architectures leverage event sourcing and event-driven integration patterns to enable loose coupling and scalability.
Data Management Patterns: Managing data in a microservices environment requires careful consideration. The Database per Service pattern suggests that each microservice has its dedicated database, ensuring loose coupling and independent data management. The Saga pattern helps maintain data consistency in distributed transactions by using a series of compensating actions. Command Query Responsibility Segregation (CQRS) pattern separates read and write operations, optimizing data access and scalability.
Service Discovery and Routing: Service discovery is crucial in a dynamic microservices environment where services can come and go. The Service Registry pattern uses a central registry or service mesh to register and discover services. The API Gateway pattern provides a single entry point for clients to access multiple microservices and performs routing, authentication, and rate limiting.
Resilience and Fault Tolerance Patterns: Microservices need to handle failures and maintain resilience. The Circuit Breaker pattern helps prevent cascading failures by automatically failing fast and providing fallback mechanisms. The Bulkhead pattern isolates failures in one microservice from affecting others by using separate thread pools or process pools. The Retry pattern allows for automatic retries of failed requests to handle transient failures.
Deployment Patterns: Microservices can be deployed using different patterns. Containerization with technologies like Docker allows for packaging microservices and their dependencies into portable containers. Orchestration tools like Kubernetes provide automated management and scaling of containerized microservices. Deployment patterns like Blue-Green Deployment and Canary Release facilitate rolling out new versions of microservices with minimal downtime.
Observability and Monitoring: Observability is essential for understanding the behavior and performance of microservices. Distributed tracing, using tools like Jaeger or Zipkin, provides visibility into the flow of requests across microservices. Log aggregation tools like ELK Stack (Elasticsearch, Logstash, and Kibana) help consolidate logs for analysis. Metrics collection tools like Prometheus allow monitoring key performance indicators of microservices.
Security Patterns: Security is a critical concern in microservices architecture. Authentication and authorization mechanisms, such as OAuth 2.0 or JSON Web Tokens (JWT), are used to secure communication between microservices and clients. Secure communication can be achieved through Transport Layer Security (TLS) encryption. Data encryption techniques, like encryption at rest and in transit, ensure data protection.
Scaling and Load Balancing: Microservices can be independently scaled based on their specific demands. Horizontal scaling, adding more instances of a microservice, helps handle increased load. Load balancing techniques, such as round-robin or least-connections, distribute requests across multiple instances of a microservice to optimize resource utilization.
Testing Strategies: Microservices require comprehensive testing strategies. Unit testing ensures individual microservices function correctly in isolation. Integration testing verifies the interaction and compatibility between microservices. Contract testing validates the contracts between services to ensure they work together as expected. Chaos engineering tests the resilience of microservices by injecting failures and monitoring their impact.
// CircuitBreakerService.java
@Service
public class CircuitBreakerService {
@Autowired
private RestTemplate restTemplate;
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String callRemoteService() {
String url = "http://remote-service/api/endpoint";
return restTemplate.getForObject(url, String.class);
}
public String fallbackMethod() {
return "Fallback response";
}
}// MainService.java
@RestController
public class MainService {
@Autowired
private CircuitBreakerService circuitBreakerService;
@GetMapping("/main")
public String mainEndpoint() {
try {
return circuitBreakerService.callRemoteService();
} catch (HystrixRuntimeException e) {
return "Fallback response";
}
}
}Advanced SQL Series
Day 2 : SQL Basics, Query Structure, Built In functions Conditions
Day 4 : Set Theory Operations, Stored Procedures and CASE statements in SQL
Day 6 : Subqueries, Group by, order by and Having clauses in SQL and Analytical Functions
Day 7 : Window Functions, Grouping Sets and Constraints in SQL
Day 8 : BigQuery Basics, SELECT, FROM, WHERE and Date and Extract in BigQuery
Day 9 : Common Expression Table, UNNEST Clause, SQL vs NoSQL Databases
Day 10 : Triggers, Pivot and Cursors in SQL
Day 14 : MySQL in Depth
Day 15 : PostgreSQL inDepth
Anyways, For Day 15 of 15 days of Advanced SQL, we will cover —
PostgreSQL inDepth
Github for Advanced SQL that you can follow —
All the projects, data structures, algorithms, system design, Data Science and ML, Data Engineering, MLOps and Deep Learning videos will be published on our youtube channel ( just launched).
Subscribe today!
System Design Case Studies — In Depth
Complete Data Structures and Algorithm Series
Github —
Some of the other best Series —
30 days of Data Structures and Algorithms and System Design Simplified
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Microservices are very useful since they help achieve —
- Better scalability
- Distributed and decentralization of the application
- Continuous Integration and Delivery ( CI/CD)
- Auto provisioning the resources as per the requirements
- Improved testability, deployability and maintainability
- More faster, productive and speeds up the deployments
- Autonomy and independent process flow
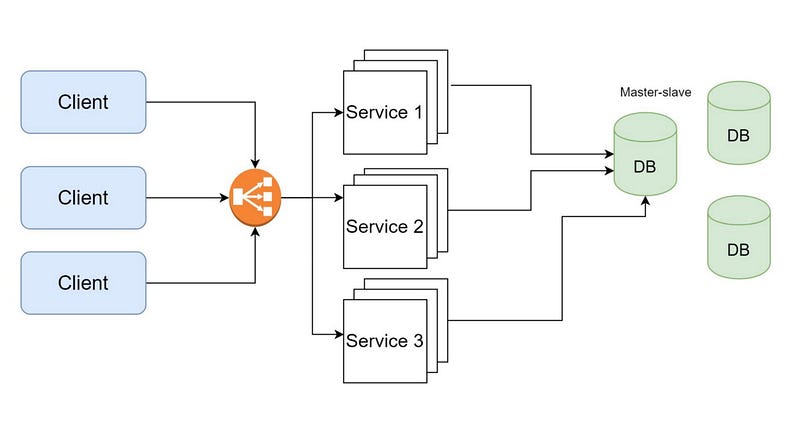
Microservices have design patterns like API gateway pattern, branch pattern, db pattern, Async Messaging pattern, Decomposition pattern etc — we will cover this in the later posts as we work around some examples wrt the large systems.
That’s it for now!
Part 11 of Complete System Design Series
Keep learning and coding :)
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding!
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras





