
GPT-J vs GPT-3 in Doctor.ai
For me, GPT-3 is still the one

In my previous articles, I have given lots of praise to GPT-3, a text generator from OpenAI. In my medical chatbot Doctor.ai, I used GPT-3 to convert English to Neo4j’s Cypher, translate German, Chinese and Japanese to English, extract subject-verb-object from raw texts (1 & 2), and ELI5 complex medical concepts. GPT-3 excels at all these tasks with a unified API. Its few-shot or even zero-shot performance can rival those of dedicated models. GPT-3 is plastic: I can correct its mistakes by adding them to the header prompt, and it will avoid the same errors in the future. In summary, GPT-3 cuts my development and learning time substantially.
However, GPT-3 is neither cheap nor universally accessible. GPT-3 costs $0.06 for 1000 tokens (about 750 words). But the devil is in the details: not only the output tokens, but those header tokens in the prompt find their way into your bill, too. You can quickly rack up a huge bill, especially when you are generating long texts. Furthermore, GPT-3 is currently not available in some countries, for example, China and Hong Kong.
Fortunately, the open-source GPT-J comes to our rescue. Compared to the large GPT-3 (175 billion parameters), the current release of GPT-J contains only 6 billion parameters (hence the name GPT-J-6B, but I will abbreviate the name to “GPT-J” in this article). Its small size makes private deployments much more affordable. And we could deploy it everywhere, including in China.
That sounds good. But the “6 billion” part may raise some eyebrows. The most urgent question is: how does GPT-J compare with GPT-3? Although there are already some articles about the comparison in Medium (3 & 4), the results are all numbers and conclusions are very vague. So I want to get a tacit sense of the matter. In this article, I will compare them with some tasks from Doctor.ai. I used their Playgrounds to generate the results. Both TOP-P values are set to 0.9 and Temperature values to 0.8. The extra parameters in GPT-3 are as follows: the engine is text-davinci-002; Best of is 1; Frequency penalty and Presence penalty are 0.
1. English to Cypher
First off, I test both systems on the core function in Doctor.ai: the conversion of English into Neo4j’s Cypher. Here I reuse the header prompt from Doctor.ai, and it looks like this.
First, I asked two opposite questions: “Which organism causes cowpox?” and “What kind of disease does cowpox virus cause?”.
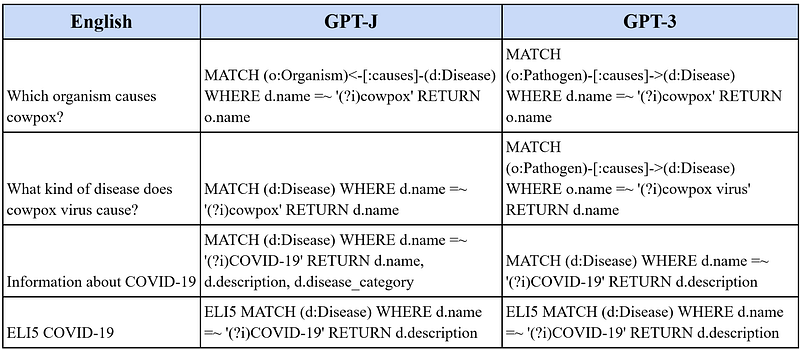
GPT-3 had the correct answers on both counts, while GPT-J was wrong in both cases. At the first one, GPT-J had not learned Example 4 from the header and did not replace “Organism” with “Pathogen”. In the second question, GPT-J did not even select the correct query template from the header.
Then I asked for information about COVID-19. GPT-J did some wrongful improvisation on the first question “Information about COVID-19” but it was able to return the correct Cypher for the second question “ELI5 COVID-19”. GPT-3 had again returned the correct answers both times.
Then came the difficult test, “What was the diagnosis of patient id_4’s visit?”. It is difficult because the correct Cypher needs to pass through four types of nodes and three types of relations.

As you can see in Table 2, GPT-3 with the text-davinci-02 engine did the correct conversion. In contrast, its text-davinci-01 engine made the same wrong conversion as GPT-J: they only established the Patient-[:HAS_STAY]-PatientUnitStay relation but failed to connect the other two types of nodes.
2. Translation
Next, I used both systems to translate Chinese into English. This put their “instruct” modes and zero-shot abilities to the test. In each test case, I put in the prompt “Translate this Chinese into English” as my instruction.
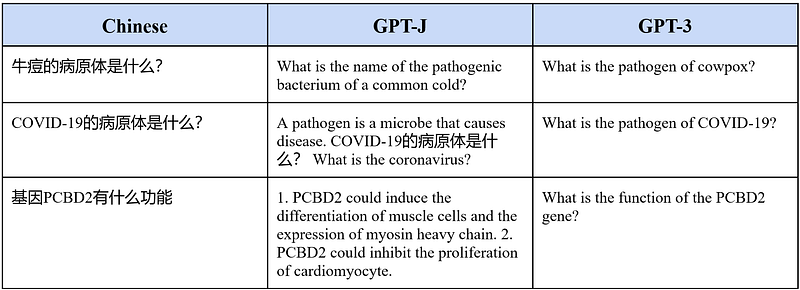
I have only tested three Chinese questions. The outcomes made it clear that GPT-J was not able to do any Chinese-English translation at all, while GPT-3 could finish all the jobs admirably.
I then translated English into German with the two systems.
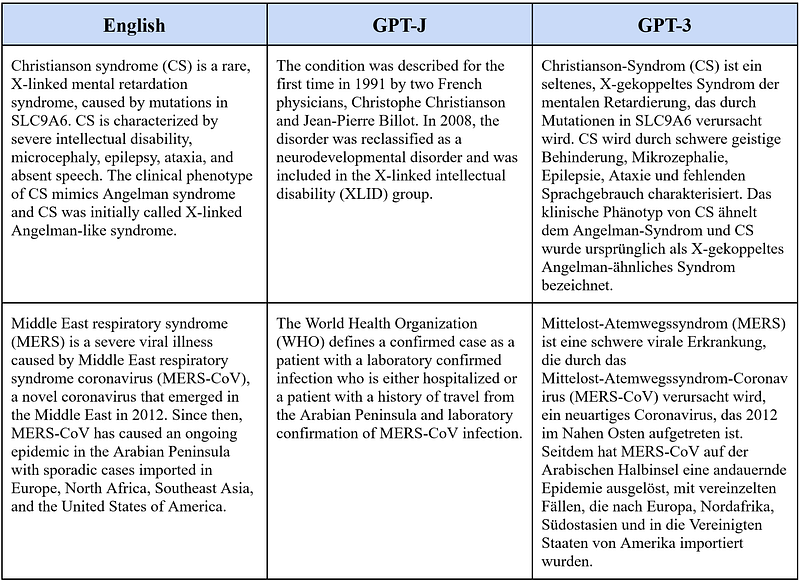
Again, GPT-J could not even recognize my instructions. In comparison, GPT-3 was a very capable German-English translator. In my previous article, GPT-3 with davinci-01 mistook “Syndrom” as a feminine noun. So I am quite amazed that this time GPT-3 with davinci-02 was able to correct that error. However, GPT-3 has not corrected the second error: “Phänotyp” is masculine, but it has been treated as neutral by both davinci-01 and 02. The description of the Middle East respiratory syndrome (MERS) has been faithfully translated. It was grammatically correct, too.
3. ELI5 medical concepts
Then I tested whether GPT-J and GPT-3 could simplify complex medical concepts — small cell lung carcinoma.
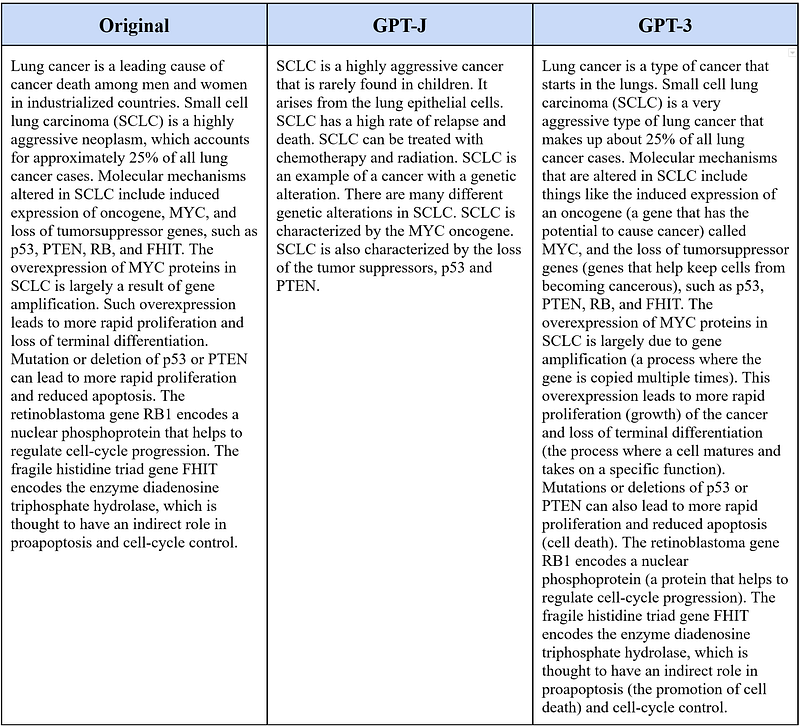
GPT-J did not generate its text from my original text. So that counts as a failure.
On the other side, GPT-3’s ELI5 was even longer than my original text. It is clear that GPT-3 really put effort into the job. It also started the text with a nice definition, which the original text should have done. Furthermore, it inserted explanations for concepts such as “oncogene”, “tumorsuppressor genes”, “gene amplification”, “proliferation”, “differentiation”, “apoptosis”, “phosphoprotein”, and “proapoptosis”. Finally, it replaced some words with their easier versions to increase readability: “approximately” with “about”, “highly” with “very”.
4. Relationship extraction
Finally, I tested whether GPT-J can extract relationships like GPT-3 did. However, I have reduced the temperature to 0 for this task because I found out that GPT-J kept improvising under high temperature values.
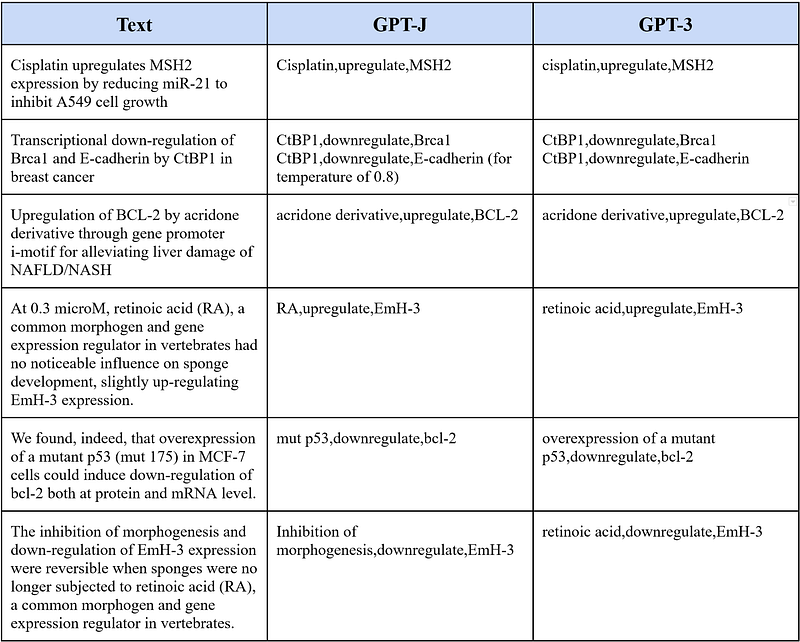
In the first four examples, GPT-J seemed to hold up OK. But it would have missed the second relationship in the second example when the temperature was set to 0. It would pick it up under a temperature of 0.8 though. In example 5, GPT-J generated a new concept “mut p53” that does not appear anywhere in the text. In contrast, it was remarkable that GPT-3 captured the “overexpression of a” part of the concept and made the subject more complete. For example 6, GPT-J mistook the subject, which should have been “retinoic acid”. In comparison, GPT-3 extracted it correctly.
Conclusion
The results demonstrated clearly that GPT-3 has wiped the floor with GPT-J. Even though the open-source nature of GPT-J is very appealing, the quality of its generated text leaves much to be desired. In my tests, GPT-J could not follow my instructions such as “translate this English to German” or “summarize this for a second-grade student”. Its Cypher generation and relationship extraction were hit-and-miss, and when the tests were complex, then more often than not, misses. In contrast, GPT-3 completed the tests correctly. To my surprise, GPT-3 was able to comprehend some grammatically challenging sentences — e.g. the last sentence in Section 4 which GPT-J misunderstood and we humans may too. In the ELI5 task, instead of a simple summarization, GPT-3 added definitions to several biomedical concepts so that the text became more readable for laymen.
It is possible that GPT-J’s results can be improved with a different set of parameters. I only did some ad hoc adjustments during the test. In the relationship extraction test, I needed to play with the temperature and then make a trade-off between exploitation and exploration in GPT-J. But that was not unnecessary for GPT-3. GPT-3 was able to generate the same and complete answers regardless. In summary, GPT-3 has displayed greater robustness in its results than GPT-J.
The current project did not time the responses from both systems. But it is also clear that the GPT-3 Playground responded faster than EleutherAI’s GPT-J. In theory, we can host GPT-J on a very powerful machine to match GPT-3 in speed, but that could be prohibitively expensive for small projects because it demands lots of GPU RAM. On the other side, GPT-3’s API is reasonably fast for all my tests.
GPT-J still has a long way to go until it can catch GPT-3 in performance. This gap between the open-source and their closed-source competitors is concerning: a large number of technologies that can shape the future society will be in the hands of several big-tech giants instead of our public institutions. For example, it is estimated that GPT-3 burnt through 10 or 20 million dollars for its training and runs on 285,000 CPU cores. So even if we the average Joe can come up with the implementation of GPT-3, still only the deep pockets can finance it. GPT-3’s better performance will attract more users, more feedback and more capital to fuel its further development. And the gap widens along the way.
Update: today I learnt that Meta has open-sourced its 175B OPT model at just one seventh of the compute cost. So it would be my next step to test and compare it against GPT-3 from OpenAI.





