
What is Uber’s Ludwig?
An open-source framework for low code ML …

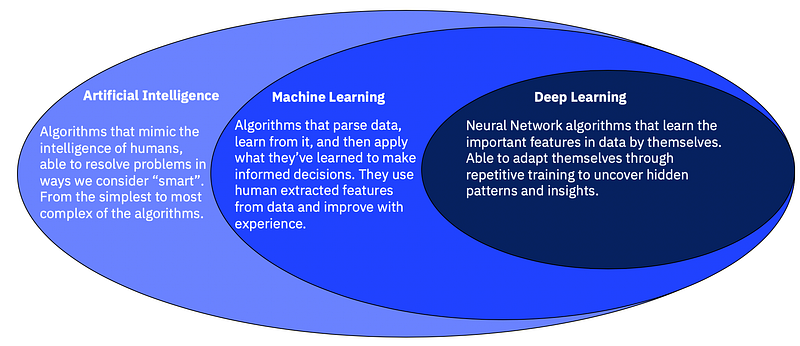
Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed. Its a subset of artificial intelligence that focuses mainly on the machine, learning from their experience and making predictions based on its experience.
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
What are the different types of Machine Learning?
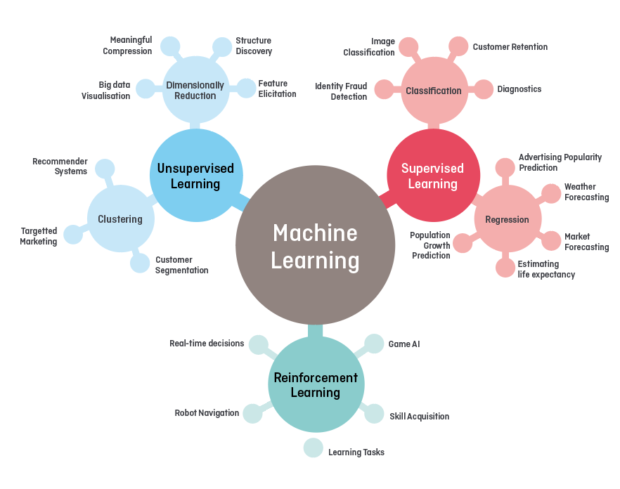
- Supervised Machine Learning — Supervised learning is when the model is getting trained on a labeled dataset. The labeled dataset is one that has both input and output parameters. In this type of learning both training and validation, datasets are labeled

- Unsupervised Machine Learning — The model learns through observation and finds structures in the data. Once the model is given a dataset, it automatically finds patterns and relationships in the dataset by creating clusters in it. What it cannot do is add labels to the cluster.

- Reinforcement Machine Learning — Reinforcement learning is the training of machine learning models to make a sequence of decisions. The agent learns to achieve a goal in an uncertain, potentially complex environment. In reinforcement learning and artificial intelligence faces a game-like situation. The computer employs trial and error to come up with a solution to the problem.

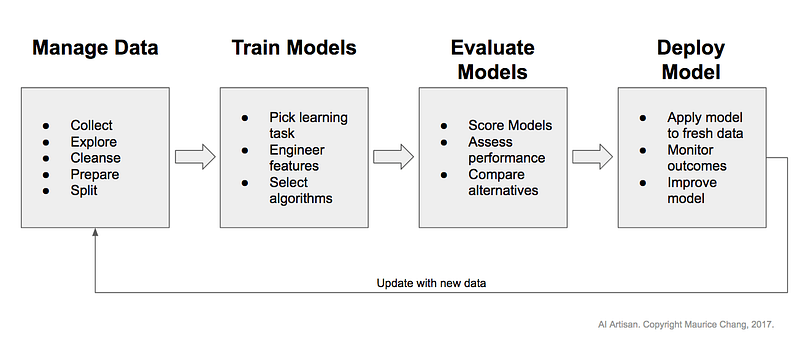
Different Stages of ML
Deep Learning
Deep learning is a branch of machine learning, in essence, its the implementation of neural networks with more than a single hidden layer of neurons.
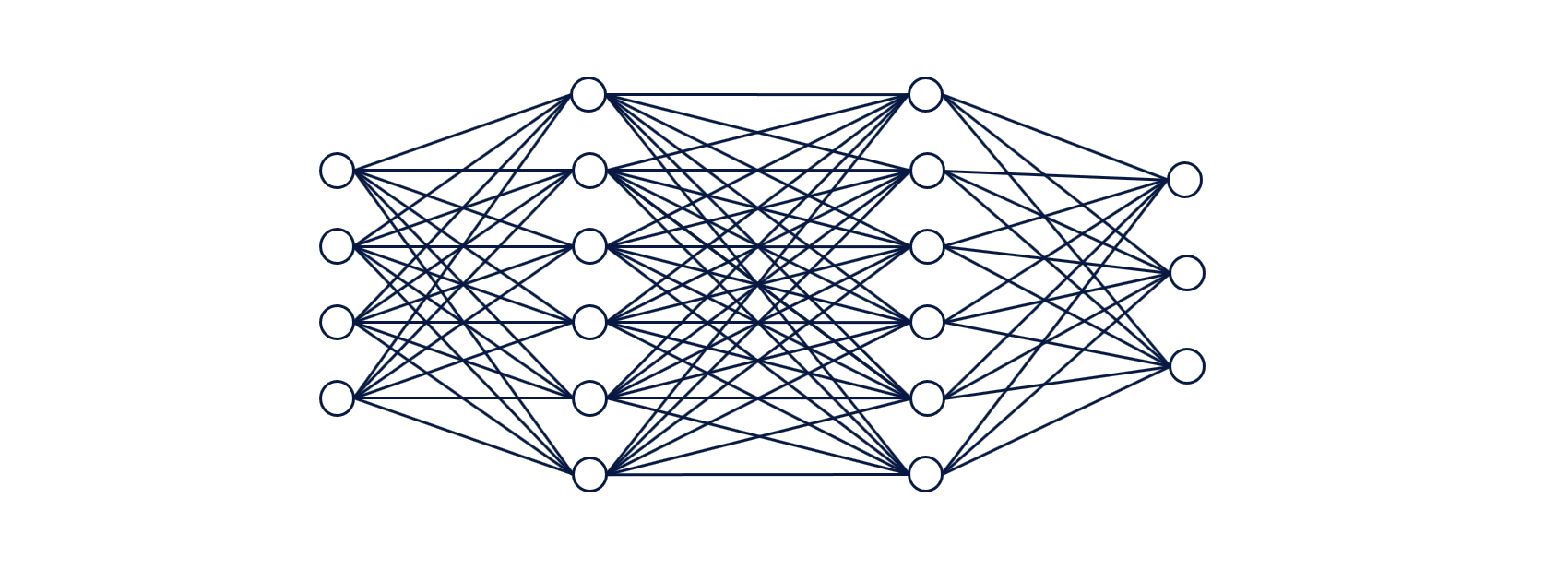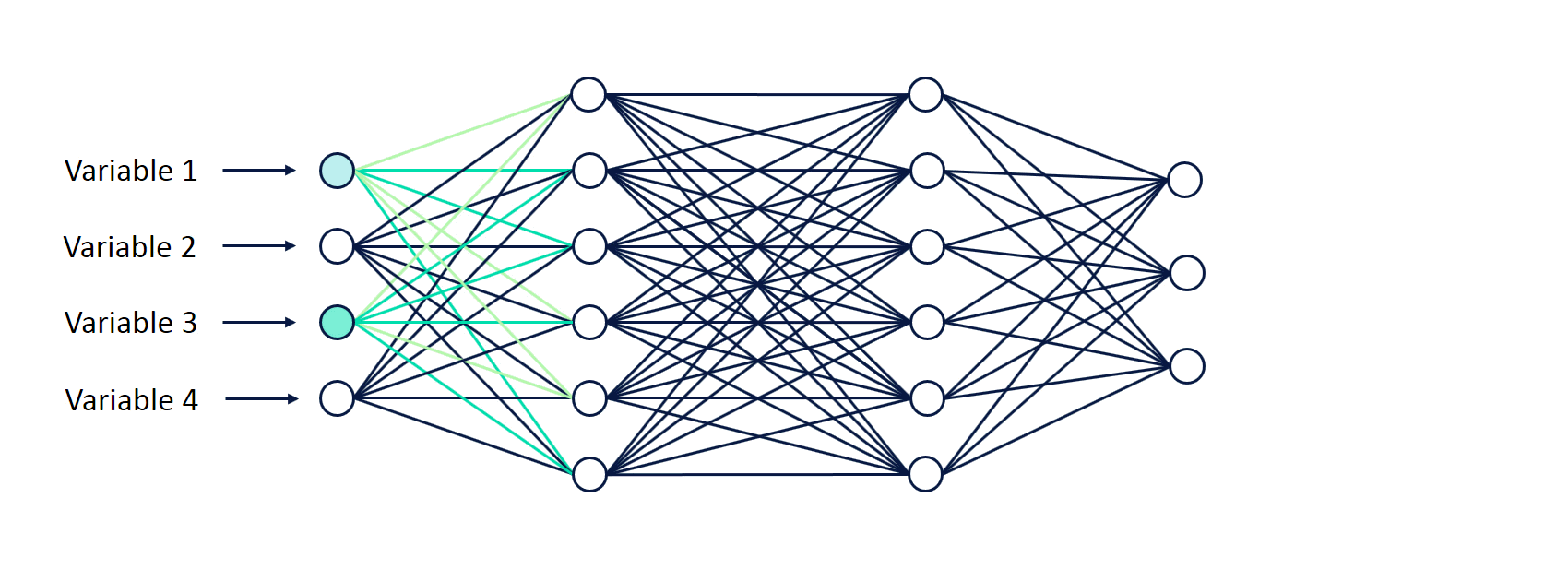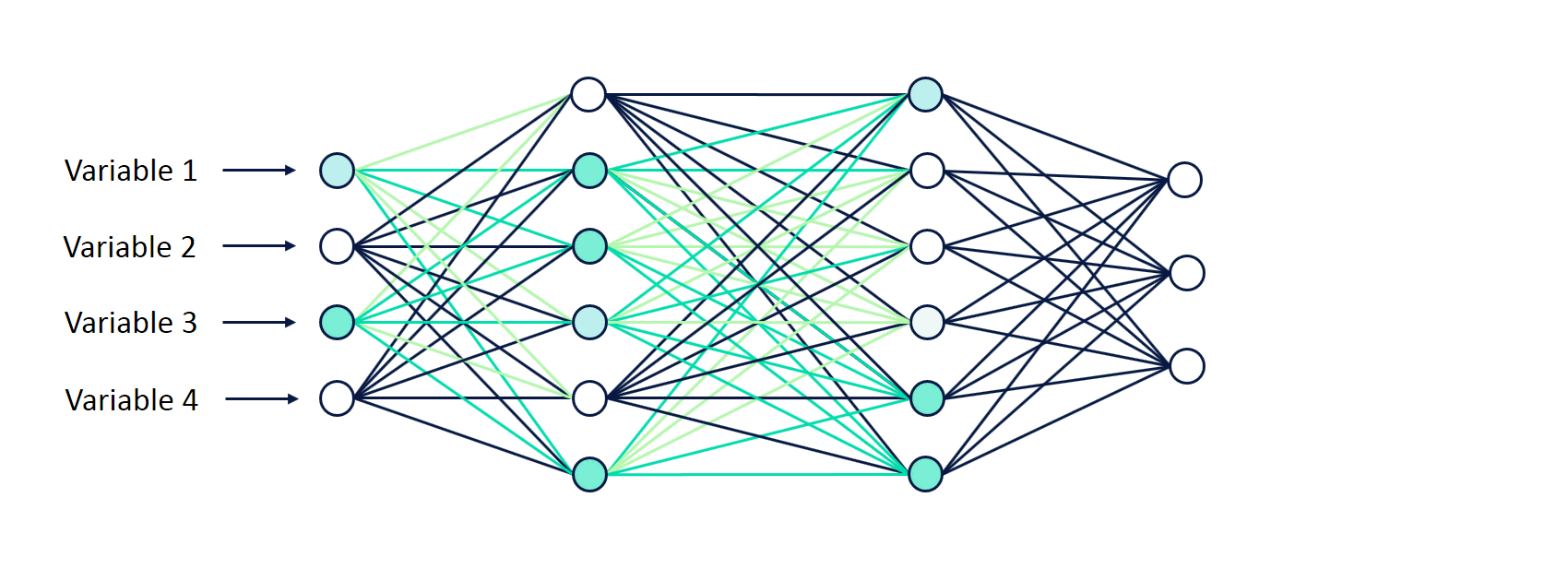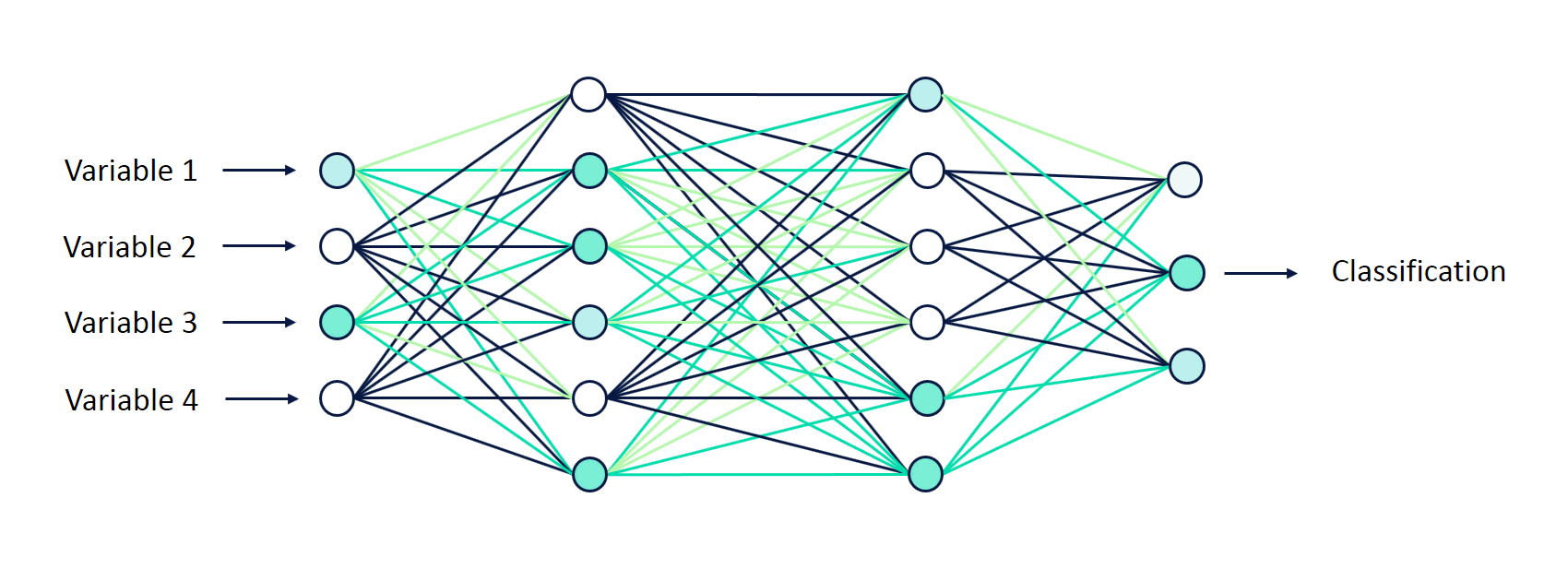
The stages of training and testing deep-learning require sophisticated knowledge of the ML architectures and data infrastructure. As a solution, Uber introduced a framework for training and testing deep learning models without the need to write code and named it Ludwig —
Ludwig is a toolbox built on top of TensorFlow that allows us to train and test deep learning models without the need to write code.
The core design principles of Ludwig are (source: Ludwig Github):
- No coding required: no coding skills are required to train a model and use it for obtaining predictions.
- Generality: a new data type-based approach to deep learning model design that makes the tool usable across many different use cases.
- Flexibility: experienced users have extensive control over model building and training, while newcomers will find it easy to use.
- Extensibility: easy to add new model architecture and new feature data types.
- Interpretability and Understandability: Ludwig includes visualizations that help data scientists understand the performance of machine learning models.

- Ludwig uses a modular design, where each component of the model, such as the encoder, decoder, and head, is implemented as a separate module. This design allows you to easily mix and match components to build a custom model that fits your specific use case.
- To use Ludwig, you first prepare your data in a tabular format, such as a CSV file. Then, you define your model architecture using a YAML configuration file that specifies the input and output features, the encoder and decoder to use, and any additional hyperparameters.
- Next, you train the model using the Ludwig command-line interface. Ludwig takes care of the training process, including splitting the data into training and validation sets, setting up the optimizer and loss function, and training the model for a specified number of epochs.
- Finally, you can test the model on a new dataset using the same command-line interface, and Ludwig will generate evaluation metrics such as accuracy, precision, recall, and F1 score.
Ludwig’s goal is to make it easy for people with limited machine learning experience to quickly train and test machine learning models, and to allow experts to experiment with new models and ideas quickly without having to write code from scratch.
How to work with Ludwig?
Input as a CSV file containing your data, a list of columns, and a list of columns to use as outputs, Ludwig will do the rest. Simple commands can be used to train models both locally and in a distributed way, and to use them to predict on new data.
Ludwig API —
A programmatic API can be plugged to use Ludwig from your python code. A suite of visualization tools allows you to analyze models’ training and test performance and to compare them.
There are 4 steps —
1. Install
Just run pip install ludwig and it will be ready to use.
Ludwig’s basic requirements are the following:
- tensorflow
- numpy
- pandas
- python 3
- scipy
- scikit-learn
- Cython
- h5py
- tabulate
- tqdm
- PyYAML
- absl-py
2. Train
Prepare your data in a CSV file, define input and output feature in a model definition YAML file and run:
ludwig train
--data_csv file.csv
--model_definition definition.yaml3. Predict
Prepare your data in a CSV file and use a pre-trained model to predict the output targets:
ludwig predict
--data_csv data.csv
--model path_to_model4. Visualize
Ludwig comes with many visualization options. If you want to look at the learning curves of your model for instance, run:
ludwig visualize
--visualization learning_curves
--training_statistics train_statistics.jsonFor API —
Train models and use them to predict directly from Python
from ludwig.api import LudwigModel# train a model
model_definition = {...}
model = LudwigModel(model_definition)
train_stats = model.train(training_dataframe)
# or load a model
model = LudwigModel.load(model_path)# obtain predictions
predictions = model.predict(test_dataframe)When to use Ludwig?
Ludwig can be used by practitioners to quickly train and test deep learning models as well as by researchers to obtain strong baselines that can be used to compare and have an experimentation setting that ensures comparability by performing standard data preprocessing and visualization.
Ludwig provides two main functionalities: training models and then use these to predict.
Ludwig is based on datatype abstraction which means that the data preprocessing and postprocessing will be performed on different datasets that share data types and the same encoding and decoding models developed for one task can be reused for different tasks.
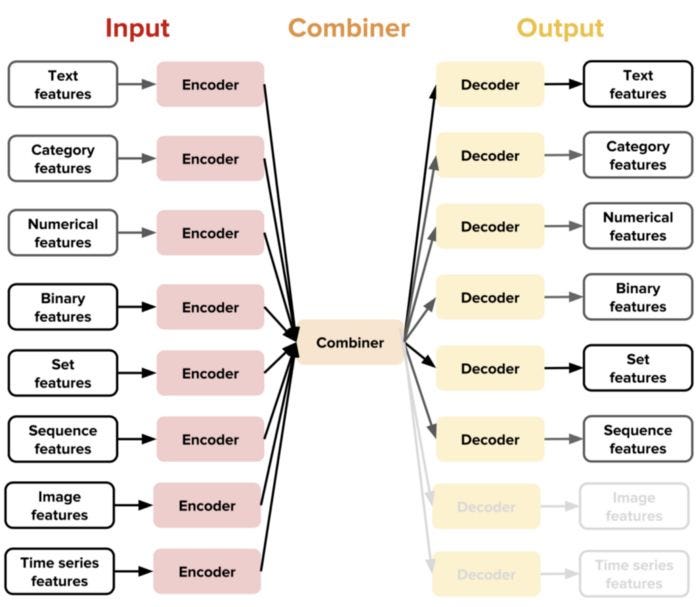
Example —
Input your image_classification.csv which has a column containing path/url to the image to be classified.
ludwig experiment \ --data_csv image_classification.csv \ --model_definition_file model_definition.yamlWith model_definition.yaml
input_features:
-
name: image_path
type: image
encoder: stacked_cnnoutput_features:
-
name: class
type: categoryReferences and credits —