
Day 13 of 15 Days of Advanced SQL Series

Welcome back peeps. Hope all’s well.
Day 2 : SQL Basics, Query Structure, Built In functions Conditions
Day 4 : Set Theory Operations, Stored Procedures and CASE statements in SQL
Day 6 : Subqueries, Group by, order by and Having clauses in SQL and Analytical Functions
Day 7 : Window Functions, Grouping Sets and Constraints in SQL
Day 8 : BigQuery Basics, SELECT, FROM, WHERE and Date and Extract in BigQuery
Day 9 : Common Expression Table, UNNEST Clause, SQL vs NoSQL Databases
Day 10 : Triggers, Pivot and Cursors in SQL
Day 14 : MySQL in Depth
Day 15 : PostgreSQL inDepth
Anyways, For Day 13 of 15 days of Advanced SQL, we will cover —
Github for Advanced SQL that you can follow —
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
System Design Case Studies — In Depth
Complete Data Structures and Algorithm Series
Github —
Let’s get started with Day 13.
- MySQL is an open-source relational database management system (RDBMS) that is widely used in web applications and other software that require a reliable, high-performance data storage. It is known for its ease of use and low cost, and it supports a wide range of programming languages and platforms.
- PostgreSQL is an open-source relational database management system (RDBMS) that is known for its robustness, scalability, and compliance with SQL standards. It is often used in high-traffic web applications, data warehousing, and other mission-critical tasks.
- MongoDB is an open-source, document-oriented NoSQL database management system that is designed for scalability and high performance. It uses a JSON-like document data model, which allows for more flexible and dynamic data schema. MongoDB is often used in big data, real-time analytics, and other applications that require high read and write throughput.
- MySQL and PostgreSQL are both relational databases and use SQL as their primary language. Both are widely used and have a large community of users and developers. MySQL is generally considered to be more lightweight and easy to use, while PostgreSQL is known for its robustness, compliance with SQL standards and scalability. MongoDB is a NoSQL database and it uses document-based data model and it’s more flexible and dynamic compared to relational databases. MongoDB is more suitable for big data, real-time analytics and other applications that require high read and write throughput.
- SQL databases, also known as relational databases, are based on the relational model and use structured query language (SQL) to manage and manipulate data. They store data in tables with defined schema, and relationships between data are defined by foreign keys. Examples of SQL databases include MySQL, PostgreSQL, and Microsoft SQL Server.
- NoSQL databases, on the other hand, are non-relational and do not use SQL as their primary language. They are designed to handle large amounts of unstructured or semi-structured data, and are often more flexible and scalable than SQL databases. Examples of NoSQL databases include MongoDB, Cassandra, and Redis.
Introduction to MySQL

MySQL is the most popular open source DBMS which is extremely scalable, reliable, fast and easy to use. It’s system is client-server system which mainly consists of multithreaded SQL server and multiple clients.
MySQL databases are relational which means the the data is organized in the form of tables, rows, columns and views and rules are established for the relationships between the different tables, data fields — such as one to one, one to many, many to one and many to many.
It has a unique architecture and gives developers great productivity for using Triggers, Stored procedures and Views.
Some of the other advantages of using MySQL is — replication, high availability, high performance, easy deployment, security and scalability.
Some important functions —
COUNT(): The COUNT() function is used to count the number of rows returned by a query or the number of occurrences of a specific value in a column.
-- Count the number of rows in a table
SELECT COUNT(*) FROM your_table;-- Count the number of occurrences of a specific value in a column
SELECT COUNT(column_name) FROM your_table WHERE column_name = 'value';SUM(): The SUM() function is used to calculate the sum of values in a column.
-- Calculate the sum of values in a column
SELECT SUM(column_name) FROM your_table;AVG(): The AVG() function is used to calculate the average value of a column.
-- Calculate the average value of a column
SELECT AVG(column_name) FROM your_table;MIN(): The MIN() function is used to find the minimum value in a column.
-- Find the minimum value in a column
SELECT MIN(column_name) FROM your_table;MAX(): The MAX() function is used to find the maximum value in a column.
-- Find the maximum value in a column
SELECT MAX(column_name) FROM your_table;CONCAT(): The CONCAT() function is used to concatenate two or more strings together.
-- Concatenate two columns together
SELECT CONCAT(column1, column2) FROM your_table;GROUP_CONCAT(): The GROUP_CONCAT() function is used to concatenate values from multiple rows into a single string, grouped by a specific column.
-- Concatenate values from multiple rows into a single string
SELECT column1, GROUP_CONCAT(column2) FROM your_table GROUP BY column1;DATE_FORMAT(): The DATE_FORMAT() function is used to format dates or timestamps according to a specific format.
-- Format a date column as "YYYY-MM-DD"
SELECT DATE_FORMAT(date_column, '%Y-%m-%d') FROM your_table;IFNULL(): The IFNULL() function is used to replace NULL values with a specified value.
-- Replace NULL values with a default value
SELECT IFNULL(column_name, 'N/A') FROM your_table;CASE statement: The CASE statement is used to perform conditional logic within a query and return different values based on specified conditions.
-- Perform conditional logic using CASE statement
SELECT column_name,
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
ELSE result3
END AS calculated_column
FROM your_table;ROW_NUMBER(): The ROW_NUMBER() function is used to assign a unique sequential number to each row in the result set, based on the specified ordering.
-- Assign a sequential number to each row
SELECT ROW_NUMBER() OVER (ORDER BY column_name) AS row_number, column_name FROM your_table;I’ll be covering MySQL in detail on Day 14 of 15 days of Advanced SQL.
Introduction to PostgreSQL

Started out as a project in 1986, PostgreSQL is a relational DBMS which is open source and has many features such as — Multi version concurrency, point in time recovery, async replication, SQL sub selects, Views, Transaction, Trigger, Complex SQL queries etc.
It stores the data securely and supports the best practices. It helps developers build fault tolerant applications and protect data integrity.
It has many popular use cases such as — Geospatial database, Federated hub database, LAPP open source stack and General purpose OLTP database.
CONCAT(): The CONCAT() function is used to concatenate two or more strings together.
-- Concatenate two strings
SELECT CONCAT('Hello', 'World') AS result;EXTRACT(): The EXTRACT() function is used to extract a specific part of a date or timestamp, such as year, month, day, hour, etc.
-- Extract the year from a date column
SELECT EXTRACT(YEAR FROM date_column) AS year FROM your_table;COALESCE(): The COALESCE() function is used to return the first non-null value from a set of values.
-- Return the first non-null value from multiple columns
SELECT COALESCE(column1, column2, column3) AS result FROM your_table;DATE_TRUNC(): The DATE_TRUNC() function is used to truncate a date or timestamp to a specified precision, such as year, month, day, etc.
-- Truncate a date column to the month precision
SELECT DATE_TRUNC('month', date_column) AS truncated_date FROM your_table;STRING_AGG(): The STRING_AGG() function is used to concatenate values from multiple rows into a single string, with a specified delimiter.
-- Concatenate values from multiple rows into a single string with a comma delimiter
SELECT STRING_AGG(column_name, ', ') AS concatenated_values FROM your_table;JSONB Functions: PostgreSQL provides a rich set of functions for working with JSONB data type, which allows storing and querying JSON documents.
-- Extract value from JSON document
SELECT jsonb_extract_path('{"name": "John", "age": 30}', 'name'); -- Check if JSON document contains a specific key
SELECT '{"name": "John", "age": 30}'::jsonb ? 'age'; -- Modify JSON document by adding or updating a key-value pair
SELECT jsonb_set('{"name": "John"}', '{age}', '30'::jsonb, true);Window Functions: Window functions perform calculations across a set of rows that are related to the current row. They allow you to perform complex aggregations and calculations without the need for subqueries or joins.
-- Calculate the average salary for each department, along with the total and rank
SELECT department, AVG(salary) OVER (PARTITION BY department) AS avg_salary,
SUM(salary) OVER (PARTITION BY department) AS total_salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM employees;Common Table Expressions (CTEs): CTEs are temporary result sets that can be used within a query. They allow you to break down complex queries into more manageable and readable parts.
-- Use CTE to calculate the total sales for each product category
WITH category_sales AS (
SELECT category, SUM(sales) AS total_sales
FROM sales
GROUP BY category
)
SELECT category, total_sales
FROM category_sales
ORDER BY total_sales DESC;Full-Text Search Functions: PostgreSQL provides full-text search capabilities, allowing you to perform advanced text search operations.
-- Search for documents containing specific keywords
SELECT *
FROM documents
WHERE to_tsvector('english', content) @@ to_tsquery('english', 'search keywords');I’ll be covering PostgreSQL in detail on Day 15 of 15 days of Advanced SQL.
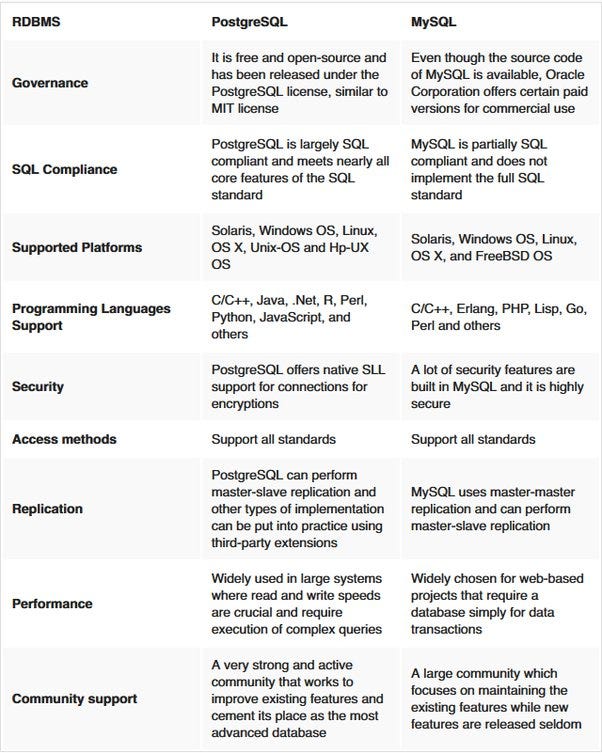
Comparison between MySQL and PostgreSQL —
Introduction to MongoDB

MongoDB is a no SQL, document database which is written in C++. It stores the data in the JSON format and works best for the unstructured data.
It is used when you need high availability of data with automatic, fast and instant data recovery. Also, in those situations when you have an unstable schema and you want to reduce the schema migration cost.
It stores unstructured data and run complex queries on both cloud and onsite deployments.
It has robust documentation and community support and supports built in replication, auto elections and sharding.
Its use cases include real time analytics, IOT, mobile apps data.
Find: The find function is used to query documents in a collection based on specified criteria.
// Find documents in the "users" collection where the age is greater than 25
db.users.find({ age: { $gt: 25 } });InsertOne: The insertOne function is used to insert a single document into a collection.
// Insert a new document into the "users" collection
db.users.insertOne({ name: "John", age: 30 });UpdateOne: The updateOne function is used to update a single document in a collection.
// Update the document with name "John" in the "users" collection, set age to 35
db.users.updateOne({ name: "John" }, { $set: { age: 35 } });DeleteOne: The deleteOne function is used to delete a single document from a collection.
// Delete the document with name "John" from the "users" collection
db.users.deleteOne({ name: "John" });Aggregate: The aggregate function is used to perform advanced aggregation operations on a collection, such as grouping, sorting, and calculating aggregate values.
// Calculate the average age of users in the "users" collection
db.users.aggregate([
{ $group: { _id: null, avgAge: { $avg: "$age" } } }
]);$lookup: The $lookup function is used for performing a left outer join between two collections and retrieving matched documents from the joined collection.
// Perform a left outer join between "orders" and "customers" collections
db.orders.aggregate([
{
$lookup: {
from: "customers",
localField: "customerId",
foreignField: "_id",
as: "customer"
}
}
]);$group: The $group function is used for grouping documents based on specified criteria and performing aggregate operations on grouped data.
// Group documents in the "orders" collection by customerId and calculate the total amount for each customer
db.orders.aggregate([
{
$group: {
_id: "$customerId",
totalAmount: { $sum: "$amount" }
}
}
]);$unwind: The $unwind function is used to deconstruct an array field and generate a new document for each element of the array.
// Unwind the "tags" array field in the "articles" collection
db.articles.aggregate([
{ $unwind: "$tags" }
]);$push: The $push function is used to add a value to an array field in a document.
// Add a new tag to the "tags" array field in the document with _id "12345" in the "articles" collection
db.articles.updateOne(
{ _id: "12345" },
{ $push: { tags: "newtag" } }
);$regex: The $regex function is used for performing regular expression-based pattern matching in queries .
// Find documents in the "users" collection where the name starts with "J"
db.users.find({ name: { $regex: "^J" } });I’ll be covering Mongodb in detail as the bonus post of 15 days of Advanced SQL.
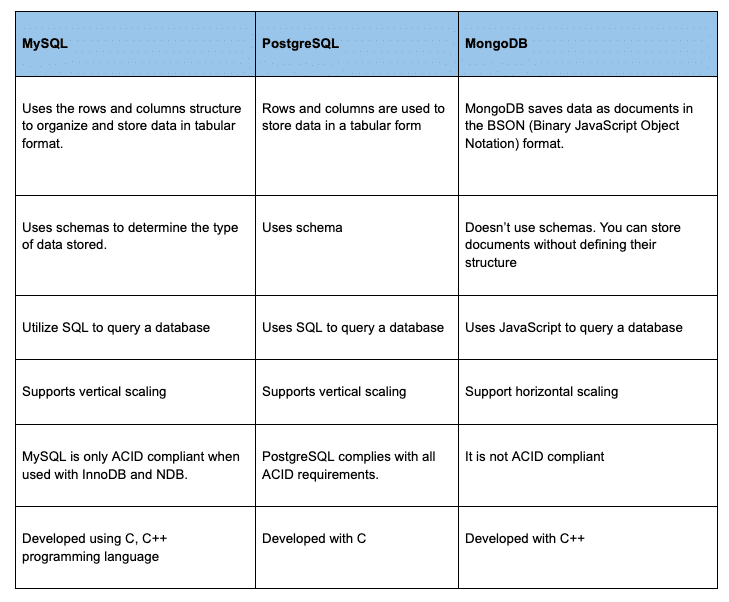
Comparison between MongoDB, PostgreSQL and MySQL —
Introduction to SQL and NoSQL Databases
SQL
As you design large systems ( or even smaller ones), you need to decide the inflow-processing and outflow of data coming- and getting processed in the system.
Data is generally organized in tables as rows and columns where columns represents attributes and rows represent records and keys have logical relationships. The SQL db schema always shows relational, tabular data following the ACID properties.
There are two types of databases to consider — SQL and NoSQL databases.
SQL databases have predefined schema and the data is organized/displayed in the form of tables. These databases use SQL ( Structured Query Language) to define, manipulate, update the data.
Relational databases like MS SQL Server, PostgreSQL, Sybase, MySQL Database, Oracle, etc. use SQL.
NoSQL
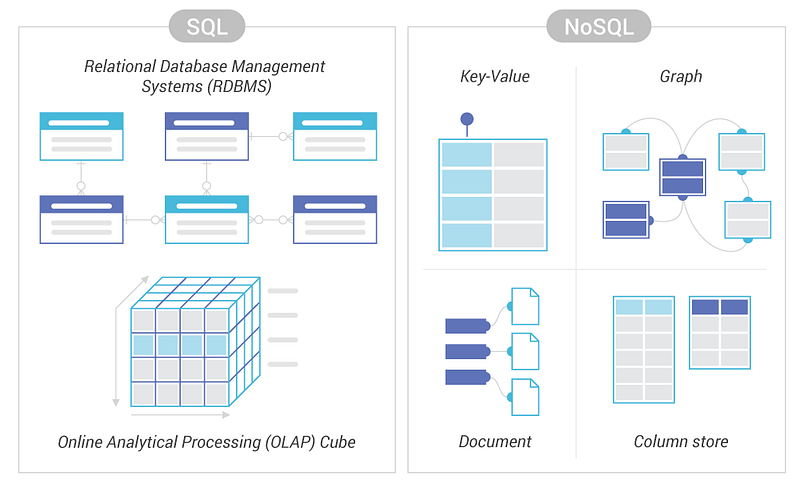
NoSQL databases on the other side, have no predefined schema which adds to more flexibility to use the formats that best suits the data — Work with graphs, column-oriented data, key-value and documents etc. They are generally preferred for hierarchical data, graphs ( e.g. social network) and to work with large data.
Some examples — Wide-column use Cassandra and HBase, Graph use Neo4j, Document use MongoDB and CouchDB, Key-value use Redis and DynamoDB,
A good comparison —
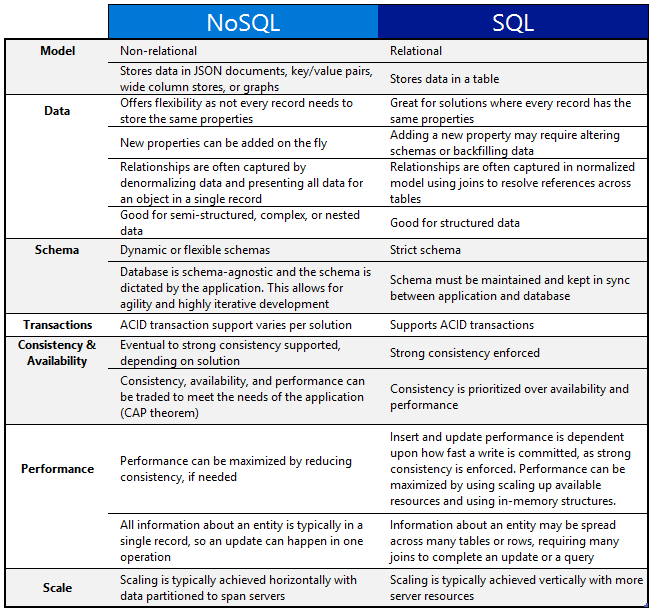
One of the important question that you might be asked, when to use which db?
When use SQL databases?
When you want to —
1. Scale Vertically — increase the processing power of your hardware
2. Work with predefined schema
3. Process queries and joins against structured data
4. Optimize the storage
5. Data is small
When to use NoSQL databases?
When you want to —
1. Scale horizontally
2. Work with graphs, column-oriented data, key-value and documents etc
3. Use multiple languages to query
4. Work with dynamic schema that has no predefined schema
5. Large Data
Implementation —
--SQL Database
-- Create a table for storing users
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
-- Insert a user into the table
INSERT INTO users (id, name, email)
VALUES (1, 'John Doe', '[email protected]');
-- Retrieve all users from the table
SELECT * FROM users;
--NoSQL (MongoDB) Database:
// Connect to the MongoDB database
const MongoClient = require('mongodb').MongoClient;
const url = 'mongodb://localhost:27017';
const dbName = 'mydatabase';
MongoClient.connect(url, function(err, client) {
if (err) throw err;
// Access the database
const db = client.db(dbName);
// Create a collection for storing users
const usersCollection = db.collection('users');
// Insert a user into the collection
usersCollection.insertOne({ id: 1, name: 'John Doe', email: '[email protected]' }, function(err, result) {
if (err) throw err;
// Retrieve all users from the collection
usersCollection.find().toArray(function(err, users) {
if (err) throw err;
console.log(users);
// Close the database connection
client.close();
});
});
});That’s it for now.
Find Day 14 Below —
Let me know if you have questions in the comment section below. Subscribe/ Follow, Like/Clap as it would encourage me to write more in my free time
Stay Tuned!!
Read More —
11 most important System Design Base Concepts
6. Networking, How Browsers work, Content Network Delivery ( CDN)
13. System Design Template — How to solve any System Design Question
Some of the other best Series —
30 days of Data Structures and Algorithms and System Design Simplified
Data Science and Machine Learning Research ( papers) Simplified **
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Exceptional Github Repos — Part 1
Exceptional Github Repos — Part 2
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding!
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras




