
Part 4— Complete System Design Series
System Design Made Easy…
Welcome back peeps. In the last part ( links below) we covered system design basics and horizontal and vertical scaling, load balancing, message queues with our pasta resto story.
Note : Please read System Design Important Terms you MUST know before reading this post.
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Solved System Design Case Studies — In depth
Design Google Drive
Design Instagram
Design Quora
Design Flipkart
ML System Design
Design Tiny URL
Design Netflix
Design Messenger App
Design Twitter
Design Foursquare
Design Reddit
Design Amazon
Design Dropbox
Design URL Shortener
Design Youtube
Design API Rate Limiter
Design Web Crawler
Design Amazon Prime Video
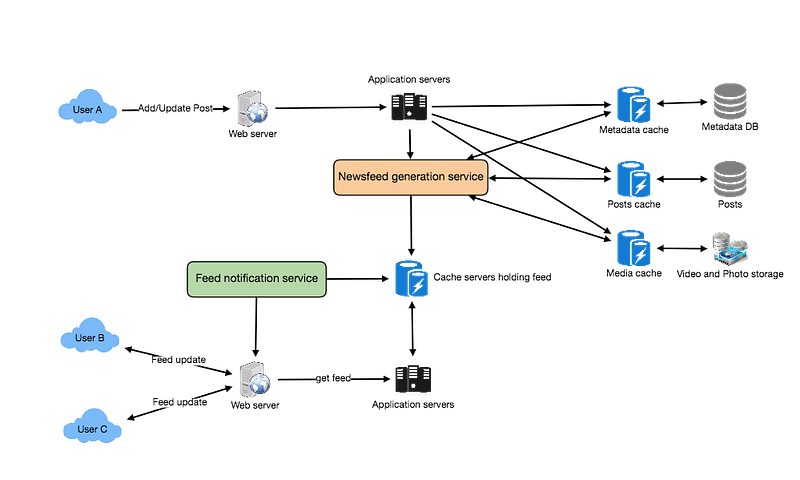
Design Facebook’s Newsfeed
Design Yelp
Design Uber
Design Tinder
Design Tiktok
Design Whatsapp
Most Popular System Design Questions
Mega Compilation : Solved System Design Case studies
Complete Data Structures and Algorithm Series
Github —
All the Complete System Design Series Parts —
6. Networking, How Browsers work, Content Network Delivery ( CDN)
Moving forward, this is the part 4 of the system design series where we will be covering —
1.High level design and Low level design
2. Monolithic and microservices architecture and which one to choose and when?
3. Consistent Hashing
Part 1 of this series can be found here —
Part 2 of this series can be found here —
Part 3 of this series can be found here —
And Most popular System Design Questions —
Let’s dive in!
High Level Design and Low Level Design
Pasta resto case :
In the last part we covered how owner of our pasta resto have decided to balance the customer load. Let’s talk about our pasta dish in detail. Every pasta dish can be described at two levels — a high level view ( look and overall smell — feel of the dish) and low level view (each ingredients, nitty gritty details).
System Design analogy
Using same analogy, in the system design every system can be described/viewed as HLD and LLD.
High level Design (HLD) aka Macro level design — coverts business requirements into high level solutions used for program management and solutions team. It describes the overall architecture of the application and covers functionality of each module of the system very briefly.
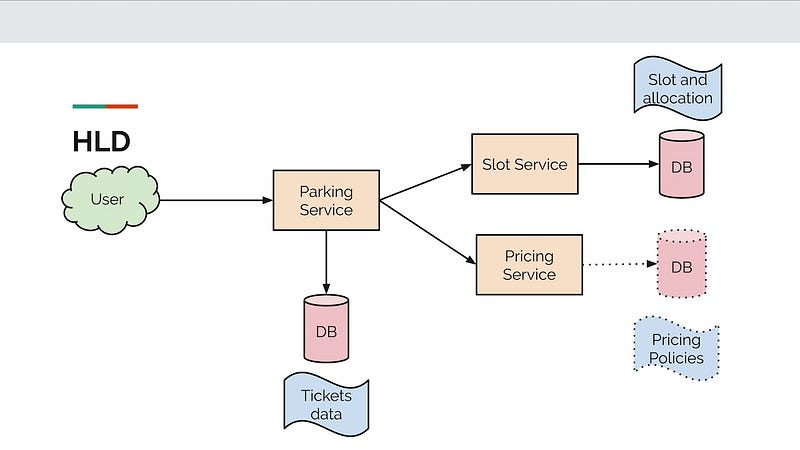
Low level design ( LLD) aka micro level design is detailed design which conveys in depth information of the high level design. It’s generally used by operations teams and solution developers. It details the functional logic of the each module in the system.
- High-level design is the first phase of the design process. It is also known as architectural design or system-level design. It involves creating a high-level representation of the system, identifying the main components, and defining the relationships between them. The main goal of high-level design is to create a big picture of the system, including its overall structure, interfaces, and data flows. This phase is typically done by system architects, and it’s the starting point for creating the system requirements.
- Low-level design is the second phase of the design process. It is also known as detailed design or component-level design. It involves creating a detailed representation of the system, defining the algorithms, data structures, and interfaces of each component. The main goal of low-level design is to provide the implementation details of the system, including the specific algorithms, data structures, and interfaces that will be used to build the system. This phase is typically done by developers, and it’s the starting point for the implementation of the system.
Here’s an example in Python to demonstrate the difference between high-level design and low-level design:
High-level design:
class Instagram:
def __init__(self):
self.users = []
self.posts = []
def add_user(self, user):
self.users.append(user)
def add_post(self, post):
self.posts.append(post)
def get_posts_by_user(self, user_id):
return [post for post in self.posts if post.user_id == user_id]
class User:
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
class Post:
def __init__(self, post_id, user_id, caption):
self.post_id = post_id
self.user_id = user_id
self.caption = captionIn the high-level design, we have defined the main classes of the system, Instagram, User, and Post, and the relationships between them. We have also defined the main methods for adding users and posts, and for retrieving posts for a specific user.
Low-level design:
class Instagram:
def __init__(self):
self.users = {}
self.posts = {}
def add_user(self, user):
self.users[user.user_id] = user
def add_post(self, post):
self.posts[post.post_id] = post
def get_posts_by_user(self, user_id):
return [post for post_id, post in self.posts.items() if post.user_id == user_id]
class User:
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
class Post:
def __init__(self, post_id, user_id, caption):
self.post_id = post_id
self.user_id = user_id
self.caption = captionIn the low-level design, we have made changes to the implementation of the classes to make them more efficient and optimized for the expected workload. For example, we have changed the storage of users and posts from lists to dictionaries, which allow for faster retrieval of elements based on the user ID or post ID.
High-level design provides a holistic view of the entire system, while low-level design provides a detailed view of each component. The two phases are closely related, and the output of the high-level design is used as the input for the low-level design. The two design phases are iterative, and the design is refined in each iteration to ensure that the final design is optimal and meets the requirements of the system.
In summary, high-level design is the first phase of the design process, it’s a top-down approach in which the main components and relationships of the system are identified. Low-level design is the second phase of the design process, it’s a bottom-up approach in which the detailed representation of the system, the algorithms, data structures, and interfaces of each component are defined.
Monolith and Microservices
Pasta resto case :
Let’s say now you have high customer growth at your pasta resto and you are thinking how are you going to manage all of it? You can build a centralized unit which controls everything, for e.g say a manager who keeps a tap on everything happening at your resto right from reservations, orders, payments, hiring, troubleshooting issues and what not. But then one day the manager isn’t doing well so he/she calls a day off. Now?
Everything in your pasta resto goes haywire with the mad rush and no one to manage things.
So, the owner thinks — the centralized unit i.e a single manager might not be best idea to manage and run everything smoothly. Let’s hire micro managers — each will manage their own department and even if someone calls in sick it wont be that chaotic. And guess what? It worked!
System Design analogy :
Taking the same analogy, there are two types of architectures based on which systems are designed in the real world.
Monolithic architecture — consists of single code base with multiple modules and it’s easier and faster to deploy.
Microservices architecture — consists of individual service units with each service being responsible for exactly one functionality. It’s relatively complex and time taking to deploy.
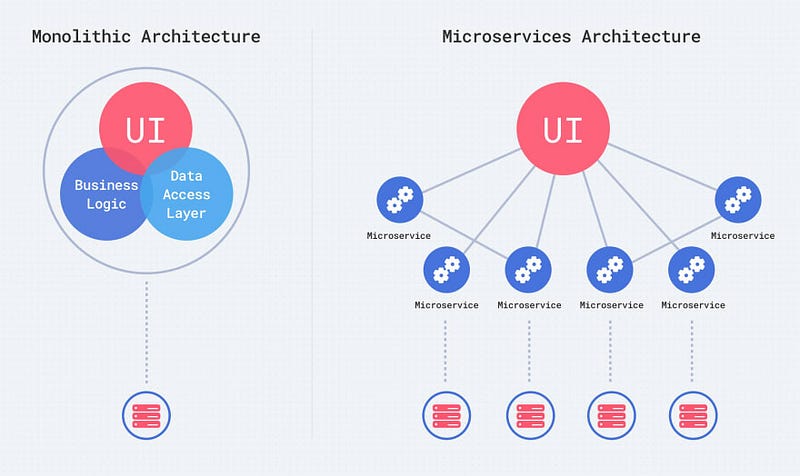
Some of the benefits and drawbacks of monolith architecture —
Benefits :
Easier and simple deployment
Simple to develop and scale horizontally
Easier testing and debugging
Drawbacks:
Complex system of code in the singleton system makes the application/system hard to manage.
Can’t scale each module of the system independently
New technology becomes bottleneck as the whole code base needs to changed/rewritten
Hard to implement changes and development process is way longer than microservices
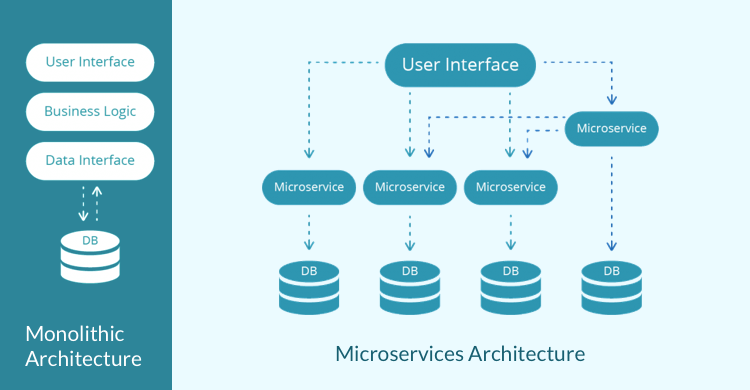
- Monolithic Architecture: A simple example of a monolithic architecture using Python would be a web application that handles user authentication, registration, and profile management. Here’s how we can implement this application using Flask, a popular Python web framework:
from flask import Flask, request, jsonify
app = Flask(__name__)
# Define routes for user authentication, registration, and profile management
@app.route('/login', methods=['POST'])
def login():
# Handle user login
return jsonify({'message': 'Logged in successfully'})
@app.route('/register', methods=['POST'])
def register():
# Handle user registration
return jsonify({'message': 'Registered successfully'})
@app.route('/profile', methods=['GET'])
def profile():
# Get user profile information
return jsonify({'username': 'john_doe', 'email': '[email protected]'})
# Run the Flask application
if __name__ == '__main__':
app.run()- Microservices Architecture: A simple example of a microservices architecture using Python would be an e-commerce application that consists of multiple services, including a product catalog service, a shopping cart service, and a payment service. Here’s how we can implement this application using Flask and Docker, a popular containerization platform:
from flask import Flask, jsonify
import requests
app = Flask(__name__)
# Define routes for product catalog, shopping cart, and payment services
@app.route('/products', methods=['GET'])
def products():
# Get product catalog information from the product catalog service
response = requests.get('http://product-catalog:8000/products')
return response.json()
@app.route('/cart', methods=['GET'])
def cart():
# Get shopping cart information from the shopping cart service
response = requests.get('http://shopping-cart:8000/cart')
return response.json()
@app.route('/payment', methods=['POST'])
def payment():
# Process payment using the payment service
response = requests.post('http://payment:8000/payment')
return response.json()
# Run the Flask application
if __name__ == '__main__':
app.run()Some of the benefits and drawbacks of microservices architecture —
Benefits
Very east to deploy as the components/modules are independent
Scales better — each component/module can be scaled independently
Easy to develop, understand, incorporate changes and deploy
Drawbacks
Microservices is nothing but a distributed system which leads to adding extra complexity to the whole system design.
Testing is difficult as compare to the monolithic architecture.
Deployment and changes are sometimes very complicated.
Here’s an example in Python to demonstrate the difference between the two architectures:
Monolithic architecture:
class Instagram:
def __init__(self):
self.users = {}
self.posts = {}
self.comments = {}
self.likes = {}
def add_user(self, user):
self.users[user.user_id] = user
def add_post(self, post):
self.posts[post.post_id] = post
def add_comment(self, comment):
self.comments[comment.comment_id] = comment
def add_like(self, like):
self.likes[like.like_id] = like
def get_posts_by_user(self, user_id):
return [post for post_id, post in self.posts.items() if post.user_id == user_id]
def get_comments_by_post(self, post_id):
return [comment for comment_id, comment in self.comments.items() if comment.post_id == post_id]
def get_likes_by_post(self, post_id):
return [like for like_id, like in self.likes.items() if like.post_id == post_id]
class User:
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
class Post:
def __init__(self, post_id, user_id, caption):
self.post_id = post_id
self.user_id = user_id
self.caption = caption
class Comment:
def __init__(self, comment_id, post_id, user_id, text):
self.comment_id = comment_id
self.post_id = post_id
self.user_id = user_id
self.text = text
class Like:
def __init__(self, like_id, post_id, user_id):
self.like_id = like_id
self.post_id = post_id
self.user_id = user_idIn the monolithic architecture, all the components of the system are bundled into a single module or a single application. This can make the development and deployment of the system easier, since everything is in one place, but can also make the system more complex and harder to maintain as it grows.
Monolithic architecture is a traditional approach to software development in which all the components of the system are built as a single, large, and unified executable. A monolithic system is a single, autonomous unit that is deployed and executed as a single process. The system is typically divided into different layers, such as the user interface, business logic, and data access layers. These layers are tightly coupled and share a common codebase. Monolithic architecture is simple to understand and develop, and it’s suitable for small to medium-sized systems. However, it can become unwieldy and difficult to maintain as the system grows and evolves.
Here’s an example implementation of microservices architecture in Python:
class UserService:
def __init__(self):
self.users = {}
def add_user(self, user):
self.users[user.user_id] = user
def get_user(self, user_id):
return self.users.get(user_id)
class PostService:
def __init__(self):
self.posts = {}
def add_post(self, post):
self.posts[post.post_id] = post
def get_posts_by_user(self, user_id):
return [post for post_id, post in self.posts.items() if post.user_id == user_id]
class CommentService:
def __init__(self):
self.comments = {}
def add_comment(self, comment):
self.comments[comment.comment_id] = comment
def get_comments_by_post(self, post_id):
return [comment for comment_id, comment in self.comments.items() if comment.post_id == post_id]
class LikeService:
def __init__(self):
self.likes = {}
def add_like(self, like):
self.likes[like.like_id] = like
def get_likes_by_post(self, post_id):
return [like for like_id, like in self.likes.items() if like.post_id == post_id]
class User:
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
class Post:
def __init__(self, post_id, user_id, caption):
self.post_id = post_id
self.user_id = user_id
self.caption = caption
class Comment:
def __init__(self, comment_id, post_id, user_id, text):
self.comment_id = comment_id
self.post_id = post_id
self.user_id = user_id
self.text = text
class Like:
def __init__(self, like_id, post_id, user_id):
self.like_id = like_id
self.post_id = post_id
self.user_id = user_idIn microservices architecture, the components of the system are split into smaller, independent services. Each service is responsible for a specific functionality and communicates with other services through APIs. This makes the system more scalable and easier to maintain, as changes to one service can be made without affecting the other services. However, it also requires more complex deployment and management, since each service has to be deployed and maintained separately.
Microservices architecture, on the other hand, is a more recent approach to software development that emphasizes building systems as a collection of small, independent, and loosely coupled services. Each service is a self-contained unit that implements a specific functionality and communicates with other services through APIs. Microservices architecture is highly scalable and allows for fast deployment and easy maintenance. It’s suitable for large and complex systems, and it allows for continuous integration and delivery.
In summary, Monolithic architecture is a traditional approach to software development , while Microservices architecture is a more recent approach that emphasizes building systems as a collection of small, independent and loosely coupled services. Microservices architecture allows for faster deployment, easy maintenance, and it’s suitable for large and complex systems, while monolithic architecture is simple to understand and develop and it’s suitable for small to medium-sized systems.
So which one to chose while designing a system?
As you can see there are multiple tradeoffs. When your team is small and you are building a simple standalone application and intend to launch it quickly then monolithic architecture is the best. Otherwise, if you want to build a large system with multiple functionalities, complex business logic, large team in terms of engineering and want to scale your system as you hit high growth highway, then choose microservices architecture.
Consistent Hashing
Pasta resto case :
Continuing our pasta resto story, you can see mad rush of customers and now the receptionist is panicking. How to allocate the table to the customers ( both customers who have reservations as well as who are walk-ins). Since the tables are big, is it possible to allocate one table to two different customers? Is there a mathematical arrangement ( like odd or even or by color) using which the tables can be best allocated for every customer sweating outside in the queue?
And once the customer is done eating, how do we determine which table he/she was occupying?
System Design analogy :
Taking the same analogy, in system design consistent hashing is a very important concept ( that you must know).
Consistent hashing is a technique to divide keys/data between multiple servers/machines using a hash function ( key — value). Assigning keys to the machines is the game here. Hashing is the technique to map data of random size to the fixed-size values. Each existing algorithm with its own use case and specifications has:
- MD5 produces 128-bit hash values.
- SHA-1 produces 160-bit hash values.
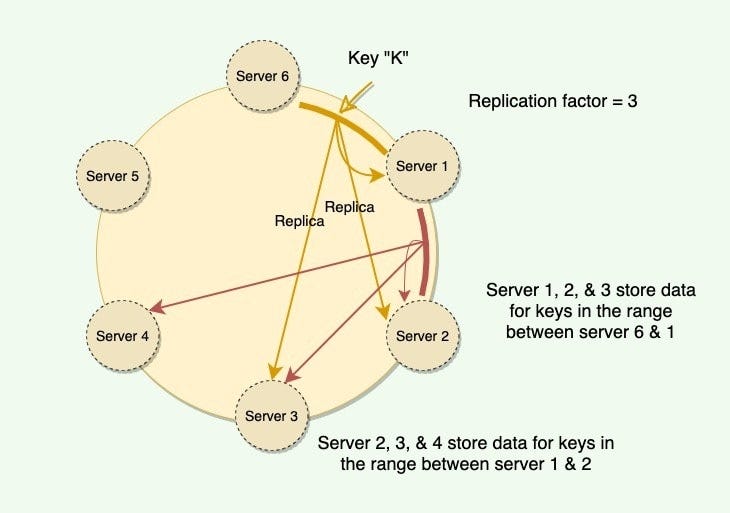
The basic idea behind consistent hashing is to use a hash function to map keys (i.e., the objects to be distributed) to a fixed number of points on a circle. The circle is called a hash ring. Each server is also assigned to a point on the same ring. When a request for a key comes in, the hash function is used to determine the point on the ring where the key would be located. The server that is closest to that point on the ring is responsible for handling the request.
When a new server is added to the cluster or an existing server is removed, only a small number of keys will need to be remapped to new servers. This is because the hash ring is divided into a large number of points, and each server is only responsible for a small number of points.
Consistent hashing has several benefits:
- It minimizes the number of re-mappings of keys to servers when the number of servers changes.
- It allows for dynamic resizing of the cluster without incurring significant overhead.
- It distributes the load evenly across the servers.
It’s commonly used in distributed systems like distributed caching systems and content delivery networks to distribute data evenly across multiple nodes, and also is a key component in distributed hash table implementation.
Here’s an example implementation of consistent hashing in Python:
import hashlibclass Node:
def __init__(self, id, data):
self.id = id
self.data = data
class HashRing:
def __init__(self, nodes, replicas=100):
self.nodes = nodes
self.replicas = replicas
self.ring = {}
self.sorted_keys = []
for node in nodes:
for i in range(replicas):
key = self.get_key(node.id, i)
self.ring[key] = node
self.sorted_keys.append(key)
self.sorted_keys.sort()
def get_key(self, node_id, i):
return int(hashlib.md5("%s:%s" % (node_id, i)).hexdigest(), 16)
def get_node(self, data):
key = int(hashlib.md5(data).hexdigest(), 16)
for i in range(len(self.sorted_keys)):
node_key = self.sorted_keys[i]
if node_key >= key:
return self.ring[node_key].data
return self.ring[self.sorted_keys[0]].data
nodes = [Node("Node %d" % i, "192.168.1.%d" % i) for i in range(10)]
hash_ring = HashRing(nodes)
data = "Hello, World!"
node = hash_ring.get_node(data)
print("Data:", data)
print("Node:", node)In consistent hashing, data is hashed and distributed among nodes in a circular fashion. Each node is assigned a range of the hash space, and data is assigned to the node whose range it falls into. This allows for distributing the data evenly among nodes, and also makes it possible to add or remove nodes without affecting the data distribution too much. The consistent hashing algorithm can be used to implement caching and load balancing systems.
In summary, Consistent Hashing is a technique used to distribute requests across a cluster of servers in a distributed system, it’s based on using a hash function to map keys to a fixed number of points on a circle, this circle is called a hash ring, when a new server is added or an existing server is removed, only a small number of keys will need to be remapped to new servers. It allows for dynamic resizing of the cluster without incurring significant overhead and distributes the load evenly across the servers.
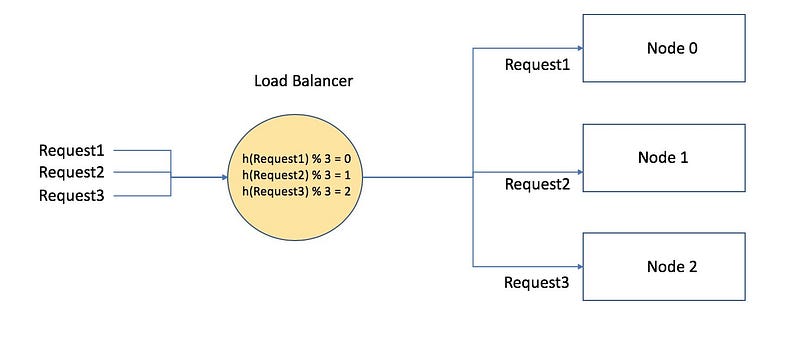
The most popular one are Mod-n-hashing and Ring hashing. In simple words, in Mod -n- hashing each key is hashed using a hashing function which converts the input to an integer and then we calculate the modulo based on the number of server nodes ( as shown below)
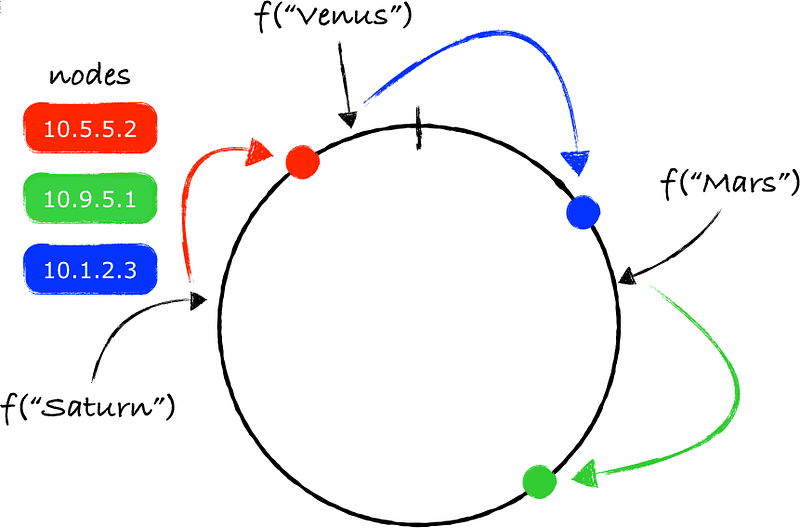
In the case of Ring hashing, the requests are allocated to the server nodes in the ring at the random places using hash function. The familiar requests arising from the same computer/machines are placed on the same ringing using the same hash function instead of allocating a new place based on the increasing order of the location indexes/addresses.
Here’s an example implementation of ring hashing in Python:
import hashlibclass Node:
def __init__(self, id, data):
self.id = id
self.data = data
class HashRing:
def __init__(self, nodes):
self.nodes = nodes
self.ring = {}
self.sorted_keys = []
for node in nodes:
key = self.get_key(node.id)
self.ring[key] = node
self.sorted_keys.append(key)
self.sorted_keys.sort()
def get_key(self, node_id):
return int(hashlib.md5(node_id).hexdigest(), 16)
def get_node(self, data):
key = int(hashlib.md5(data).hexdigest(), 16)
for i in range(len(self.sorted_keys)):
node_key = self.sorted_keys[i]
if node_key >= key:
return self.ring[node_key].data
return self.ring[self.sorted_keys[0]].data
nodes = [Node("Node %d" % i, "192.168.1.%d" % i) for i in range(10)]
hash_ring = HashRing(nodes)
data = "Hello, World!"
node = hash_ring.get_node(data)
print("Data:", data)
print("Node:", node)In ring hashing, data is hashed and assigned to a node based on its hash value. The nodes are arranged in a circular fashion and each node is assigned a portion of the hash space. When data is hashed, its hash value is used to determine which node it should be assigned to. This way, data is distributed evenly among nodes. Ring hashing can be used for implementing distributed systems such as caching and load balancing.
More on High Level Design, Low level Design, Consistent Hashing, Monolithic and Microservices Architecture —
High-Level Design:
System Architecture: The overall architecture of the system follows a microservices-based approach, where different components are designed as independent services that communicate with each other through APIs. The system consists of the following components:
- User Interface (UI): This component handles the presentation layer and provides an intuitive and user-friendly interface for users to interact with the system.
- API Gateway: The API Gateway acts as a single entry point for all client requests and manages the routing of requests to the appropriate microservices. It also handles authentication, authorization, and rate limiting.
- Microservices: The system is decomposed into multiple microservices, each responsible for a specific business functionality. These microservices are designed to be loosely coupled, allowing for independent development, deployment, and scalability. They communicate with each other via synchronous or asynchronous messaging.
- Databases: Data storage and management are handled by different types of databases based on the requirements of each microservice. Relational databases, NoSQL databases, and caching mechanisms are used to ensure efficient data storage and retrieval.
- External Services: The system integrates with various external services such as payment gateways, email providers, and third-party APIs. Integration with these services is done through well-defined APIs.
Scalability and Performance: To handle increasing loads and ensure optimal performance, the system employs several strategies:
- Horizontal Scaling: The microservices architecture allows individual services to be scaled independently based on demand. Additional instances of a microservice can be deployed to handle increased traffic, and load balancers distribute the requests evenly across these instances.
- Caching: Caching is utilized to reduce the load on the databases and improve response times. A distributed caching system such as Redis or Memcached is employed to cache frequently accessed data or computation results.
- Asynchronous Processing: Long-running tasks or resource-intensive operations are offloaded to background workers or message queues, reducing the response time of the main API requests.
- Performance Monitoring: The system incorporates monitoring tools that track key performance metrics such as response times, throughput, and resource utilization. This data is used for performance analysis, capacity planning, and identifying bottlenecks.
Availability and Fault Tolerance: The system maintains high availability and recovers from failures through the following measures:
- Redundancy: Critical components, such as the API Gateway and databases, are designed with redundancy in mind. Multiple instances of these components are deployed across different servers or regions to ensure availability even if some instances fail.
- Automated Failover: Load balancers and clustering techniques are employed to automatically detect failures and redirect traffic to healthy instances. This minimizes service disruptions and ensures seamless failover.
- Fault Isolation: By adopting a microservices architecture, failures in one service are isolated and do not impact the entire system. This improves fault tolerance and allows for easier troubleshooting and debugging.
- Monitoring and Alerting: Continuous monitoring of system health and performance helps detect anomalies and potential failures. Alerts and notifications are triggered to the operations team in case of abnormal behavior, enabling them to take corrective actions promptly.
Data Storage and Management: The system employs various strategies for storing and managing data:
- Relational Databases: For structured data, a relational database such as MySQL or PostgreSQL is used. The database schema is designed to efficiently represent the relationships between entities and support complex queries.
- NoSQL Databases: Unstructured or semi-structured data is stored in NoSQL databases like MongoDB or Cassandra. These databases provide flexibility and scalability for handling large volumes of data.
- Caching: Frequently accessed data or computation results are cached using a distributed caching system like Redis. This reduces the load on databases and improves response times.
- Data Replication: To ensure data availability and resilience, data replication techniques such as master-slave replication or sharding are employed. Data is replicated across multiple nodes or shards to provide redundancy and improve read performance.
- Backup and Recovery: Regular backups of databases are performed to ensure data integrity and facilitate disaster recovery. Backup strategies include full backups, incremental backups, or continuous replication to secondary storage.
Security: The system incorporates various measures to ensure the security of the system and protect against threats:
- Authentication and Authorization: User authentication is implemented using industry-standard protocols like OAuth or JWT. Role-based access control (RBAC) is used to enforce authorization policies and restrict access to sensitive resources.
- Encryption: Sensitive data is encrypted both in transit and at rest. Secure communication channels, such as HTTPS, are used to protect data during transmission. Encryption algorithms and best practices are followed to safeguard stored data.
- Input Validation and Sanitization: User input is validated and sanitized to prevent common security vulnerabilities like SQL injection or cross-site scripting (XSS) attacks. Input validation is performed at both the client-side and server-side.
- Security Auditing and Logging: Comprehensive logging mechanisms are implemented to capture security-related events and activities. Logs are regularly reviewed, and security audits are conducted to identify any potential vulnerabilities or breaches.
- Security Testing: The system undergoes regular security testing, including vulnerability assessments and penetration testing. Automated tools and manual reviews are used to identify and address security vulnerabilities.
Integration and APIs: The system integrates with external services and follows API design principles:
- API Layer: The system exposes a set of well-defined APIs that allow external services, third-party applications, or client applications to interact with the system. The APIs follow RESTful or GraphQL principles, providing a clear and consistent interface.
- API Documentation: Detailed documentation is provided for the APIs, including endpoints, request/response formats, authentication requirements, and error handling. This documentation helps developers understand and effectively use the system’s APIs.
- Integration Patterns: Depending on the requirements, the system supports various integration patterns such as synchronous request-response, asynchronous messaging, or event-driven architectures. These patterns enable seamless communication and integration with external services.
- Rate Limiting and Throttling: To manage and control the usage of APIs, rate limiting and throttling mechanisms are implemented. These mechanisms prevent abuse, protect system resources, and ensure fair access to the system.
User Interface and User Experience: The design principles and considerations for creating an intuitive and user-friendly interface are as follows:
- User-Centered Design: The user interface is designed with a focus on the needs and goals of the users. User research, usability testing, and iterative design processes are employed to create an interface that meets user expectations.
- Responsive Design: The user interface is designed to be responsive and adaptable to different devices and screen sizes. This ensures a consistent and optimized experience across desktop, mobile, and tablet devices.
- Intuitive Navigation: Clear and logical navigation paths are implemented to help users easily navigate through different sections of the system. User-friendly menus, breadcrumbs, and search functionality are provided for efficient information retrieval.
- Consistency and Visual Hierarchy: Consistent visual elements, typography, and color schemes are used to provide a cohesive user experience. Visual hierarchy is employed to highlight important information and guide users’ attention.
- Feedback and Validation: Interactive elements provide feedback to users, confirming successful actions, displaying error messages, or guiding them through form validation. This helps users understand the system’s behavior and avoid mistakes.
Monitoring and Logging: The system incorporates mechanisms for monitoring the system’s health and performance and capturing logs:
- Health Monitoring: Monitoring tools are used to continuously check the availability and performance of different components, including servers, databases, and microservices. Metrics such as CPU usage, memory utilization, and response times are monitored.
- Performance Monitoring: Performance monitoring tools are employed to track key performance indicators (KPIs) such as response times, throughput, and resource utilization. This data helps identify performance bottlenecks and optimize system performance.
- Log Management: Logs are generated by various system components and are stored centrally for analysis and troubleshooting. Logging frameworks and tools are used to capture relevant events, errors, and debugging information.
- Alerting and Notifications: Thresholds and rules are set up in the monitoring system to trigger alerts and notifications when specific conditions or anomalies are detected. This enables proactive identification and resolution of issues.
- Log Analysis and Reporting: Log data is analyzed using log analysis tools to gain insights into system behavior, identify patterns, and troubleshoot issues. Reports and dashboards are generated to provide visibility into system performance and health.
Low-Level Design:
Detailed Component Design: The low-level design of each individual component involves defining their responsibilities, interfaces, and interactions. It includes:
- User Interface (UI): The UI component includes the design of web pages or mobile screens, their layout, visual elements, and interaction patterns. It interacts with the backend components through API calls to fetch and submit data.
- API Gateway: The API Gateway component is responsible for handling incoming client requests and routing them to the appropriate microservices. It provides a unified interface for API consumers and enforces security, authentication, and rate limiting.
- Microservices: Each microservice is designed with a specific business functionality and has well-defined APIs. The low-level design includes specifying the data models, business logic, and interactions with other microservices. The microservices communicate with each other through synchronous HTTP calls, asynchronous messaging systems, or event-driven architectures.
- Databases: The low-level design of databases involves defining the schema, tables, relationships, and indexes. It includes specifying data access patterns, optimizing queries, and ensuring data consistency and integrity.
Algorithms and Data Structures: The system utilizes various algorithms and data structures for efficient processing and storage of data. Some examples include:
- Search Algorithms: Algorithms like binary search or hash-based search are used to efficiently retrieve data from sorted or indexed data structures.
- Sorting Algorithms: Sorting algorithms like quicksort or mergesort are used to order data in ascending or descending order based on specific criteria.
- Data Structures: Data structures such as arrays, linked lists, trees (binary, B-trees), hash tables, or graphs are employed based on the requirements of different components.
- Caching Algorithms: LRU (Least Recently Used) or LFU (Least Frequently Used) caching algorithms are used to determine which data should be cached or evicted from the cache.
Database Schema Design: The database schema design involves specifying the tables, their columns, data types, relationships (one-to-one, one-to-many, many-to-many), and constraints. It includes considerations for normalization, denormalization, indexing strategies, and query optimization. The schema design ensures efficient storage, retrieval, and manipulation of data.
Caching and Performance Optimization: Caching is utilized to improve performance, and specific strategies are employed for optimal caching:
- Distributed Caching: A distributed caching system like Redis or Memcached is employed to store frequently accessed data in memory. The caching system is designed to be distributed across multiple nodes, ensuring high availability and scalability.
- Cache Invalidation: Strategies such as time-based expiration, event-based invalidation, or manual invalidation are used to invalidate cached data when the underlying data changes. This ensures data consistency between the cache and the data source.
- Cache Segmentation: Large datasets or frequently accessed data can be segmented into multiple caches based on access patterns. This allows for efficient management of caches and reduces cache lookup overhead.
- Cache Synchronization: In distributed systems where data is replicated across multiple caches, cache synchronization mechanisms like cache coherence protocols or cache invalidation techniques are employed to ensure consistency among caches.
- Error Handling and Exception Management: The system follows a comprehensive approach to handle errors and exceptions:
- Error Classification: Errors are classified into different categories based on their severity and impact on the system. Common categories include client errors (e.g., invalid input), server errors (e.g., internal server failure), and third-party service errors.
- Error Logging: Errors and exceptions are logged with relevant information such as timestamps, error messages, stack traces, and associated request/response data. This facilitates debugging and troubleshooting.
- Exception Handling: Exception handling mechanisms, such as try-catch blocks, are implemented at appropriate levels within the system to catch and handle exceptions gracefully. Specific exception types are defined to differentiate between different types of errors.
- Error Messaging and Responses: Clear and informative error messages are provided to users or clients to help them understand the nature of the error and guide them towards resolution. Error responses follow standard formats (e.g., JSON or XML) and include appropriate HTTP status codes.
Concurrency and Threading: To handle concurrent requests and manage threads effectively, the system employs the following strategies:
- Thread Pooling: A thread pool is used to manage a pool of reusable threads. This allows for efficient handling of concurrent requests, as threads are not created and destroyed for every request.
- Synchronization Mechanisms: Synchronization techniques such as locks, semaphores, or mutexes are used to ensure thread safety and prevent race conditions when accessing shared resources.
- Asynchronous Processing: Asynchronous programming paradigms, such as callbacks, promises, or async/await, are utilized to handle concurrent requests without blocking threads. This improves overall system responsiveness and scalability.
- Parallel Execution: In scenarios where parallelism is beneficial, parallel processing techniques, such as multi-threading or parallel programming models like MapReduce, are employed to divide tasks across multiple threads or processors.
Third-Party Integrations: The system incorporates third-party integrations using the following design considerations and patterns:
- API-based Integration: External services or APIs are integrated into the system by defining interfaces and contracts that specify how the system interacts with them. This allows for seamless communication and data exchange between the system and external services.
- Adapter or Wrapper Patterns: Adapter or wrapper patterns are used to encapsulate the specific APIs or protocols of external services and provide a unified interface within the system. This simplifies integration and decouples the system from changes in the external services.
- Webhooks or Event-driven Integrations: Event-driven architectures or webhooks are employed to enable asynchronous and real-time interactions with external services. This allows the system to react to events or notifications triggered by external services.
- Data Transformation and Mapping: Data transformation and mapping techniques are employed to ensure compatibility between data formats and structures used by the system and external services. This includes mapping data fields, converting data types, or applying data transformations during data exchange.
Testing and Quality Assurance: To ensure the system’s quality and reliability, comprehensive testing strategies and quality assurance practices are followed:
- Unit Testing: Each component is thoroughly tested in isolation using unit tests. Mocking frameworks are used to simulate dependencies and ensure independent testing. Test coverage tools are employed to assess the completeness of unit tests.
- Integration Testing: Integration tests verify the interactions and compatibility between different components or services. This includes testing API integrations, data flow between microservices, and external service integrations.
- Performance Testing: Performance testing is conducted to evaluate the system’s performance under different load conditions. Tools like JMeter or Gatling are used to simulate high loads and measure response times, throughput, and resource utilization.
- Security Testing: Security testing, including vulnerability assessments, penetration testing, and security code reviews, is conducted to identify and address potential security vulnerabilities. Techniques such as OWASP Top 10 testing, input validation testing, and authentication/authorization testing are employed.
- Regression Testing: Regression tests are performed to ensure that system modifications or new feature additions do not introduce unintended side effects or regressions in existing functionality. Automated regression testing frameworks or tools are used to streamline this process.
- Load Testing: Load testing is conducted to assess the system’s performance and stability under expected or peak loads. It involves simulating concurrent user interactions and measuring response times, throughput, and resource utilization.
- User Acceptance Testing (UAT): UAT involves engaging end-users to test the system and provide feedback on its usability and functionality. This ensures that the system meets user requirements and expectations.
- Continuous Integration and Deployment: Continuous integration (CI) and continuous deployment (CD) practices are followed to automate the build, testing, and deployment processes. This ensures faster feedback cycles, early detection of issues, and frequent releases with improved quality.
- Code Reviews and Static Analysis: Code reviews are conducted to ensure adherence to coding standards, identify potential bugs or vulnerabilities, and share knowledge among team members. Static analysis tools are used to analyze code for potential issues, code smells, or security vulnerabilities.
- Quality Assurance Processes: Quality assurance practices such as peer reviews, documentation reviews, and adherence to coding guidelines and best practices are followed to maintain high-quality code and system reliability.
Consistent Hashing:
Hashing is a technique used to map data of arbitrary size to a fixed-size value, known as a hash. It is commonly used for data indexing, data retrieval, or ensuring data integrity.
Problem of Data Distribution: In a distributed system, distributing data across multiple nodes can be challenging. Traditional hashing techniques, such as modulo hashing, can lead to significant data redistribution when nodes are added or removed, causing performance degradation and increased overhead.
Basic Hashing: Basic hashing techniques involve using modulo or division operations to map data to a fixed number of nodes or buckets. When nodes are added or removed, the entire data distribution needs to be recalculated, resulting in data movement and disruption.
Consistent Hashing Algorithm: Consistent hashing solves the data distribution problem by introducing a hash ring and assigning each node or bucket a position on the ring. Data is mapped to the nearest node clockwise on the ring.
When a node is added or removed, only a fraction of the data needs to be remapped, minimizing data redistribution. Each node is responsible for a range of hash values on the ring, and additional virtual nodes can be introduced to balance the data distribution.
Ring Structure and Virtual Nodes: The consistent hashing algorithm uses a ring structure, where the hash values are treated as a circular continuum. Nodes are placed on the ring based on their hash values, forming a distributed structure.
Virtual nodes are introduced to balance the data distribution among physical nodes. Each physical node can be represented by multiple virtual nodes on the ring, increasing the opportunities for data distribution.
Load Balancing and Scaling: Consistent hashing enables load balancing by distributing the data across multiple nodes uniformly. As the number of nodes increases or decreases, the data distribution remains stable, and the load is evenly distributed.
Scaling the system becomes easier with consistent hashing, as adding or removing nodes requires redistributing only a portion of the data, minimizing disruption and maintaining system performance.
Failure Handling and Resilience: Consistent hashing provides resilience in the face of node failures. When a node fails, the data originally assigned to that node is redirected to the next available node in the clockwise direction on the ring, ensuring data availability and minimizing the impact of node failures.
Use Cases and Applications: Consistent hashing finds applications in various distributed systems and scenarios, including:
- Distributed Caching: Consistent hashing is commonly used in distributed caching systems like Memcached or Redis. It allows for efficient data distribution across cache nodes, ensuring high cache hit rates and minimizing cache misses.
- Content Delivery Networks (CDNs): CDNs use consistent hashing to distribute content across edge servers located worldwide. It ensures that content requests are directed to the nearest server, reducing latency and improving content delivery performance.
- Peer-to-Peer Networks: Consistent hashing is utilized in peer-to-peer networks to allocate data chunks or resources among participating peers. It enables efficient lookup and retrieval of data in a decentralized manner.
- Key-Value Stores: Distributed key-value stores, such as DynamoDB or Riak, employ consistent hashing to partition and distribute data across multiple storage nodes. It allows for scalable storage and retrieval of key-value pairs.
- Database Sharding: Sharding databases horizontally using consistent hashing enables efficient data distribution and scalability. It ensures that each shard handles a balanced load and minimizes data movement when adding or removing shards.
- Load Balancers: Consistent hashing algorithms are used in load balancers to distribute incoming requests across multiple backend servers or services. It ensures that requests are consistently routed to the same server based on their hashed key, enabling session affinity and minimizing request redirection.
- Distributed File Systems: Distributed file systems like Hadoop HDFS or Cassandra use consistent hashing to distribute file blocks across multiple storage nodes. It allows for parallel processing, fault tolerance, and scalable storage.
That’s it for now!
Read Part 5 of System Design Series —
CAP Theorem
Caching
Indexing
Proxies
Keep learning and coding :)
Day 2 : SQL Basics, Query Structure, Built In functions Conditions
Day 4 : Set Theory Operations, Stored Procedures and CASE statements in SQL
Day 6 : Subqueries, Group by, order by and Having clauses in SQL and Analytical Functions
Day 7 : Window Functions, Grouping Sets and Constraints in SQL
Day 8 : BigQuery Basics, SELECT, FROM, WHERE and Date and Extract in BigQuery
Day 9 : Common Expression Table, UNNEST Clause, SQL vs NoSQL Databases
Day 10 : Triggers, Pivot and Cursors in SQL
Day 14 : MySQL in Depth
Day 15 : PostgreSQL inDepth
Anyways, For Day 15 of 15 days of Advanced SQL, we will cover —
PostgreSQL inDepth
Github for Advanced SQL that you can follow —
All the projects, data structures, algorithms, system design, Data Science and ML, Data Engineering, MLOps and Deep Learning videos will be published on our youtube channel ( just launched).
Subscribe today!
System Design Case Studies — In Depth
Complete Data Structures and Algorithm Series
Github —
Some of the other best Series —
30 days of Data Structures and Algorithms and System Design Simplified
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
For Python Projects —
For complete 60 days of Data Science and ML : Day 1 — Day 60 : Quick Recap of 60 days of Data Science and ML
Follow for more updates. Stay tuned and keep coding!
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras





