
Meta AI Open-Sources a 175B Parameter Language Model: GPT-3 Comparable Performance at One-Seventh the Compute Cost

Today’s state-of-the-art large language models (LLMs) can have more than 100 billion parameters — a number that is regularly rising — and have achieved astounding performance on complex natural language processing (NLP) tasks such as writing articles, solving math problems, question answering and more. The proprietary nature of these generative behemoths however means access is restricted to only a very few monied research labs. Another LLM limitation is their massive compute costs, which makes them difficult to replicate for most AI researchers.
In the new technical report OPT: Open Pre-trained Transformer Language Models, Meta AI releases Open Pretrained Transformer (OPT), an open-source suite of decoder-only pretrained transformers ranging from 125M to 175B parameters that achieves performance comparable to OpenAI’s state-of-the-art GPT series. The OPT175B release could be a game-changer for the machine learning community, as it will give countless academic and other researchers their first-ever access to a powerful LLM and “increase the diversity of voices defining the ethical considerations of such technologies.”
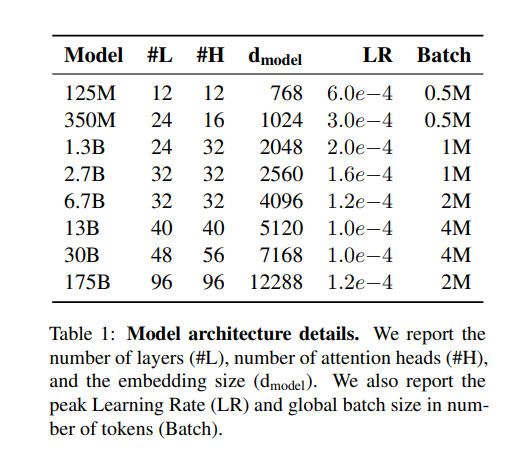
The Meta AI team set out to capture the scale and performance of the GPT-3 class of models while also applying optimal strategies for data curation and training efficiency. The resulting OPT autoregressive language models range from 125M to 175B parameters and have been publicly released with the exception of the OPT-175B, which requires registration. Meta AI is also releasing a model creation logbook and the associated metaseq codebase.
The OPT training setup uses the Megatron-LM codebase setting for weight initialization, AdamW as an optimizer, and a dropout of 0.1 throughout. The pretraining corpus is drawn from a concatenation of publicly available datasets used in LLMs such as RoBERTa (Liu et al., 2019b), the Pile (Gao et al., 2021a), and PushShift.io Reddit (Baumgartner et al., 2020; Roller et al., 2021). The team leveraged a GPT-2 byte-level BPE tokenizer to tokenize all corpora, resulting in a final corpus containing roughly 180B tokens.
OPT-175B benefits from the latest-generation NVIDIA hardware and was trained on 992 80GB A100 GPUs utilizing Fully Sharded Data Parallel (Artetxe et al., 2021) with Megatron-LM Tensor Parallelism (Smith et al., 2022) to achieve utilization of up to 147 TFLOP/s per GPU.
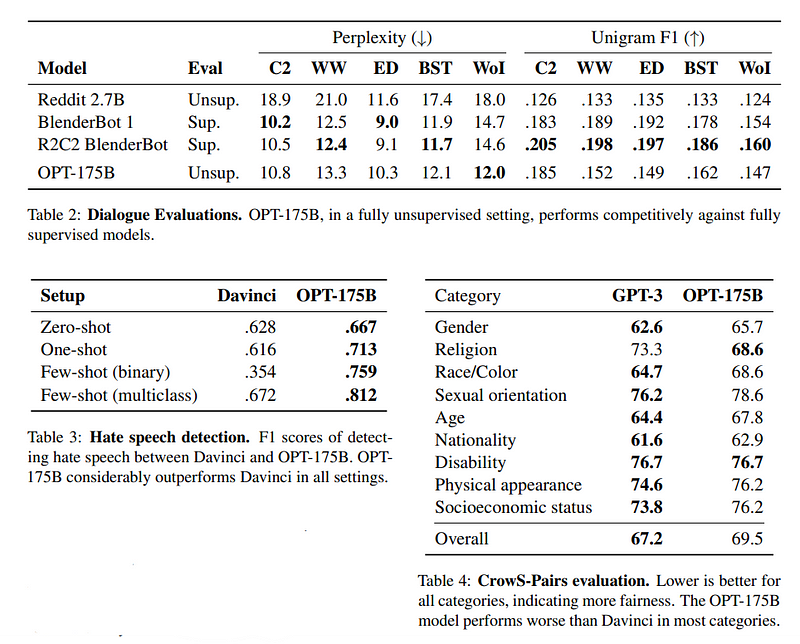
In their empirical study, the researchers evaluated their models on 16 standard NLP tasks that included OpenBookQA (Mihaylov et al., 2018), WinoGrad (Levesque et al., 2011), WinoGrande (Sakaguchi et al., 2020), and SuperGLUE. The results show that OPT-175B performance is competitive with GPT-3, but with only 1/7th the carbon footprint.
The Meta AI team believes direct access to OPT-175B will greatly benefit the AI community and encourage researchers to work together to develop better and more socially responsible LLMs.
The code and small pretrained models are available on the project’s GitHub. The paper OPT: Open Pre-trained Transformer Language Models is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.





