Free AI web copilot to create summaries, insights and extended knowledge, download it at here
35510
Abstract
<span class="hljs-number">0</span> Clothing ID <span class="hljs-number">23486</span> non-<span class="hljs-literal">null</span> int64
<span class="hljs-number">1</span> Age <span class="hljs-number">23486</span> non-<span class="hljs-literal">null</span> int64
<span class="hljs-number">2</span> Title <span class="hljs-number">19676</span> non-<span class="hljs-literal">null</span> <span class="hljs-keyword">object</span>
<span class="hljs-number">3</span> Review Text <span class="hljs-number">22641</span> non-<span class="hljs-literal">null</span> <span class="hljs-keyword">object</span>
<span class="hljs-number">4</span> Rating <span class="hljs-number">23486</span> non-<span class="hljs-literal">null</span> int64
<span class="hljs-number">5</span> Recommended IND <span class="hljs-number">23486</span> non-<span class="hljs-literal">null</span> int64
<span class="hljs-number">6</span> Positive Feedback Count <span class="hljs-number">23486</span> non-<span class="hljs-literal">null</span> int64
<span class="hljs-number">7</span> Division Name <span class="hljs-number">23472</span> non-<span class="hljs-literal">null</span> <span class="hljs-keyword">object</span>
<span class="hljs-number">8</span> Department Name <span class="hljs-number">23472</span> non-<span class="hljs-literal">null</span> <span class="hljs-keyword">object</span>
<span class="hljs-number">9</span> Class Name <span class="hljs-number">23472</span> non-<span class="hljs-literal">null</span> <span class="hljs-keyword">object</span>
dtypes: int64(<span class="hljs-number">5</span>), <span class="hljs-keyword">object</span>(<span class="hljs-number">5</span>)
memory usage: <span class="hljs-number">2.0</span>+ MB</pre></div><div id="f529"><pre><span class="hljs-comment"># Missing Values</span>
df.isna().<span class="hljs-built_in">sum</span>()</pre></div><p id="3d74">Output —</p><div id="04da"><pre>Clothing ID <span class="hljs-number">0</span>
Age <span class="hljs-number">0</span>
Title <span class="hljs-number">3810</span>
Review <span class="hljs-keyword">Text</span> <span class="hljs-number">845</span>
Rating <span class="hljs-number">0</span>
Recommended IND <span class="hljs-number">0</span>
Positive Feedback Count <span class="hljs-number">0</span>
Division Name <span class="hljs-number">14</span>
Department Name <span class="hljs-number">14</span>
<span class="hljs-keyword">Class</span> Name <span class="hljs-number">14</span>
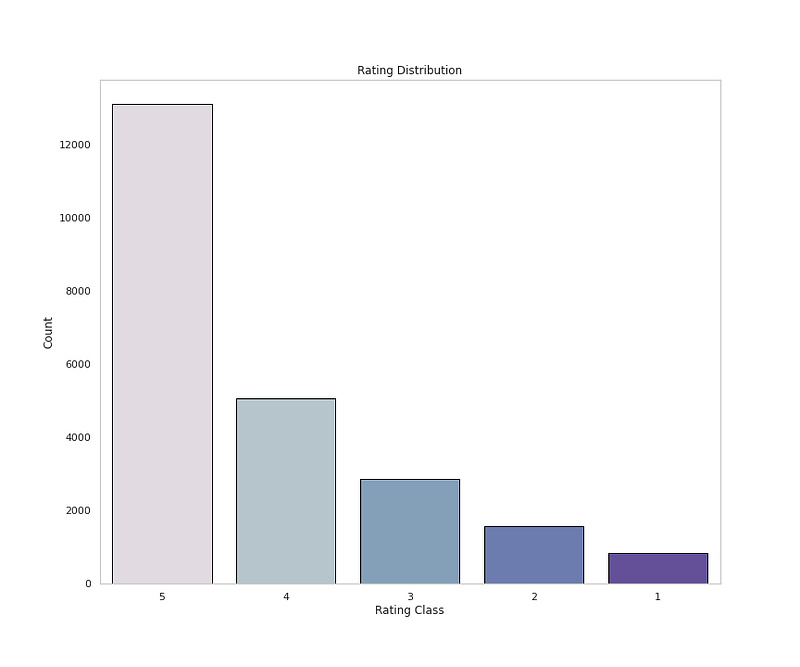
<span class="hljs-symbol">dtype:</span> int64</pre></div><div id="0e8c"><pre><span class="hljs-comment"># See the stats</span></pre></div><div id="70f3"><pre>df<span class="hljs-selector-class">.describe</span>()<span class="hljs-selector-class">.T</span></pre></div><div id="0b5c"><pre># <span class="hljs-keyword">Get</span> <span class="hljs-keyword">unique</span> <span class="hljs-keyword">Values</span></pre></div><div id="3bda"><pre>df<span class="hljs-selector-class">.Rating</span><span class="hljs-selector-class">.value_counts</span>()</pre></div><p id="595a">Output —</p><div id="400d"><pre><span class="hljs-number">5</span> <span class="hljs-number">13131</span>
<span class="hljs-number">4</span> <span class="hljs-number">5077</span>
<span class="hljs-number">3</span> <span class="hljs-number">2871</span>
<span class="hljs-number">2</span> <span class="hljs-number">1565</span>
<span class="hljs-number">1</span> <span class="hljs-number">842</span>
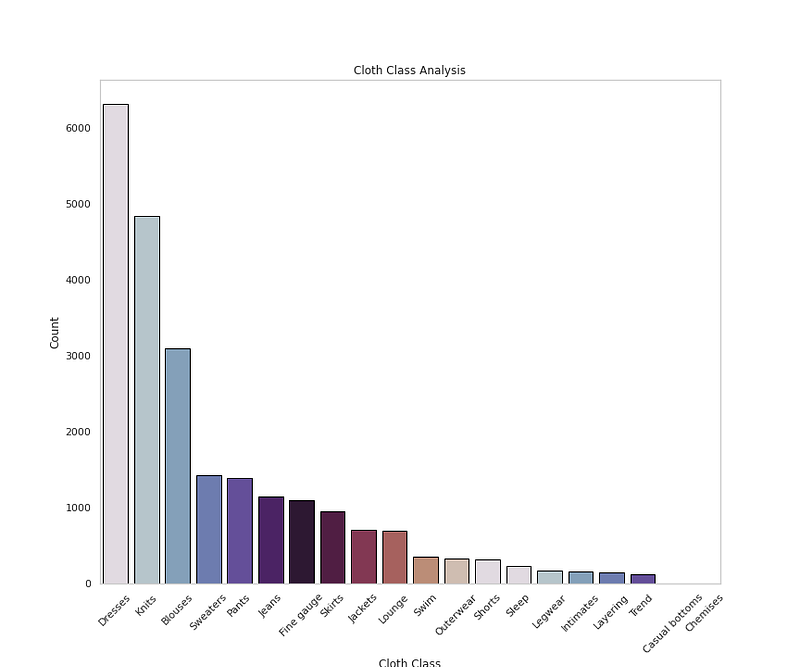
<span class="hljs-attr">Name:</span> <span class="hljs-string">Rating,</span> <span class="hljs-attr">dtype:</span> <span class="hljs-string">int64</span></pre></div><div id="3fdf"><pre><span class="hljs-comment"># Get Class name Counts</span></pre></div><div id="2539"><pre>df<span class="hljs-selector-attr">[<span class="hljs-string">'Class Name'</span>]</span><span class="hljs-selector-class">.value_counts</span>()</pre></div><p id="ceb4">Output —</p><div id="9860"><pre><span class="hljs-string">Dresses</span> <span class="hljs-number">6319</span>
<span class="hljs-string">Knits</span> <span class="hljs-number">4843</span>
<span class="hljs-string">Blouses</span> <span class="hljs-number">3097</span>
<span class="hljs-string">Sweaters</span> <span class="hljs-number">1428</span>
<span class="hljs-string">Pants</span> <span class="hljs-number">1388</span>
<span class="hljs-string">Jeans</span> <span class="hljs-number">1147</span>
<span class="hljs-string">Fine</span> <span class="hljs-string">gauge</span> <span class="hljs-number">1100</span>
<span class="hljs-string">Skirts</span> <span class="hljs-number">945</span>
<span class="hljs-string">Jackets</span> <span class="hljs-number">704</span>
<span class="hljs-string">Lounge</span> <span class="hljs-number">691</span>
<span class="hljs-string">Swim</span> <span class="hljs-number">350</span>
<span class="hljs-string">Outerwear</span> <span class="hljs-number">328</span>
<span class="hljs-string">Shorts</span> <span class="hljs-number">317</span>
<span class="hljs-string">Sleep</span> <span class="hljs-number">228</span>
<span class="hljs-string">Legwear</span> <span class="hljs-number">165</span>
<span class="hljs-string">Intimates</span> <span class="hljs-number">154</span>
<span class="hljs-string">Layering</span> <span class="hljs-number">146</span>
<span class="hljs-string">Trend</span> <span class="hljs-number">119</span>
<span class="hljs-string">Casual</span> <span class="hljs-string">bottoms</span> <span class="hljs-number">2</span>
<span class="hljs-string">Chemises</span> <span class="hljs-number">1</span>
<span class="hljs-attr">Name:</span> <span class="hljs-string">Class</span> <span class="hljs-string">Name,</span> <span class="hljs-attr">dtype:</span> <span class="hljs-string">int64</span></pre></div><div id="3ec6"><pre><span class="hljs-comment"># Get Count of Department Name</span></pre></div><div id="0813"><pre>df<span class="hljs-selector-attr">[<span class="hljs-string">'Department Name'</span>]</span><span class="hljs-selector-class">.value_counts</span>()</pre></div><p id="9144">Output —</p><div id="713d"><pre><span class="hljs-string">Tops</span> <span class="hljs-number">10468</span>
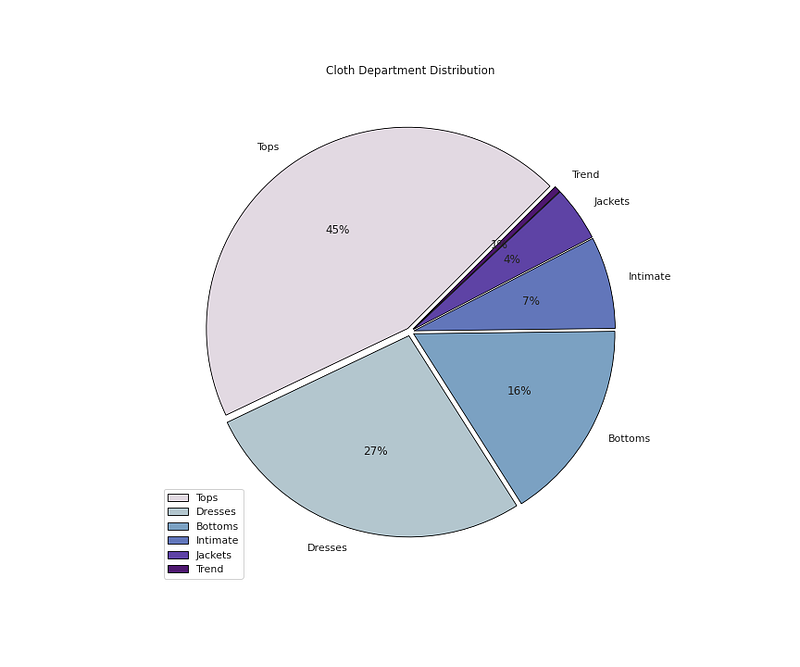
<span class="hljs-string">Dresses</span> <span class="hljs-number">6319</span>
<span class="hljs-string">Bottoms</span> <span class="hljs-number">3799</span>
<span class="hljs-string">Intimate</span> <span class="hljs-number">1735</span>
<span class="hljs-string">Jackets</span> <span class="hljs-number">1032</span>
<span class="hljs-string">Trend</span> <span class="hljs-number">119</span>
<span class="hljs-attr">Name:</span> <span class="hljs-string">Department</span> <span class="hljs-string">Name,</span> <span class="hljs-attr">dtype:</span> <span class="hljs-string">int64</span></pre></div><h2 id="c4b1">Data Visualization</h2><div id="a12a"><pre><span class="hljs-comment"># Cloth Department Analysis</span></pre></div><div id="b2ed"><pre>plt.figure(figsize=(10,10))
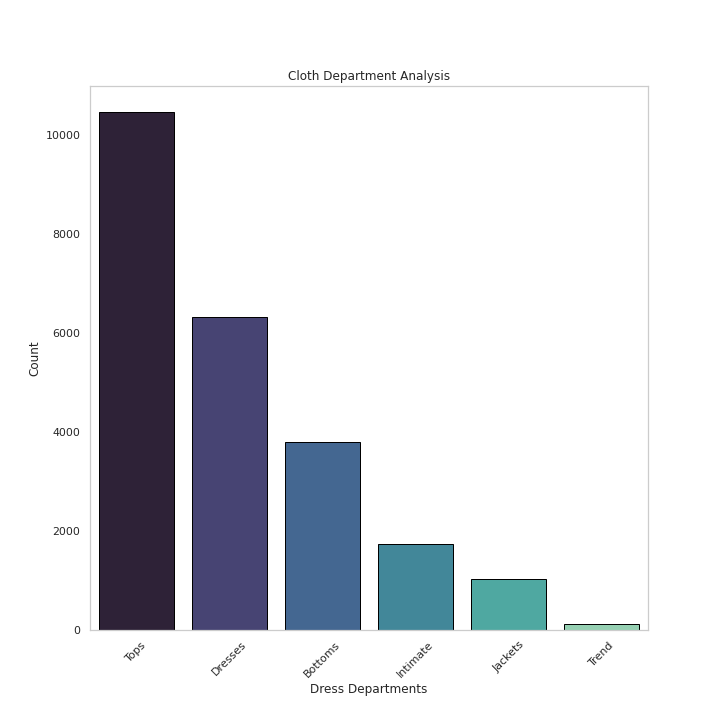
sns.countplot(x=<span class="hljs-string">'Department Name'</span>,data=<span class="hljs-built_in">df</span>,palette=<span class="hljs-string">'mako'</span>,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Department Name'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.xlabel(<span class="hljs-string">'Dress Departments'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Department Analysis'</span>)
plt.grid(False)</pre></div><div id="1fe2"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="30ed">Output —</p><figure id="c5b4"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*F3w3A9Up00L_xiPbY1XQxw.png"><figcaption></figcaption></figure><div id="0e1b"><pre><span class="hljs-comment"># Cloth Department by Ratings</span></pre></div><div id="9620"><pre>plt.figure(figsize=(12,10))
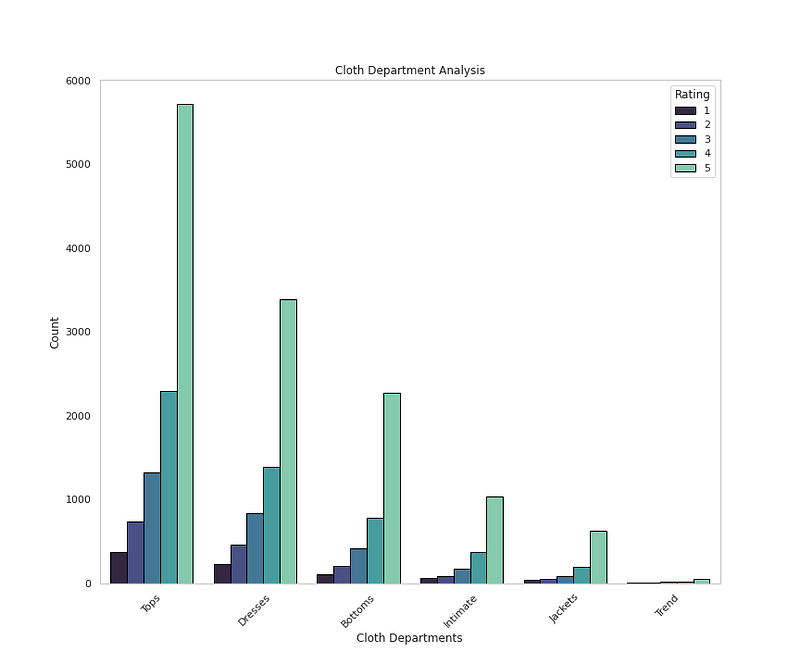
sns.countplot(x=<span class="hljs-string">'Department Name'</span>,data=<span class="hljs-built_in">df</span>,palette=<span class="hljs-string">'mako'</span>,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Department Name'</span>].value_counts().index,hue=<span class="hljs-string">'Rating'</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.xlabel(<span class="hljs-string">'Cloth Departments'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Department Analysis'</span>)
plt.grid(False)</pre></div><div id="a8ff"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="974e">Output —</p><figure id="99e5"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*2t0ugz8r7H_ZFVslPw8pTA.png"><figcaption></figcaption></figure><div id="5e6b"><pre><span class="hljs-comment"># Cloth Department by Age, Department and Recommendation</span></pre></div><div id="1007"><pre>plt.figure(figsize=(12,10))
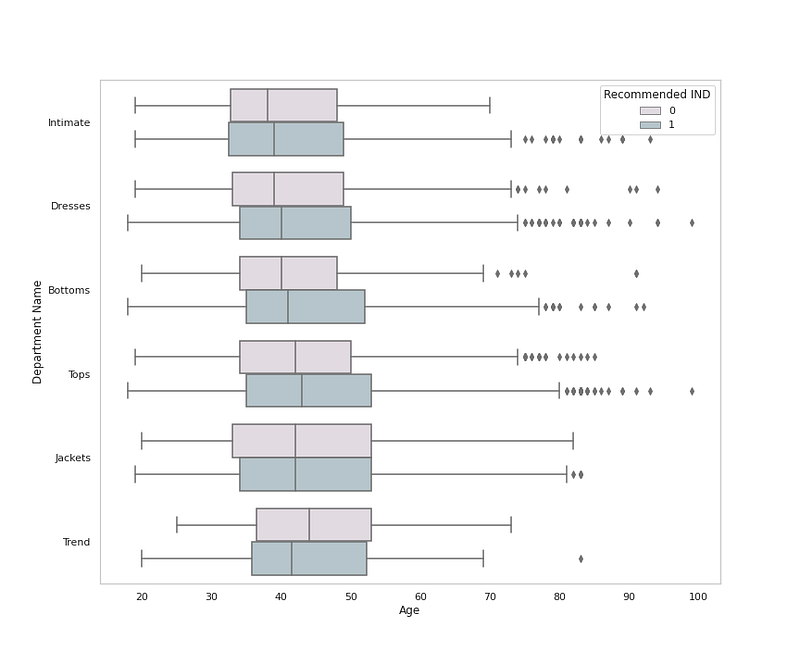
sns.boxplot(x = <span class="hljs-string">'Age'</span>, y = <span class="hljs-string">'Department Name'</span>, data = <span class="hljs-built_in">df</span>,palette=colors1,hue=<span class="hljs-string">'Recommended IND'</span>)
plt.grid(False)</pre></div><div id="654a"><pre>plt.title<span class="hljs-comment">('Cloth Department by Age and Recommendation ')</span>
plt.show<span class="hljs-comment">()</span></pre></div><p id="a83f">Output —</p><figure id="18e0"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*nvueFmBjiT1j-5s6PTu4EA.png"><figcaption></figcaption></figure><div id="9841"><pre><span class="hljs-comment"># Cloth Department Distribution</span></pre></div><div id="3a59"><pre>plt.figure(figsize=(12,10))
plt.pie(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Department Name'</span>].value_counts().values,data=<span class="hljs-built_in">df</span>,colors=colors1,labels=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Department Name'</span>].value_counts().index,autopct=<span class="hljs-string">'%.0f%%'</span>,explode=[0.02 <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">df</span>[<span class="hljs-string">'Department Name'</span>].value_counts().index],startangle=45,wedgeprops={<span class="hljs-string">'linewidth'</span>:0.8,<span class="hljs-string">'edgecolor'</span>:<span class="hljs-string">'black'</span>})
plt.title(<span class="hljs-string">'Cloth Department Distribution'</span>)
plt.legend(loc=<span class="hljs-string">'lower left'</span>)</pre></div><div id="f7f0"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="bd39">Output —</p><figure id="b96b"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*gdRckYuef62hbNi2rheRFQ.png"><figcaption></figcaption></figure><div id="c556"><pre># Cloth <span class="hljs-keyword">Class</span> <span class="hljs-keyword">by</span> Age, Department <span class="hljs-built_in">and</span> Recommendation</pre></div><div id="e8b7"><pre>plt.figure(figsize=(12,10))
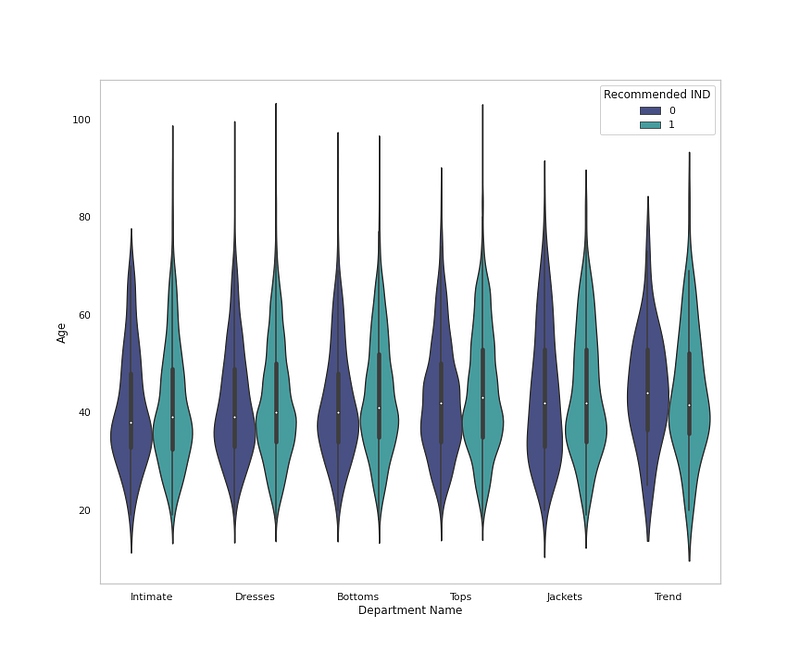
sns.violinplot(x = <span class="hljs-string">'Department Name'</span>, y = <span class="hljs-string">'Age'</span>, data = <span class="hljs-built_in">df</span>,palette=<span class="hljs-string">'mako'</span>,hue=<span class="hljs-string">'Recommended IND'</span>,orient=<span class="hljs-string">'v'</span>)
plt.grid(False)</pre></div><div id="a8a6"><pre>plt.title<span class="hljs-comment">('Cloth Department by Age and Recommendation ')</span>
plt.show<span class="hljs-comment">()</span></pre></div><p id="7bb5">Output —</p><figure id="ac97"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*YAkZXteLXfbKN7-sIR_02g.png"><figcaption></figcaption></figure><div id="340f"><pre><span class="hljs-comment"># Cloth Class Analysis</span></pre></div><div id="39e8"><pre>plt.figure(figsize=(12,10))
sns.countplot(x=<span class="hljs-string">'Class Name'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.xlabel(<span class="hljs-string">'Cloth Class'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Class Analysis'</span>)
plt.grid(False)</pre></div><div id="830c"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="014b">Output —</p><figure id="85ab"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*TcEYrVhxC335pKob4KxXbA.png"><figcaption></figcaption></figure><div id="c452"><pre><span class="hljs-comment"># Cloth Class Analysis by Rating</span></pre></div><div id="f90d"><pre>plt.figure(figsize=(22,12))
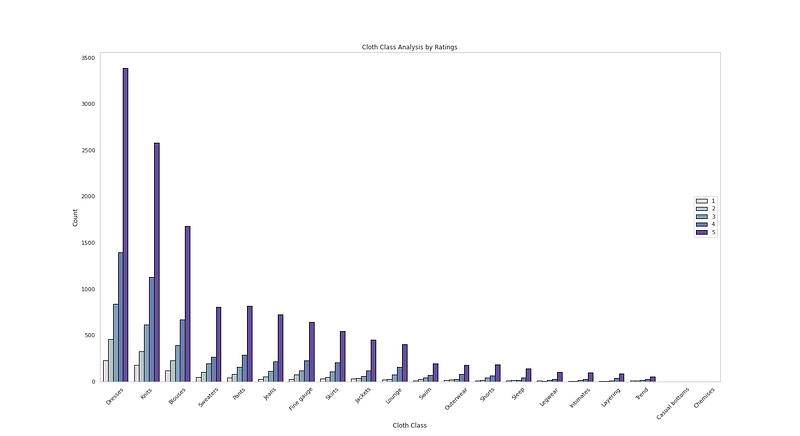
sns.countplot(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>],data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1,hue=<span class="hljs-string">'Rating'</span>)
plt.xlabel(<span class="hljs-string">'Cloth Class'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Class Analysis by Ratings'</span>)
plt.grid(False)
plt.legend(loc=<span class="hljs-string">'right'</span>)</pre></div><div id="5c9b"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="2251">Output —</p><figure id="4a39"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*mVZUCfTxzypBbI4C3qhfTw.png"><figcaption></figcaption></figure><div id="cebf"><pre><span class="hljs-comment"># Cloth Class Distribution</span></pre></div><div id="e5bd"><pre>plt.figure(figsize=(18,15))
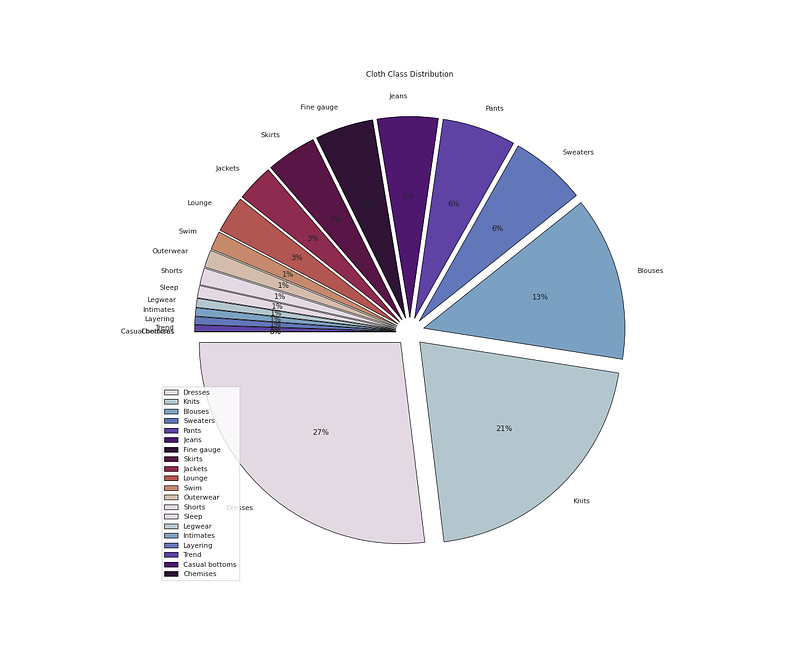
plt.pie(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>].value_counts().values,data=<span class="hljs-built_in">df</span>,colors=colors1,labels=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>].value_counts().index,autopct=<span class="hljs-string">'%.0f%%'</span>,explode=[0.07 <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">df</span>[<span class="hljs-string">'Class Name'</span>].value_counts().index],startangle=180,wedgeprops={<span class="hljs-string">'linewidth'</span>:0.8,<span class="hljs-string">'edgecolor'</span>:<span class="hljs-string">'black'</span>})
plt.title(<span class="hljs-string">'Cloth Class Distribution'</span>)
<span class="hljs-comment">#plt.grid(False)</span>
plt.legend(loc=<span class="hljs-string">'lower left'</span>)</pre></div><div id="ed09"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="bfbe">Output —</p><figure id="3db4"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*POnBvIeSf3enLYEk2_jqgw.png"><figcaption></figcaption></figure><div id="a800"><pre># Cloth <span class="hljs-keyword">Class</span> <span class="hljs-keyword">by</span> Age, Department <span class="hljs-built_in">and</span> Recommendation</pre></div><div id="65f8"><pre>plt.figure(figsize=(12,10))
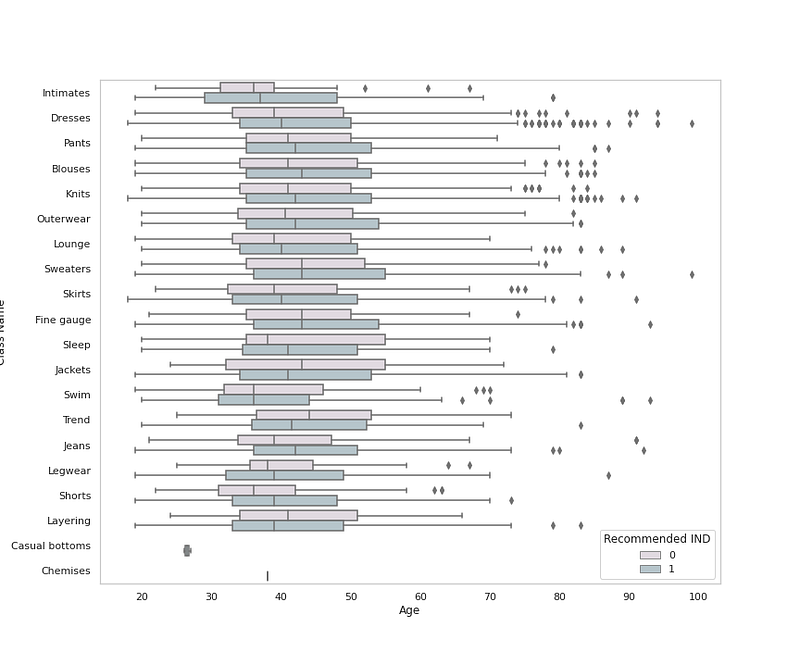
sns.boxplot(x = <span class="hljs-string">'Age'</span>, y = <span class="hljs-string">'Class Name'</span>, data = <span class="hljs-built_in">df</span>,palette=colors1,hue=<span class="hljs-string">'Recommended IND'</span>)
plt.grid(False)</pre></div><div id="dbb8"><pre>plt.title<span class="hljs-comment">('Cloth Class by Age and Recommendation ')</span>
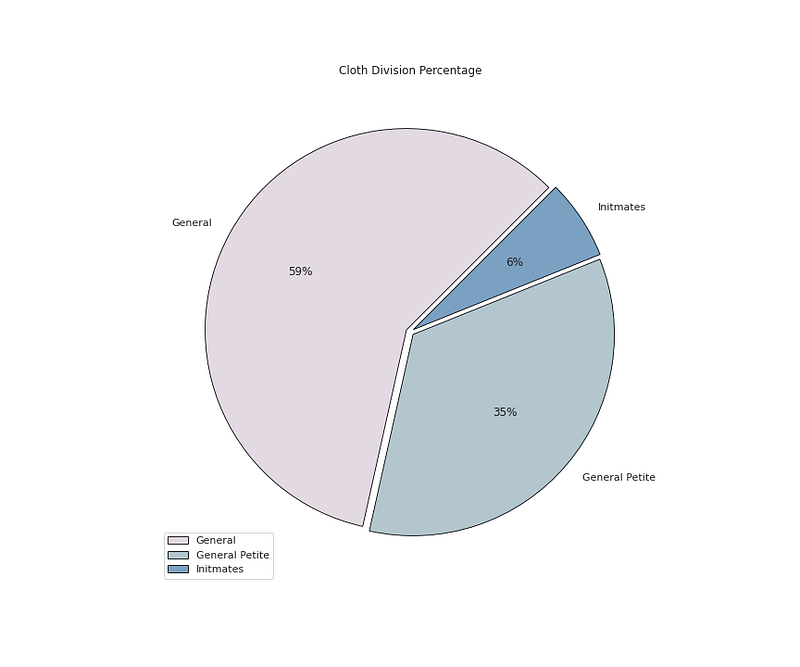
plt.show<span class="hljs-comment">()</span></pre></div><p id="20f5">Output —</p><figure id="54ea"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*iLXAWVHLVuW9j1aBiwGOCA.png"><figcaption></figcaption></figure><div id="e486"><pre><span class="hljs-comment"># Division Value Counts</span></pre></div><div id="e52d"><pre>df<span class="hljs-selector-attr">[<span class="hljs-string">'Division Name'</span>]</span><span class="hljs-selector-class">.value_counts</span>()</pre></div><p id="72dd">Output —</p><div id="a2dc"><pre><span class="hljs-string">General</span> <span class="hljs-number">13839</span>
<span class="hljs-string">General</span> <span class="hljs-string">Petite</span> <span class="hljs-number">8110</span>
<span class="hljs-string">Initmates</span> <span class="hljs-number">1502</span>
<span class="hljs-attr">Name:</span> <span class="hljs-string">Division</span> <span class="hljs-string">Name,</span> <span class="hljs-attr">dtype:</span> <span class="hljs-string">int64</span></pre></div><div id="4d69"><pre><span class="hljs-comment"># Cloth Division Analysis by Department</span></pre></div><div id="ce78"><pre>plt.figure(figsize=(12,10))
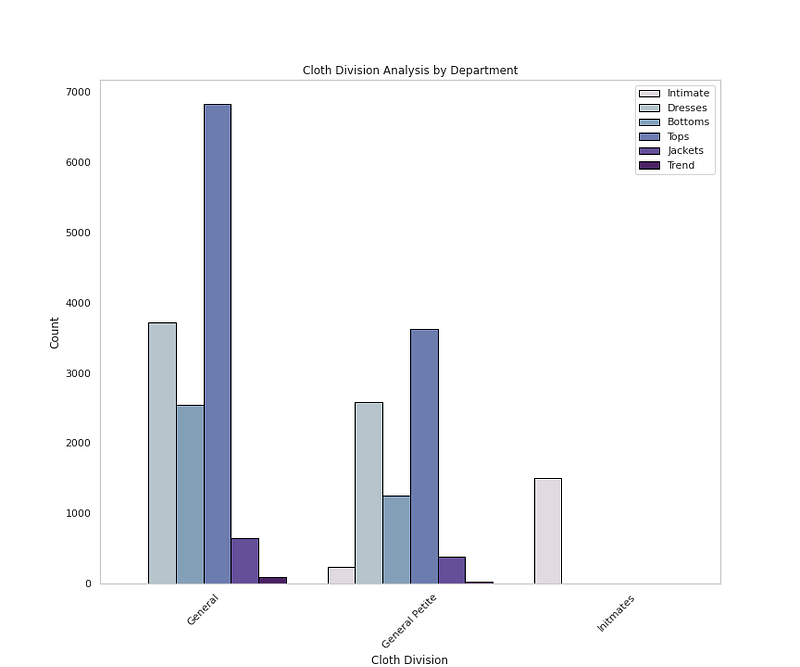
sns.countplot(x=<span class="hljs-string">'Division Name'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Division Name'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1,hue=<span class="hljs-string">'Department Name'</span>)
plt.xlabel(<span class="hljs-string">'Cloth Division'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Division Analysis by Department'</span>)
plt.grid(False)
plt.legend(loc=<span class="hljs-string">'upper right'</span>)</pre></div><div id="9b46"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="f336">Output —</p><figure id="d2b7"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*f435BEP3NK5WIOL7FG6kkA.png"><figcaption></figcaption></figure><div id="1039"><pre><span class="hljs-comment"># Cloth Division by Rating</span></pre></div><div id="828b"><pre>plt.figure(figsize=(12,10))
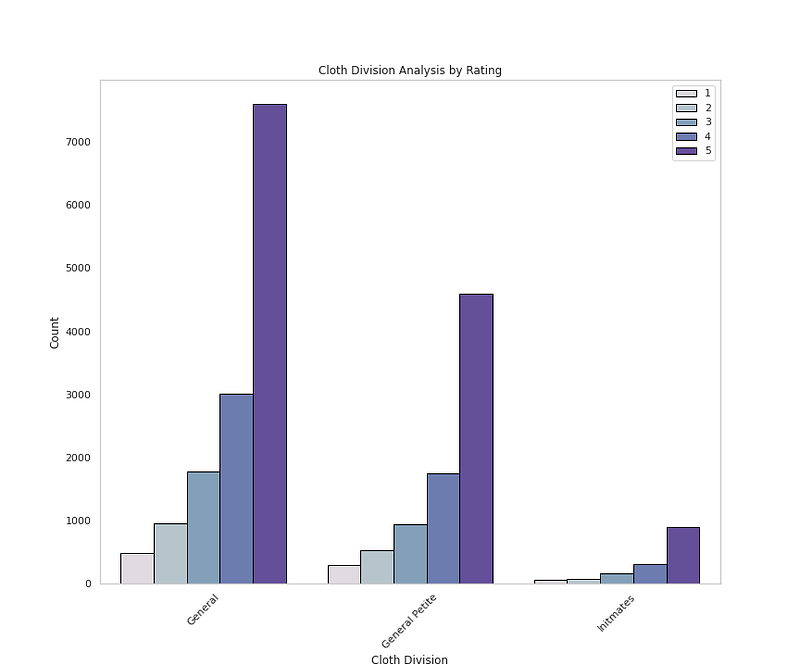
sns.countplot(x=<span class="hljs-string">'Division Name'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Division Name'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1,hue=<span class="hljs-string">'Rating'</span>)
plt.xlabel(<span class="hljs-string">'Cloth Division'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)
plt.xticks(rotation=45)
plt.title(<span class="hljs-string">'Cloth Division Analysis by Rating'</span>)
plt.grid(False)
plt.legend(loc=<span class="hljs-string">'upper right'</span>)</pre></div><div id="a2d8"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="dca7">Output —</p><figure id="8b6f"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*HRgk-HGj_fYWIj5Z9dUKYg.png"><figcaption></figcaption></figure><div id="2aca"><pre><span class="hljs-comment"># Cloth Division Percentage</span></pre></div><div id="1287"><pre>plt.figure(figsize=(12,10))
plt.pie(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Division Name'</span>].value_counts().values,data=<span class="hljs-built_in">df</span>,colors=colors1,labels=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Division Name'</span>].value_counts().index,autopct=<span class="hljs-string">'%.0f%%'</span>,explode=[0.02 <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">df</span>[<span class="hljs-string">'Division Name'</span>].value_counts().index],startangle=45,wedgeprops={<span class="hljs-string">'linewidth'</span>:0.8,<span class="hljs-string">'edgecolor'</span>:<span class="hljs-string">'black'</span>})</pre></div><div id="9dc2"><pre>plt.title(<span class="hljs-string">'Cloth Division Percentage'</span>)</pre></div><div id="5b54"><pre>plt<span class="hljs-selector-class">.legend</span>()
plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="2cc3">Output —</p><figure id="9705"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*CWMDakpD9f1nMotonzRdtw.png"><figcaption></figcaption></figure><div id="4a34"><pre><span class="hljs-comment"># Cloth Division Name by Age</span></pre></div><div id="bd25"><pre>plt.figure(figsize=(12,10))
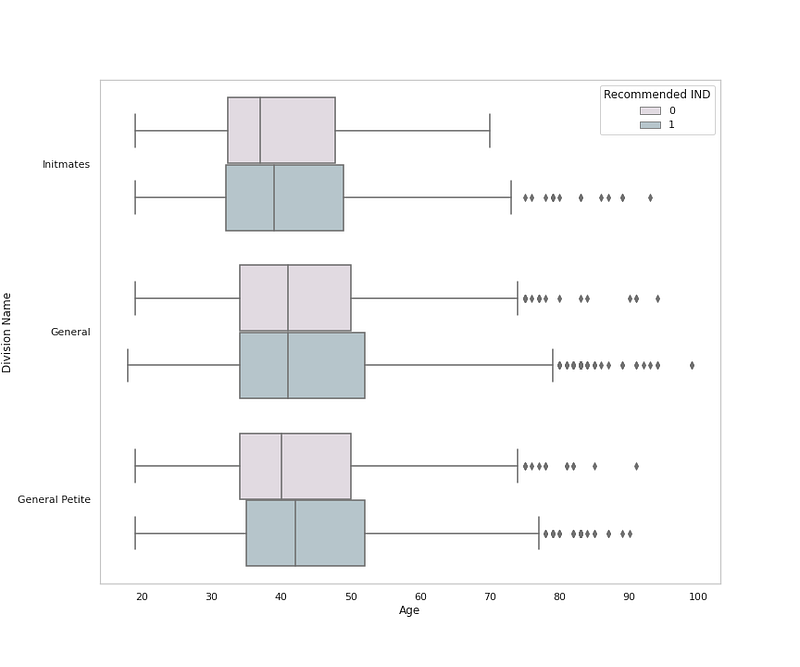
sns.boxplot(x = <span class="hljs-string">'Age'</span>, y = <span class="hljs-string">'Division Name'</span>, data = <span class="hljs-built_in">df</span>,palette=colors1,hue=<span class="hljs-string">'Recommended IND'</span>)
plt.grid(False)</pre></div><div id="dee3"><pre>plt.title<span class="hljs-comment">('Cloth Division by Age and Recommendation ')</span>
plt.show<span class="hljs-comment">()</span></pre></div><p id="493b">Output —</p><figure id="781b"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*Bs8ITpKy9u5AsO48YC-X1A.png"><figcaption></figcaption></figure><div id="bd0e"><pre><span class="hljs-comment"># Rating by Age</span></pre></div><div id="a863"><pre>plt.figure(figsize=(12,10))
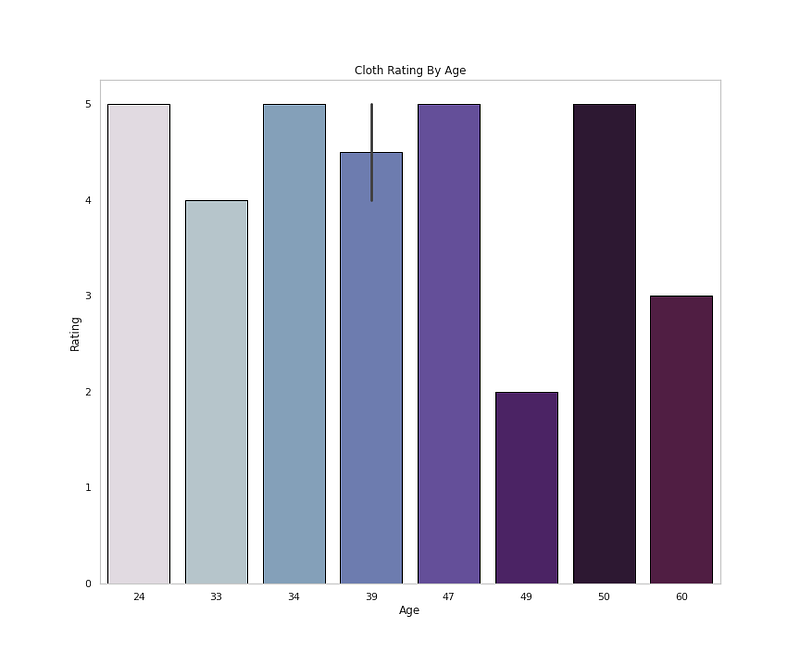
sns.barplot(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Age'</span>].<span class="hljs-built_in">head</span>(10),y=<span class="hljs-string">'Rating'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.title(<span class="hljs-string">'Cloth Rating By Age'</span>)
plt.grid(False)</pre></div><div id="940e"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="31fa">Output —</p><figure id="3f91"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*Htw1v2jJ8s1iNT3WRQOGDw.png"><figcaption></figcaption></figure><div id="e902"><pre><span class="hljs-comment"># Rating Distribution</span></pre></div><div id="5444"><pre>plt.figure(figsize=(12,10))
sns.countplot(x=<span class="hljs-string">'Rating'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Rating'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.xlabel(<span class="hljs-string">'Rating Class'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)</pre></div><div id="c3ae"><pre>plt.title(<span class="hljs-string">'Rating Distribution'</span>)
plt.grid(<span class="hljs-literal">False</span>)</pre></div><div id="ae6d"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="e01f">Output —</p><figure id="2b83"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*78u8WQaoUtvuKOGbyezwfw.png"><figcaption></figcaption></figure><div id="9ebf"><pre><span class="hljs-comment"># Rating Percentage</span></pre></div><div id="9031"><pre>plt.figure(figsize=(12,10))
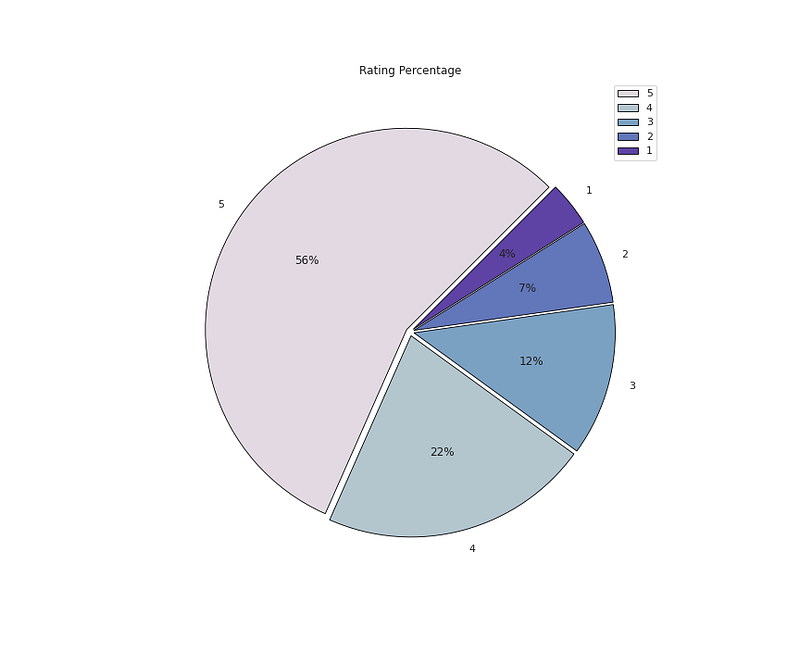
plt.pie(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Rating'</span>].value_counts().values,data=<span class="hljs-built_in">df</span>,colors=colors1,labels=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Rating'</span>].value_counts().index,autopct=<span class="hljs-string">'%.0f%%'</span>,explode=[0.02 <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">df</span>[<span class="hljs-string">'Rating'</span>].value_counts().index],startangle=45,wedgeprops={<span class="hljs-string">'linewidth'</span>:0.8,<span class="hljs-string">'edgecolor'</span>:<span class="hljs-string">'black'</span>})
plt.title(<span class="hljs-string">'Rating Percentage'</span>)
plt.legend()</pre></div><div id="e799"><pre>plt.<span class="hljs-keyword">show</span>()</pre></div><p id="0a51">Output —</p><figure id="5686"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*ep-3m5tGSAMhWEOBZ8j2SA.png"><figcaption></figcaption></figure><div id="843c"><pre><span class="hljs-comment"># Rating Distribution by Age</span></pre></div><div id="ebed"><pre>plt.figure(figsize=(12,10))
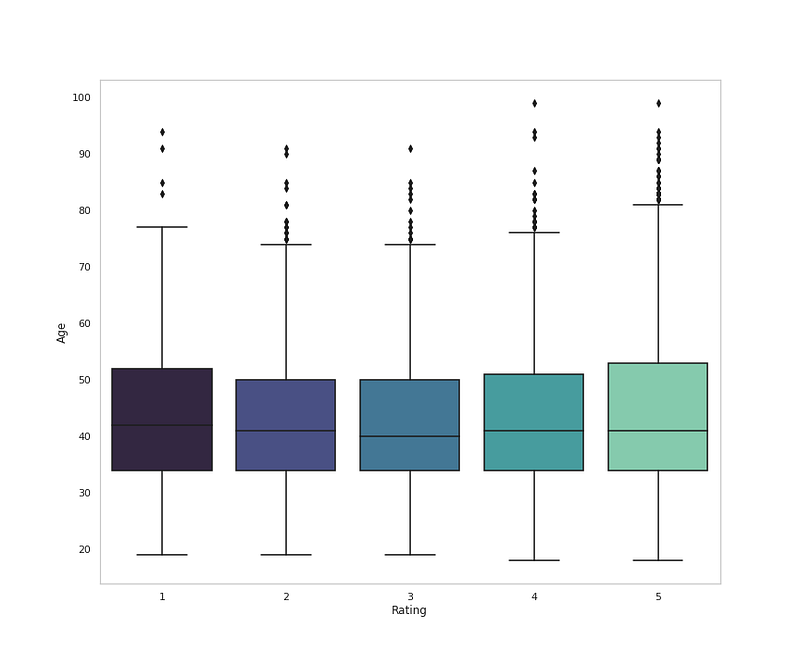
sns.boxplot(x = <span class="hljs-string">'Rating'</span>, y = <span class="hljs-string">'Age'</span>, data = <span class="hljs-built_in">df</span>,palette=<span class="hljs-string">'mako'</span>)
plt.grid(False)</pre></div><div id="9356"><pre>plt<span class="hljs-selector-class">.title</span>(<span class="hljs-string">'Rating Distribution by Age'</span>)
plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="8c42">Output —</p><figure id="988f"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*kp17auvubGMxNE-vaL9ekw.png"><figcaption></figcaption></figure><div id="305f"><pre><span class="hljs-comment"># Age Distribution</span></pre></div><div id="f046"><pre>plt<span class="hljs-selector-class">.figure</span>(figsize=(<span class="hljs-number">12</span>,<span class="hljs-number">10</span>))</pre></div><div id="206f"><pre>plt.hist(<span class="hljs-built_in">df</span>[<span class="hljs-string">'Age'</span>], bins=40,color=<span class="hljs-string">'#CBC3E3'</span>,edgecolor=<span class="hljs-string">'black'</span>)
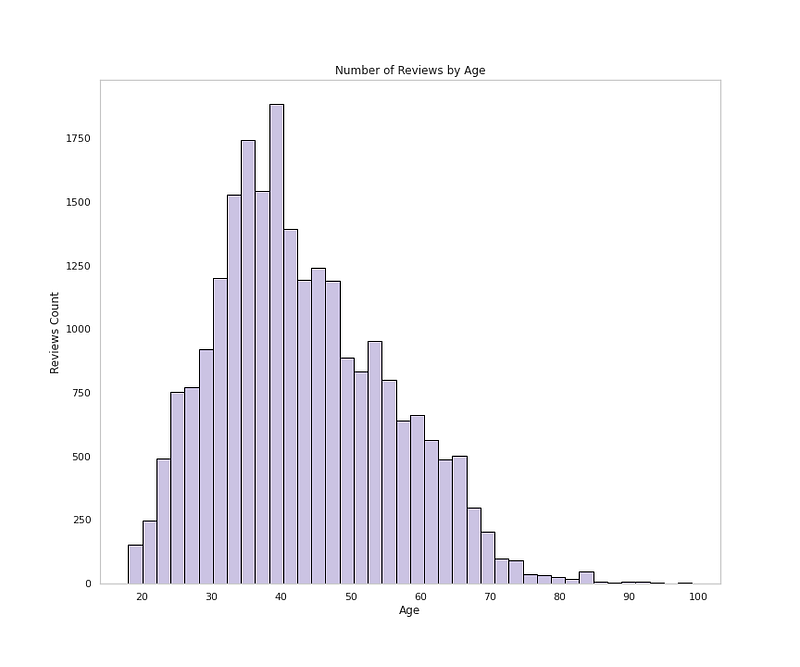
plt.xlabel(<span class="hljs-string">'Age'</span>)
plt.ylabel(<span class="hljs-string">'Reviews Count'</span>)
plt.grid(False)
plt.title(<span class="hljs-string">'Number of Reviews by Age'</span>)
plt.show()</pre></div><p id="8341">Output —</p><figure id="3931"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*Z2tKux78TIYgfHzRVxTAuA.png"><figcaption></figcaption></figure><h2 id="8101">Load the data</h2><div id="d089"><pre><span class="hljs-comment"># Cloth Recommendation Analysis</span></pre></div><div id="ea7e"><pre>df<span class="hljs-selector-attr">[<span class="hljs-string">'Recommended IND'</span>]</span><span class="hljs-selector-class">.value_counts</span>()</pre></div><p id="f97c">Output —</p><div id="383c"><pre><span class="hljs-number">1</span> <span class="hljs-number">19293</span>
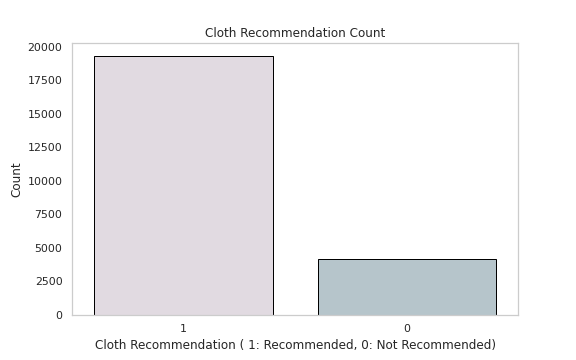
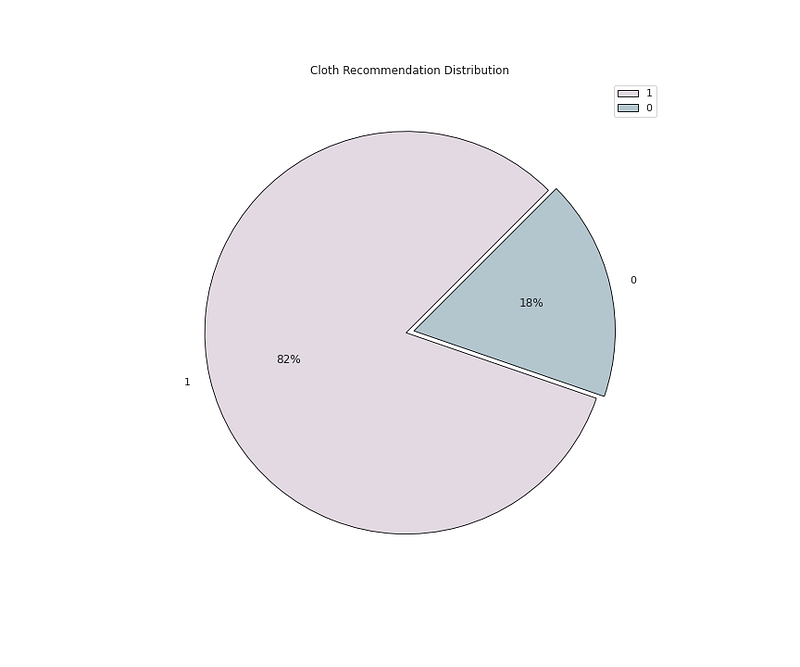
<span class="hljs-number">0</span> <span class="hljs-number">4172</span>
<span class="hljs-attr">Name:</span> <span class="hljs-string">Recommended</span> <span class="hljs-string">IND,</span> <span class="hljs-attr">dtype:</span> <span class="hljs-string">int64</span></pre></div><div id="8e10"><pre><span class="hljs-comment"># Cloth Recommendation Count</span></pre></div><div id="fbf9"><pre>plt.figure(figsize=(8,5))
sns.countplot(x=<span class="hljs-string">'Recommended IND'</span>,data=<span class="hljs-built_in">df</span>,palette=colors1,order=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>].value_counts().index,edgecolor=<span class="hljs-string">'black'</span>,linewidth=1)
plt.xlabel(<span class="hljs-string">'Cloth Recommendation ( 1: Recommended, 0: Not Recommended)'</span>)
plt.ylabel(<span class="hljs-string">'Count'</span>)</pre></div><div id="bcee"><pre>plt<span class="hljs-selector-class">.title</span>('Cloth Recommendation Count')
plt<span class="hljs-selector-class">.grid</span>(False)
plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="5ba5">Output —</p><figure id="af10"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*SA8wiEIol_3EUjPXxlsGYw.png"><figcaption></figcaption></figure><div id="6ff1"><pre><span class="hljs-comment"># Recommendation Distribution ( 1 means recommended and 0 means not # Recommended by the Customer)</span></pre></div><div id="7be9"><pre>plt.figure(figsize=(12,10))
plt.pie(x=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>].value_counts().values,data=<span class="hljs-built_in">df</span>,colors=colors1,labels=<span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>].value_counts().index,autopct=<span class="hljs-string">'%.0f%%'</span>,explode=[0.02 <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>].value_counts().index],startangle=45,wedgeprops={<span class="hljs-string">'linewidth'</span>:0.8,<span class="hljs-string">'edgecolor'</span>:<span class="hljs-string">'black'</span>})
plt.title(<span class="hljs-string">'Cloth Recommendation Distribution'</span>)
plt.legend()
plt.show()</pre></div><p id="765f">Output —</p><figure id="009c"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*qnkYmpvD0quM8l6hv4XKFA.png"><figcaption></figcaption></figure><div id="1d1e"><pre><span class="hljs-comment"># recommendation Analysis ( 1 means recommended and 0 means not Recommended by the Customer)</span></pre></div><div id="a5c5"><pre>r = <span class="hljs-built_in">df</span>[<span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>]==1]
not_r= <span class="hljs-built_in">df</span>[<span class="hljs-built_in">df</span>[<span class="hljs-string">'Recommended IND'</span>]==0]</pre></div><div id="0d31"><pre><span class="hljs-comment"># Plot Cloth Recommendation by Cloth Department, Division, Class</span></pre></div><div id="534c"><pre><span class="hljs-attr">fig</span> = plt.figure(figsize=(<span class="hljs-number">20</span>, <span class="hljs-number">15</span>))
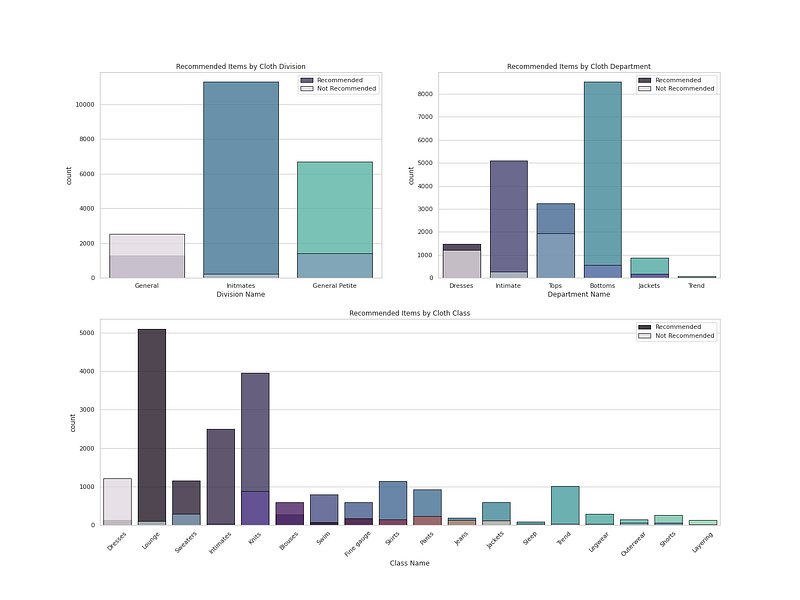
<span class="hljs-attr">ax1</span> = plt.subplot2grid((<span class="hljs-number">2</span>, <span class="hljs-number">2</span>), (<span class="hljs-number">0</span>, <span class="hljs-number">0</span>))
<span class="hljs-attr">ax1</span> = sns.countplot(r[<span class="hljs-string">'Division Name'</span>], palette =<span class="hljs-string">'mako'</span>, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax1</span> = sns.countplot(not_r[<span class="hljs-string">'Division Name'</span>], palette = colors1, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Not Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax1</span> = plt.title(<span class="hljs-string">"Recommended Items by Cloth Division"</span>)
<span class="hljs-attr">ax1</span> = plt.legend()</pre></div><div id="aadd"><pre><span class="hljs-attr">ax2</span> = plt.subplot2grid((<span class="hljs-number">2</span>, <span class="hljs-number">2</span>), (<span class="hljs-number">0</span>, <span class="hljs-number">1</span>))
<span class="hljs-attr">ax2</span> = sns.countplot(r[<span class="hljs-string">'Department Name'</span>], palette =<span class="hljs-string">'mako'</span>, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax2</span> = sns.countplot(not_r[<span class="hljs-string">'Department Name'</span>], palette =colors1, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Not Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax2</span> = plt.title(<span class="hljs-string">"Recommended Items by Cloth Department"</span>)
<span class="hljs-attr">ax2</span> = plt.legend()</pre></div><div id="c8c4"><pre><span class="hljs-attr">ax3</span> = plt.subplot2grid((<span class="hljs-number">2</span>, <span class="hljs-number">2</span>), (<span class="hljs-number">1</span>, <span class="hljs-number">0</span>), colspan=<span class="hljs-number">2</span>)
<span class="hljs-attr">ax3</span> = plt.xticks(rotation=<span class="hljs-number">45</span>)
<span class="hljs-attr">ax3</span> = sns.countplot(r[<span class="hljs-string">'Class Name'</span>], palette =<span class="hljs-string">'mako'</span>, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax3</span> = sns.countplot(not_r[<span class="hljs-string">'Class Name'</span>], palette =colors1, alpha = <span class="hljs-number">0.8</span>, label = <span class="hljs-string">"Not Recommended"</span>,edgecolor=<span class="hljs-string">'black'</span>,linewidth=<span class="hljs-number">1</span>)
<span class="hljs-attr">ax3</span> = plt.title(<span class="hljs-string">"Recommended Items by Cloth Class"</span>)
<span class="hljs-attr">ax3</span> = plt.legend()</pre></div><div id="b7c0"><pre>plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="e62e">Output —</p><figure id="838c"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*HJ_4YqLuLWxpj6xNFtUVVA.png"><figcaption></figcaption></figure><div id="722b"><pre><span class="hljs-comment"># heatmap</span></pre></div><div id="a5a6"><pre>plt.figure(figsize<span class="hljs-operator">=</span>(<span class="hljs-number">8</span>,<span class="hljs-number">6</span>))
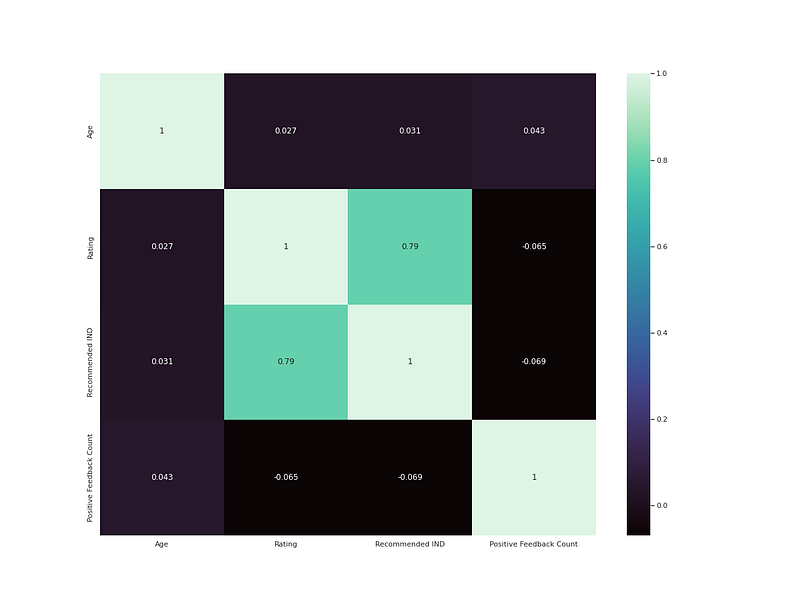
h <span class="hljs-operator">=</span> df.drop(<span class="hljs-string">'Clothing ID'</span>,axis<span class="hljs-operator">=</span><span class="hljs-number">1</span>).<span class="hljs-built_in">corr</span>()
sns.heatmap(h,annot<span class="hljs-operator">=</span><span class="hljs-literal">True</span>,cmap<span class="hljs-operator">=</span><span class="hljs-string">'mako'</span>)
plt.show()</pre></div><p id="a4ee">Output —</p><figure id="728d"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*0i7fytjXx7c8H5KNBJFZUg.png"><figcaption></figcaption></figure><div id="db36"><pre><span class="hljs-comment"># Tokenizing the reviews</span></pre></div><div id="6068"><pre>def <span class="hljs-built_in">tokens</span>(words):
words = re.<span class="hljs-built_in">sub</span>(<span class="hljs-string">"[^a-zA-Z]"</span>,<span class="hljs-string">" "</span>, words)
text = words.<span class="hljs-built_in">lower</span>().<span class="hljs-built_in">split</span>()
return <span class="hljs-string">" "</span>.<span class="hljs-built_in">join</span>(text)
df[<span class="hljs-string">'Review Text'</span>] = df[<span class="hljs-string">'Review Text'</span>].<span class="hljs-built_in">astype</span>(str)
df[<span class="hljs-string">'Final_Reviews'</span>] = df[<span class="hljs-string">'Review Text'</span>].<span class="hljs-built_in">apply</span>(tokens)</pre></div><div id="399d"><pre><span class="hljs-comment"># Use the Stop words</span></pre></div><div id="5a1c"><pre><span class="hljs-attr">sw</span> = stopwords.words(<span class="hljs-string">'english'</span>)</pre></div><div id="958e"><pre>clothes <span class="hljs-operator">=</span>[<span class="hljs-string">'skirt'</span>,<span class="hljs-string">'pants'</span>,<span class="hljs-string">'white'</span>,<span class="hljs-string">'black'</span>,<span class="hljs-string">'fabric'</span>,<span class="hljs-string">'silky'</span>,<span class="hljs-string">'leather'</span>,<span class="hljs-string">'blouse'</span>,<span class="hljs-string">'sleeve'</span>,<span class="hljs-string">'even'</span>,<span class="hljs-string">'jacket'</span>,<span class="
Options
hljs-string">'dress'</span>,<span class="hljs-string">'color'</span>,<span class="hljs-string">'wear'</span>,<span class="hljs-string">'top'</span>,<span class="hljs-string">'sweater'</span>,<span class="hljs-string">'material'</span>,<span class="hljs-string">'shirt'</span>,<span class="hljs-string">'jeans'</span>,<span class="hljs-string">'pant'</span>]
def stopwords(review):
text <span class="hljs-operator">=</span> [word.<span class="hljs-built_in">lower</span>() <span class="hljs-keyword">for</span> word <span class="hljs-keyword">in</span> review.split() if word.<span class="hljs-built_in">lower</span>() <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> sw <span class="hljs-keyword">and</span> word.<span class="hljs-built_in">lower</span>() <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> clothes]
<span class="hljs-keyword">return</span> " ".<span class="hljs-keyword">join</span>(text)
df[<span class="hljs-string">'Final_Reviews'</span>] <span class="hljs-operator">=</span> df[<span class="hljs-string">'Final_Reviews'</span>].apply(stopwords)</pre></div><div id="2ccf"><pre><span class="hljs-comment"># Lemmatize</span>
<span class="hljs-keyword">from</span> nltk.stem.wordnet <span class="hljs-keyword">import</span> WordNetLemmatizer
lm = WordNetLemmatizer()</pre></div><div id="e163"><pre>def <span class="hljs-built_in">lemma</span>(text):
lem_text = [lm.<span class="hljs-built_in">lemmatize</span>(word) for word in text.<span class="hljs-built_in">split</span>()]
return <span class="hljs-string">" "</span>.<span class="hljs-built_in">join</span>(lem_text)
df[<span class="hljs-string">'Final_Reviews'</span>] = df[<span class="hljs-string">'Final_Reviews'</span>].<span class="hljs-built_in">apply</span>(lemma)</pre></div><div id="549f"><pre><span class="hljs-comment"># Seperating Positive and Negative Reviews</span></pre></div><div id="5d42"><pre><span class="hljs-attr">nw</span> = []
<span class="hljs-attr">pw</span> =[]
<span class="hljs-attr">pos</span> = df[df[<span class="hljs-string">'Recommended IND'</span>]== <span class="hljs-number">1</span>]
<span class="hljs-attr">neg</span> = df[df[<span class="hljs-string">'Recommended IND'</span>]== <span class="hljs-number">0</span>]</pre></div><div id="c43b"><pre>for r in neg<span class="hljs-selector-class">.Final_Reviews</span>:
nw.<span class="hljs-built_in">append</span>(r)
nw = <span class="hljs-string">' '</span>.<span class="hljs-built_in">join</span>(nw)</pre></div><div id="996b"><pre>for r in pos<span class="hljs-selector-class">.Final_Reviews</span>:
pw.<span class="hljs-built_in">append</span>(r)
pw = <span class="hljs-string">' '</span>.<span class="hljs-built_in">join</span>(pw)</pre></div><div id="d2f1"><pre><span class="hljs-comment"># Wordcloud of Negative Reivews</span></pre></div><div id="d60e"><pre><span class="hljs-attr">wordcloud</span> = WordCloud(background_color=<span class="hljs-string">"white"</span>, max_words=len(nw),width=<span class="hljs-number">500</span>, height=<span class="hljs-number">480</span>, max_font_size=<span class="hljs-number">60</span>, min_font_size=<span class="hljs-number">10</span>,colormap=<span class="hljs-string">'rocket'</span>)</pre></div><div id="3f4d"><pre>wordcloud<span class="hljs-selector-class">.generate</span>(nw)</pre></div><div id="7d42"><pre>plt<span class="hljs-selector-class">.figure</span>(figsize=(<span class="hljs-number">20</span>,<span class="hljs-number">17</span>))
plt<span class="hljs-selector-class">.imshow</span>(wordcloud, interpolation="bilinear")
plt<span class="hljs-selector-class">.axis</span>("off")
plt<span class="hljs-selector-class">.margins</span>(x=<span class="hljs-number">0</span>, y=<span class="hljs-number">0</span>)
plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="9eb4">Output —</p><figure id="e76c"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*Wk8rk4c3t_sVpFoi1XJh-w.png"><figcaption></figcaption></figure><div id="0413"><pre><span class="hljs-comment"># Word Cloud of positive Reviews</span></pre></div><div id="7399"><pre><span class="hljs-attr">wordcloud</span> = WordCloud(background_color=<span class="hljs-string">"white"</span>, max_words=len(pw),width=<span class="hljs-number">500</span>, height=<span class="hljs-number">480</span>, max_font_size=<span class="hljs-number">60</span>, min_font_size=<span class="hljs-number">10</span>,colormap=<span class="hljs-string">'mako'</span>)</pre></div><div id="026d"><pre>wordcloud<span class="hljs-selector-class">.generate</span>(pw)</pre></div><div id="65ce"><pre>plt<span class="hljs-selector-class">.figure</span>(figsize=(<span class="hljs-number">20</span>,<span class="hljs-number">17</span>))
plt<span class="hljs-selector-class">.imshow</span>(wordcloud, interpolation="bilinear")
plt<span class="hljs-selector-class">.axis</span>("off")
plt<span class="hljs-selector-class">.margins</span>(x=<span class="hljs-number">0</span>, y=<span class="hljs-number">0</span>)
plt<span class="hljs-selector-class">.show</span>()</pre></div><p id="639d">Output —</p><figure id="dcae"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/1*9-kyKgkNDaMlQaJ7hgd10g.png"><figcaption></figcaption></figure><div id="3d5f"><pre><span class="hljs-comment"># Building Model</span></pre></div><div id="1262"><pre><span class="hljs-attr">X</span> = pos[<span class="hljs-string">'Final_Reviews'</span>]
<span class="hljs-attr">y</span> = pos[<span class="hljs-string">'Recommended IND'</span>]</pre></div><div id="ee97"><pre>X_train, X_test, y_train, y_test = <span class="hljs-title function_">train_test_split</span>(X, y, test_size=<span class="hljs-number">0.3</span>, random_state = <span class="hljs-number">42</span>)</pre></div><div id="2da1"><pre><span class="hljs-comment"># Count Vectorizer</span></pre></div><div id="5376"><pre><span class="hljs-attr">v</span> = CountVectorizer(min_df=<span class="hljs-number">7</span>, ngram_range=(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>)).fit(X_train)
<span class="hljs-attr">X_tv</span> = v.transform(X_train)</pre></div><h2 id="f8d7">Naive Bayes —</h2><p id="4c54">These are classification algorithms based on Bayes’ Theorem. They are extremely fast for both training and prediction and provide probabilistic prediction. Multinomial NB is used for discrete counts.</p><p id="fd09">The formula for Bayes’ theorem is given as:</p><figure id="3205"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/0*9w51ji7fsre6Ex3F.png"><figcaption></figcaption></figure><p id="a372">Bayes’s theorem tells us how to express this in terms of quantities we can calculate more directly:</p><blockquote id="7a03"><p>P(L | features)=P(features | L)P(L)P(features)</p></blockquote><p id="8402">Examples include spam filtration, Sentimental analysis, and classifying articles.</p><div id="26a6"><pre><span class="hljs-comment"># Naive Bayes</span></pre></div><div id="0443"><pre><span class="hljs-attr">model_nb</span> = Pipeline([(<span class="hljs-string">'v'</span>, CountVectorizer(min_df=<span class="hljs-number">7</span>, ngram_range=(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>))),(<span class="hljs-string">'tfidf'</span>, TfidfTransformer()),(<span class="hljs-string">'clf'</span>,MultinomialNB())])</pre></div><div id="c368"><pre>model_nb<span class="hljs-selector-class">.fit</span>(X_train, y_train)</pre></div><div id="98f5"><pre>ytest = np.<span class="hljs-keyword">array</span>(y_test)
pred_nb = model_nb.<span class="hljs-title function_ invoke__">predict</span>(X_test)
<span class="hljs-keyword">print</span>(<span class="hljs-string">'accuracy %s'</span> % <span class="hljs-title function_ invoke__">accuracy_score</span>(pred_nb, y_test))
<span class="hljs-keyword">print</span>(<span class="hljs-string">'Confusion Matrix:'</span>,<span class="hljs-title function_ invoke__">confusion_matrix</span>(y_test, pred_nb))
<span class="hljs-keyword">print</span>(<span class="hljs-title function_ invoke__">classification_report</span>(ytest, pred_y))</pre></div><p id="929c">Output —</p><div id="adba"><pre><span class="hljs-string">accuracy</span> <span class="hljs-number">1.0</span>
<span class="hljs-attr">Confusion Matrix:</span> [[<span class="hljs-number">5788</span>]]
<span class="hljs-string">precision</span> <span class="hljs-string">recall</span> <span class="hljs-string">f1-score</span> <span class="hljs-string">support</span>
<span class="hljs-number">1</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">accuracy</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">macro</span> <span class="hljs-string">avg</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">weighted</span> <span class="hljs-string">avg</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span></pre></div><h2 id="2663">Random Forest —</h2><p id="8551">It’s a supervised machine learning algorithm that is constructed from decision tree algorithms ( it predicts the outcome by taking the average or mean of the output from the different trees) and Is used to solve both regression and classification problems. It mainly used ensemble learning, a technique in which many classifiers are combined together to provide solutions to complex problems. It’s very efficient as it reduces the overfitting of datasets, provides an effective way of handling missing data, runs efficiently on large databases, achieves extremely high accuracies, increases precision and scales really well when new features are added to the dataset..</p><figure id="dc10"><img src="https://cdn-images-1.readmedium.com/v2/resize:fit:800/0*E6r4l_5gRd1WWaUJ.png"><figcaption></figcaption></figure><div id="22cc"><pre><span class="hljs-comment"># Random Forest</span>
model_rf = <span class="hljs-title function_ invoke__">Pipeline</span>([(<span class="hljs-string">'v'</span>, <span class="hljs-title function_ invoke__">CountVectorizer</span>(min_df=<span class="hljs-number">7</span>, ngram_range=(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>))),(<span class="hljs-string">'tfidf'</span>, <span class="hljs-title function_ invoke__">TfidfTransformer</span>()),(<span class="hljs-string">'clf-rf'</span>, <span class="hljs-title function_ invoke__">RandomForestClassifier</span>(n_estimators=<span class="hljs-number">30</span>)),])
model_rf.<span class="hljs-title function_ invoke__">fit</span>(X_train, y_train)
ytest = np.<span class="hljs-keyword">array</span>(y_test)
pred_rf = model_rf.<span class="hljs-title function_ invoke__">predict</span>(X_test)
<span class="hljs-keyword">print</span>(<span class="hljs-string">'accuracy %s'</span> % <span class="hljs-title function_ invoke__">accuracy_score</span>(pred_rf, y_test))
<span class="hljs-keyword">print</span>(<span class="hljs-string">'Confusion Matrix:'</span>, <span class="hljs-title function_ invoke__">confusion_matrix</span>(y_test, pred_rf))
<span class="hljs-keyword">print</span>(<span class="hljs-title function_ invoke__">classification_report</span>(ytest, pred))</pre></div><p id="af5c">Output —</p><div id="354d"><pre><span class="hljs-string">accuracy</span> <span class="hljs-number">1.0</span>
<span class="hljs-attr">Confusion Matrix:</span> [[<span class="hljs-number">5788</span>]]
<span class="hljs-string">precision</span> <span class="hljs-string">recall</span> <span class="hljs-string">f1-score</span> <span class="hljs-string">support</span>
<span class="hljs-number">1</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">accuracy</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">macro</span> <span class="hljs-string">avg</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span>
<span class="hljs-string">weighted</span> <span class="hljs-string">avg</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">1.00</span> <span class="hljs-number">5788</span></pre></div><h1 id="d849">That’s it for now. Quick Recap and Data Analytics Projects coming soon!</h1><p id="00f9"><i>Let me know if you have questions in the comment section below. Subscribe/ Follow, Like/Clap as it would encourage me to write more in my free time</i></p><p id="6bdd"><i>Stay Tuned!!</i></p><h2 id="1275">Read More —</h2><h1 id="e6db">11 most important System Design Base Concepts</h1><blockquote id="07c4"><p><a href="https://readmedium.com/complete-system-design-series-part-1-45bf9c8654bc"><b>1. System design basics</b></a></p></blockquote><blockquote id="5e90"><p><a href="https://readmedium.com/complete-system-design-series-part-2-922f45f2faaf"><b>2. Horizontal and vertical scaling</b></a></p></blockquote><blockquote id="e615"><p><a href="https://readmedium.com/part-3-complete-system-design-series-e1362baa8a4c"><b>3. Load balancing and Message queues</b></a></p></blockquote><blockquote id="ba0d"><p><a href="https://readmedium.com/part-4-complete-system-design-series-138bc9fbcfc0"><b>4. High level design and low level design, Consistent Hashing, Monolithic and Microservices architecture</b></a></p></blockquote><blockquote id="9480"><p><a href="https://readmedium.com/part-5-complete-system-design-series-4b9b04f23608"><b>5. Caching, Indexing, Proxies</b></a></p></blockquote><blockquote id="786d"><p><a href="https://readmedium.com/part-6-complete-system-design-series-59a2d8bbf1ed"><b>6. Networking, How Browsers work, Content Network Delivery ( CDN)</b></a></p></blockquote><blockquote id="1e02"><p><a href="https://readmedium.com/part-7-complete-system-design-series-1bef528923d6"><b>7. Database Sharding, CAP Theorem, Database schema Design</b></a></p></blockquote><blockquote id="ed73"><p><a href="https://readmedium.com/part-8-complete-system-design-series-57bc88433c8e"><b>8. Concurrency, API, Components + OOP + Abstraction</b></a></p></blockquote><blockquote id="6213"><p><a href="https://readmedium.com/part-9-complete-system-design-series-df975c85ec51"><b>9. Estimation and Planning, Performance</b></a></p></blockquote><blockquote id="c502"><p><b>10. <a href="https://readmedium.com/part-10-complete-system-design-series-523b4dd978bf?sk=741f92929c8639a2e4cf218521e8cc4a">Map Reduce, Patterns and Microservices</a></b></p></blockquote><blockquote id="967c"><p><b>11. <a href="https://naina0412.medium.com/part-11-complete-system-design-series-9c8efbc0237a?sk=5bddf2adc78ea4947ae88ab21c94af1c">SQL vs NoSQL and Cloud</a></b></p></blockquote><blockquote id="767e"><p><a href="https://readmedium.com/most-popular-system-design-questions-mega-compilation-45218129fe26"><b>12. Most Popular System Design Questions</b></a></p></blockquote><blockquote id="33a4"><p><b>13. <a href="https://readmedium.com/day-3-of-system-design-case-studies-series-875df4b766b9?sk=1133c9135f849f4497400a6b9caf5c2e">System Design Template — How to solve any System Design Question</a></b></p></blockquote><blockquote id="7526"><p><a href="https://readmedium.com/quick-roundup-solved-system-design-case-studies-6ad776d437cf?sk=e42f56968e1b592382f484c222e7c111"><b>14. Quick RoundUp : Solved System Design Case Studies</b></a></p></blockquote><h1 id="9ae4">System Design Case Studies — In Depth</h1><blockquote id="f5c2"><p><a href="https://readmedium.com/day-4-of-system-design-case-studies-series-design-instagram-part-1-10943440f29c?sk=38e68a213058e169e71754e00c501813"><b>Design Instagram</b></a></p></blockquote><blockquote id="4c87"><p><a href="https://readmedium.com/day-5-of-system-design-case-studies-series-design-messenger-app-7b73c589f4a?sk=4a53b122e8f02836c17fa35622aa0309"><b>Design Messenger App</b></a></p></blockquote><blockquote id="ca00"><p><a href="https://readmedium.com/day-7-of-system-design-case-studies-series-design-twitter-fd0722d7bb7c?sk=cdfc23d38edd5f48dc30efdcc0801c3e"><b>Design Twitter</b></a></p></blockquote><blockquote id="52bb"><p><a href="https://readmedium.com/day-8-of-system-design-case-studies-series-design-url-shortener-91c812a08e0b?sk=5e20d426c91ebaacfe43031bc43642da"><b>Design URL Shortener</b></a></p></blockquote><blockquote id="dcc2"><p><a href="https://readmedium.com/day-9-of-system-design-case-studies-series-design-dropbox-ead523ccccfa?sk=03b3b4ea3633051f7a9a7d379b1066b8"><b>Design Dropbox</b></a></p></blockquote><blockquote id="25bf"><p><a href="https://readmedium.com/day-10-of-system-design-case-studies-series-design-youtube-58bc4ad09c4b?sk=18560ffcc3d7174566d38d60c99d4914"><b>Design Youtube</b></a></p></blockquote><blockquote id="6d16"><p><a href="https://readmedium.com/day-11-of-system-design-case-studies-series-design-api-rate-limiter-8627993c5a92?sk=fad32cada40f414aef47b7928dfb7e67"><b>Design API Rate Limiter</b></a></p></blockquote><blockquote id="3942"><p><a href="https://readmedium.com/day-12-of-system-design-case-studies-series-design-web-crawler-efba93f40030?sk=185e88e37fbc3d30dcaf41bc3863a868"><b>Design Web Crawler</b></a></p></blockquote><blockquote id="80bf"><p><a href="https://naina0412.medium.com/day-13-of-system-design-case-studies-series-design-facebooks-newsfeed-e96294c7d871?sk=f0956b536721902c7da6a1ec8e2f0880"><b>Design Facebook’s Newsfeed</b></a></p></blockquote><blockquote id="2353"><p><a href="https://readmedium.com/day-14-of-system-design-case-studies-series-design-yelp-af432d13e838?sk=55e19b7d8ad43c4109e9b1694678c177"><b>Design Yelp</b></a></p></blockquote><blockquote id="dcb7"><p><a href="https://readmedium.com/day-15-of-system-design-case-studies-series-design-uber-2adc612701d?sk=d1c5481fcfd4f30e84074e5a5d7c548e"><b>Design Uber</b></a></p></blockquote><blockquote id="580e"><p><a href="https://readmedium.com/day-16-of-system-design-case-studies-series-design-tinder-a0867163f449?sk=6313f0b9760c3d78a17443a98bdb3330"><b>Design Tinder</b></a></p></blockquote><blockquote id="6b84"><p><a href="https://readmedium.com/day-17-of-system-design-case-studies-series-design-tiktok-58e5a93bcfb5?sk=5eed7cbac7af8b6506951417514ec8e0"><b>Design Tiktok</b></a></p></blockquote><blockquote id="1a51"><p><a href="https://readmedium.com/day-18-of-system-design-case-studies-series-design-whatsapp-38ec39f32b44?sk=89cc7003e78917fd65330ad56a7ed8f0"><b>Design Whatsapp</b></a></p></blockquote><blockquote id="86fc"><p><a href="https://readmedium.com/most-popular-system-design-questions-mega-compilation-45218129fe26?sk=6432dd01c067dd28bc81da1dfceccdab"><b>Most Popular System Design Questions</b></a></p></blockquote><blockquote id="a7f7"><p><a href="https://readmedium.com/quick-roundup-solved-system-design-case-studies-6ad776d437cf?sk=e42f56968e1b592382f484c222e7c111"><b>Mega Compilation : Solved System Design Case studies</b></a></p></blockquote><h1 id="c325">Complete Data Structures and Algorithm Series</h1><blockquote id="c8f1"><p><a href="https://readmedium.com/day-4-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-83d4c90d9115?sk=8ab3d284915f8f28534651d1c9cf41e5"><b>Complexity Analysis</b></a></p></blockquote><blockquote id="c155"><p><a href="https://readmedium.com/day-5-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-backtracking-f7de93dbe72d?sk=08c8ce11404387e46fdd73013aec267f"><b>Backtracking</b></a></p></blockquote><blockquote id="66fd"><p><a href="https://readmedium.com/day-3-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-af62dc4aec9c?sk=704354dbc4c0048ac0a0b5c97f1eef0e"><b>Sliding Window</b></a></p></blockquote><blockquote id="da37"><p><a href="https://readmedium.com/day-6-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-greedy-technique-4b219a8488d0?sk=540b74ce2d13f345dd00cbbfb252815f"><b>Greedy Technique</b></a></p></blockquote><blockquote id="d262"><p><a href="https://readmedium.com/day-8-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-two-pointer-7c513302dfa9?sk=cc32bc3ce22139845c64d195553859e0"><b>Two pointer Technique</b></a></p></blockquote><blockquote id="43b9"><p><a href="https://readmedium.com/day-11-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-arrays-bf7045a3c98b?sk=42ad70a29aa9f7891794d7feaa63bea9"><b>Arrays</b></a></p></blockquote><blockquote id="8dbb"><p><a href="https://readmedium.com/day-13-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-linked-list-6536f0041153?sk=952899c3d2e2bd5b4dbd6c8ad7debf05"><b>Linked List</b></a></p></blockquote><blockquote id="29e2"><p><a href="https://readmedium.com/day-12-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-strings-fa27c45a5fd6?sk=f6b3fc7bf5c770d2d04107667be1c446"><b>Strings</b></a></p></blockquote><blockquote id="95aa"><p><a href="https://readmedium.com/day-14-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-stack-b26d68eb3477?sk=ed28cc4e45134ad3562a3594ddea4017"><b>Stack</b></a></p></blockquote><blockquote id="d072"><p><a href="https://readmedium.com/day-15-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-queue-db38d5477cd5?sk=44ae516bf0f1da510ee9618b7f135995"><b>Queues</b></a></p></blockquote><blockquote id="0e08"><p><a href="https://readmedium.com/day-17-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-hash-ddfe72657211?sk=a457b598d5f5f3d2572029693c587198"><b>Hash Table/Hashing</b></a></p></blockquote><blockquote id="b6d3"><p><a href="https://readmedium.com/day-16-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-binary-search-8799ce6321cb?sk=e4ee1b96f1cd2f9531b5e739539d8b7e"><b>Binary Search</b></a></p></blockquote><blockquote id="5586"><p><a href="https://readmedium.com/day-7-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-1-d-dynamic-2560f585499?sk=0756b6bd798238d9a96fe3d161690350"><b>1- D Dynamic Programming</b></a></p></blockquote><blockquote id="be69"><p><a href="https://readmedium.com/day-10-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-divide-and-a00f7375507?sk=3d52023dade6f37c396b58e039ca29f2"><b>Divide and Conquer Technique</b></a></p></blockquote><blockquote id="b173"><p><a href="https://readmedium.com/day-9-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-recursion-ed6f7f41742?sk=bf98ce6abdb3e3f2fa71213c6ed8caa9"><b>Recursion</b></a></p></blockquote><h1 id="c583">Some of the other best Series —</h1><blockquote id="ca4e"><p><a href="https://readmedium.com/day-1-day-60-quick-recap-of-60-days-of-data-science-and-ml-6fc021643d1?sk=4e75e043b7630a9f963562ebac94e129"><b>60 days of Data Science and ML Series with projects</b></a></p></blockquote><blockquote id="1ff6"><p><a href="https://readmedium.com/quick-recap-30-days-of-natural-language-processing-nlp-with-projects-series-ceb674e3c09b?sk=ca09b27b3d5867f23ab4dc367b6c0c32"><b>30 Days of Natural Language Processing ( NLP) Series</b></a></p></blockquote><blockquote id="c2cf"><p><a href="https://readmedium.com/day-1-of-30-days-of-machine-learning-ops-7c299e4b09be?sk=4ab48350a5c359fc157109e48b1d738f"><b>30 days of Machine Learning Ops</b></a></p></blockquote><blockquote id="5c01"><p><a href="https://readmedium.com/day-1-of-30-days-of-data-structures-and-algorithms-and-system-design-simplified-dsa-and-system-965e860ec677?sk=aa49bdbc46a72f600cb51774f0aea6b6"><b>30 days of Data Structures and Algorithms and System Design Simplified</b></a></p></blockquote><blockquote id="f2fd"><p><a href="https://readmedium.com/day-1-of-60-days-of-deep-learning-with-projects-series-4a5caa305cf6?sk=89f3d43dd450035546bf3a8cf85bb125"><b>60 Days of Deep Learning with Projects Series</b></a></p></blockquote><blockquote id="b8a0"><p><a href="https://readmedium.com/day-1-of-30-days-of-data-engineering-894822fcb128?sk=76ba558bfe2d9f85cbe741e505295531"><b>30 days of Data Engineering with projects Series</b></a></p></blockquote><blockquote id="9d85"><p><a href="https://readmedium.com/day-1-data-science-and-ml-research-papers-simplified-a68b00a3b1c4?sk=56136229ff738bd734f19d2b6953f78c"><b>Data Science and Machine Learning Research ( papers) Simplified</b></a><b> **</b></p></blockquote><blockquote id="fb06"><p><a href="https://readmedium.com/100-days-your-data-science-and-ml-degree-part-3-c621ecfdf711?sk=1a8c7b0c204d73432d56b7d1a3a26474"><b>100 days : Your Data Science and Machine Learning Degree Series with projects</b></a></p></blockquote><blockquote id="5203"><p><a href="https://ai.plainenglish.io/23-data-science-techniques-you-should-know-61bc2c9d1b3a?sk=1680c36193eb22198974c9008d62a33c"><b>23 Data Science Techniques You Should Know</b></a></p></blockquote><blockquote id="ac12"><p><a href="https://readmedium.com/mega-post-tech-interview-the-only-list-of-questions-you-need-to-practice-ee349ea197bb?sk=fac3614684daff4b50a70c0a71e4d528"><b>Tech Interview Series — Curated List of coding questions</b></a></p></blockquote><blockquote id="dede"><p><a href="https://readmedium.com/system-design-made-easy-quick-recap-of-complete-system-design-34af7e3aedfb?sk=bdd6a19edc1f3ce4a5064923f5b68721"><b>Complete System Design with most popular Questions Series</b></a></p></blockquote><blockquote id="6508"><p><a href="https://readmedium.com/complete-data-preprocessing-and-data-visualization-with-projects-mega-compilation-part-2-41584ef0920e?sk=842390da51689b8d43148c3980570db0"><b>Complete Data Visualization and Pre-processing Series with projects</b></a></p></blockquote><blockquote id="409a"><p><a href="https://readmedium.com/complete-python-and-projects-mega-compilation-7ec8f7adfe71?sk=ee0ecf43f23c6dd44dd35d984b3e5df4"><b>Complete Python Series with Projects</b></a></p></blockquote><blockquote id="67e0"><p><a href="https://readmedium.com/complete-advanced-python-with-projects-mega-compilation-part-6-729c1826032b?sk=7faffe20f8039fa57099f7a372b6d665"><b>Complete Advanced Python Series with Projects</b></a></p></blockquote><blockquote id="4ded"><p><a href="https://readmedium.com/my-list-of-kaggle-best-notebooks-topic-wise-data-science-and-machine-learning-part-2-84772863e9ae?sk=5ed02e419854a6c11add3ddc1e52947f"><b>Kaggle Best Notebooks that will teach you the most</b></a></p></blockquote><blockquote id="4b2e"><p><a href="https://medium.datadriveninvestor.com/the-complete-developers-guide-to-git-6a23125996e1?sk=e30479bbe713930ea93018e1a46d9185"><b>Complete Developers Guide to Git</b></a></p></blockquote><blockquote id="732e"><p><a href="https://readmedium.com/6-exceptional-github-repos-for-all-developers-part-1-21e8fa04e150?sk=9140b249af6fe73d45717185fad48962"><b>Exceptional Github Repos</b></a><b> — Part 1</b></p></blockquote><blockquote id="7079"><p><a href="https://readmedium.com/6-exceptional-github-repos-for-all-developers-part-2-3eec9a68c31c?sk=8e31d0eb7eb1d2d0bbbcecaa66bd4e7e"><b>Exceptional Github Repos</b></a><b> — Part 2</b></p></blockquote><blockquote id="d9c6"><p><a href="https://medium.datadriveninvestor.com/best-resources-for-data-science-and-machine-learning-full-list-5ceb9a2791bf?sk=cf85b2cef95560c58509877a794577ff"><b>All the Data Science and Machine Learning Resources</b></a></p></blockquote><blockquote id="b2cb"><p><a href="https://medium.datadriveninvestor.com/210-machine-learning-projects-with-source-code-that-you-can-build-today-721b035649e0?sk=da5f593572a0261a6314afad99a0356c"><b>210 Machine Learning Projects</b></a></p></blockquote><h2 id="9083">Tech Newsletter —</h2><blockquote id="f86c"><p>If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to <b>Tech Brew :</b></p></blockquote><div id="8d5c" class="link-block">
<a href="https://naina0405.substack.com/">
<div>
<div>
<h2>Ignito</h2>
<div><h3>Data Science, ML, AI and more… Click to read Ignito, by Naina Chaturvedi, a Substack publication. Launched 7 months…</h3></div>
<div><p>naina0405.substack.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*_ER1J-h50iqAjH70)"></div>
</div>
</div>
</a>
</div><p id="eb48"><b><i>For Python Projects —</i></b></p><div id="22a4" class="link-block">
<a href="https://readmedium.com/complete-python-and-projects-mega-compilation-7ec8f7adfe71">
<div>
<div>
<h2>Complete Python And Projects — Mega Compilation</h2>
<div><h3>Everything that you need to know in Python with Projects…</h3></div>
<div><p>medium.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*NnCSMN6etFjjw4Jn.jpg)"></div>
</div>
</div>
</a>
</div><div id="471c" class="link-block">
<a href="https://medium.datadriveninvestor.com/analyzing-video-using-python-opencv-and-numpy-5471cab200c4">
<div>
<div>
<h2>Analyzing Video using Python, OpenCV and NumPy</h2>
<div><h3>With Code Implementation…</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*PYNCDW3IXI2BcT5f.jpg)"></div>
</div>
</div>
</a>
</div><p id="f199"><b><i>For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML</i></b></p><div id="9d77" class="link-block">
<a href="https://readmedium.com/day-1-day-60-quick-recap-of-60-days-of-data-science-and-ml-6fc021643d1">
<div>
<div>
<h2>Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML</h2>
<div><h3>Connect the ML dots…</h3></div>
<div><p>medium.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*ZfJ1yKIzPLGABAI_.png)"></div>
</div>
</div>
</a>
</div><p id="1253"><b><i>Follow for more updates. Stay tuned and keep coding!</i></b></p><h1 id="21c3">For other projects, tune to —</h1><p id="b31f"><b>Build Machine Learning Pipelines( With Code)</b></p><div id="5b37" class="link-block">
<a href="https://medium.datadriveninvestor.com/build-machine-learning-pipelines-with-code-part-1-bd3ed7152124">
<div>
<div>
<h2>Build Machine Learning Pipelines( With Code) — Part 1</h2>
<div><h3>Complete implementation…</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*KdToBD8RDMBH4jXM.png)"></div>
</div>
</div>
</a>
</div><p id="946c"><b>Recurrent Neural Network with Keras</b></p><div id="f317" class="link-block">
<a href="https://medium.datadriveninvestor.com/recurrent-neural-network-with-keras-b5b5f6fe5187">
<div>
<div>
<h2>Recurrent Neural Network with Keras</h2>
<div><h3>Project Implementation and cheatsheet…</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*xs3Dya3qQBx6IU7C.png)"></div>
</div>
</div>
</a>
</div><p id="8018"><b>Clustering Geolocation Data in Python using DBSCAN and K-Means</b></p><div id="2b3e" class="link-block">
<a href="https://medium.datadriveninvestor.com/clustering-geolocation-data-in-python-using-dbscan-and-k-means-3705d9f44522">
<div>
<div>
<h2>Clustering Geolocation Data in Python using DBSCAN and K-Means</h2>
<div><h3>Project Implementation…</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*0uPCZnohdaPCO4NN.png)"></div>
</div>
</div>
</a>
</div><p id="a29c"><b>Facial Expression Recognition using Keras</b></p><div id="ccaa" class="link-block">
<a href="https://medium.datadriveninvestor.com/facial-expression-recognition-using-keras-cbdd661a0a54">
<div>
<div>
<h2>Facial Expression Recognition using Keras</h2>
<div><h3>Project Implementation…</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*CGch7hzdjg1fpgKy.jpg)"></div>
</div>
</div>
</a>
</div><p id="0db7"><b>Hyperparameter Tuning with Keras Tuner</b></p><div id="6dff" class="link-block">
<a href="https://medium.datadriveninvestor.com/hyperparameter-tuning-with-keras-tuner-3a609d3fd85b">
<div>
<div>
<h2>Hyperparameter Tuning with Keras Tuner</h2>
<div><h3>Project Implementation….</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*jlaEz8AZaptNWHEr.png)"></div>
</div>
</div>
</a>
</div><p id="fed8"><b>Custom Layers in Keras</b></p><div id="e4fd" class="link-block">
<a href="https://medium.datadriveninvestor.com/custom-layers-in-keras-de5f793217aa">
<div>
<div>
<h2>Custom Layers in Keras</h2>
<div><h3>Code implementation …</h3></div>
<div><p>medium.datadriveninvestor.com</p></div>
</div>
<div>
<div style="background-image: url(https://miro.readmedium.com/v2/resize:fit:320/0*1IH67KJadqeqeO01.png)"></div>
</div>
</div>
</a>
</div></article></body>