
Project 8 — Day 22 of 30 days of Data Analytics with Projects Series
Welcome back peep. Hope all’s well. This is Day 22 of 30 days of data analytics where we will be implementing a project covering —
Linear Regression
Data Profiling
Feature Engineering
Sort Values
Categorical and Numerical Features
Missing Value Analysis
Unique Value Analysis
Univariate Analysis
Bivariate Analysis
Multivariate Analysis
Correlation Analysis
Correlation Coefficients
Let’s cover some of the most important concepts in brief —
- Data Profiling: is the process of analyzing and summarizing the main characteristics of a dataset. This can include reviewing the data types, number of records, missing values, and other statistical summaries.
- Feature Engineering: is the process of creating new features from existing data to improve the performance of a model. This can include combining existing features, creating new features based on mathematical transformations of existing data, or using domain knowledge to create new features.
- GroupBy Features: is a method of grouping data by one or more features and then calculating statistics for each group. This can be useful for identifying patterns or trends within the data.
- Categorical and Numerical Features: Categorical features refer to data that can be divided into categories, such as gender or product type. Numerical features refer to data that can be quantified, such as age or price.
- Missing Value Analysis: is the process of identifying and analyzing missing values in a dataset. This can include calculating the percentage of missing values, identifying patterns in the missing data, and determining the best way to handle missing values.
- Fill the missing Values: is the process of imputing or replacing missing values in a dataset. This can include using a mean, median, or mode to replace missing values, or using more advanced techniques such as machine learning models.
- Unique Value Analysis: is the process of identifying and analyzing unique values in a dataset. This can include calculating the percentage of unique values, identifying patterns in the unique data, and determining the best way to handle unique values.
- Univariate Analysis: is the process of analyzing one variable at a time. This can include calculating summary statistics, creating histograms or box plots, and identifying outliers.
- Bivariate Analysis: is the process of analyzing the relationship between two variables. This can include calculating correlation coefficients, creating scatter plots, and identifying patterns or trends in the data.
- Multivariate Analysis: is the process of analyzing the relationship between three or more variables. This can include using techniques such as principal component analysis or multivariate regression.
- Correlation Analysis: is the process of analyzing the relationship between two or more variables. This can include calculating correlation coefficients and identifying patterns or trends in the data.
- Correlation Coefficients: are measures of the strength and direction of the relationship between two variables. Some examples include:
- Spearman’s ρ: a non-parametric measure of the correlation between two variables.
- Pearson’s r: a measure of the linear correlation between two variables.
- Kendall’s τ: a non-parametric measure of the correlation between two variables.
- Cramér’s V (φc): a measure of association between two categorical variables.
- Phik (φk): a measure of association between two categorical variables.
These coefficients can be used to determine whether two variables are positively or negatively correlated and the strength of this correlation.
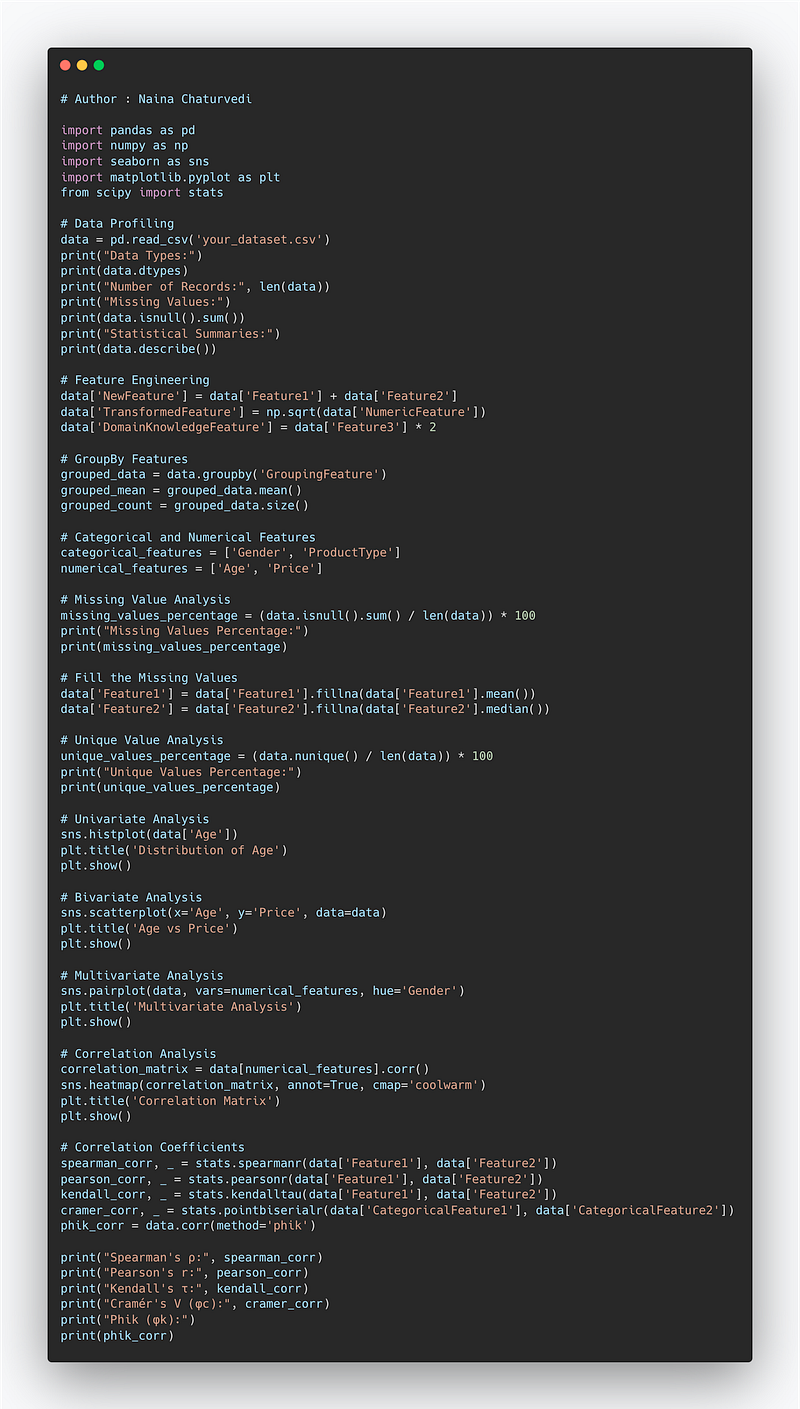
Example Code Implementation —
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
# Data Profiling
data = pd.read_csv('your_dataset.csv')
print("Data Types:")
print(data.dtypes)
print("Number of Records:", len(data))
print("Missing Values:")
print(data.isnull().sum())
print("Statistical Summaries:")
print(data.describe())
# Feature Engineering
data['NewFeature'] = data['Feature1'] + data['Feature2']
data['TransformedFeature'] = np.sqrt(data['NumericFeature'])
data['DomainKnowledgeFeature'] = data['Feature3'] * 2
# GroupBy Features
grouped_data = data.groupby('GroupingFeature')
grouped_mean = grouped_data.mean()
grouped_count = grouped_data.size()
# Categorical and Numerical Features
categorical_features = ['Gender', 'ProductType']
numerical_features = ['Age', 'Price']
# Missing Value Analysis
missing_values_percentage = (data.isnull().sum() / len(data)) * 100
print("Missing Values Percentage:")
print(missing_values_percentage)
# Fill the Missing Values
data['Feature1'] = data['Feature1'].fillna(data['Feature1'].mean())
data['Feature2'] = data['Feature2'].fillna(data['Feature2'].median())
# Unique Value Analysis
unique_values_percentage = (data.nunique() / len(data)) * 100
print("Unique Values Percentage:")
print(unique_values_percentage)
# Univariate Analysis
sns.histplot(data['Age'])
plt.title('Distribution of Age')
plt.show()
# Bivariate Analysis
sns.scatterplot(x='Age', y='Price', data=data)
plt.title('Age vs Price')
plt.show()
# Multivariate Analysis
sns.pairplot(data, vars=numerical_features, hue='Gender')
plt.title('Multivariate Analysis')
plt.show()
# Correlation Analysis
correlation_matrix = data[numerical_features].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Matrix')
plt.show()
# Correlation Coefficients
spearman_corr, _ = stats.spearmanr(data['Feature1'], data['Feature2'])
pearson_corr, _ = stats.pearsonr(data['Feature1'], data['Feature2'])
kendall_corr, _ = stats.kendalltau(data['Feature1'], data['Feature2'])
cramer_corr, _ = stats.pointbiserialr(data['CategoricalFeature1'], data['CategoricalFeature2'])
phik_corr = data.corr(method='phik')
print("Spearman's ρ:", spearman_corr)
print("Pearson's r:", pearson_corr)
print("Kendall's τ:", kendall_corr)
print("Cramér's V (φc):", cramer_corr)
print("Phik (φk):")
print(phik_corr)Snippet —
What’s covered in 30 days of Data Analytics Series till now —
Day 1 : Data Analytics basics and kickstart of Data analytics with projects series
Day 3 : Data Analytics Ecosystem — Data Life Cycle, Data Analysis complete process ( most important things)
Day 5 : Statistics
Day 6 : Basic and Advanced SQL
Day 8 : Pandas and Numpy
Day 9 : Data Manipulation
Day 10 : Data Visualization — Part 1
Day 11 : Project 1 : Data Visualization — Part 2
Day 12 : Data Visualization — Part 3
Day 13: Tableau — Part 1
Day 14: Tableau — Part 2
Day 15: Tableau — Part 3
Day 16 : Data Analysis Project 2
Day 17 : Data Analysis Project 3
Day 18: Data Analysis Project 4
Day 20 : Data Analysis Project 6
Day 21 : Data Analysis Project 7
Take Complete Hands On Tableau Course : Link
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
In the last post we covered Data Visualization and in this post we will cover a project.
Before starting, go through this post to understand which chart to use and when.
(Note : Zoom all the images)
Import Necessary Libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
from matplotlib import pyplot as plt
import numpy as np
from matplotlib.colors import rgb2hex
import matplotlib.cm as cm
import matplotlib.colors
from collections import Counter
cmap2 = cm.get_cmap('twilight',13)
colors1= []
for i in range(cmap2.N):
rgb= cmap2(i)[:4]
colors1.append(rgb2hex(rgb))
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Set style
sns.set(style='whitegrid')Load data
#Load the data
df= pd.read_csv('/Path to file/Pokemon.csv', low_memory = False)
#Get information about your data
df.info()Output —
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 800 entries, 0 to 799
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 # 800 non-null int64
1 Name 800 non-null object
2 Type 1 800 non-null object
3 Type 2 414 non-null object
4 Total 800 non-null int64
5 HP 800 non-null int64
6 Attack 800 non-null int64
7 Defense 800 non-null int64
8 Sp. Atk 800 non-null int64
9 Sp. Def 800 non-null int64
10 Speed 800 non-null int64
11 Generation 800 non-null int64
12 Legendary 800 non-null bool
dtypes: bool(1), int64(9), object(3)
memory usage: 75.9+ KB# Get Columns informationdf.columnsOutput —
Index(['#', 'Name', 'Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense',
'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary', 'FName'],
dtype='object')Data Description
‘#’: ID for each pokemon
Name: Name of each pokemon
Type 1: Each pokemon has a type, this determines weakness/resistance to attacks
Type 2: Some pokemon are dual type and have 2 types
Total: sum of all stats of pokemon — how strong a pokemon
HP: hit points, or health, defines how much damage a pokemon can withstand before fainting
Attack: the base modifier for normal attacks (eg. Scratch, Punch)
Defense: the base damage resistance against normal attacks
SP Atk: special attack, the base modifier for special attacks (e.g. fire blast, bubble beam)
SP Def: the base damage resistance against special attacks
Speed: determines which pokemon attacks first each round
Generation : Generation of each pokemon
Statistical Summary of the data
df.describe()Categorical and Numerical Features
Categorical features are those values that be sorted into groups or categories.
Numerical Features are those values that can be measures (can be places in ascending or descending order)
For this, lets get the Categorical and Numerical Features —
df.info()Output —
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16376 entries, 0 to 16375
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 page_id 16376 non-null int64
1 name 16376 non-null object
2 urlslug 16376 non-null object
3 ID 12606 non-null object
4 ALIGN 13564 non-null object
5 EYE 6609 non-null object
6 HAIR 12112 non-null object
7 SEX 15522 non-null object
8 GSM 90 non-null object
9 ALIVE 16373 non-null object
10 APPEARANCES 15280 non-null float64
11 FIRST APPEARANCE 15561 non-null object
12 Year 15561 non-null float64
dtypes: float64(2), int64(1), object(10)
memory usage: 1.6+ MBYou can see , in our dataset —
Categorical Features are Name, Type , Type 2
Numerical Variable are ID, Total, HP, Attack, Defense, Sp.Atk, Sp. Def, Speed,Generation, Legendary
Missing Value Analysis
In this we figure out the missing values in the
df.isnull().sum()Output —
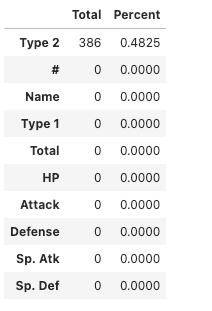
Name 0
Type 1 0
Type 2 386
Total 0
HP 0
Attack 0
Defense 0
Sp. Atk 0
Sp. Def 0
Speed 0
Generation 0
Legendary 0
dtype: int64One can also calculate the percentage of missing values out of the total.
p = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False)
t = df.isnull().sum().sort_values(ascending=False)
m_data = pd.concat([t, p], axis=1, keys=['Total', 'Percent'])
m_data.head(10)Output —
Unique Value Analysis
One can get the count of the unique values for each column in your data —
for i in list(df.columns):
print("{} -> {}".format(i, df[i].value_counts().shape[0]))Output —
# -> 721
Name -> 800
Type 1 -> 18
Type 2 -> 18
Total -> 200
HP -> 94
Attack -> 111
Defense -> 103
Sp. Atk -> 105
Sp. Def -> 92
Speed -> 108
Generation -> 6
Legendary -> 2Univariate Analysis
In Univariate Analysis, single variable/feature is analyzed at a time.
First we will start with Categorical Features in our data and then Numerical Features.
Categorical Features are Name, Type , Type 2
Numerical Variable are ID, Total, HP, Attack, Defense, Sp.Atk, Sp. Def, Speed,Generation, Legendary
Categorical Features Univariate Analysis
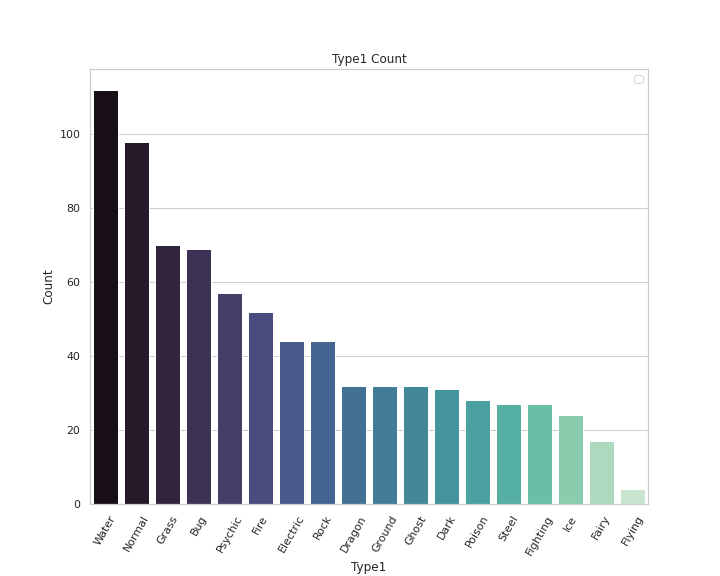
# Type 1 Pokemon Count
plt.figure(figsize=(10,8))
sns.countplot(x='Type 1',data=df,palette='mako',order = df['Type 1'].value_counts().index)
plt.xlabel('Type1')
plt.xticks(rotation = 60)
plt.ylabel('Count')
plt.legend()
plt.title('Type1 Count')
plt.show()
Output —
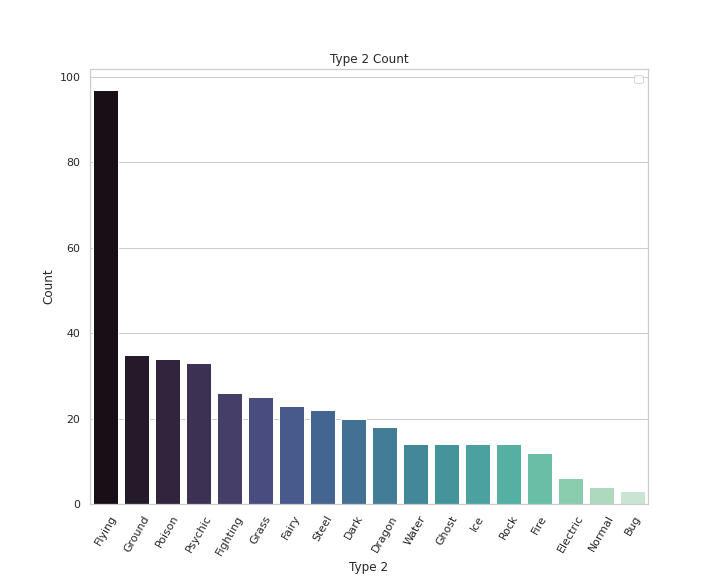
# Type 2 Pokemon Count
plt.figure(figsize=(10,8))
sns.countplot(x='Type 2',data=df,palette='mako',order = df['Type 2'].value_counts().index)
plt.xlabel('Type 2')
plt.xticks(rotation = 60)
plt.ylabel('Count')
plt.legend()
plt.title('Type 2 Count')
plt.show()Output —
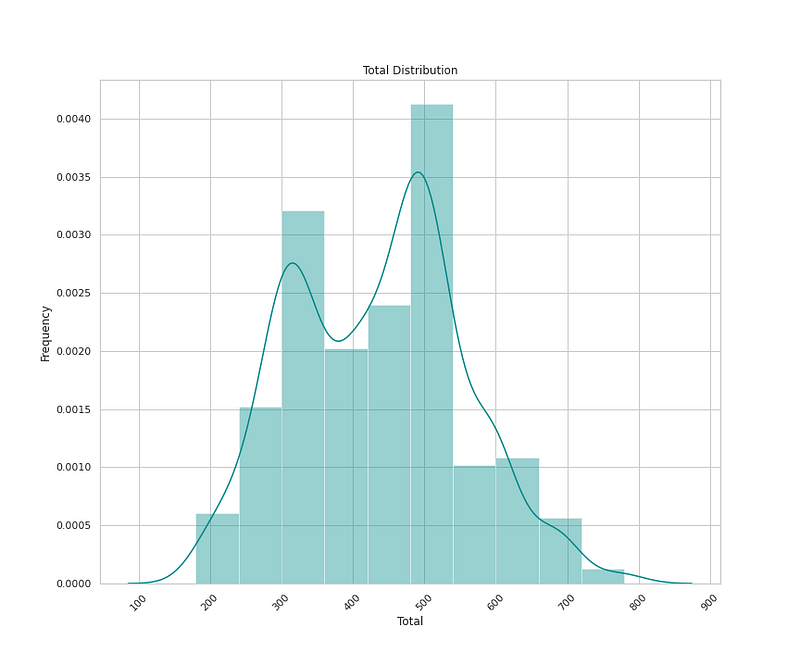
Numerical Features Univariate Analysis
# Total Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Total'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Total Distribution')
plt.xlabel('Total')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
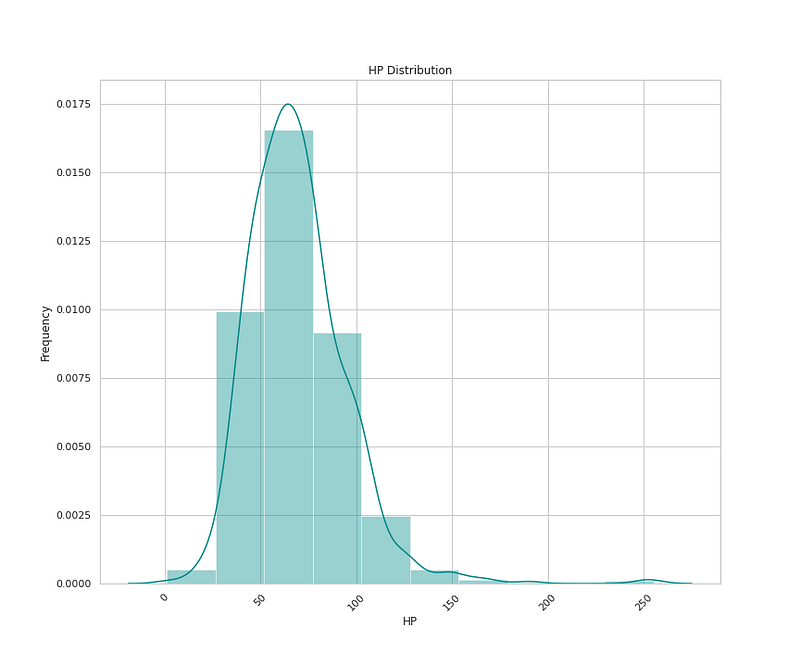
# HP Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['HP'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('HP Distribution')
plt.xlabel('HP')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
# Attack Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Attack'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Attack Distribution')
plt.xlabel('Attack')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
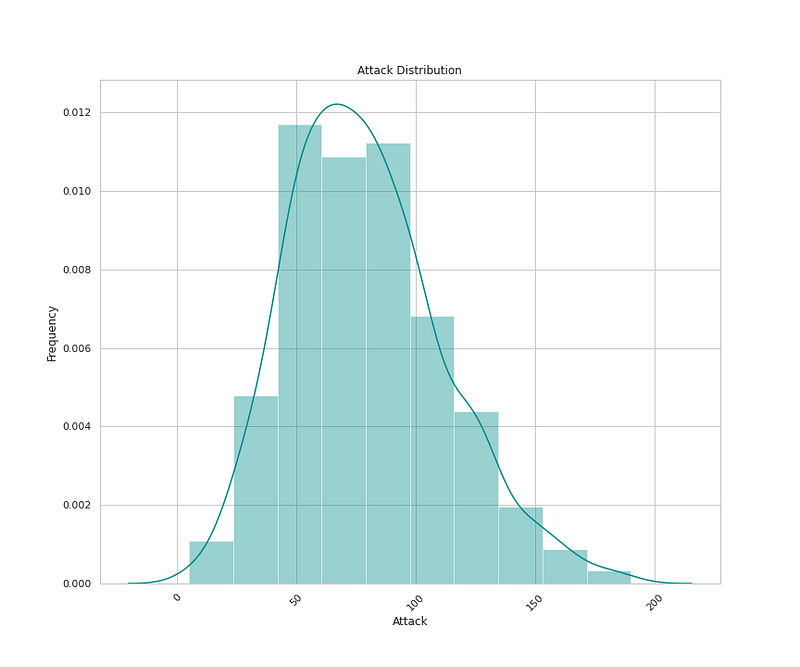
# Defense Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Defense'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Defense Distribution')
plt.xlabel('Defense')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
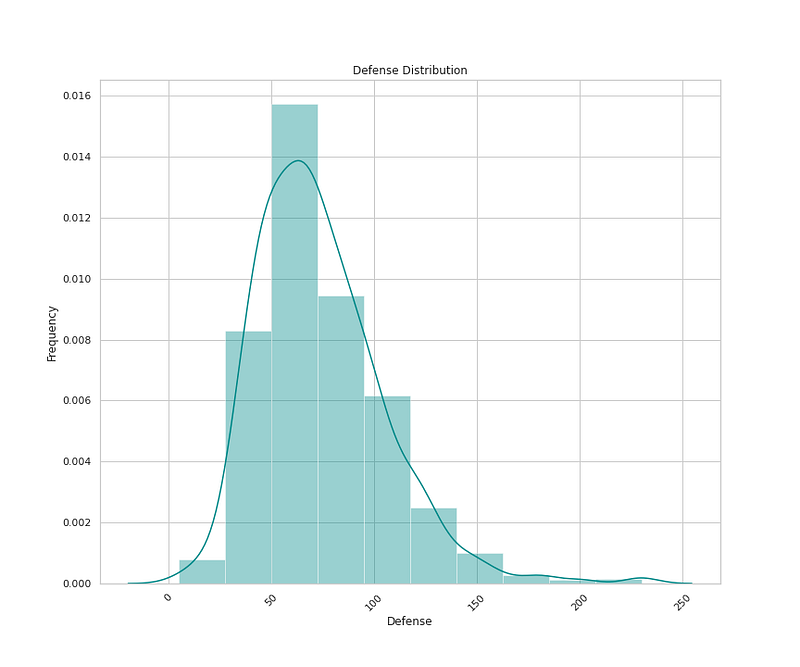
# Sp Attack Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Sp. Atk'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Sp. Attack Distribution')
plt.xlabel('Sp. Attack')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
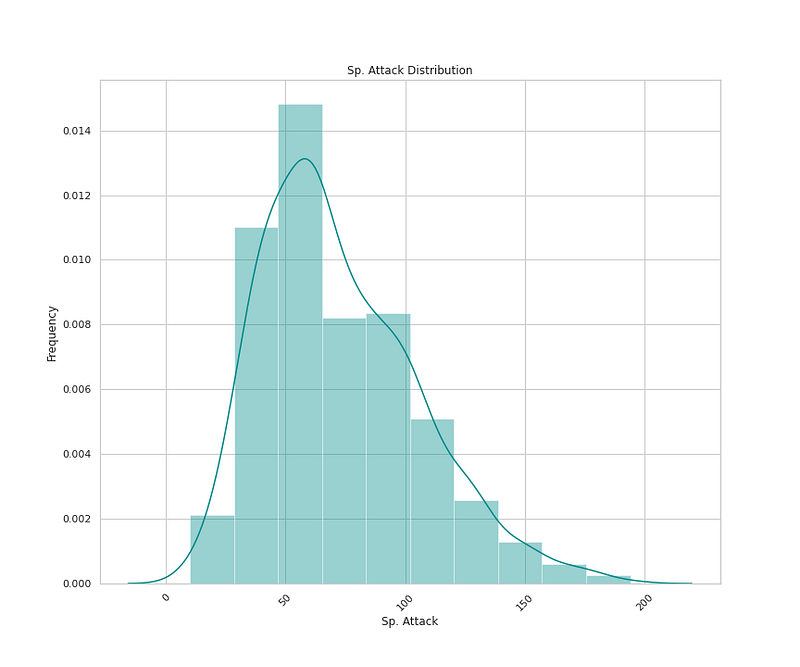
# Sp Defense Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Sp. Def'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Sp. Def Distribution')
plt.xlabel('Sp. Def')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
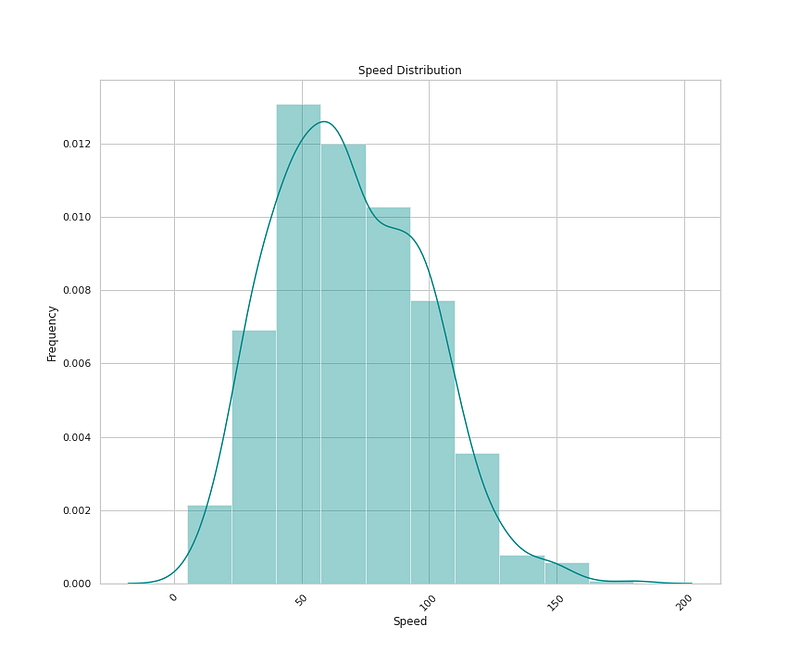
# Speed Distribution
plt.figure(figsize=(12,10))
sns.distplot(x=df['Speed'],bins=10,color='darkcyan',kde=True,hist=True)
plt.title('Speed Distribution')
plt.xlabel('Speed')
plt.ylabel('Frequency')
plt.xticks(rotation=45)
plt.show()Output —
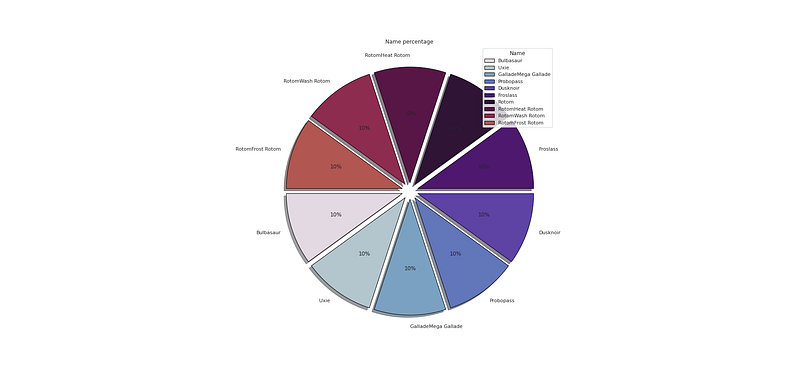
# Name Percentage
plt.figure(figsize=(25,12))
p_r = df['Name'].value_counts().head(10)
plt.pie(x=p_r,labels=p_r.index,colors=colors1,autopct='%.0f%%',explode=[0.07 for i in p_r.index],startangle=180,wedgeprops={'linewidth':1,'edgecolor':'black'},shadow=True)
plt.title('Name percentage ')
plt.legend(loc='upper right',title='Name')
plt.show()Output —
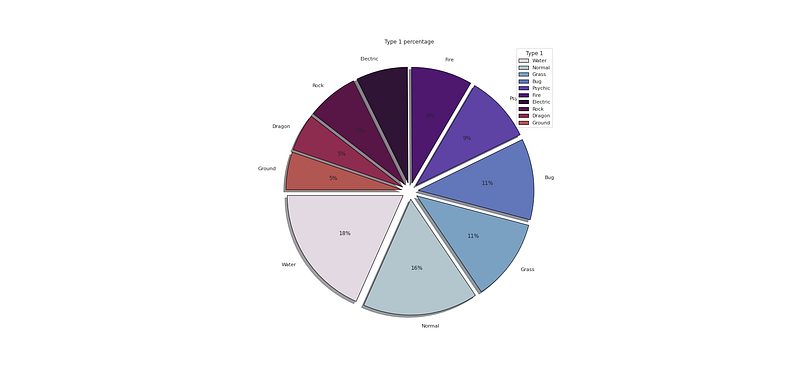
# Type 1 Percentage
plt.figure(figsize=(25,12))
p_r = df['Type 1'].value_counts().head(10)
plt.pie(x=p_r,labels=p_r.index,colors=colors1,autopct='%.0f%%',explode=[0.07 for i in p_r.index],startangle=180,wedgeprops={'linewidth':1,'edgecolor':'black'},shadow=True)
plt.title('Type 1 percentage ')
plt.legend(loc='upper right',title='Type 1')
plt.show()Output —
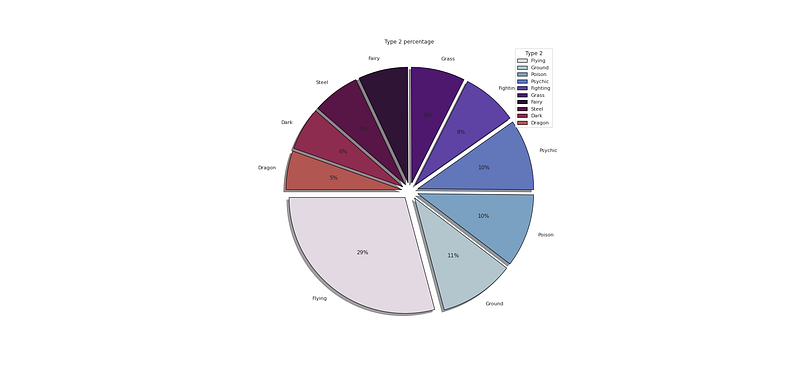
# Type 2 Percentage
plt.figure(figsize=(25,12))
p_r = df['Type 2'].value_counts().head(10)
plt.pie(x=p_r,labels=p_r.index,colors=colors1,autopct='%.0f%%',explode=[0.07 for i in p_r.index],startangle=180,wedgeprops={'linewidth':1,'edgecolor':'black'},shadow=True)
plt.title('Type 2 percentage ')
plt.legend(loc='upper right',title='Type 2')
plt.show()Output —
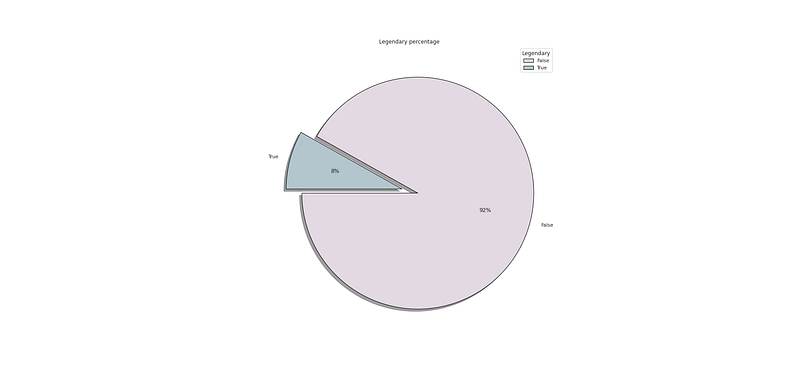
# Legendary Percentage
plt.figure(figsize=(25,12))
p_r = df['Legendary'].value_counts().head(10)
plt.pie(x=p_r,labels=p_r.index,colors=colors1,autopct='%.0f%%',explode=[0.07 for i in p_r.index],startangle=180,wedgeprops={'linewidth':1,'edgecolor':'black'},shadow=True)
plt.title('Legendary percentage ')
plt.legend(loc='upper right',title='Legendary')
plt.show()Output —
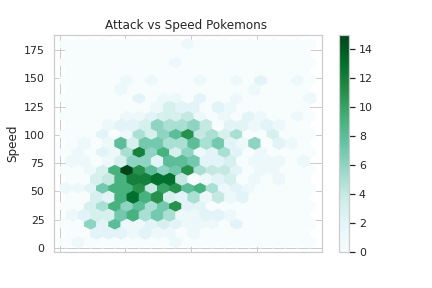
Bivariate Analysis
In Bivariate Analysis, two variables/features are analyzed together and the relationship/association between them is studied.
# Attack vs Speed Pokemons
plt.figure(figsize=(10,8))
df.plot.hexbin(x='Attack', y='Speed', gridsize=20)
plt.title("Attack vs Speed Pokemons ")
plt.show()Output —
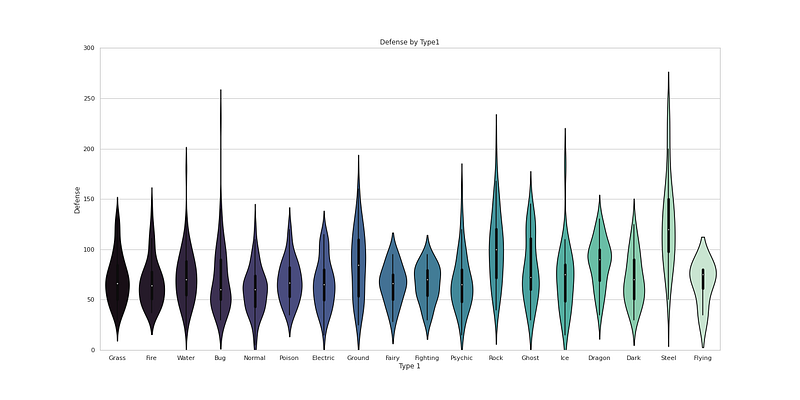
plt.figure(figsize=(20,10))
plt.title('Defense by Type1')
sns.violinplot(x = "Type 1", y = "Defense",data = df,palette='mako')
plt.ylim(0,300)
plt.show()Output —
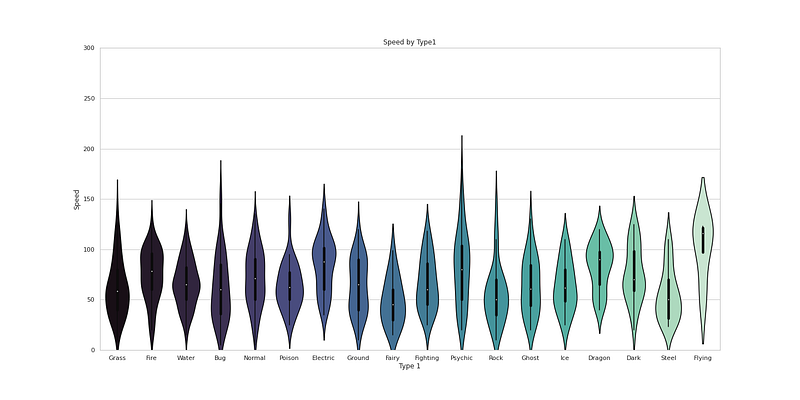
plt.figure(figsize=(20,10))
plt.title('Speed by Type1')
sns.violinplot(x = "Type 1", y = "Speed",data = df,palette='mako')
plt.ylim(0,300)
plt.show()Output —
plt.figure(figsize=(20,20))
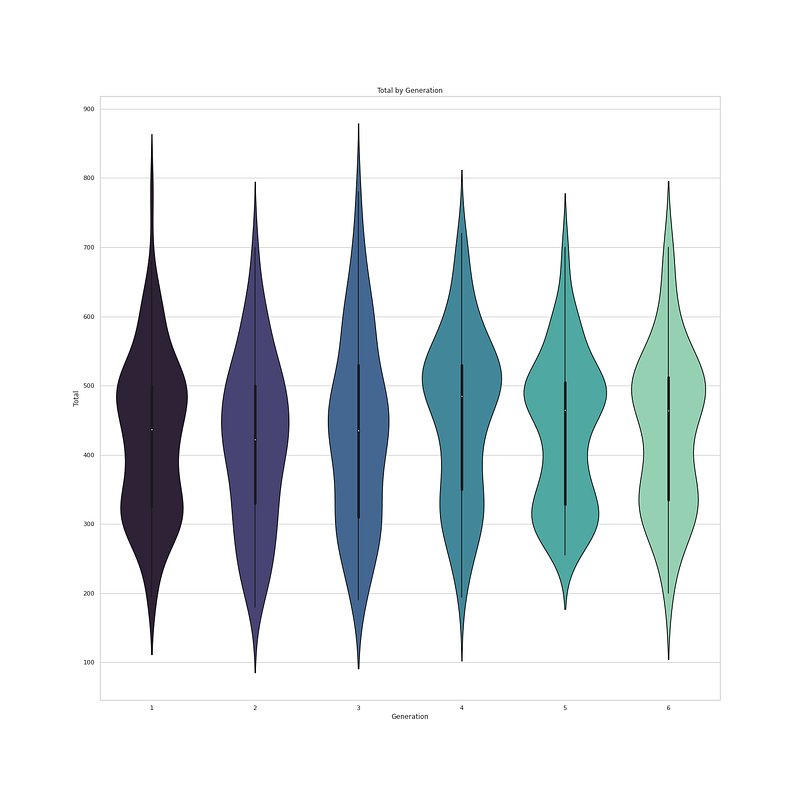
plt.title('Total by Generation')
sns.violinplot(x = "Generation", y = "Total",data = df,palette='mako')
plt.show()
Output —
plt.figure(figsize=(20,20))
plt.title('Attack vs Defense')
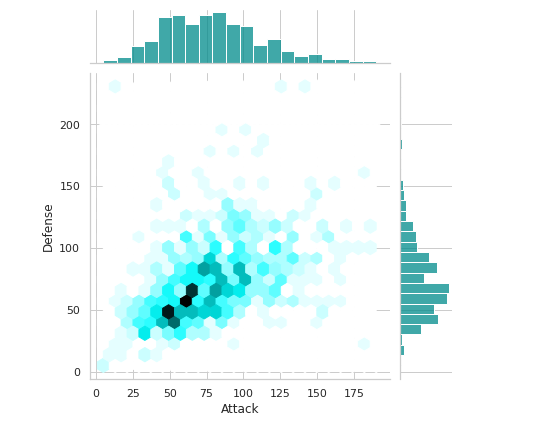
sns.jointplot(x="Attack",y="Defense",data=df,kind="hex",color='darkcyan')
plt.show()Output —
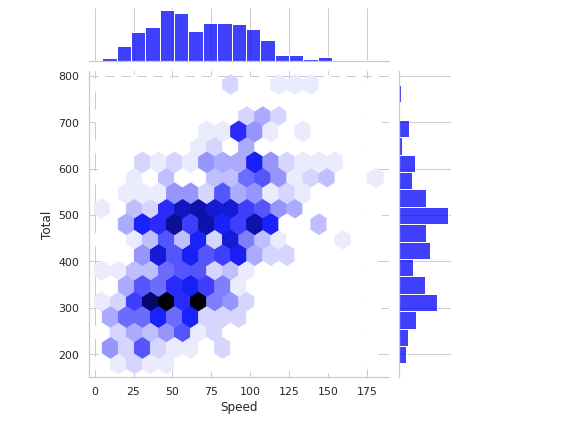
plt.figure(figsize=(20,20))
plt.title('Speed vs Total')
sns.jointplot(x="Speed",y="Total",data=df,kind="hex",color='Blue')
plt.show()Output —
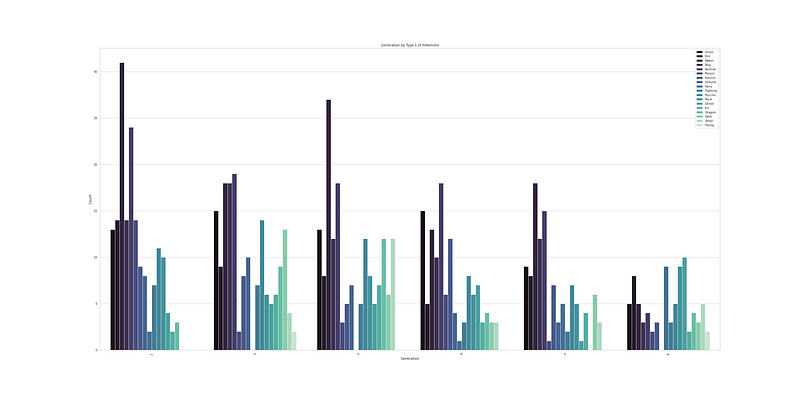
# Generation by Type 1 of Pokemons
plt.figure(figsize=(40,20))
sns.countplot(x='Generation',data=df,palette='mako',order = df['Generation'].value_counts().index, hue = 'Type 1')
plt.xlabel('Generation')
plt.xticks(rotation = 60)
plt.ylabel('Count')
plt.legend()
plt.title('Generation by Type 1 of Pokemons')
plt.show()Output —
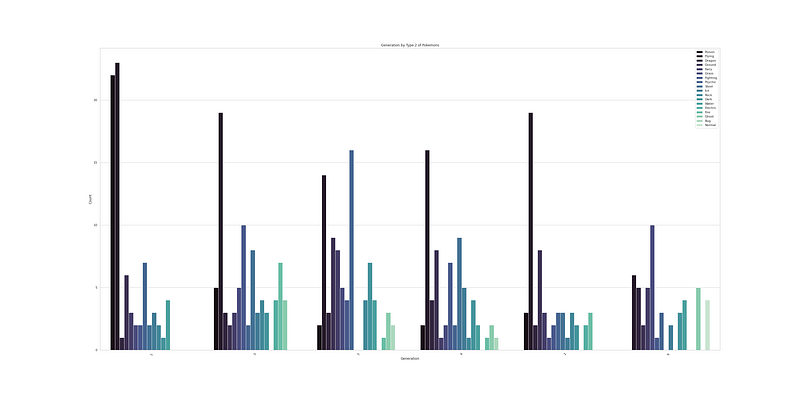
# Generation by Type 2 of Pokemons
plt.figure(figsize=(40,20))
sns.countplot(x='Generation',data=df,palette='mako',order = df['Generation'].value_counts().index, hue = 'Type 2')
plt.xlabel('Generation')
plt.xticks(rotation = 60)
plt.ylabel('Count')
plt.legend(loc='upper right')
plt.title('Generation by Type 2 of Pokemons')
plt.show()Output —
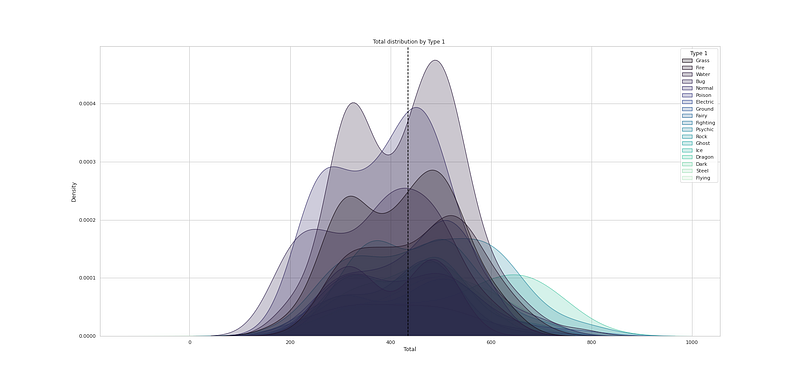
# Total distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["Total"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Total'].mean(), c='black',ls='--')
plt.title("Total distribution by Type 1 ")
plt.show()Output —
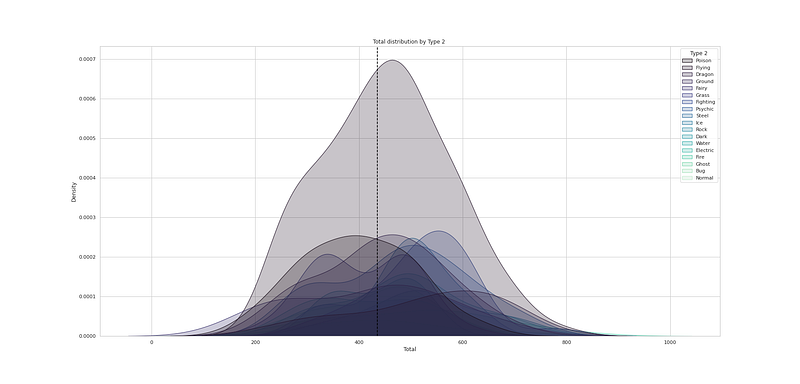
# Total distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["Total"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Total'].mean(), c='black',ls='--')
plt.title("Total distribution by Type 2 ")
plt.show()Output —
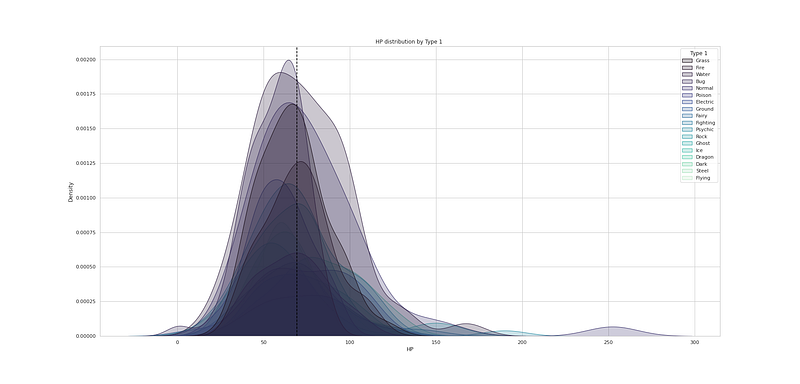
# HP distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["HP"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['HP'].mean(), c='black',ls='--')
plt.title("HP distribution by Type 1 ")
plt.show()Output —
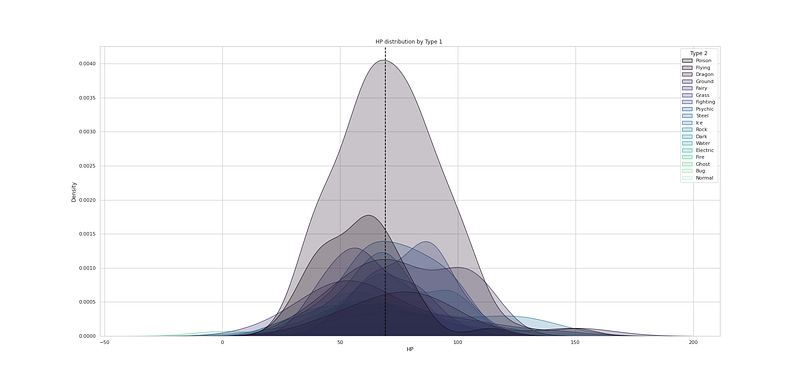
# HP distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["HP"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['HP'].mean(), c='black',ls='--')
plt.title("HP distribution by Type 1 ")
plt.show()Output —
# Attack distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["Attack"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Attack'].mean(), c='black',ls='--')
plt.title("Attack distribution by Type 1 ")
plt.show()Output —
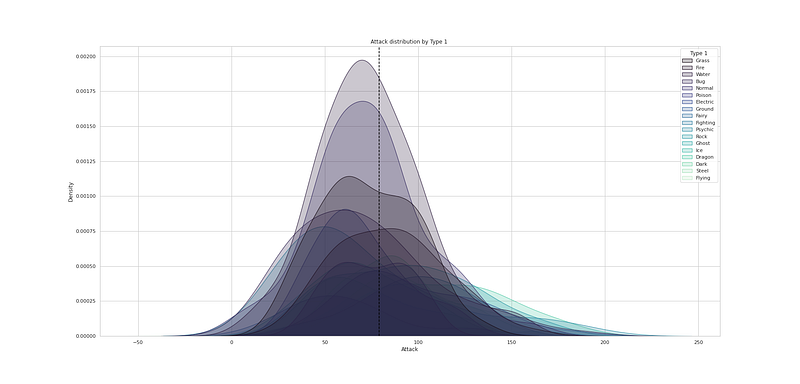
# Attack distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["Attack"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Attack'].mean(), c='black',ls='--')
plt.title("Attack distribution by Type 2 ")
plt.show()Output —
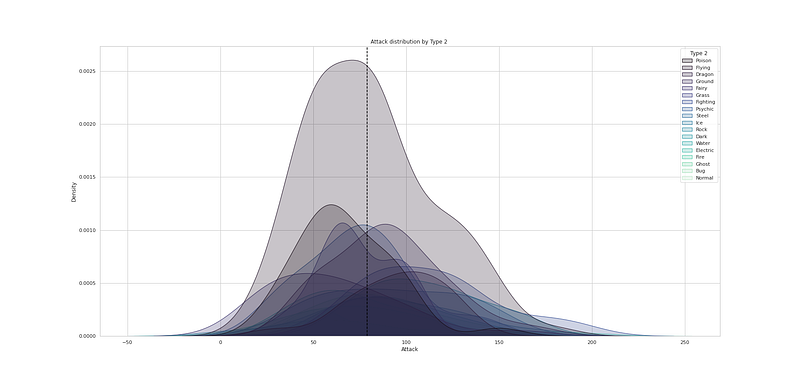
# Defense distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["Defense"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Defense'].mean(), c='black',ls='--')
plt.title("Defense distribution by Type 1 ")
plt.show()Output —
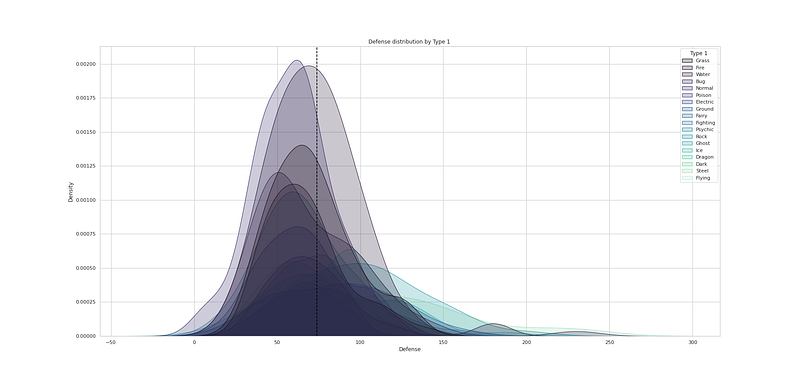
# Defense distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["Defense"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Defense'].mean(), c='black',ls='--')
plt.title("Defense distribution by Type 2 ")
plt.show()Output —
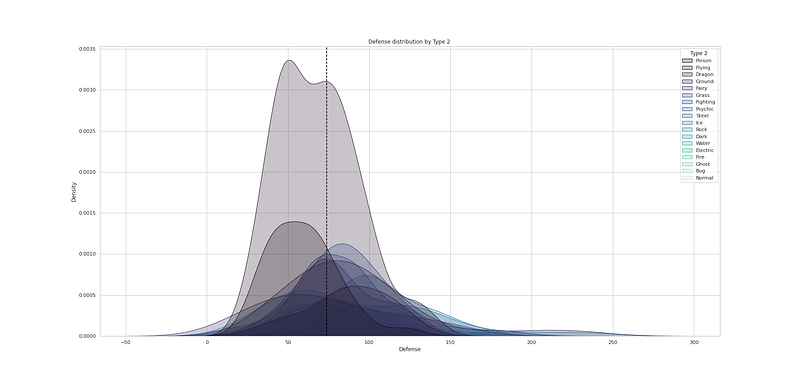
# Sp.Attack distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["Sp. Atk"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Sp. Atk'].mean(), c='black',ls='--')
plt.title("Sp. Atk distribution by Type 1 ")
plt.show()Output —
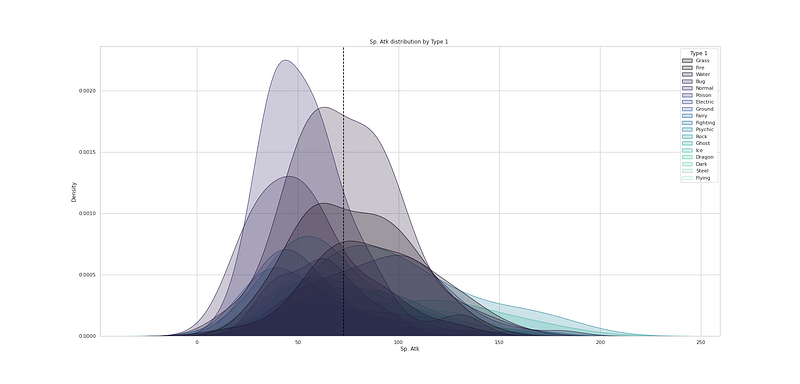
# Sp.Attack distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["Sp. Atk"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Sp. Atk'].mean(), c='black',ls='--')
plt.title("Sp. Atk distribution by Type 2 ")
plt.show()Output —
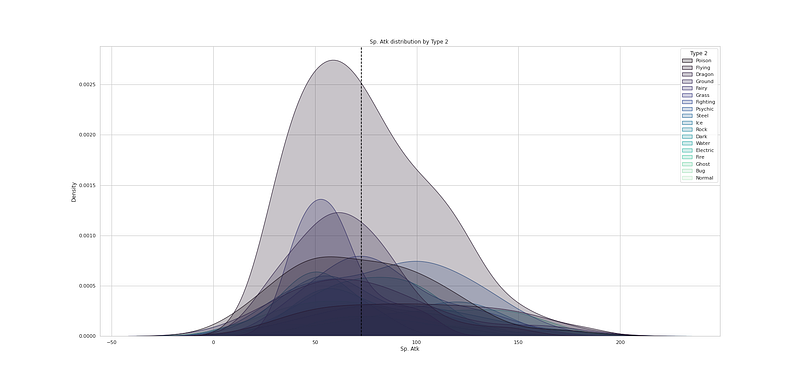
# Speed distribution by Type 1
plt.figure(figsize=(25,12))
sns.kdeplot(df["Speed"], hue=df["Type 1"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Speed'].mean(), c='black',ls='--')
plt.title("Speed distribution by Type 1 ")
plt.show()Output —
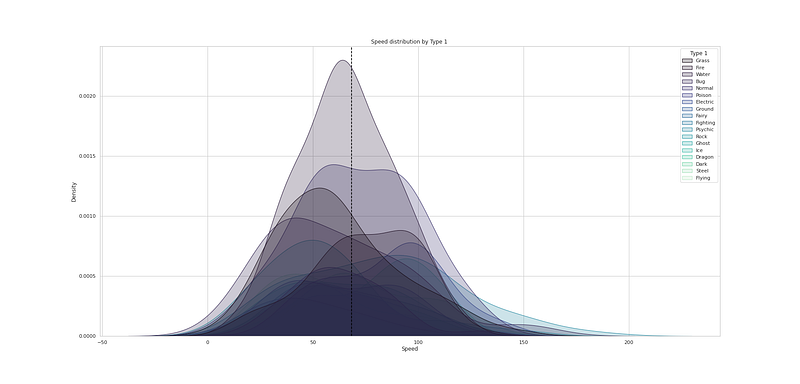
# Speed distribution by Type 2
plt.figure(figsize=(25,12))
sns.kdeplot(df["Speed"], hue=df["Type 2"], fill=True, linewidth=1, palette='mako')
plt.axvline(df['Speed'].mean(), c='black',ls='--')
plt.title("Speed distribution by Type 2 ")
plt.show()Output —

Multivariate Analysis
In Multivariate Analysis, more than two variables/features are analyzed together and the relationship/association between them is studied.
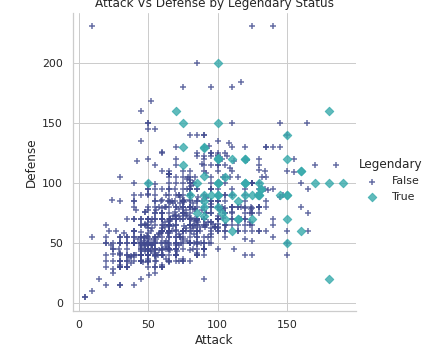
# Attack Vs Defense by Legendary Status
plt.figure(figsize=(20,10))
sns.lmplot(x='Attack', y='Defense', hue='Legendary', markers=['+', 'D'], fit_reg=False, data=df,palette='mako')
plt.title('Attack Vs Defense by Legendary Status')
plt.show()Output —
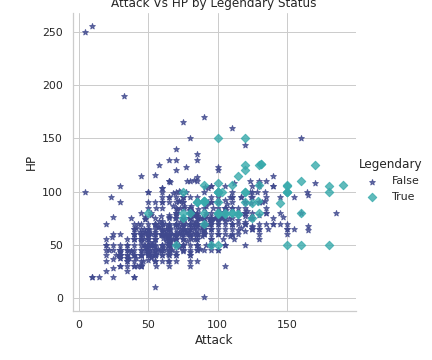
# Attack Vs HP by Legendary Status
plt.figure(figsize=(20,10))
sns.lmplot(x='Attack', y='HP', hue='Legendary', markers=['*', 'D'], fit_reg=False, data=df,palette='mako')
plt.title('Attack Vs HP by Legendary Status')
plt.show()Output —
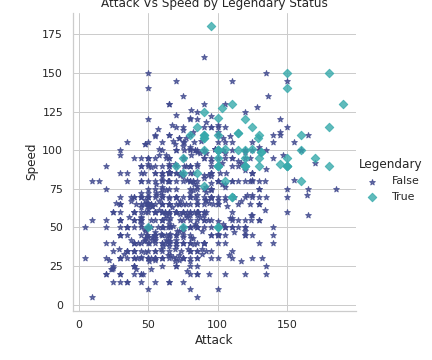
# Attack Vs Speed by Legendary Status
plt.figure(figsize=(20,10))
sns.lmplot(x='Attack', y='Speed', hue='Legendary', markers=['*', 'D'], fit_reg=False, data=df,palette='mako')
plt.title('Attack Vs Speed by Legendary Status')
plt.show()Output —
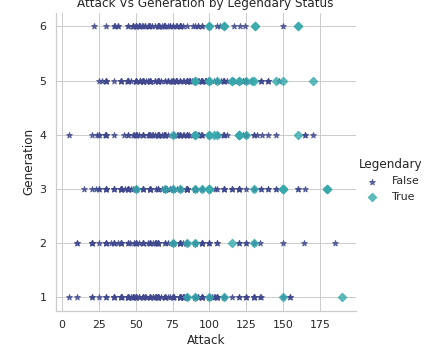
# Attack Vs Generation by Legendary Status
plt.figure(figsize=(20,10))
sns.lmplot(x='Attack', y='Generation', hue='Legendary', markers=['*', 'D'], fit_reg=False, data=df,palette='mako')
plt.title('Attack Vs Generation by Legendary Status')
plt.show()Output —
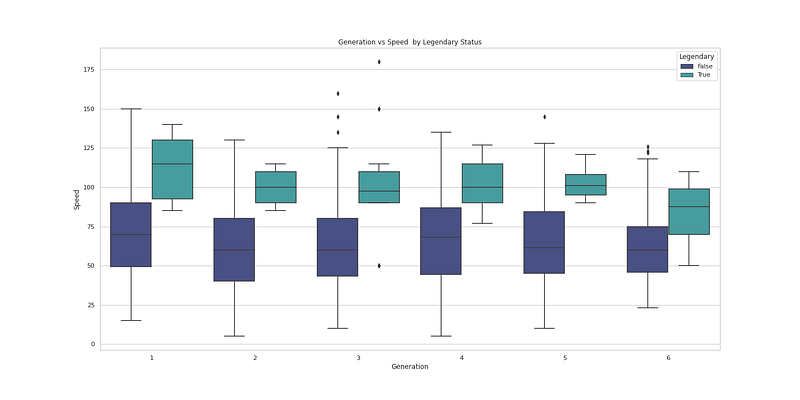
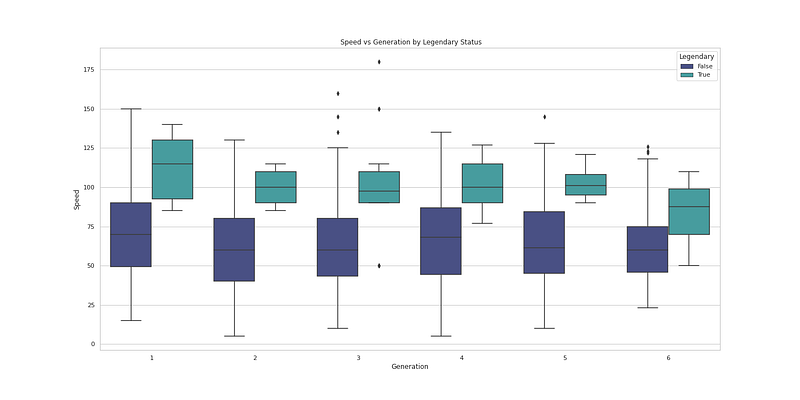
plt.figure(figsize=(20,10))
sns.boxplot(x="Generation", y="Speed", hue='Legendary', data=df, palette='mako')
plt.title('Generation vs Speed by Legendary Status')
plt.show()Output —
plt.figure(figsize=(20,10))
sns.boxplot(x="Generation", y="Total", hue='Legendary', data=df, palette='mako')
plt.title('Generation vs Total by Legendary Status')
plt.show()Output —
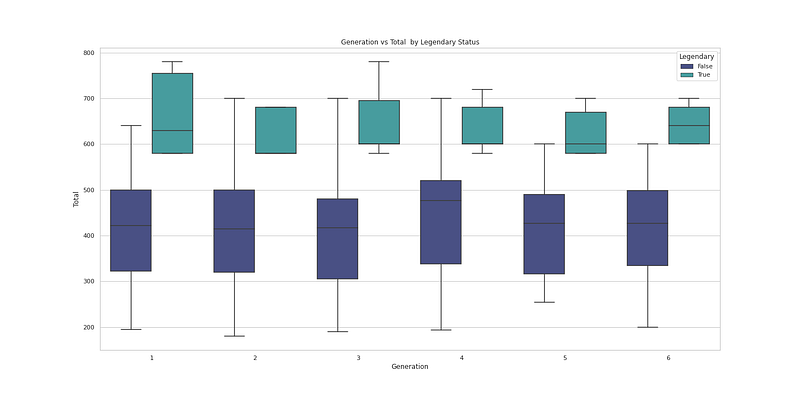
plt.figure(figsize=(20,10))
sns.boxplot(x="Generation", y="Attack", hue='Legendary', data=df, palette='mako')
plt.title('Generation vs Attack by Legendary Status')
plt.show()Output —
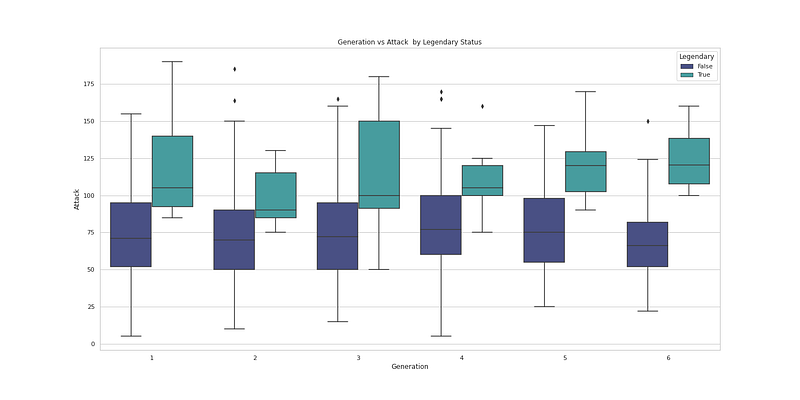
plt.figure(figsize=(20,10))
sns.boxplot(x="Generation", y="Defense", hue='Legendary', data=df, palette='mako')
plt.title('Generation vs Defense by Legendary Status')
plt.show()Output —
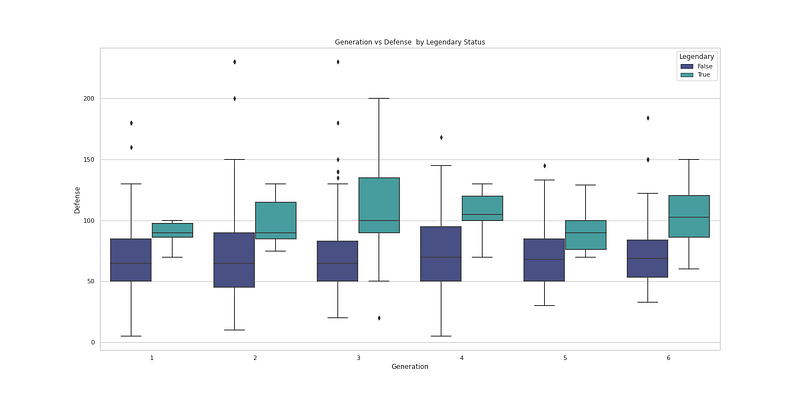
plt.figure(figsize=(20,10))
sns.boxplot(x="Type 1", y="Speed", hue='Legendary', data=df, palette='mako')
plt.title(' Speed vs Type 1 by Legendary Status')
plt.show()Output —
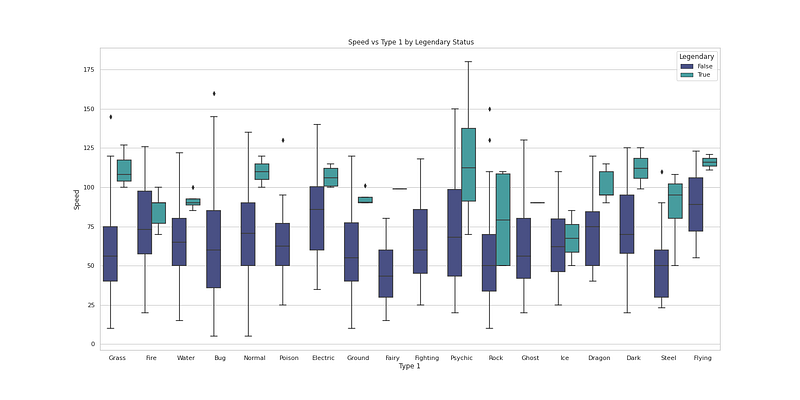
plt.figure(figsize=(20,10))
sns.boxplot(x="Generation", y="Speed", hue='Legendary', data=df, palette='mako')
plt.title(' Speed vs Generation by Legendary Status')
plt.show()Output —
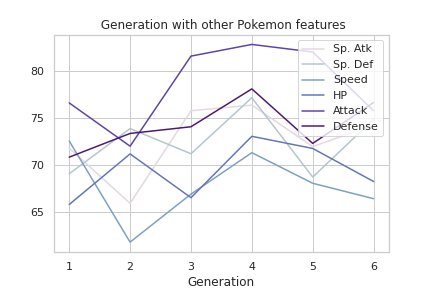
pg = df.groupby('Generation').mean()[['Sp. Atk', 'Sp. Def', 'Speed','HP', 'Attack', 'Defense' ]]
# Generation with other Pokemon features
plt.figure(figsize=(20,10))
pg.plot.line(color=colors1)
plt.title(' Generation with other Pokemon features')
plt.legend(loc='upper right')
plt.show()Output —
plt.figure(figsize=(50,30))
sns.pairplot(data=df,diag_kind = "kde",palette='mako',markers='o',size=7,hue = 'Legendary')
plt.show()Output —
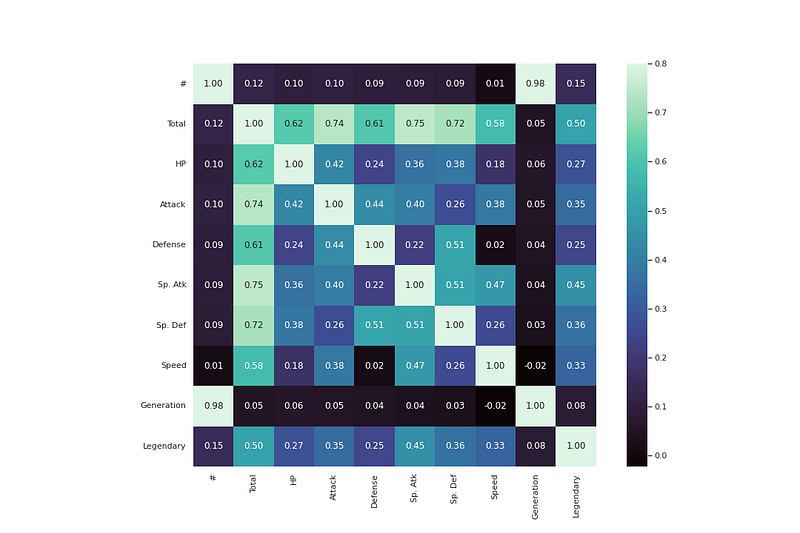
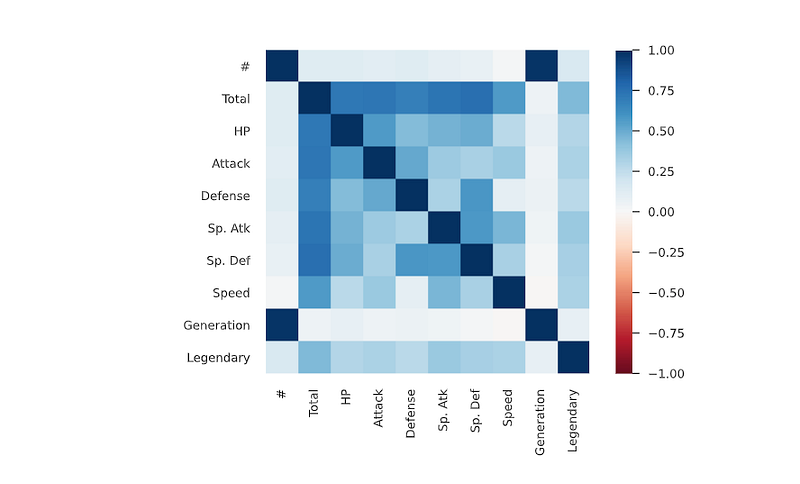
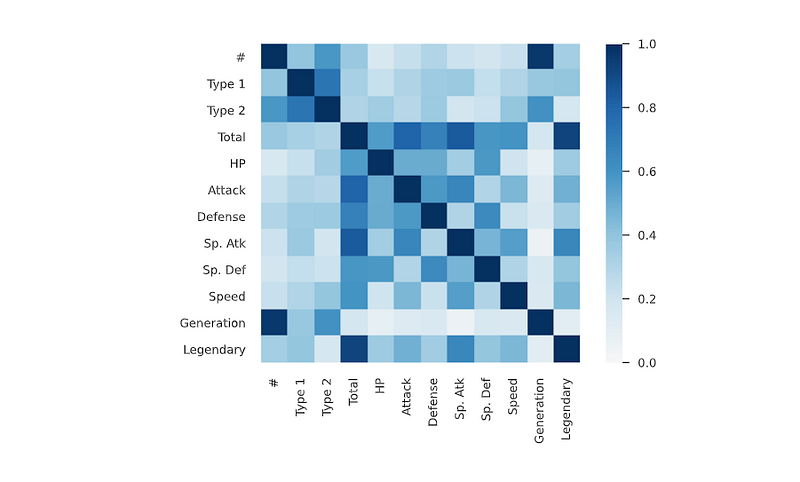
Correlation Analysis
In order to measure the strength of the linear association/relation between two variable, Correlation Analysis is used.
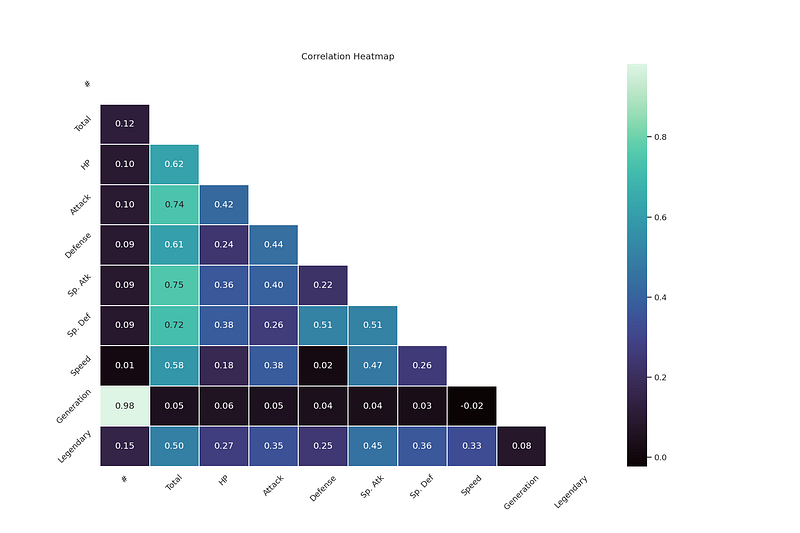
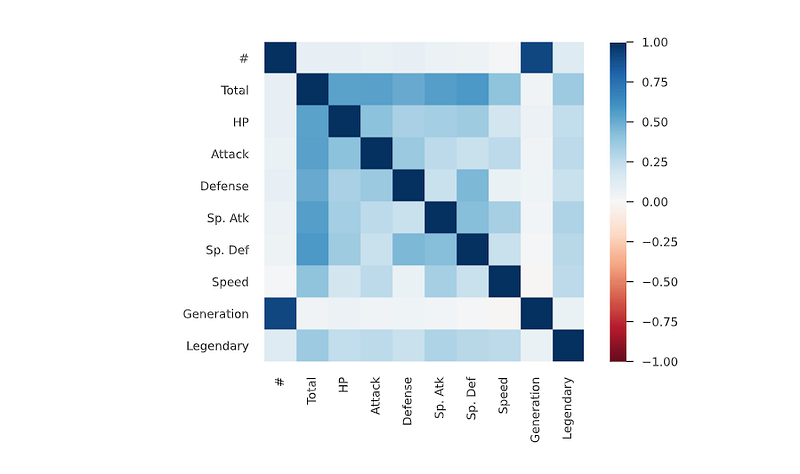
# heatmap correlation
corrmat = df.corr()
f, ax = plt.subplots(figsize=(15, 10))
sns.heatmap(corrmat, vmax=.8, square=True,annot=True,fmt=".2f",cmap='mako')
plt.show()Output —
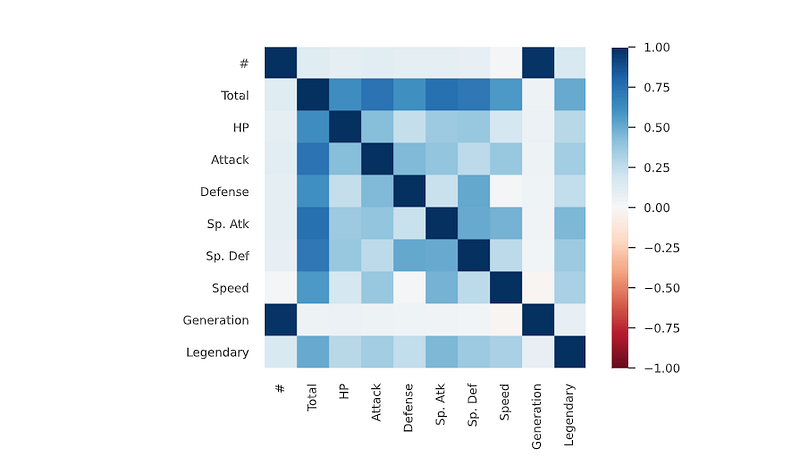
plt.figure(dpi = 120,figsize= (15,10))
mask = np.triu(np.ones_like(df.corr(),dtype = bool))
sns.heatmap(df.corr(),mask = mask, fmt = ".2f",annot=True,lw=1,cmap = 'mako')
plt.yticks(rotation = 45)
plt.xticks(rotation = 45)
plt.title('Correlation Heatmap')
plt.show()Output —
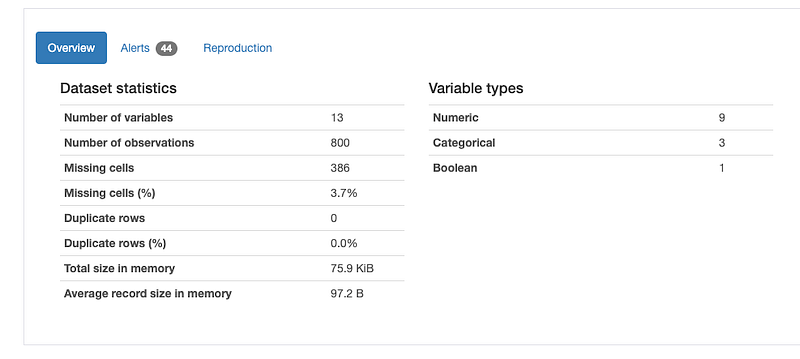
Data Profiling
It is used to generate profile reports from the input data.
The statistics include
Descriptive Statistics and Quantile Statistics.
Descriptive stats — Standard deviation, Kurtosis, mean, skewness, variance etc
Quantile Statistics — Min-max, percentiles, median, IQR etc
df.profile_report()Output —
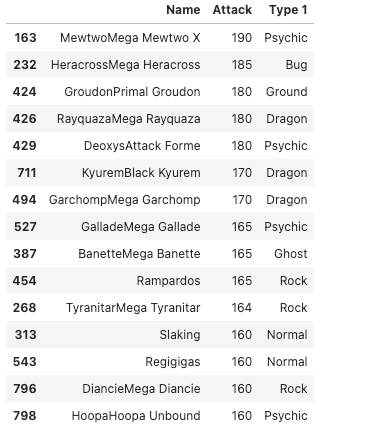
Sort Values
# Total Attack
df_da = df.sort_values(by='Attack',ascending=False)[:15][['Name','Attack','Type 1']]
df_daOutput —
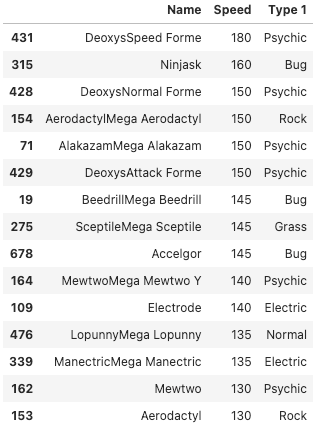
# Total Speed by different Pokemons
df_ds = df.sort_values(by='Speed',ascending=False)[:15][['Name','Speed','Type 1']]
df_dsOutput —
Linear Regression
It’s a technique to estimate the relationship between two quantitative variables. It is used when you want to establish:
- Strength of the relationship — How strong the relationship is between two variables
- The value of the dependent variable at a certain value of the independent variable.
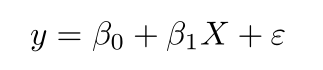
where,
y is the predicted value of the dependent variable for any given value of the independent variable which is X.
B0 is the intercept and B1 is the regression coefficient
x is the independent variable
e is the error of the estimate
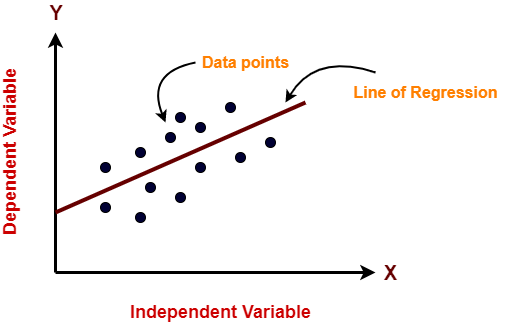
It works on the assumption that the relationship between the independent and dependent variable is linear: the line of best fit through the data points is a straight line as shown in the diagram.
reg_X = df.loc[:,"Attack":]
reg_y = pd.DataFrame(df.loc[:,"Total"])
X_train, X_test, y_train, y_test = train_test_split(pd.DataFrame(reg_X.loc[:,"Attack"]), reg_y,random_state = 0)
lr = LinearRegression().fit(X_train, y_train)
x = np.array(reg_X["Attack"])
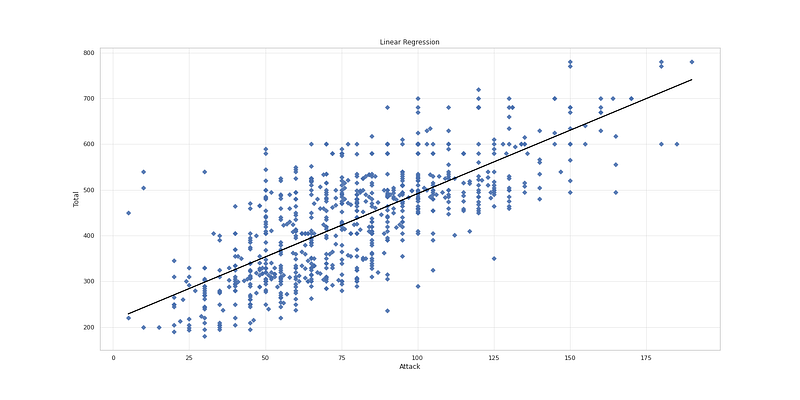
# Linear Regression
plt.figure(figsize=(20,10))
plt.scatter(reg_X.loc[:,"Attack"], reg_y, marker= 'D', s=30, alpha=0.9, cmap='Blue')
plt.plot(reg_X.loc[:,"Attack"], lr.intercept_+ lr.coef_ * x.reshape(-1,1) , 'black')
ax = plt.gca()
ax.xaxis.grid(True,alpha=0.4)
ax.yaxis.grid(True,alpha=0.4)
plt.title('Linear Regression')
plt.xlabel('Attack')
plt.ylabel('Total')
plt.show()Output —
Feature Engineering
In simple terms, feature engineering is the process of extracting features from the raw data. Here we will do a small demo —
first_name = df["Name"]
df["FName"] = [i.split(" ")[0].split(",")[-1].strip() for i in first_name]
df['FName']Output —
0 Bulbasaur
1 Ivysaur
2 Venusaur
3 VenusaurMega
4 Charmander
...
795 Diancie
796 DiancieMega
797 HoopaHoopa
798 HoopaHoopa
799 Volcanion
Name: FName, Length: 800, dtype: object# Character Name Percentage
plt.figure(figsize=(25,12))
p_r = df['FName'].value_counts().head(10)
plt.pie(x=p_r,labels=p_r.index,colors=colors1,autopct='%.0f%%',explode=[0.07 for i in p_r.index],startangle=120,wedgeprops={'linewidth':1,'edgecolor':'black'},shadow=True)
plt.title('Pokemon First Name Percentage ')
plt.legend(loc='upper right',title='Pokemon First Name')
plt.show()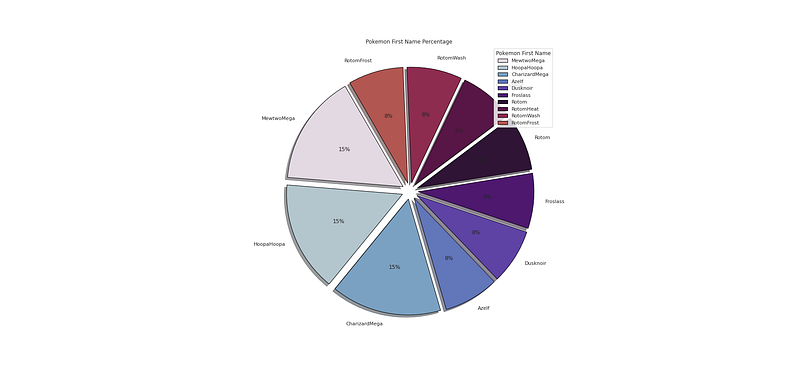
Correlation Coefficients
It’s the measure of the strength of the relationship between two variables.

Spearman’s ρ
The Spearman’s rank correlation coefficient (ρ) is a measure of monotonic correlation between two variables, and is therefore better in catching nonlinear monotonic correlations than Pearson’s r. It’s value lies between -1 and +1, -1 indicating total negative monotonic correlation, 0 indicating no monotonic correlation and 1 indicating total positive monotonic correlation.
To calculate ρ for two variables X and Y, one divides the covariance of the rank variables of X and Y by the product of their standard deviations.
Pearson’s r
The Pearson’s correlation coefficient (r) is a measure of linear correlation between two variables. It’s value lies between -1 and +1, -1 indicating total negative linear correlation, 0 indicating no linear correlation and 1 indicating total positive linear correlation. Furthermore, r is invariant under separate changes in location and scale of the two variables, implying that for a linear function the angle to the x-axis does not affect r.
To calculate r for two variables X and Y, one divides the covariance of X and Y by the product of their standard deviations.
Kendall’s τ
Similarly to Spearman’s rank correlation coefficient, the Kendall rank correlation coefficient (τ) measures ordinal association between two variables. It’s value lies between -1 and +1, -1 indicating total negative correlation, 0 indicating no correlation and 1 indicating total positive correlation.
To calculate τ for two variables X and Y, one determines the number of concordant and discordant pairs of observations. τ is given by the number of concordant pairs minus the discordant pairs divided by the total number of pairs.
Cramér’s V (φc)
Cramér’s V is an association measure for nominal random variables. The coefficient ranges from 0 to 1, with 0 indicating independence and 1 indicating perfect association. The empirical estimators used for Cramér’s V have been proved to be biased, even for large samples.
Phik (φk)
Phik (φk) is a new and practical correlation coefficient that works consistently between categorical, ordinal and interval variables, captures non-linear dependency and reverts to the Pearson correlation coefficient in case of a bivariate normal input distribution.
That’s it for now. Day 23 coming soon: Data Analysis : Project 9.
Let me know if you have questions in the comment section below. Subscribe/ Follow, Like/Clap as it would encourage me to write more in my free time
Stay Tuned!!
Read More —
11 most important System Design Base Concepts
6. Networking, How Browsers work, Content Network Delivery ( CDN)
13. System Design Template — How to solve any System Design Question
System Design Case Studies — In Depth
Complete Data Structures and Algorithm Series
Some of the other best Series —
30 days of Data Structures and Algorithms and System Design Simplified
Data Science and Machine Learning Research ( papers) Simplified **
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Exceptional Github Repos — Part 1
Exceptional Github Repos — Part 2
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding!
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras




