
Pandas — DataFrames
The Primary Pandas Data Structure! It Is a Dict-Like Container for Series Objects— #PySeries#Episode 08
Hello, let’s see Pandas AGAIN!
This time, DataFrame!

Here are the topics for our study about Pandas Series:
.Series
.DataFrames (this one:)
.Missing Data
.GroupBy
.Merging, Joinning, and Cocarenating
.Operations
.Data Input and Output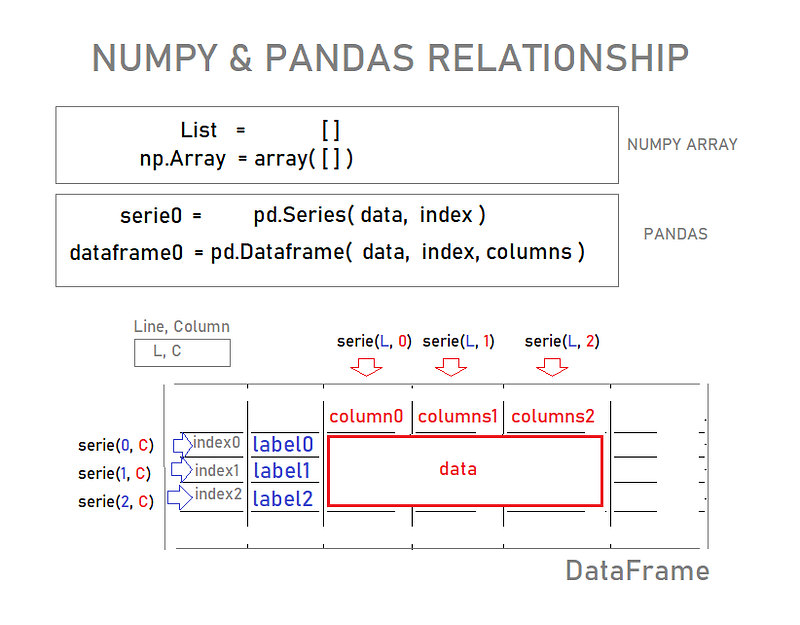
The second topic will be this one: DataFrames!
DATAFRAMES
The primary Pandas data structure!
Can be thought of as a dict-like container for Series objects.
import numpy as np
import pandas as pdAnd for our database creation:
from numpy.random import randnLet's seed it, so our data is the same (in case you want to follow me:)
np.random.seed(101)How To Create a DataFrame
For the purpose of our studying, here is how:
DataFrame(Data, xLabel, yLabel):
df=pd.DataFrame(randn(5,4), ['A','B','C','D','E'], ['W','X','Y','Z' ])Note: to work on your code you may need to retype the single quotes (´), compatible with your system;)
Now call the object:
df
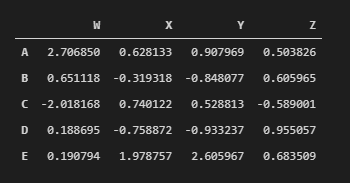
Each of these columns and row is Series themselves!
INDEXING & SELECTION IN PANDAS
Using Brackets Notation:
Just pass in the column name, ie ‘W’:
df[‘W’]A 2.706850
B 0.651118
C -2.018168
D 0.188695
E 0.190794
Name: W, dtype: float64See what type of object df is:
type(df['W'])pandas.core.series.SeriesSee ‘W’ is just a Series!
And The DataFrame itself?
type(df)pandas.core.frame.DataFrameThe df itself is the DataFrame!
Using SQL Notation:
Note: not recommended, because we can confuse with the real method of df object!
So, always use the bracket Notation when it comes to rescuing series from df :)
Anyway, here you have it!
# This is SQL Notation: Not recommended :/df.WA 2.706850
B 0.651118
C -2.018168
D 0.188695
E 0.190794
Name: W, dtype: float64# Use Bracket Notation [] instead :)Getting Multiple Columns back!
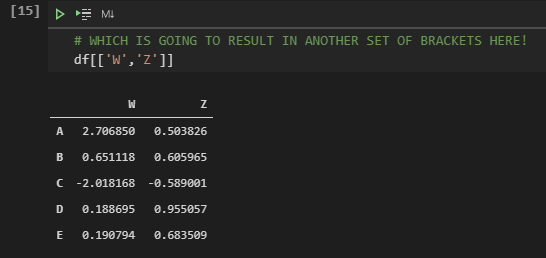
Pass in a List, please!
# WHICH IS GOING TO RESULT IN ANOTHER SET OF BRACKETS HERE!df[[‘W’,’Z’]]
Creating a New Column
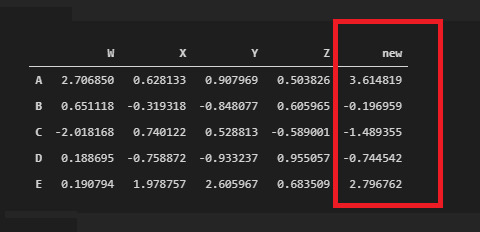
Just make some arithmetic on the right side with the series you want to create your column:
df[‘new’] = df[‘W’] + df[‘Y’]df
Dropping Columns
Pandas requires that you specify that you really want to modify your data in place (affect the original DB);
It is like so you do not accidentally lose information;
In case you’ve done a bunch of adjustments to your data, you don’t want to accidentally lose it, right?
This is like ‘commit’ in DB!
df.drop(‘new’, axis=1, inplace=True)df
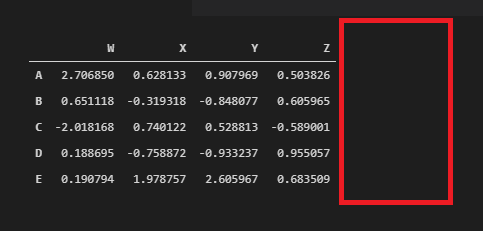
Dropping Rows
This time I am not doing this in place!
Note: axis=0 is the default, so you don’t need to specify it here:)
dropped_df = df.drop(‘E’, axis=0)
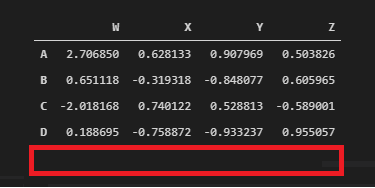
See that our DataFrame has not been affected yet by the last drop! We didn’t make it in place, remember?
# Shape returns a tuple dimension (row, column)
df.shape(5, 4)See, df isn’t affected yet!
df
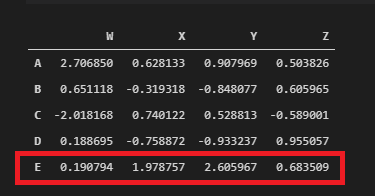
Selecting Rows
There are two methods:
- LOC -> label-BASE index
- ILOC -> numerical-BASE index
IT’S A LITTLE WEIRD HOW THE METHODS ARE CALLED IN PANDAS:
IT USES A SQUARED BRACKET!
But that’s the way it works for Pandas!
# This returns a series of that ‘A’ row!
df.loc[‘A’]W 2.706850
X 0.628133
Y 0.907969
Z 0.503826
Name: A, dtype: float64Or alternatively, type the index of the row required!
# This is a numerical-BASE index locator = iloc
df.iloc[0]W 2.706850
X 0.628133
Y 0.907969
Z 0.503826
Name: A, dtype: float64Returning a Single Value
# INDEXING
df.loc[‘B’, ‘Y’]-0.8480769834036315Returning the same as previous, just locating it.
# Grab the element on the second row (‘B’)
# and in the third column (‘Y’), right?df.iloc[1,2]-0.8480769834036315Returning a SUB-SET of the DataFrame
Just pass two lists of the rows and columns you want!
# Please, get used to the SQUARED BRACKET :/df.loc[[‘A’, ‘B’],[‘W’, ‘Y’]]WYA2.7068500.907969B0.651118–0.848077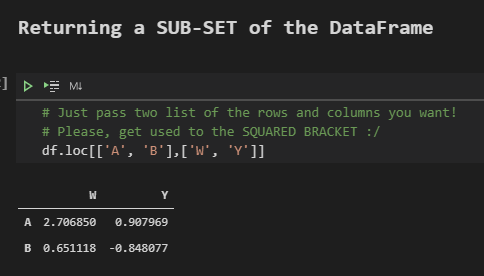
And that’s it!
print(“Ok, we’re going to stop here for now and continue the discussion in the next PySeries Episode!” )Ok, we’re going to stop here for now and continue the discussion in the next PySeries Episode!
# https://medium.com/jungletronics/pandas-dataframes-7ba872dcbc30
print(‘Thank You for reading This post!. Bye!’)Thank You for reading this post! Bye!
We’re gonna be alright. Live From home!
The code bundle for this episode is available at:
GitHub Repo link
Colab Link
Credits & References:
Jose Portilla — Python for Data Science and Machine Learning Bootcamp — Learn how to use NumPy, Pandas, Seaborn , Matplotlib , Plotly , Scikit-Learn , Machine Learning, Tensorflow , and more!
Posts Related:
00Episode#PySeries — Python — Jupiter Notebook Quick Start with VSCode — How to Set your Win10 Environment to use Jupiter Notebook
01Episode#PySeries — Python — Python 4 Engineers — Exercises! An overview of the Opportunities Offered by Python in Engineering!
02Episode#PySeries — Python — Geogebra Plus Linear Programming- We’ll Create a Geogebra program to help us with our linear programming
03Episode#PySeries — Python — Python 4 Engineers — More Exercises! — Another Round to Make Sure that Python is Really Amazing!
04Episode#PySeries — Python — Linear Regressions — The Basics — How to Understand Linear Regression Once and For All!
05Episode#PySeries — Python — NumPy Init & Python Review — A Crash Python Review & Initialization at Numpy lib.
06Episode#PySeries — Python — NumPy Arrays & Jupyter Notebook — Arithmetic Operations, Indexing & Selection, and Conditional Selection
07Episode#PySeries — Python — Pandas — Intro & Series — What it is? How to use it?
08Episode#PySeries — Python —Pandas DataFrames — The primary Pandas data structure! It is a dict-like container for Series objects (this one)
09Episode#PySeries — Python — Python 4 Engineers — Even More Exercises! — More Practicing Coding Questions in Python!
10Episode#PySeries — Python — Pandas — Hierarchical Index & Cross-section — Open your Colab notebook and here are the follow-up exercises!
11Episode#PySeries — Python — Pandas — Missing Data — Let’s Continue the Python Exercises — Filling & Dropping Missing Data
12Episode#PySeries — Python — Pandas — Group By — Grouping large amounts of data and compute operations on these groups
13Episode#PySeries — Python — Pandas — Merging, Joining & Concatenations — Facilities For Easily Combining Together Series or DataFrame
14Episode#PySeries — Python — Pandas — Pandas Dataframe Examples: Column Operations
15Episode#PySeries — Python — Python 4 Engineers — Keeping It In The Short-Term Memory — Test Yourself! Coding in Python, Again!
16Episode#PySeries — NumPy — NumPy Review, Again;) — Python Review Free Exercises
17Episode#PySeries — Generators in Python — Python Review Free Hints
18Episode#PySeries — Pandas Review…Again;) — Python Review Free Exercise
19Episode#PySeries — MatlibPlot & Seaborn Python Libs — Reviewing theses Plotting & Statistics Packs
20Episode#PySeries — Seaborn Python Review — Reviewing theses Plotting & Statistics Packs
31 Episode#PySeries — Pandas — DATAFRAMES — When should I use pandas DataFrame?#PySeries#Episode 31
