
Day 29 of 30 days of Data Engineering Series with Projects
Welcome back peeps to Day 29 of Data Engineering Series with Projects!
In this we will cover —
Data Engineering on cloud
AWS
AWS Services
Google Cloud Platform
GCP services
Pre-requisite to Day 29 is to complete Day 1–28( link below):
Day 3 : Complete Advanced Python for Data Engineering — Part 2
Day 18 : Data Visualization basics, Data Visualization Projects, Data Visualization using Plotly and Bokeh, Data Profiling, Summary Functions, Indexing, Grouping, Linear Regression, Multi Linear Regression, Polynomial Regression, Regression, Support Vector Regression, Decision Tree Regression, Random Forest Regression, Feature Engineering, GroupBy Features, Categorical and Numerical Features, Missing Value Analysis, Fill the missing Values, Unique Value Analysis, Univariate Analysis, Bivariate Analysis, Multivariate Analysis, Correlation Analysis, Spearman’s ρ, Pearson’s r, Kendall’s τ, Cramér’s V (φc), Phik (φk)
Day 20 : ETL ( Extract, Tranform and Load) basics, Why ETL is important?, How ETL works, ETL Tools
Day 21 : Structured Data, Semi Structured Data, Unstructured Data, Data Warehouse, Data Mart, Data Lake
Day 25: Docker, Docker vs Virtual Machines, Most important Docker commands, Kubernetes, Snowflake
Day 26 : Data Pipelines, Transformation, Processing, Workflow, Monitoring, Airflow, DAG
Day 29 : Data Engineering on cloud, AWS, AWS Services, Google Cloud Platform, GCP services
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Ignito:
System Design Case Studies — In Depth
Design Instagram
Design Netflix
Design Reddit
Design Amazon
Design Messenger App
Design Twitter
Design URL Shortener
Design Dropbox
Design Youtube
Design API Rate Limiter
Design Web Crawler
Design Amazon Prime Video
Design Facebook’s Newsfeed
Design Yelp
Design Uber
Design Tinder
Design Tiktok
Design Whatsapp
Most Popular System Design Questions
Mega Compilation : Solved System Design Case studies
Let’s get started!
Data Engineering on cloud refers to the process of building, deploying, and maintaining systems for collecting, storing, processing, and analyzing data on cloud platforms such as AWS (Amazon Web Services) and GCP (Google Cloud Platform).
AWS is a cloud computing platform that offers a wide range of services for data engineering, including:
- S3: Simple Storage Service, an object storage service that can be used to store and retrieve large amounts of data.
- Glue: A fully managed extract, transform, and load (ETL) service that makes it easy to move and transform data.
- Redshift: A data warehouse service that can be used to store and query large amounts of data.
- DynamoDB: A NoSQL database service that can be used to store and retrieve data in a flexible and scalable manner.
- Kinesis: A real-time streaming data service that can be used to collect, process, and analyze streaming data.
Google Cloud Platform (GCP) also offers a wide range of services for data engineering, including:
- BigQuery: A fully managed, cloud-native data warehouse that can be used to store and query large amounts of data.
- Cloud Storage: An object storage service similar to AWS S3.
- Cloud Dataflow: A fully managed service for creating data pipelines and performing ETL operations.
- Cloud Dataproc: A fully managed service for running Apache Hadoop and Apache Spark workloads.
- Cloud SQL: A fully managed SQL database service that can be used to store and query relational data.
Data Engineering on cloud
It’s the process of building, testing, deploying data processing systems and ML modules on Cloud. Companies/organizations have large amount of data that needs to be stored, processed and analyzed accurately.
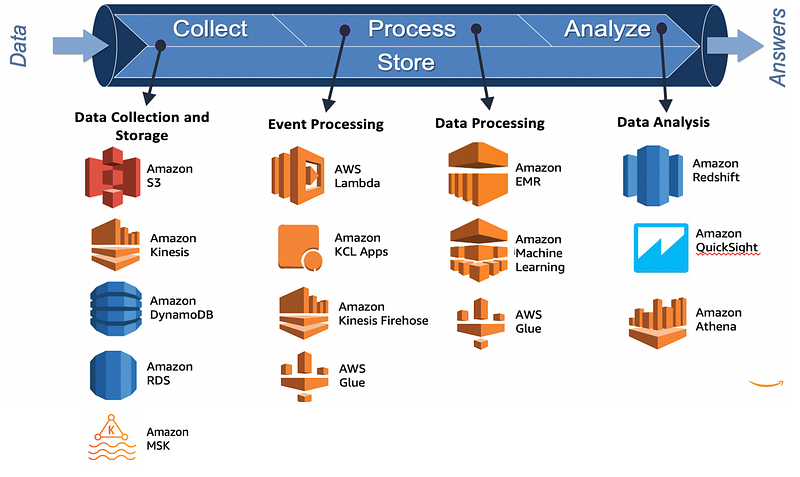
Cloud services for each step —
Data Ingestion — ETL and Stream Processing
Data Storage — RDBMS, Object Store, Key Value Store
Data Processing — ETL Services, Distributed processing, Data Pipeline, Workflow
Data Analysis and Visualization — Data Warehouse, Machine Learning, Streaming Analytics and Business Intelligence
Security — Authentication, Data Encryption, Access and Policies
Deployment — Containerization, Orchestration, CI/CD
AWS
AWS is a cloud computing platform providing cost effective, scalable solutions to the businesses all over the world.

The advantages of using AWS —
Automated Management
Speed and Agility
Security
Automated backups
Third Party APIs integration
Multi tenant architecture
Highly scalable according to the business needs
Affordable subscription model
Fixed and Predictable costs
For data engineering, big data management and analytics, AWS offers-
Amazon EMR — Hadoop framework to process large amount of data
Amazon Kinesis — To process and analyze data and develop interactive analytics
Amazon Glue — To extract, transform and load jobs
Amazon Athena — To query the data
Amazon QuickSight — To visualize the data
Amazon Elastic Search — To perform monitoring, log analysis etc.
For Machine Learning and AI, AWS offers —
Amazon lex — For chatbot tech
Amazon Forecast — To build end-to-end prediction model
Amazon Polly — To do text — to — speech transition
Amazon Textract — To extract imp text and data from documents
We will be covering each service in detail in the further posts.
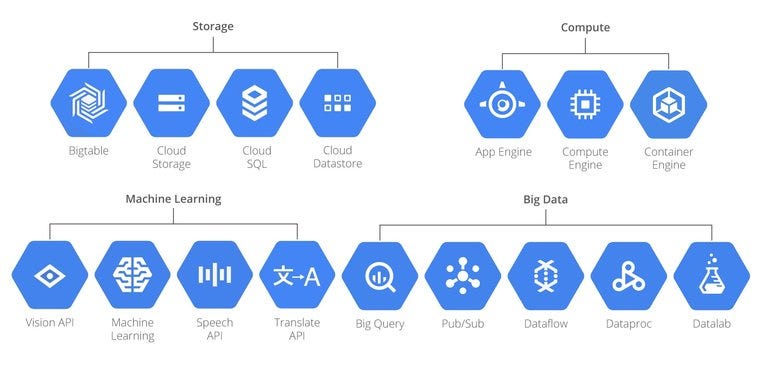
Google Cloud Platform
Google Cloud platform is a cloud computing platform which offers easy to use, tools and services, global, regional and zonal resources.
It has —
Cloud storage — To store binary or object data like images, media etc
Cloud SQL — Database service which allows users to configure, use databases in the cloud.
Cloud Bigtable — High performance NoSQL big data service to cater to high workloads etc.
Cloud Datastore — NoSQL database that stores data in different formats
Cloud spanner — Used to manage globally distributed relational database
Big Query — Used for data analysis
Cloud Dataflow — To perform data batch and stream processing tasks
Cloud Datalab — To explore, analyze and visualize data
Cloud Dataproc — To process big dataset using Apache big data environment
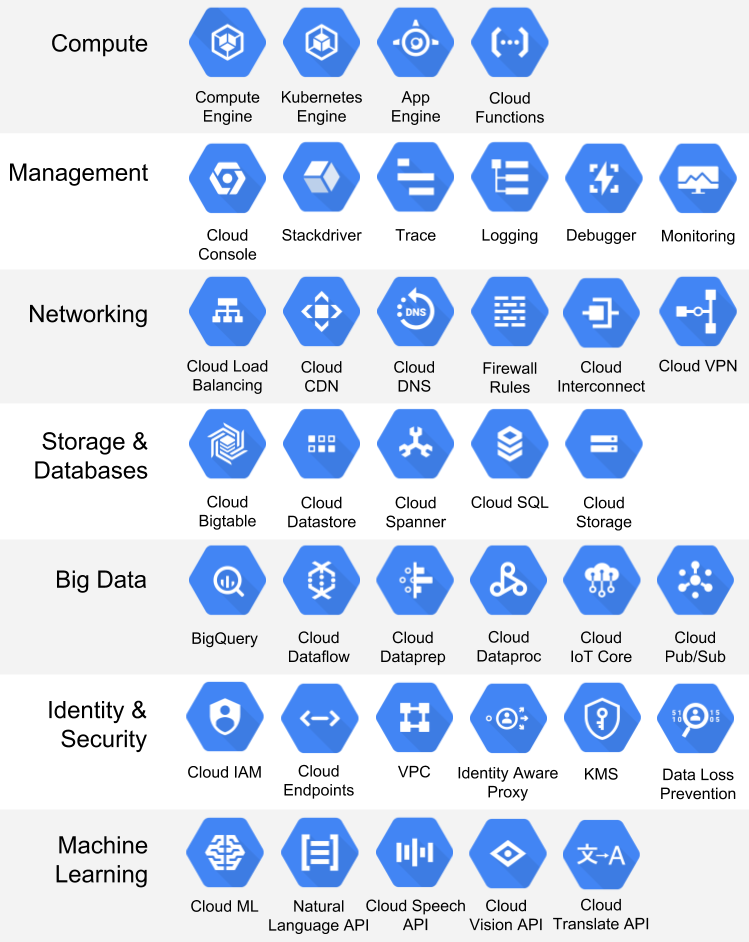
For Machine Learning and AI —
Cloud AutoML — To provide high quality models
Cloud speech API and vision API — For speech recognition, image recognition and classification
Cloud NLP API — For NLP tasks, sentiment analysis and text classification etc
A project video covering Data engineering on cloud, AWS, Google Cloud Platform coming soon ( subscribe today) —
That’s it for now. Day 30: Coming soon!
Let me know if you have questions in the comment section below. Subscribe/ Follow, Like/Clap as it would encourage me to write more in my free time
Stay Tuned!!
Read more —
All the Complete System Design Series Parts —
6. Networking, How Browsers work, Content Network Delivery ( CDN)
Github —
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding!
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras




