
Relationship Extraction with GPT-3
Accelerate knowledge graph construction with GPT-3

In my previous articles (1, 2, and 3), I have demonstrated that GPT-3 from OpenAI is a game-changing Natural Language Understanding (NLU) engine. GPT-3 is easy to learn and easy to repurpose. It is highly accurate in both content and format. In the case of Doctor.ai, compared to AWS Lex, GPT-3 delivers better results with far less learning and development time.
But GPT-3 is more than a chatbot. It can do keyword and relationship extractions, too. This is especially important for knowledge graph construction. I have shown in my previous article how to integrate public knowledge graphs into Doctor.ai, but it takes time for these public sources to incorporate the newest research results. So in order to keep Doctor.ai always up-to-date, we need a fast and automatic way to extract relationships — gene regulations, drug interactions and protein interactions — from research articles ourselves. You can imagine my excitement when I found out that GPT-3 also excelled at this task.
And more importantly, GPT-3 does not just mechanically extract the relationships. It has a good semantic understanding. It does the necessary noun-verb conversion and entity expansion, too. For example, “upregulation of A by B” can be correctly transformed into B,upregulate,A. Or “A and B are not hydrolyzed” can be correctly turned into {"A hydrolysis": "negative", "B hydrolysis": "negative"}. And according to my tests, GPT-3’s outputs are more precise than those of spaCy.
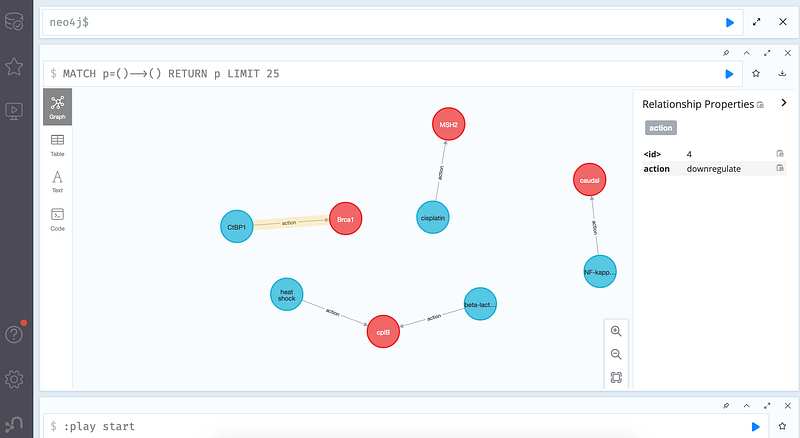
The good news is that we don’t need to change our modus operandi at all for all this. In my previous projects, GPT-3 read the English questions and turned them into Cypher queries. In this task, GPT-3 will read excerpts of research articles, extract the subject-verb-object and format them as CSV or JSON. And we can then import them into Neo4j (Figure 1).
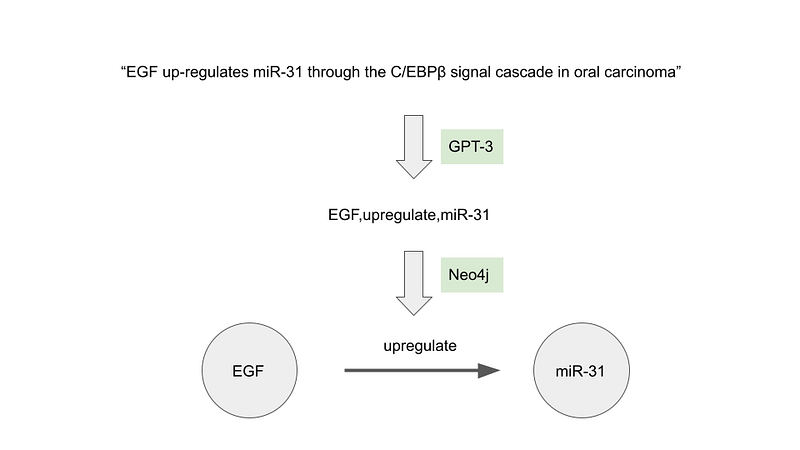
In this article, I am going to show you how to do this. I will extract two kinds of relationships: gene regulation and metabolic capacities. The code for this project is hosted on my GitHub repository. At the time of writing, I used the text-davinci-002 engine, but later I have found that the text-curie-001 engine generates fewer noises and thus delivers better results at just one tenth of the cost!
1. Construct the GPT-3 prompts
1.1 Gene regulations
By default, a few-shot API query in GPT-3 consists of an example portion and a user prompt. Through the examples, GPT-3 gets an idea of what we want (content) and how we want it (format). The user prompt is a primer from which we want GPT-3 to generate content. GPT-3 will try to generate the content in the right format. For example, I want GPT-3 to extract the gene regulation relationships from the titles of some research articles. I have constructed the following prompt.
The sharp “#” symbols mark the article titles I have collected. I also gave GPT-3 the answers in CSV format in the next lines. GPT-3 can learn from this small set of examples, figure out the inner logics and then take on the new challenges. Let’s test it with some new texts in the GPT-3 Playground one by one.
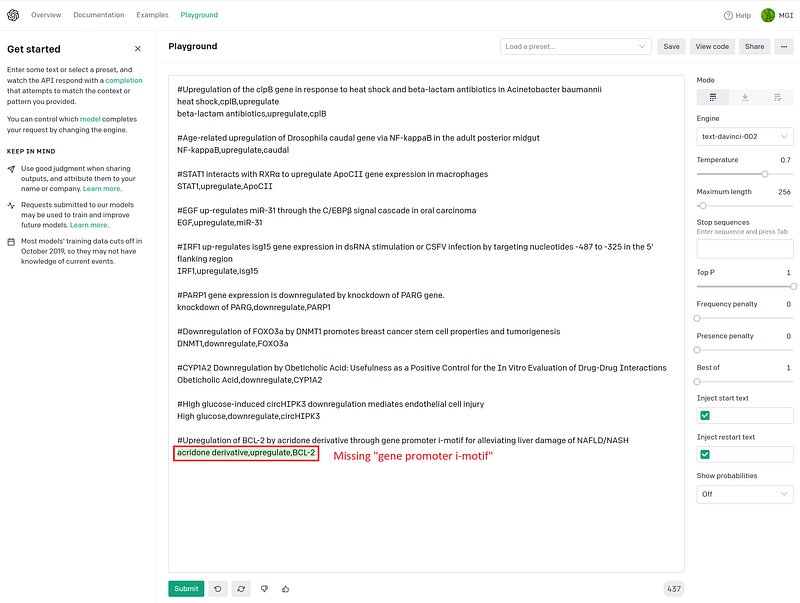
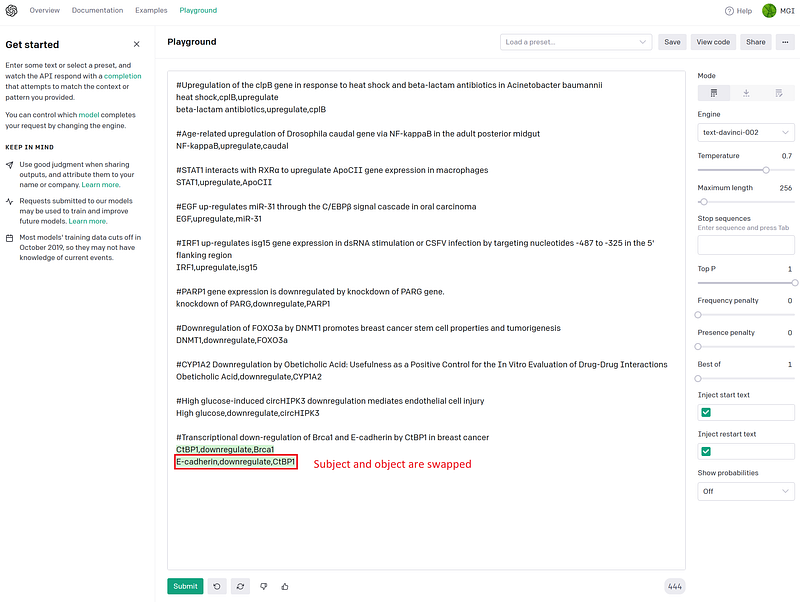
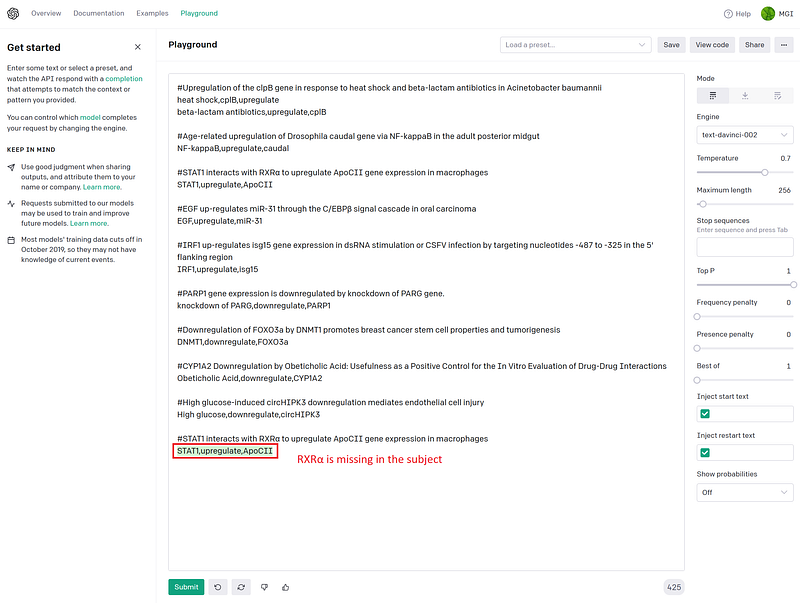
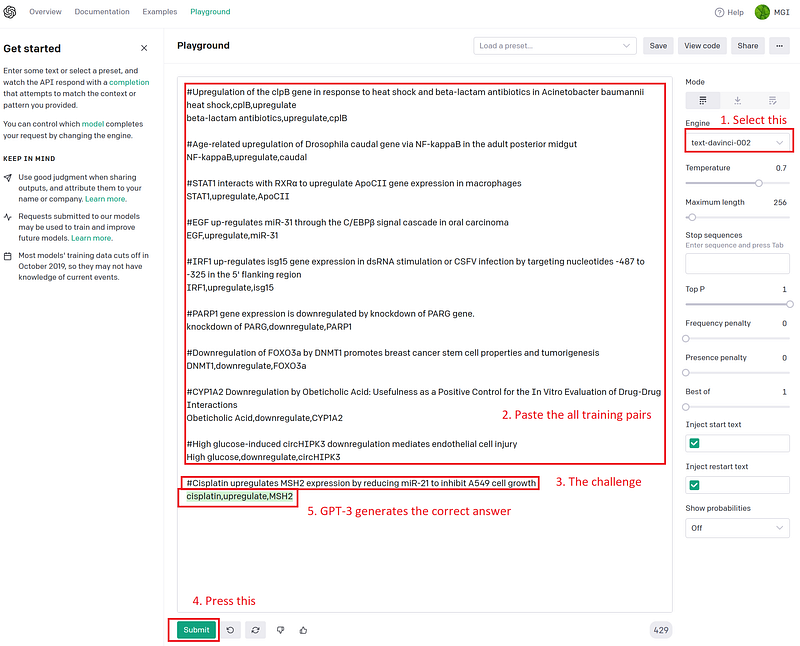
As you can see the test results in Figure 2, GPT-3 did not always get it right. It stumbled upon complicated grammar. Some texts above are hard to parse even for us humans. Sometimes GPT-3 misses a part of the text, at other times it swapped the subject and object. Nevertheless, these errors are easy to spot and to correct. It is worth mentioning that even though the words in my first example answer (“heat shock,cplB,upregulate”) were in the wrong order, GPT-3 was able to ignore the small mistake and got the answers in the correct order.
1.2 Bacterial metabolic capacities
In microbiology, researchers publish strain descriptions. They are published in journals such as the International Journal of Systematic and Evolutionary Microbiology. These articles describe the morphologies, phylogenies and metabolic capacities of some bacterial strains. Bioinformatic scientists can combine these observable traits with genomic data to study phenotype-genotype relations. Compared to genomic data, the phenotypic data have long been neglected. They have been rarely digitalized or structuralized. Even though we have databases such as BacDive and JGI, many of the phenotypic data are still buried in texts.
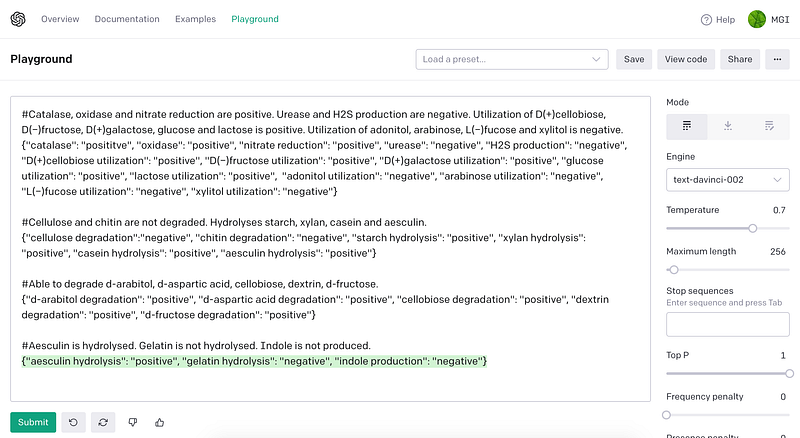
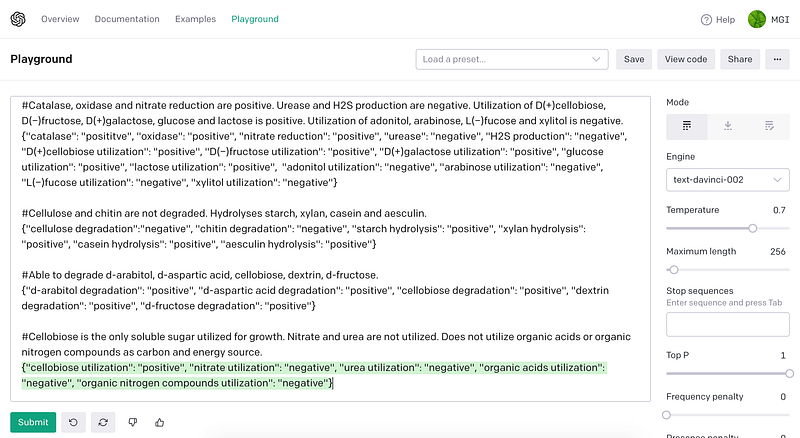
Similar to Section 1.1, we can use GPT-3 to parse bacterial strain descriptions. In this project, we are only interested in metabolic capacities. In addition, we want the results in JSON format.
Here are the challenge texts.
And you can see in Figure 3, the results were very accurate.
2. A Python wrapper
Even though the GPT-3 Playground is a great place for experimentation, we still need to interact with GPT-3 programmatically. In the Playground, you can click on the View code button to inspect the API code snippets in JavaScript and Python. I have written a small Python wrapper for the extraction of metabolic capacities in Section 1.2.
This code reads two plain text files. The first one contains the example prompts while the other contains the challenge texts. It submits the challenges one by one, gets the answers from GPT-3 and formats them into JSON. To run this command, first export the environment variable OPENAI_API_KEY with your own OpenAI key. And then run the command like this. It will print the results in the standard output.
3. Import into Neo4j
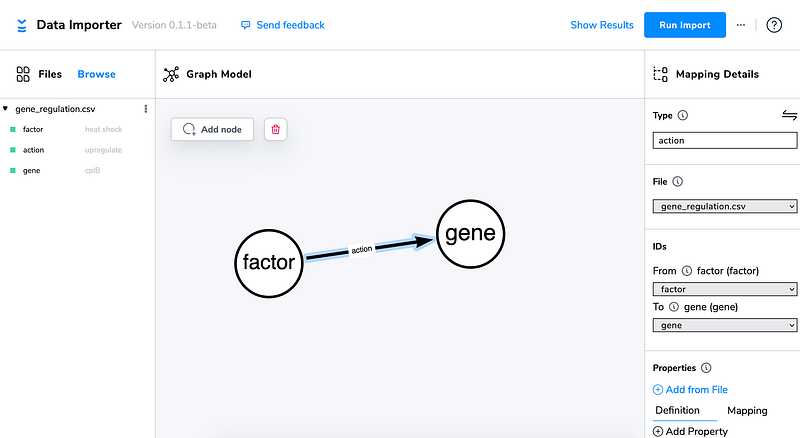
Once we curate the results from GPT-3, we can quite easily import the extracted relations into a Neo4j knowledge graph. Here I used the free AuraDB (Figure 5). I also used the new Data Importer (Figure 4) to import the GPT-3 results in CSV format into the database.
Conclusion
We can expand the knowledge graph in Doctor.ai manually. But that route takes time and requires domain knowledge. The ability to programmatically extract relations out of natural language texts changes the game. Although GPT-3 still makes errors sometimes as shown in the article, we can correct those errors easily. It is amazing that we can add the correct answers back into the training portion for GPT-3 to learn so that it will avoid the same mistakes in the future.
And we are not limited to gene regulations and metabolic capacities. We can extract allergic information out of patients’ medical records, drug-drug interactions from research articles and many other relations. You can also change the parameters of the GPT-3 calls and see the changes. And GPT-3’s “learning from examples” makes it quite easy for us to adapt our code to other applications.
But this does not mean that we can use this ability everywhere. It is utmost important for us to honor the terms of service of the source texts. Some journals can forbid all kinds of programmatic text extraction. So please make sure that you have the permission before you act. Secondly, GPT-3’s prompt can only accept up to about 1,500 words and the service is not cheap. Therefore it makes sense to preprocess your full length texts. And I have just created such an NLP pipeline in my article Use Crosslingual Coreference, spaCy, Hugging face and GPT-3 to Extract Relationships from Long Texts.
Update: the next article uses GPT-3 to explain complicated medical concepts in Doctor.ai.




