
Day 2: 30 Days of Natural Language Processing Series with Projects
Most important topics in NLP…
Welcome back peeps. As we move forward in 30 days of NLP with Projects series, in this post we will focus on basic terminologies/techniques to build a good foundation.
Some of the other best Series —
100 days : Your Data Science and Machine Learning Degree Series with projects
Complete Data Visualization and Pre-processing Series with projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Tech Newsletter —
If you are interested, you can join my newsletter through which I send tech interview tips, techniques, patterns, hacks — Software Development, ML, Data Science, Startups and Technology projects to more than 30K readers. You can subscribe to Tech Brew :
Day 1 post which covers the pre-requisites before you dive in further —
So let’s get started!
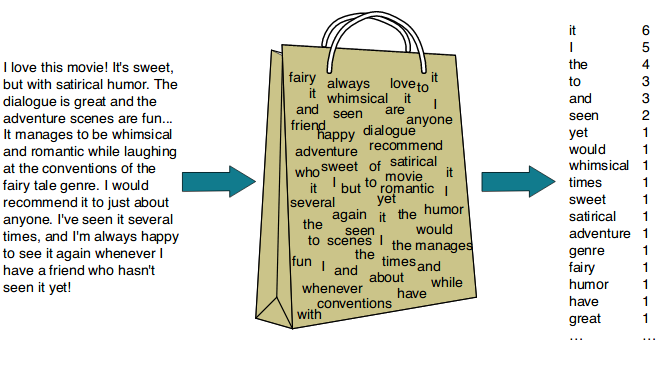
Bag of Words —
Bag of Words is the NLP technique which is used to preprocess the text by converting it into a bag of words, which keeps a count of the total occurrences of most frequently used words.
The process of creating a bag-of-words representation of text data typically involves the following steps:
- Tokenization: The text is split into individual words or tokens. This step is also known as text segmentation or word segmentation.
- Removing Stop words: Stop words are common words that do not add much meaning to the text such as “the”, “is”, “and” etc. These are typically removed from the text as they do not contribute much to the meaning of the text.
- Stemming or Lemmatization: The process of reducing inflected or derived words to their word stem, base or root form. It is done to reduce the dimensionality of the data and to group similar words together.
- Building the vocabulary: The set of all unique words in the text is built, also known as the vocabulary.
- Counting the words: The number of occurrences of each word in the vocabulary is counted.
- Building the BoW representation: A vector is created where each element represents a word in the vocabulary, and the value of the element represents the number of occurrences of that word in the text.
Once the bag-of-words representation of the text is created, it can be used as input for various NLP tasks such as text classification, sentiment analysis, topic modeling, and information retrieval. Since the order of the words is not considered, the BoW model is not suitable for tasks that require understanding the context or meaning of the text, such as language translation or text generation.
In summary, the bag-of-words model is a method of representing text data where the order of the words is not considered. It is commonly used in text classification and information retrieval tasks and it is done by Tokenization, Removing Stop words, Stemming or Lemmatization, Building the vocabulary, Counting the words, Building the BoW representation.
Bag of Words Vectors
Real world data is messy and unstructured and in order to use ML algorithms that prefer structured, well defined fixed-length inputs we use the bag of word technique using which we can convert variable-length texts into a fixed-length vector.
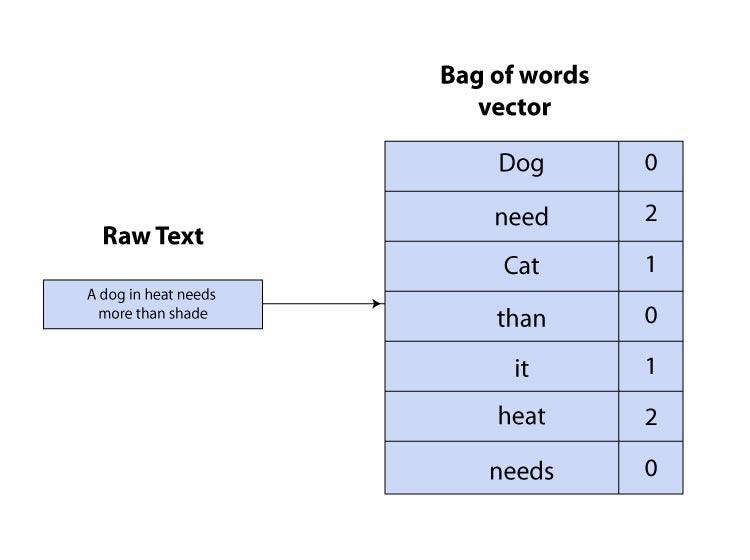
It works by creating a vocabulary of all the unique words in the text data, and then for each document or sentence, creating a vector where each dimension represents the count of each word in the vocabulary.
For example, let’s say we have a vocabulary of three words: [“dog”, “cat”, “mouse”]. If a sentence is “The dog chased the cat”, the BoW vector would be [1, 1, 0], representing one occurrence of “dog” and one occurrence of “cat” in the sentence, and no occurrences of “mouse”.
BoW is a simple and efficient representation of text data, but it does not take into account the order of words in a sentence or any context beyond the occurrence of individual words.
Term Frequency-Inverse Document Frequency (TF-IDF) —
Term frequency–inverse document frequency is used to identify the importance of a word in in a document in a collection or corpus. TF is the number of times a word appears in a document divided by the total number of words in the document. IDF is the log of the numbers of documents divided by the number of documents that contain the word w.
T.F = No of rep of words in sentence/No of words in sentence
IDF = No of sentences / No of sentences containing words

- The TF part of the method calculates the frequency of a word in a given document, with the idea that a word that appears more often in a document is more important to the meaning of the document. This frequency is typically normalized by the total number of words in the document.
- The IDF part of the method calculates the inverse of the document frequency of a word, with the idea that a word that appears in many documents is less important to the meaning of a specific document. This is typically calculated as the logarithm of the total number of documents in the corpus divided by the number of documents containing the word.
- The final TF-IDF score for a word in a document is the product of its TF and IDF scores. These scores can then be used to rank the importance of words in a document or to compare the similarity of documents.
It’s widely used in information retrieval and text mining because of its ability to give more weight to terms that are more specific to the given document and less weight to terms that are common across all documents, allowing for more relevant results.
Code —
from sklearn.feature_extraction.text import TfidfVectorizer
cv = TfidfVectorizer()
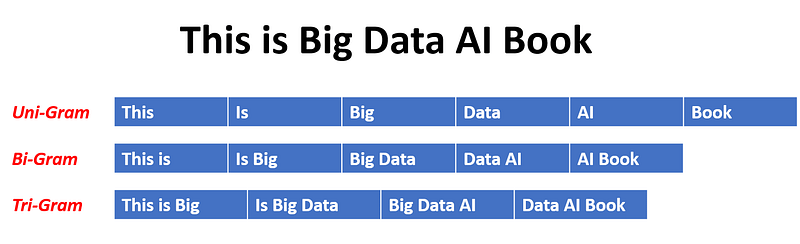
X = cv.fit_transform(counters).toarray()N-grams is a sequence of N tokens
1 gram is one word sequence
2 gram is a two word sequence of words
3 gram is three word sequence of words
Stop Words
These are most common words which do not add much value to the meaning of the document.
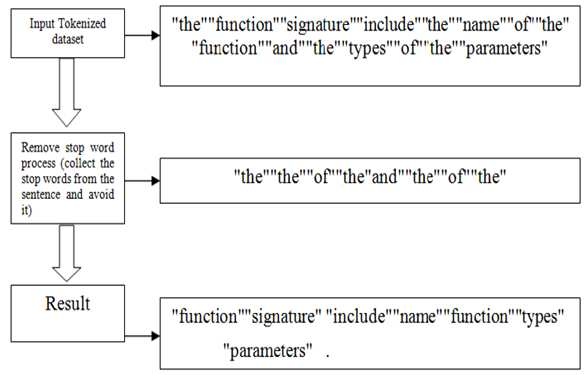
- The idea behind this is that these words are considered “unimportant” for these tasks and are unlikely to provide useful information. Examples of stop words include “the,” “an,” “and,” “is,” “are,” “was,” etc.
- The process of removing stop words from text data typically involves first creating a list of stop words, and then iterating through the text data, comparing each word to the list of stop words, and removing any that match. This is often done as a pre-processing step to improve the efficiency and accuracy of NLP tasks, as removing stop words can reduce the size of the text data and potentially remove “noise” that could negatively impact the performance of the task.
Code —
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize stopwords = set(stopwords.words('english')) Word embedding
It’s a dense representation of words in the form of numeric vectors.
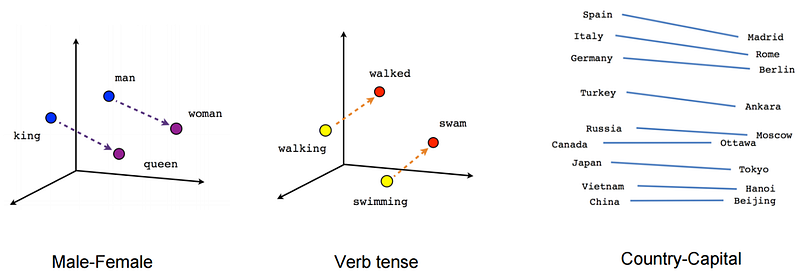
- The process of creating word embeddings typically involves training a neural network on a large corpus of text data. The neural network, such as a skip-gram or a continuous bag-of-words model, is trained to predict a word given the context of surrounding words. During training, the weights of the network’s layers are adjusted so that the embeddings for semantically similar words are close to each other in the space.
- Once the embeddings are learned, they can be used as input to other NLP models, such as language models or sentiment analysis models. By representing words as vectors, the embeddings can capture the meaning of the words and the relationships between them. This makes it possible to use the embeddings to improve the performance of other NLP models by providing them with a more rich and semantically meaningful representation of the text data.
Word embeddings can also be used for tasks such as word similarity comparison, word analogy, and clustering of similar words. These embeddings can be pre-trained on large corpora and fine-tuned for specific NLP tasks for better performance.
Tokenization
Tokenization is the text preprocessing technique used to break text into smaller components of text which are known as tokens.
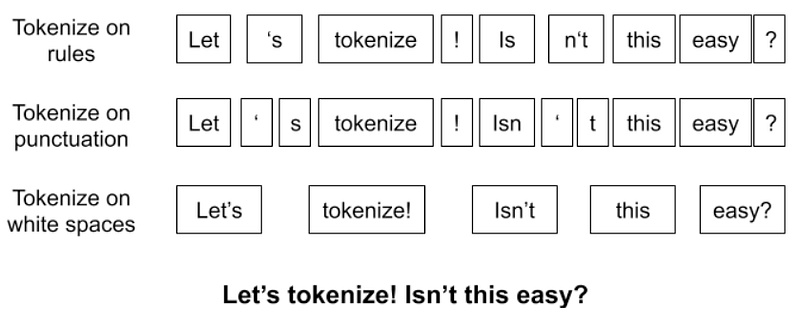
There are several ways to tokenize words in NLP, including:
- Using whitespace and punctuation as delimiters: This method splits the text into tokens based on spaces and punctuation marks.
- Using regular expressions: This method uses a regular expression to define a pattern for tokenizing text.
- Using pre-trained tokenizers: There are many pre-trained tokenizers available in different NLP libraries such as NLTK, spaCy and nltk word_tokenize,spacy tokenizer
- Using the Treebank tokenizer: This tokenizer is based on the Penn Treebank Project, which uses a set of rules to tokenize text in a way that is similar to how humans would tokenize it.
- Using BPE tokenizer : Byte pair encoding tokenizer used for sub-word tokenization.
Code —
from nltk.tokenize import word_tokenize
text = "Today is a beautiful day"
t = word_tokenize(text)
print(t)Output —
["Today", "is", "a", "beautiful", "day"]Stemming
It’s a technique to get to the root form of a word by removing the prefix and suffix of a word.
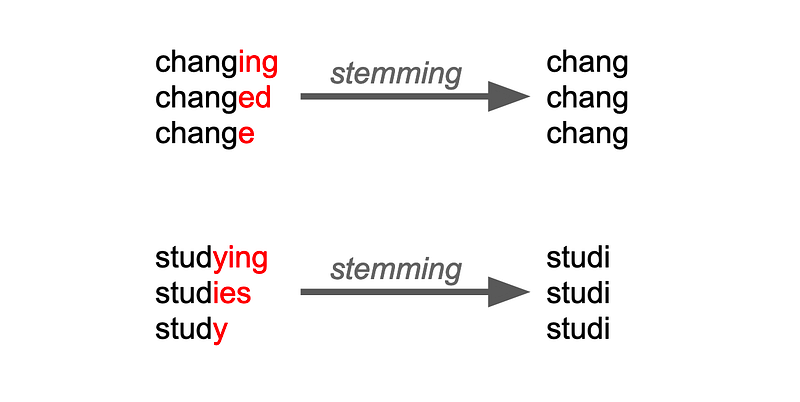
- There are different algorithms for stemming, the most common of which are the Porter stemmer and the Snowball stemmer. The Porter stemmer uses a set of heuristic rules to remove common suffixes from words, such as “ing,” “ed,” and “s.” The Snowball stemmer is based on the Porter stemmer but also supports other languages and has additional features.
- Stemming can be useful in NLP tasks such as text classification, information retrieval, and language modeling. By reducing words to their base form, stemming can help to reduce the dimensionality of the text data and make it more manageable. However, it is important to note that stemming can also lead to information loss and errors, as different words may have the same stem but different meanings.
- In addition to stemming, there is another technique called Lemmatization which aims to obtain the root word of the token but unlike stemming it uses a dictionary or a morphological analyzer to obtain the root word, this way it is more accurate and less aggressive than stemming.
Code —
from nltk.stem import PorterStemmer
tokenized = ["booking", "studying", "jumping"]
stemmer = PorterStemmer()
s = [stemmer.stem(token) for token in tokenized]Output —
['book','studi','jump]Lemmatization
Another text preprocessing technique using which we reduce the words down to their root forms.
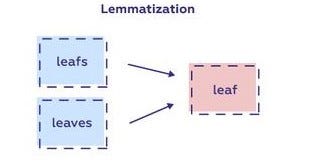
- The process of lemmatization, similar to stemming, reduces the inflected words to their word stem, base or root form, which is called the root word, but unlike stemming, it makes sure that the root word is a real word in the language, known as a lemma.
- The process of lemmatization typically uses a dictionary-based approach, where words are looked up in a dictionary and replaced with their corresponding lemma. The lemma of a word is the base form of the word, which can be found by removing inflectional endings and by bringing the word to its normal form. The lemma of the word “running” would be “run”.
- Lemmatization can be useful in NLP tasks such as text classification, information retrieval, and machine translation, where it is important to reduce the dimensionality of the data by mapping different forms of a word to a common base form. It can also improve the performance of text-based models such as language models, by reducing the number of unique words in the vocabulary and making the model more robust to inflected forms of words.
Lemmatization can be done by using pre-trained libraries such as NLTK, spaCy and WordNetLemmatizer.
from nltk.stem import WordNetLemmatizer
tokenized = ["booking", "studying", "jumping"]
lemmatizer = WordNetLemmatizer()
lemmatized = [lemmatizer.lemmatize(token) for token in tokenized]Output —
['book','study','jump]Stemming vs Lemmatization
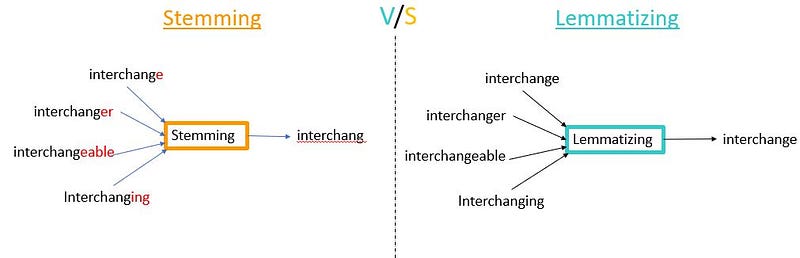
- Stemming and lemmatization are both techniques used to reduce words to their base or root form in natural language processing (NLP). However, they are slightly different in their approach and the results they produce.
- Stemming is a process of removing the suffixes or prefixes from a word to reduce it to its root form. It uses a set of rules or heuristics to chop off the ends of words to arrive at the root form. It is a simple, fast and crude method. For example, the stem of the word “running” would be “run”.
- Lemmatization, on the other hand, is a more sophisticated method. It uses a dictionary-based approach, where words are looked up in a dictionary and replaced with their corresponding lemma. The lemma of a word is the base form of the word, which can be found by removing inflectional endings and by bringing the word to its normal form. The lemma of the word “running” would be “run”.
In summary, the key difference between stemming and lemmatization is that stemming is a crude heuristic method while lemmatization uses a dictionary to map words to their base form, which is more accurate but also more computationally expensive. While stemming may produce non-real words, lemmatization will produce real words.
Part of Speech Tagging
It’s a technique of assigning a part of speech to every word in a string. It tells us the way in which a word is used in a sentence and relationship between the words.
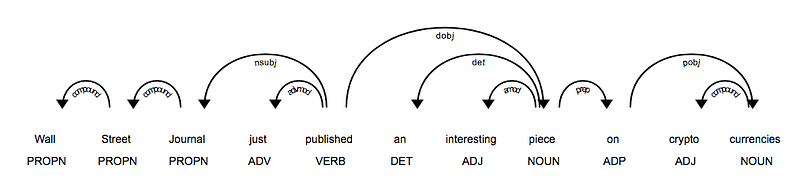
- This is an important step in natural language processing (NLP) because it helps disambiguate the meaning of words and can be used as a feature in many NLP tasks, such as syntactic parsing and named entity recognition.
- There are two main approaches to POS tagging: rule-based and statistical. Rule-based approaches use a set of manually defined rules to assign POS tags to words, while statistical approaches use machine learning algorithms to learn the most likely POS tag for a given word based on its context. The most common algorithm used in statistical POS tagging is the Hidden Markov Model (HMM).
- HMM algorithm takes into account the sequence of words and the probability of a word given its previous words, and uses this information to assign the most likely POS tag. This approach is more accurate than rule-based methods and can handle the ambiguity and variability of natural language.
Additionally, there are pre-trained models for POS tagging like BERT, ELMO, and GPT-2, which can be fine-tuned on specific tasks, providing high accuracy.
Day 3 : Coming soon!
Follow for more updates, stay tuned and of-course let me end this post with a quote by Steve Jobs ;)
“Your work is going to fill a large part of your life, and the only way to be truly satisfied is to do what you believe is great work. And the only way to do great work is to love what you do. If you haven’t found it yet, keep looking. Don’t settle. As with all matters of the heart, you’ll know when you find it.”
For other projects, tune to —
Build Machine Learning Pipelines( With Code)
Recurrent Neural Network with Keras
Clustering Geolocation Data in Python using DBSCAN and K-Means
Facial Expression Recognition using Keras
Hyperparameter Tuning with Keras Tuner
Custom Layers in Keras




