
Doctor.ai+GPT-3+Kendra = An Ensemble Chatbot for Healthcare
Three chatbots bring better results
By Sixing Huang and Hong Wang

Chatbot has become enormously popular now thanks to Alexa, Siri, GPT-3.5, and, above all, ChatGPT. It serves as a friendly intermediate between the user and the computer. The user can ask questions in natural language and then receive answers from the chatbot without writing a single line of code. As technology progresses, the responses are getting more accurate and human-like. For example, ChatGPT has coauthored a research article, where it performed at or near the passing threshold for the United States Medical Licensing Exam (USMLE) and provided concordant explanations for its choices.
Even though chatbots are getting increasingly intellectual, they are far from perfect. They can be biased and contain noises. Various articles and tweets have reported erroneous answers from ChatGPT, GPT-3, and Bard. Moreover, hardly any chatbot indicates confidence levels in its answers. As a result, it is hard for non-experts to distinguish between good and bad answers. And because of this uncertainty, its use in healthcare has been limited, where accurate information is a matter of life and death.
For this reason, several Neo4j engineers and one of us (Huang) have developed a knowledge graph-based chatbot called Doctor.ai (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, and 13). The knowledge graph is a combination of three authoritative medical databases: KEGG, Hetionet, and STRING. Doctor.ai uses GPT-3 to translate natural language questions into Cypher queries. It then uses these queries to retrieve answers from the knowledge graph. These databases are curated carefully by medical experts and the data are supported by academic research. But that can be a blessing and a curse. On the one hand, Doctor.ai’s answers should be more trustworthy than those from ChatGPT. On the other hand, Doctor.ai is constrained to find answers within the databases and cannot benefit from the rich information generated constantly on the internet.
Actually, there are other types of chatbots, such as AWS Kendra and DeepMind’s RETRO. Kendra, upon which the first version of Doctor.ai was built, serves as a semantic search engine. It digests raw texts and FAQ documents to build an index. But Kendra cannot formulate its own answers. When the user asks a question, it highlights the relevant paragraphs as its answers. As a result, Kendra’s answers are raw and inflexible compared to ChatGPT and Doctor.ai. But if you want a lightweight FAQ bot that is easy to set up, Kendra is a good choice. And you can guarantee the quality of its answers by controlling the quality of the data sources.
Wouldn’t it be great if we harness the power of all these chatbots and combine them into one app? We let them double or even triple-check each other’s answers. In this way, we can get more accurate answers. This method can be considered a form of parallel implementation. We can deploy it in healthcare, where accurate answers are of paramount importance.
In this article, we will demonstrate such an ensemble chatbot in Google Colab. It integrates Doctor.ai, Kendra, and GPT-3.5 with the text-davinci-003 engine. When a user asks a question, the three chatbots answer it in their own ways. Their answers are then weighed by another round of GPT-3.5. And the app gives a final combined answer to the user (Figure 1). We stick to Davinci because we found out that ChatGPT’s gpt-3.5-turbo API was inferior to text-davinci-003 for our purposes after some tests after its release. So all instances of ‘GPT-3.5’ in the main text refer specifically to GPT-3.5 text-davinci-003. You can access our Colab notebook here.
The FAQ document in Kendra is here.
https://datathon-medium-file.s3.amazonaws.com/medical_faq.csv
1. Architecture
The ensemble contains three chatbots. They are GPT-3.5, Kendra, and Doctor.ai. When a user submits a question, all three chatbots will try to answer it. Their answers are then collected and sent to GPT-3.5. GPT-3.5 combines the answers and presents one final answer to the user (Figure 1).
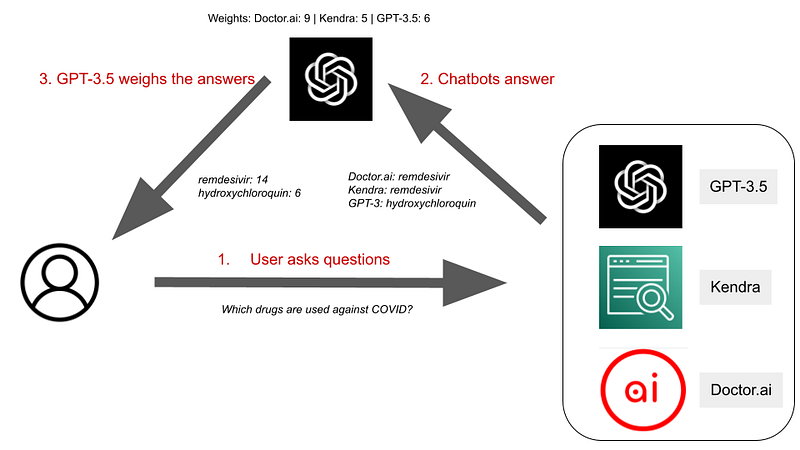
Now, let’s set up the chatbots one by one.
2. Kendra
Login to your AWS console, go to Amazon Kendra and create an index. Afterward, you need to add some data to Kendra. In this project, we have set up an S3 bucket as a data source and added an FAQ document. The S3 contains several medical PDFs (1, 2, 3, 4), while the FAQ is a CSV (see the link above) file without headers (Figure 2).
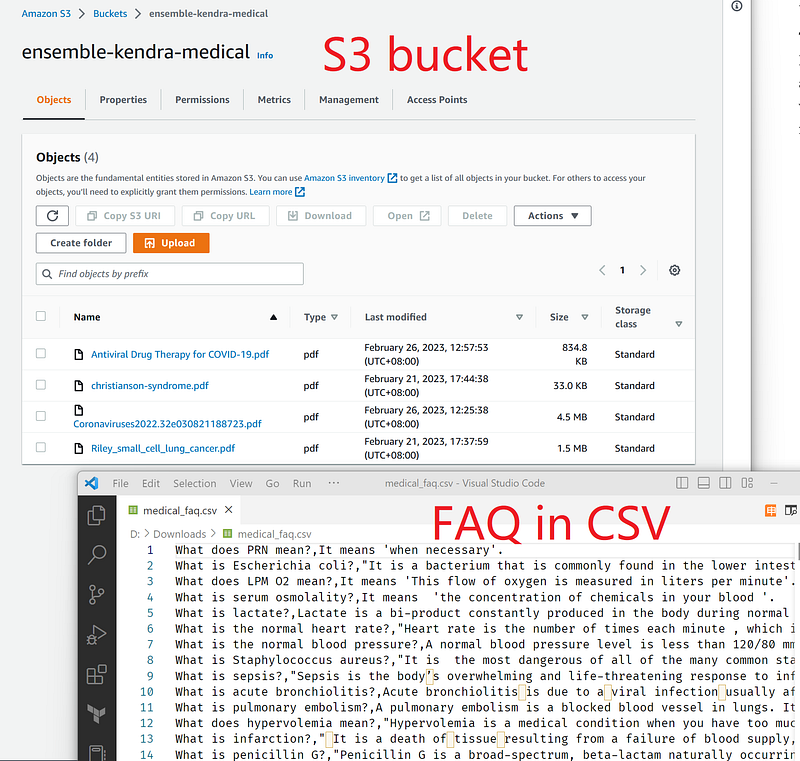
In Colab, we can query Kendra with the help of boto3. We have written a function called get_kendra for this purpose (Code 1).
#Code 1
kendra = boto3.client("kendra", region_name='us-east-1')
def get_kendra(query):
response = kendra.query(
QueryText = query,
IndexId = kendra_index_id)
answer = ""
for query_result in response["ResultItems"]:
if query_result["Type"]=="QUESTION_ANSWER":
answer_text = query_result["DocumentExcerpt"]["Text"]
return answer_text
elif query_result["Type"]=="ANSWER":
answer_text = query_result["DocumentExcerpt"]["Text"]
content = ""
for line in answer_text.split("\n"):
line = line.strip()
if line != "":
content += " " + line
answer = content
return answer
get_kendra("Which drugs are used to treat COVID?")
get_kendra
#output: Remdesivir, Paxlovid (nirmatrelvir and ritonavir)This function prefers answers from the FAQ document. When no FAQ item is found, it will then fetch excerpts from the raw PDF documents to the user.
3. Doctor.ai
For this project, we only need Doctor.ai’s Neo4j backend. You can set it up on AWS or AuraDB (instructions).
In Colab, we can query Doctor.ai like this (Code 2).
#Code 2
url = input("Your Doctor.ai backend url: ")
neo4j_username = input("Your Doctor.ai username: ")
neo4j_password = input("Your Doctor.ai password: ")
driver = GraphDatabase.driver(url, auth=(neo4j_username, neo4j_password))
training_text = """
#How many times did patient id_1 visit the ICU?
MATCH (p:Patient)-[:HAS_STAY]->(v:PatientUnitStay) WHERE p.patient_id =~ '(?i)id_1' RETURN COUNT(v)
#When did patient id_1 visit the ICU?
MATCH (p:Patient)-[:HAS_STAY]->(v:PatientUnitStay) WHERE p.patient_id =~ '(?i)id_1' RETURN v.hospitaldischargeyear
#What was the diagnosis of patient id_1's visit?; Why did patient id_1 visit the ICU?; What was the cause for patient id_1's visit?
MATCH (p:Patient)-[:HAS_STAY]->()-[:HAS_DIAG]->()-[:IS_DISEASE]->(d:Disease) WHERE p.patient_id =~ '(?i)id_1' RETURN d.name
[some codes are omitted here]
#"""
openai.api_key = GPT_APIKEY
def get_GPT_3 (query, temp):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=query,
temperature=temp,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0].text.lstrip()
def get_cypher(query):
prompt = training_text + query
cypher = get_GPT_3(prompt, 0)
return cypher
def get_doctorai(query):
cypher = get_cypher(query)
with driver.session() as session:
result = session.run(cypher)
return ", ".join(result.value())
answer_doctorai = get_doctorai("Which drugs are used to treat COVID-19?")
answer_doctorai
#Etesevimab, Nirmatrelvir and ritonavir, Sotrovimab, Elasomeran,
#Tozinameran, Molnupiravir, COVID-19 vaccine, Bamlanivimab,
#Remdesivir, Tixagevimab and cilgavimabAs described in this article, Doctor.ai uses GPT-3.5 to translate English questions into Cypher queries. It then retrieves the answers from the Neo4j backend. For example, when we asked “Which drugs are used to treat COVID-19?”, Doctor.ai returns a list of drugs, such as Etesevimab and Paxlovid (nirmatrelvir and ritonavir).
4. GPT-3.5 as a chatbot
The third chatbot is GPT-3.5 itself. We can simply reuse the get_GPT_3 function from Section 3 and get answers from GPT-3.5 (Code 3).
#Code 3
answer_gpt_3 = get_GPT_3("Which drugs are used to treat COVID?", 0.8)
answer_gpt_3
#The FDA has approved two drugs to treat COVID-19:
#remdesivir and dexamethasone. Remdesivir is an antiviral
#medication that works by blocking the virus from replicating
#in the body. Dexamethasone is a steroid that reduces
#inflammation and helps with breathing difficulties. Other
#drugs, such as hydroxychloroquine and convalescent plasma,
#are also being studied for their potential to be used to treat COVID-19.As of 2023–02–28, the output above showed that GPT-3.5 did not know Paxlovid, which was granted emergency use authorization by the United States Food and Drug Administration (FDA) for the treatment of COVID-19 in December 2021. One possible reason was that GPT-3.5 was trained on data up to June 2021 and thus has not heard about Paxlovid.
5. GPT-3.5 as a judge
Finally, we collect the answers and weigh them with a function called get_consensus (Code 4).
#Code 4
from typing import List
import ast
def get_consensus(statements: List[str], weights: List[int], my_query):
statements_str = "\n".join([f"{i} | {y}" for i, y in enumerate(statements)])
#print (statements_str)
ensemble_prompt = f"""
You have three answers to the same question.
If the answer contains multiple items, write the statement id and convert the items into a list like this
Statements:
0 | They used A, B.
1 | B was their tools.
2 | They chose C plus A.
Question:
What do they use?
Answers:
The answers are items
0 | ["A", "B"]
1 | ["B"]
2 | ["A", "C"]
If they are statements without a list of items, unify them into a coherent statement like this
Statements:
0 | This medicine XYZ is used to treat lung cancer.
1 | XYZ is developed by the company ABC.
2 | The drug XYZ is approved by the FDA.
Question:
Explain the drug XYZ.
Answers:
The answer is a statement
The company ABC has developed the drug XYZ to treat lung cancer. XYZ has reveiced the FDA approval.
Statements:
{statements_str}
Question:
{my_query}
Answers:
"""
result = get_GPT_3 (ensemble_prompt, 0)
#print (ensemble_prompt)
#print (result)
container = {}
is_list = True
for line in result.split("\n"):
line = line.strip()
if len(line) > 0:
if line == "The answers are items":
is_list = True
continue
elif line == "The answer is a statement":
is_list = False
continue
if is_list == True:
if "|" in line:
fields = line.split("|")
id = int(fields[0].strip())
items = ast.literal_eval(fields[1].strip())
for item in items:
if item not in container:
container[item] = 0
container[item] += weights[id]
else:
container[line] = sum(weights)
return container
bots = ["doctor.ai", "kendra", "GPT-3"]
statements = ["remdesivir, nirmatrelvir and ritonavir", "I used hydroxychloroquin to treat COVID", "remdesivir, nirmatrelvir and ritonavir have been successfully used against COVID-19"]
weights = [9, 6, 5]
print (get_consensus(statements, weights, "Which drugs are used to treat COVID?"))
#{
# 'remdesivir': 14, 'nirmatrelvir': 14, 'ritonavir': 14,
# 'hydroxychloroquin': 6
#}In this function, we have designed a prompt to aggregate the answers. We are dealing with two types of answers. The first type consists of lists. In this case, we would like to map-reduce them and get their total weights. For example, given three statements:
remdesivir, nirmatrelvir and ritonavir I used hydroxychloroquin to treat COVID remdesivir, nirmatrelvir and ritonavir have been successfully used against COVID-19
We would expect a result like this.
{'remdesivir': 14, 'nirmatrelvir': 14, 'ritonavir': 14, 'hydroxychloroquin': 6}The second type consists of pure statements. We would like to merge them into a coherent statement. For example, given three statements:
This medicine XYZ is used to treat lung cancer.
XYZ is developed by the company ABC.
The drug XYZ is approved by the FDA.A good consensus statement looks like this.
The company ABC has developed the drug XYZ to treat lung cancer. XYZ has reveiced the FDA approval.
After many experiments, we have come to the prompt in Code 4. It describes the two answer types and demonstrates the desired outputs. This prompt can deliver the expected outcomes for both answer types. If it is the list type, our code reduces the items. Otherwise, the get_consensus function returns a combined statement out of the three bot responses.
It is noteworthy that the weights can be set by the user. For example, Doctor.ai is the most trustworthy chatbot in our opinion, we gave it the highest weight of 9. Kendra has a weight of 6, while GPT-3.5 has 5. That is, Kendra and GPT-3.5 together can overrule Doctor.ai’s answers.
6. Test the ensemble
Let’s test the ensemble chatbot.
6.1 What is small cell lung cancer?
First, we tested the app with the question, “What is small cell lung cancer?” (Code 5).
#Code 5
my_query = "What is small cell lung cancer?"
answer_kendra = get_kendra(my_query)
answer_doctorai = get_doctorai(my_query)
answer_gpt_3 = get_GPT_3(my_query, 0.8)
bots = ["doctor.ai", "kendra", "GPT-3"]
statements = [answer_doctorai, answer_kendra, answer_gpt_3]
weights = [9, 6, 5]
for b, s in zip(bots, statements):
print (f"{b}: {s}")
print (get_consensus(bots, statements, weights, my_query))The three chatbots returned the following answers.
doctor.ai: Lung cancer is a leading cause of cancer death among men and women in industrialized countries. Small cell lung carcinoma (SCLC) is a highly aggressive neoplasm, which accounts for approximately 25% of all lung cancer cases. Molecular mechanisms altered in SCLC include induced expression of oncogene, MYC, and loss of tumorsuppressor genes, such as p53, PTEN, RB, and FHIT. The overexpression of MYC proteins in SCLC is largely a result of gene amplification. Such overexpression leads to more rapid proliferation and loss of terminal differentiation. Mutation or deletion of p53 or PTEN can lead to more rapid proliferation and reduced apoptosis. The retinoblastoma gene RB1 encodes a nuclear phosphoprotein that helps to regulate cell-cycle progression. The fragile histidine triad gene FHIT encodes the enzyme diadenosine triphosphate hydrolase, which is thought to have an indirect role in proapoptosis and cell-cycle control. kendra: Small cell lung cancer is a disease in which malignant (cancer) cells form in the tissues of the lung. GPT-3: Small cell lung cancer (SCLC) is an aggressive form of lung cancer that affects a small number of cells in the lung. It is one of two main types of lung cancer, the other being non-small cell lung cancer (NSCLC). It is much less common than NSCLC and tends to spread quickly, often to other parts of the body. Symptoms of SCLC can include coughing, chest pain, shortness of breath, and weight loss. Treatment typically involves a combination of chemotherapy, radiation therapy, and surgery.
And then GPT-3.5 summarized the results and output the following message.
Small cell lung cancer (SCLC) is an aggressive form of lung cancer that affects a small number of cells in the lung. It is characterized by the overexpression of oncogene MYC, loss of tumor suppressor genes such as p53, PTEN, RB, and FHIT, and can lead to more rapid proliferation and reduced apoptosis. Symptoms of SCLC can include coughing, chest pain, shortness of breath, and weight loss. Treatment typically involves a combination of chemotherapy, radiation therapy, and surgery.
As you can see, the app was able to fetch the answers from all three chatbots. The get_consensus function weaves the three statements together coherently. It first copies and pastes the definition of SCLC from the GPT-3.5 chatbot. It then goes to the genetics that it learns from Doctor.ai. Finally, it borrows the texts about the symptoms and treatments from GPT-3.5 again. The contribution of Kendra is not obvious in this case.
6.2 Which drugs are used to treat COVID-19
The next question is “which drugs are used to treat COVID-19”. The three chatbots gave the following answers
doctor.ai: etesevimab, nirmatrelvir and ritonavir, sotrovimab, elasomeran, tozinameran, molnupiravir, covid-19 vaccine, bamlanivimab, remdesivir, tixagevimab and cilgavimab kendra: remdesivir, nirmatrelvir and ritonavir GPT-3: the main drugs used to treat covid-19 are antiviral medications, such as remdesivir and monoclonal antibodies. other drugs being studied to treat severe covid-19 cases include corticosteroids, antiviral drugs, interferon, and anticoagulants.
The consensus looks like this.
{
'etesevimab': 9, 'nirmatrelvir and ritonavir': 15, 'sotrovimab': 9,
'elasomeran': 9, 'tozinameran': 9, 'molnupiravir': 9, 'covid-19 vaccine': 9,
'bamlanivimab': 9, 'remdesivir': 20, 'tixagevimab': 9, 'cilgavimab': 9,
'monoclonal antibodies': 5, 'corticosteroids': 5, 'antiviral drugs': 5,
'interferon': 5, 'anticoagulants': 5
}As you can see, the app has correctly map-reduced the drugs and their weights. It not only combines the lists together but also shows that Remdesivir and Paxlovid (Nirmatrelvir and Ritonavir) have the most weight.
Conclusion
In this article, we have shown you how to build an ensemble healthcare chatbot. It combines the answers from Doctor.ai, Kendra, and GPT-3.5. This parallel implementation ensures that if one chatbot fails, the other two can still fill the gap. The “wisdom of the crowd” also suggests that the consensus can be more accurate than the individual answers. And reliable and accurate answers are particularly important in healthcare. So we hope that our article here can be a starting point for your own project.
GPT-3.5 plays multiple roles in this app. It translates natural language questions into Cypher. It is a FAQ chatbot. And finally, it makes a consensus out of the three chatbots. On the one hand, it delivered precise Cypher queries in the first task and reasonable answers in the Q&A. On the other hand, its performance in consensus building was sometimes unpredictable. In other words, it failed sometimes. So we encourage you to play around with the temperature and the prompt.
Finally, this project is a framework. You can switch the components or add other chatbots, such as DeepMind’s RETRO, Alan, Rasa, or FAQ Bot. Although more chatbots can bring more benefits, you do need to make sure that their sources are trustworthy.