
Day 3 : 30 days of Natural Language Processing Series with Projects
SpaCy — Part 1 as we go…
Welcome back peeps. Coming weekend is going to be busy with some travels planned so I thought of putting Day 3, 4, 5 posts after the office work today. In the last post we saw some of the most important topics in NLP like bag of Words, vectors, Stemming, Lemmatization, POS etc. In this post we are going to learn some more basics of NLP and then start with SpaCy.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Lets’ get going!
Named Entity Recognition
It’s a NLP technique which is used to extract information from unstructured text in order to classify the entities present in the text into categories to provide detail knowledge about the text and the relationship between the different entities.

This is an important step in natural language processing (NLP) because it allows for the extraction of structured information from unstructured text.
- There are two main approaches to NER: rule-based and statistical. Rule-based approaches use a set of manually defined rules to identify named entities, while statistical approaches use machine learning algorithms to learn to identify named entities based on patterns in the data.
- The most common algorithm used in statistical NER is the Conditional Random Field (CRF) algorithm. CRF algorithm takes into account the sequence of words and the context in which they appear, and uses this information to identify named entities. This approach is more accurate than rule-based methods and can handle the ambiguity and variability of natural language.
Additionally, there are pre-trained models like BERT, ELMO, and GPT-2, which can be fine-tuned on specific NER tasks, providing high accuracy. These models use a combination of contextual information and bi-LSTM layers to identify entities.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I live in New York and it's a beautiful city") for e in doc.ents:
print(e.text, e.start_char, e.end_char, e.label_)Chunking
It’s a NLP technique which is used to extract phrases from the unstructured data and case them into a better structure by using regular expression.
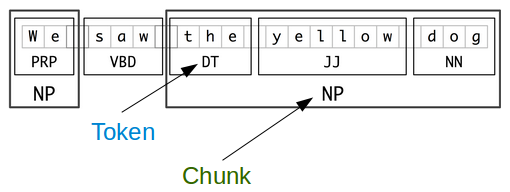
This is typically done by identifying certain words or patterns in the text, such as nouns, verbs, and adjectives, and using them as cues to group the surrounding words together.
The resulting chunks can then be used for a variety of tasks, such as text summarization, sentiment analysis, and information extraction.
There are different techniques and algorithms used for chunking, such as regular expressions, decision trees, and machine learning. One common method is called the “shallow parsing” or “light parsing” which uses a sequence of regular expressions or rule-based pattern matching to identify chunks of interest.
Code —
wt = word_tokenize(text)
wp = pos_tag(wt)
cparser = nltk.RegexpParser(grammar)
t = cparser.parse(wp)Word2Vec
In order to preserve the semantic information, in Word2vector each word is represented as a vector of 32 or more dimension instead of a number.
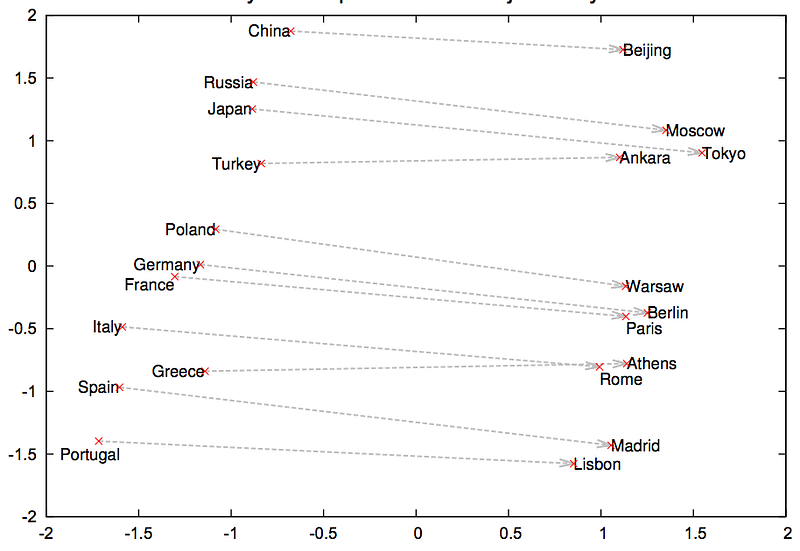
It does this by training a neural network on a large dataset of text, where the input to the network is a one-hot encoded representation of a word, and the output is a predicted probability distribution over all words in the vocabulary. The weights of the hidden layer of the network are used as the word embeddings.
The model uses two techniques, Continuous Bag of Words (CBOW) and Skip-gram, which predict the context words and target words respectively. This allows the model to learn the relationships between words, such as similarity and analogy, which can be useful for many NLP tasks like text classification, language translation, and others.
from gensim.models import Word2Vec
m = Word2Vec(sentences, min_count=1)
w = m.wv.vocab
v = m.wv['chess']
s = m.wv.most_similar['chess']SpaCy
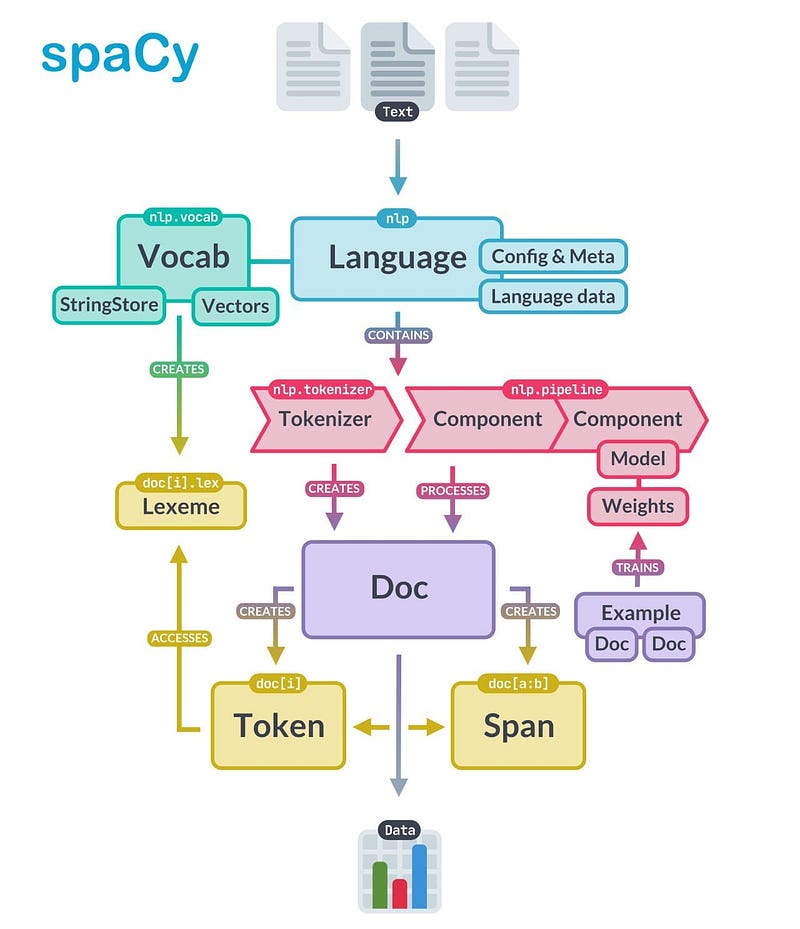
SpaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python which is designed specifically for production use and help you process and understand large volumes of text.
You can start by installing SpaCy —
$ pip install spacyAnd then import SpaCy in your jupyter notebook
import spacyOnce that’s done, you are ready to use SpaCy for your NLP projects.
Next download statistical models like part-of-speech tags, dependency labels, named entities etc
$ python -m spacy download en_core_web_smThen load the statistical models —
import spacy
nlp = spacy.load("en_core_web_sm")Linguistic features —
Named entities
doc = nlp("Elon Musk founded SpaceX")
[(ent.text, ent.label_) for ent in doc.ents] Output-[('Elon Musk', 'PERSON'), ('SpaceX', 'ORG')]Part-of-speech tags
d = nlp("This is a text.")
[token.tag_ for token in doc] Output-
['DT', 'VBZ', 'DT', 'NN', '.']Word vectors —
For word vectors install en_core_web_lg.
d = nlp("I love Newyork")
doc[1].vector
doc[1].vector_normSimilarity —
Similarity can be measured in various ways, such as by comparing the words, phrases, or concepts in the text, or by comparing the overall meaning or sentiment expressed in the text. Some common methods for measuring similarity in NLP include:
- Cosine similarity: A measure of similarity between two vectors, it calculates the cosine of the angle between them. It is commonly used to compare the similarity of two text documents by representing them as vectors of word counts.
- Jaccard similarity: A measure of similarity between two sets, it calculates the size of the intersection divided by the size of the union of the sets. It is commonly used to compare the similarity of two text documents by representing them as sets of unique words.
- Levenshtein distance: A measure of the difference between two strings, it calculates the minimum number of single-character edits (insertions, deletions or substitutions) required to change one string into the other. It is commonly used to compare the similarity of two words or short phrases.
- Word embeddings: A method to represent words in a continuous vector space, it captures the meaning of a word by its context. Word embeddings are commonly used to compare the similarity of words and phrases by measuring the similarity of their vector representations.
- Semantic similarity: A measure of similarity based on the meaning of the text, it compares the underlying semantics of the text, rather than its surface features. It is commonly used to compare the similarity of two text passages by comparing the concepts and entities they mention.
doc1 = nlp("I love Newyork")
doc2 = nlp("I like data science") doc1.similarity(doc2)Tokens —
The specific method used to create tokens can vary depending on the task and the text, but common tokenization methods include:
- Word tokenization: Breaking down the text into individual words. This is the most common tokenization method and is used for tasks such as part-of-speech tagging, named-entity recognition, and sentiment analysis.
- Sentence tokenization: Breaking down the text into individual sentences. This is used for tasks such as text summarization and machine translation.
- Subword tokenization: Breaking down words into smaller units, such as characters or subwords, which can be useful for handling out-of-vocabulary words, and handling inflections, dialects, and languages with rich morphology.
- Phrase tokenization: Breaking down the text into groups of words that together convey a single concept or meaning.
d = nlp("I love Newyork")
[token.text for token in d] Output--['I', 'love', 'Newyork']Pipelines —
The specific stages and their order can vary depending on the task, but a common pipeline includes:
- Tokenization: The process of breaking down the text into individual words, sentences, or other units of meaning.
- Part-of-Speech (POS) Tagging: The process of identifying the role of each word in a sentence (e.g. noun, verb, adjective)
- Lemmatization/Stemming: The process of reducing words to their base form (e.g. running -> run)
- Chunking: The process of grouping words into “chunks” or “noun phrases”
- Named-entity recognition (NER): The process of identifying and classifying named entities, such as persons, organizations, and locations
- Dependency parsing: The process of analyzing the grammatical structure of a sentence to determine the relationships between words.
- Semantic Role Labelling (SRL): The process of identifying the semantic roles of different words in a sentence.
- Coreference resolution: The process of identifying and linking mentions of the same entity across a text.
- Sentiment Analysis: The process of determining the sentiment or emotion expressed in the text.
- Summarization: The process of creating a condensed version of the text that still retains its key points.
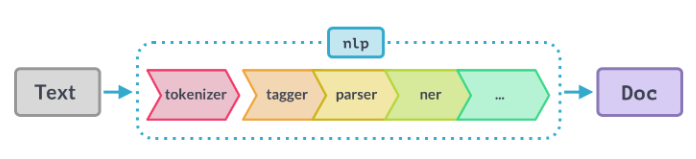
nlp = spacy.load("en_core_web_sm")
nlp.pipe_names
# ['tagger', 'parser', 'ner'] nlp.pipeline
# [('tagger', ), # ('parser', ), # ('ner', )]Day 4: Coming soon!
Follow for more updates, stay tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your time is limited, so don’t waste it living someone else’s life.”
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras




