
Day 5: 30 days of Natural Language Processing Series with Projects
SpaCy with a project — Part 1
Welcome back peeps. Hope you all’s well at your end. Work is getting hectic everyday so day 5 post is bit delayed. Anyways, in the last few posts we learned the basics of SpaCy (Go through below posts before starting this project)
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
In this post we are going to build a project in which we will implement —
- Tokenization
- POS tagging
- Chunking
- Named Entities Recognition ( NER)
For the basics of NLP and pre-requisites read the below post ( complete this before starting this project)—
Let’s dive in!
- Tokenization is the process of breaking down a string of text into individual words or phrases (called tokens).
- POS (part-of-speech) tagging is the process of marking each token in a text with its corresponding part of speech, such as noun, verb, adjective, etc.
- Chunking is the process of grouping tokens together into “chunks” that represent a complete idea or concept.
- Named Entity Recognition (NER) is the process of identifying and classifying named entities, such as people, organizations, and locations, in a text.
Import Necessary Libraries
import seaborn as sns
import matplotlib.pyplot as pltimport pandas as pd
import numpy as np
import spacy
import explacy
from spacy import displacy
%matplotlib inlineLoad Dataset
df=pd.read_csv('../Path to file/Data.csv')
df.shapeOutput —
(568454, 10)Analyze Data and Visualization
# Get all the information about the datadf.info()Output —
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 568454 entries, 0 to 568453
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 568454 non-null int64
1 ProductId 568454 non-null object
2 UserId 568454 non-null object
3 ProfileName 568438 non-null object
4 HelpfulnessNumerator 568454 non-null int64
5 HelpfulnessDenominator 568454 non-null int64
6 Score 568454 non-null int64
7 Time 568454 non-null int64
8 Summary 568427 non-null object
9 Text 568454 non-null object
dtypes: int64(5), object(5)
memory usage: 43.4+ MBGet the Statistics —
# Get the statisticsdf.describe()Find duplicates —
# Find duplicatesdf.duplicated().sum()Output —
0
Find null values —
# Find if null values existsdf.isna().sum()Output —
Id 0
ProductId 0
UserId 0
ProfileName 16
HelpfulnessNumerator 0
HelpfulnessDenominator 0
Score 0
Time 0
Summary 27
Text 0
dtype: int64Get Categorical Columns in the Dataset —
# Get categorical Featurescategorical_features = [feature for feature in df.columns if df[feature].dtypes == 'O']
print('Categorical Columns in the Dataset: ',categorical_features)Output —
Categorical Variables in the Dataset: ['ProductId', 'UserId', 'ProfileName', 'Summary', 'Text']Extract Text and Score Columns —
#Text and Score columns new_df = df[['Text','Score']].dropna()Visualization —
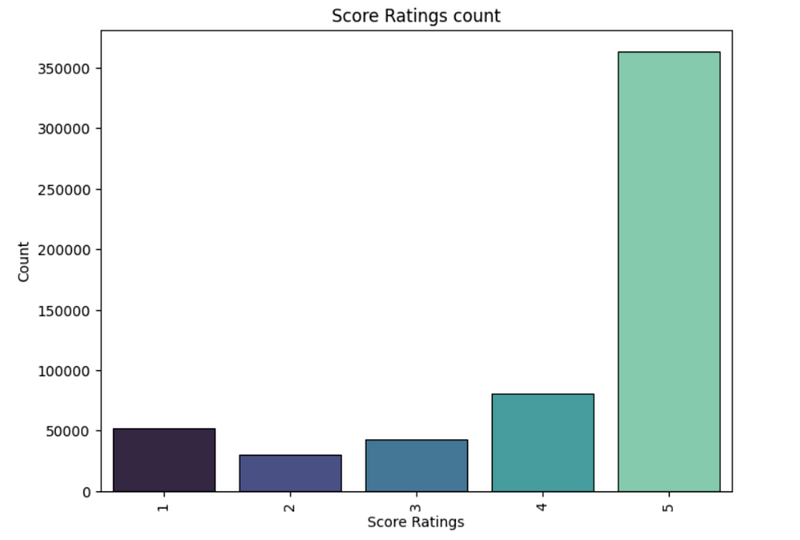
plt.figure(figsize=(8,6),dpi=100)
score_index=df['Score'].value_counts().index
score_values = df['Score'].value_counts().values
sns.barplot(x=score_index,y=score_values,palette ='mako',edgecolor='black',linewidth=0.8)
plt.xlabel('Score Ratings')
plt.ylabel('Count')
plt.title('Score Ratings count')
plt.xticks(rotation =90)
plt.show()Output —
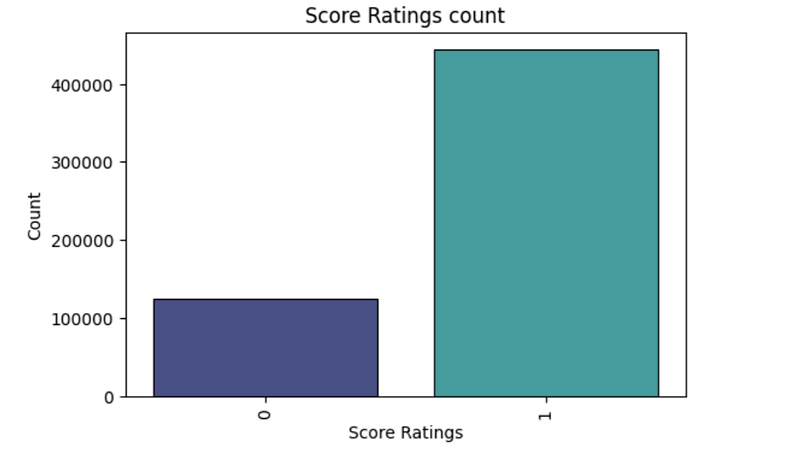
# Separate scores new_df.Score[df.Score<=3]=0
new_df.Score[df.Score>3]=1
new_df.Score.value_counts()Output —
1 443777
0 124677
Name: Score, dtype: int64Visualize again!
plt.figure(figsize=(6,4),dpi=100)
score_index=new_df['Score'].value_counts().index
score_values = new_df['Score'].value_counts().values
sns.barplot(x=score_index,y=score_values,palette ='mako',edgecolor='black',linewidth=0.8)
plt.xlabel('Score Ratings')
plt.ylabel('Count')
plt.title('Score Ratings count')
plt.xticks(rotation =90)plt.show()Output —
Split Train and Validation data —
# Prepare train dataset
positive_train_df=new_df[new_df.Score==1][:50000]
negative_train_df=new_df[new_df.Score==0][:50000]# Prepare Validation datasetpositive_val_df=new_df[new_df.Score==1][50000:70000]
negative_val_df=new_df[new_df.Score==0][50000:70000]
val_df=positive_val_df.append(negative_val_df)
val_df.shapeOutput —
(40000, 2)SpaCy
# load the modeltn = spacy.load('en_core_web_sm')
r=new_df.Text[12]
rOutput —
"My cats have been happily eating Felidae Platinum for more than two years. I just got a new bag and the shape of the food is different. They tried the new food when I first put it in their bowls and now the bowls sit full and the kitties will not touch the food. I've noticed similar reviews related to formula changes in the past. Unfortunately, I now need to find a new food that my cats will eat."Tokenization —
# tokenize the review
tr = tn(r)
trOutput —
My cats have been happily eating Felidae Platinum for more than two years. I just got a new bag and the shape of the food is different. They tried the new food when I first put it in their bowls and now the bowls sit full and the kitties will not touch the food. I've noticed similar reviews related to formula changes in the past. Unfortunately, I now need to find a new food that my cats will eat.Explacy —
explacy.print_parse_info(tn, 'Newyork is a beautiful city')Output —
Dep tree Token Dep type Lemma Part of Sp
──────── ───────── ──────── ───────── ──────────
┌─► Newyork nsubj Newyork PROPN
┌───┴── is ROOT be AUX
│ ┌──► a det a DET
│ │┌─► beautiful amod beautiful ADJ
└─►└┴── city attr city NOUNUse explacy for the review —
explacy.print_parse_info(tn,new_df.Text[12])Output —
Dep tree Token Dep type Lemma Part of Sp
───────────────── ───────────── ──────── ───────────── ──────────
┌─► My poss my PRON
┌─►└── cats nsubj cat NOUN
│┌───► have aux have AUX
││┌──► been aux be AUX
│││┌─► happily advmod happily ADV
┌┬──────┼┴┴┴── eating ROOT eat VERB
││ │ ┌─► Felidae compound Felidae PROPN
││ └─►└── Platinum dobj Platinum PROPN
│└─►┌───────── for prep for ADP
│ │ ┌──► more amod more ADJ
│ │ │┌─► than quantmod than SCONJ
│ │ ┌─►└┴── two nummod two NUM
│ └─►└────── years pobj year NOUN
└────────────► . punct . PUNCT
┌──► I nsubj I PRON
│┌─► just advmod just ADV
┌┬┬──────────┴┴── got ROOT get VERB
│││ ┌──► a det a DET
│││ │┌─► new amod new ADJ
││└─►┌───────┴┼── bag dobj bag NOUN
││ │ └─► and cc and CCONJ
││ │ ┌─► the det the DET
││ └─►┌─────┴── shape conj shape NOUN
││ └─►┌───── of prep of ADP
││ │ ┌─► the det the DET
││ └─►└── food pobj food NOUN
│└───────────►┌── is ccomp be AUX
│ └─► different acomp different ADJ
└───────────────► . punct . PUNCT
┌─► They nsubj they PRON
┌────────┬───┴── tried ROOT try VERB
│ │ ┌──► the det the DET
│ │ │┌─► new amod new ADJ
│ └─►└┴── food dobj food NOUN
│ ┌───► when advmod when ADV
│ │┌──► I nsubj I PRON
│ ││┌─► first advmod first ADV
└─►┌──┬┬───┴┴┼── put advcl put VERB
│ ││ └─► it dobj it PRON
│ │└─►┌───── in prep in ADP
│ │ │ ┌─► their poss their PRON
│ │ └─►└── bowls pobj bowl NOUN
│ └────────► and cc and CCONJ
│ ┌─────► now advmod now ADV
│ │ ┌─► the det the DET
│ │┌─►└── bowls nsubj bowl NOUN
└─►┌──┴┴─┬┬── sit conj sit VERB
│ │└─► full acomp full ADJ
│ └──► and cc and CCONJ
│ ┌─► the det the DET
│ ┌─►└── kitties nsubj kitty NOUN
│ │ ┌──► will aux will AUX
│ │ │┌─► not neg not PART
└─►┌┼─┴┴── touch conj touch VERB
││ ┌─► the det the DET
│└─►└── food dobj food NOUN
└─────► . punct . PUNCT
┌──► I nsubj I PRON
│┌─► 've aux 've AUX
┌┬───────────┴┴── noticed ROOT notice VERB
││ ┌─► similar amod similar ADJ
│└─►┌─────────┴── reviews dobj review NOUN
│ └─►┌┬──────── related acl relate VERB
│ │└─►┌───── to prep to ADP
│ │ │ ┌─► formula compound formula NOUN
│ │ └─►└── changes pobj change NOUN
│ └──►┌───── in prep in ADP
│ │ ┌─► the det the DET
│ └─►└── past pobj past NOUN
└───────────────► . punct . PUNCT
┌────► Unfortunately advmod unfortunately ADV
│┌───► , punct , PUNCT
││┌──► I nsubj I PRON
│││┌─► now advmod now ADV
┌┬─────────┴┴┴┴── need ROOT need VERB
││ ┌─► to aux to PART
│└─►┌─────────┴── find xcomp find VERB
│ │ ┌──► a det a DET
│ │ │┌─► new amod new ADJ
│ └─►┌─────┴┴── food dobj food NOUN
│ │ ┌─────► that dobj that DET
│ │ │ ┌─► my poss my PRON
│ │ │┌─►└── cats nsubj cat NOUN
│ │ ││ ┌─► will aux will AUX
│ └─►└┴──┴── eat relcl eat VERB
└───────────────► . punct . PUNCTPart of Speech Tagging —
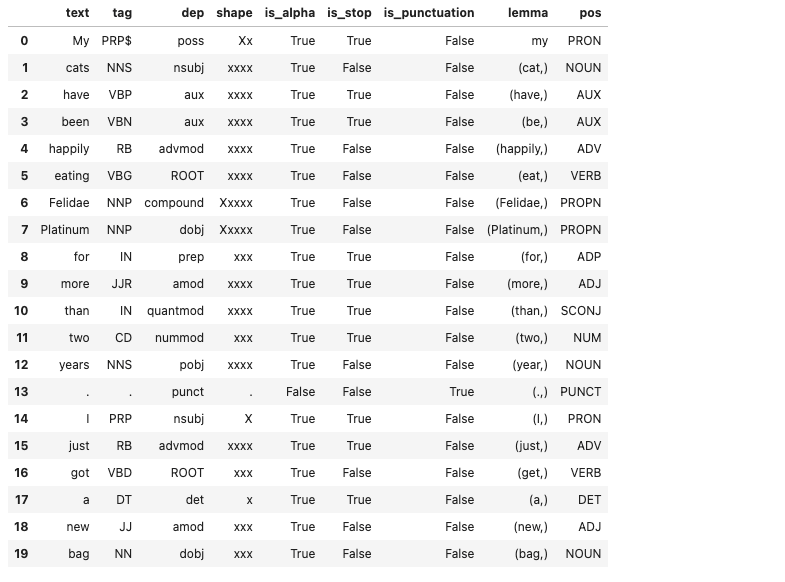
tt = pd.DataFrame()for i, token in enumerate(tr):
tt.loc[i, 'text'] = token.text
tt.loc[i, 'tag'] = token.tag_
tt.loc[i, 'dep'] = token.dep_
tt.loc[i, 'shape'] = token.shape_
tt.loc[i, 'is_alpha'] = token.is_alpha
tt.loc[i, 'is_stop'] = token.is_stop
tt.loc[i, 'is_punctuation'] = token.is_punct
tt.loc[i, 'lemma'] = token.lemma_,
tt.loc[i, 'pos'] = token.pos_tt[:20]Output —
Named Entities Recognition ( NER) —
# NERspacy.displacy.render(tr, style='ent', jupyter=True)Output —
My cats have been happily eating Felidae Platinum PERSON for more than two years DATE . I just got a new bag and the shape of the food is different. They tried the new food when I first ORDINAL put it in their bowls and now the bowls sit full and the kitties will not touch the food. I’ve noticed similar reviews related to formula changes in the past. Unfortunately, I now need to find a new food that my cats will eat.
Chunking —
# Chunkingnc = pd.DataFrame()for i, chunk in enumerate(tr.noun_chunks):
nc.loc[i, 'text'] = chunk.text
nc.loc[i, 'root.text'] = chunk.root.text,
nc.loc[i, 'root.dep_'] = chunk.root.dep_
nc.loc[i, 'root.head.text'] = chunk.root.head.text
nc.loc[i, 'root'] = chunk.root
nc[:20]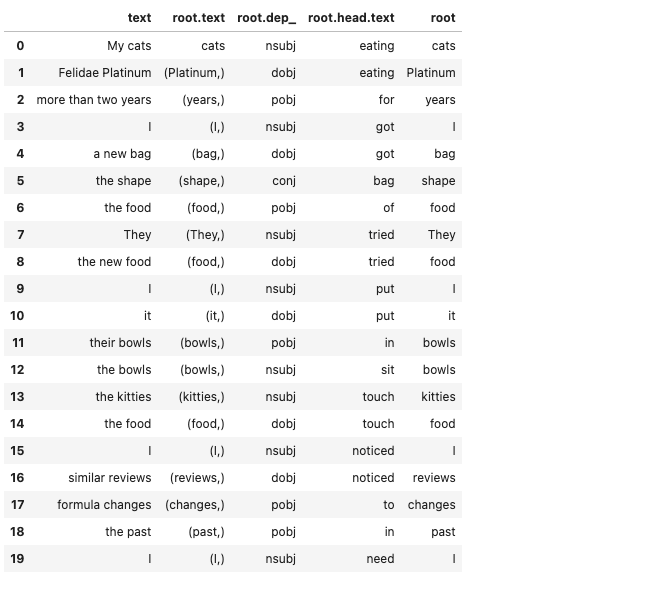
Day 6 : Part 2 : Coming soon
Follow for more updates, stay tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your time is limited, so don’t waste it living someone else’s life.”
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras





