
Use Crosslingual Coreference, spaCy, Hugging face and GPT-3 to Extract Relationships from Long Texts
Accelerate knowledge graph construction with an all-star NLP pipeline

In my previous article Relationship Extraction with GPT-3, I have demonstrated how we can use the powerful GPT-3 to extract subject-verb-object relationships such as gene regulations and metabolic capacities from research article excerpts. GPT-3 not only correctly recognizes the name entities, but it also does the necessary noun-verb conversions and entity expansions to format the results. For example, “downregulation of A by B” can be correctly transformed into B,downregulate,A. Or “A and B are not utilized” can be correctly turned into {"A utilization": "negative", "B utilization": "negative"}. These abilities make GPT-3 a very valuable tool in our biomedical NLP toolkit.
However, this solution is not viable for full-length articles, because GPT-3’s prompt has a length limitation of about 1500 words. And it is expensive, too. So we’d better submit just the very sentences, where the relationships are, to GPT-3. It means that we need a pipeline that consists of four components that preprocesses, splits, filters and submits the sentences (Figure 1). The pipeline will generate subject-verb-object triplets in the right formats ready for Neo4j or other databases.
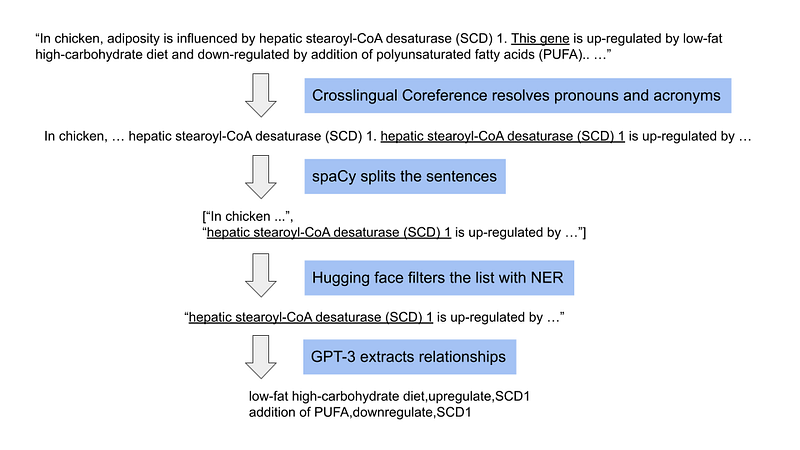
In this short article, I am going to build a pipeline to do so. I will use the alvaroalon2/biobert_genetic_ner and alvaroalon2/biobert_chemical_ner models by Alvaro A. from Hugging Face. You can find the code in my GitHub repository here. Notice that you need the Python libraries Crosslingual Coreference, spaCy, PyTorch and huggingface_hub for this project. And the en_core_web_sm model for spaCy and a GPT-3 account.
1. Pronoun resolution with Crosslingual Coreference
We use pronouns (“it”, “she”, “he” and “they”) and acronyms in long texts and conversations to avoid repetitions. But they can make relationship extraction difficult when sentences are submitted individually. The first step in the pipeline is to replace them with their original nouns. This task is called coreference. I use the Crosslingual Coreference library recommended by Tomaz Bratanic.
I have the example text:
In chicken, adiposity is influenced by hepatic stearoyl-CoA desaturase (SCD) 1. This gene is up-regulated by low-fat high-carbohydrate diet and down-regulated by addition of polyunsaturated fatty acids (PUFA).
My code was able to replace “this gene” with “hepatic stearoyl-CoA desaturase (SCD) 1”. This library works great. But it is quite slow. It took several seconds for two long sentences. So for long articles, we should either use parallel computing or skip this step with a small risk of missing some relationships.
2. Split the sentences with spaCy
Because the shortest texts where we can find subject-verb-object triplets are sentences, we need to split a long passage into a list of sentences. There are several ways to do it. Here I use the spaCy library.
This method generally does a great job. But it occasionally cuts incorrectly. For example, a sentence like
we constructed a pri-bmo-miR-275 expressing plasmid pcDNA3.0 [ie1-egfp-pri-bmo-miR-275-SV40] and BmSer-2–3´UTR recombinant reporter plasmids pGL3.0 [A3-luc-Ser-2–3' UTR-SV40].
will be cut into two: “we constructed a pri-bmo-miR-275 expressing plasmid pcDNA3.0 [ie1-egfp-pri-bmo-miR-275-SV40] and BmSer-2–3´UTR recombinant reporter plasmids pGL3.0” and “[A3-luc-Ser-2–3' UTR-SV40]”.
3. NER genes or biochemicals
After the split, we only need to keep sentences that are relevant to our quests. If we want to extract metabolic capacity relationships, we would want to keep sentences with biochemical names in them. By the same token, to extract gene regulation relationships, we would want to keep sentences with gene names. So here we need to do token classification, or Named-entity recognition (NER). In my pipeline, I use Hugging face with models provided by Alvaro A.. For gene regulation extraction, I only keep sentences with verbs such as “suppress” and “promot(e)”. Here is the code example.
4. GPT-3 extracts relationships
The last component comes from the code of my previous article. I have made two header prompts: one for gene regulations and the other for metabolic capacities. The code packs each sentence from Step 3 with the corresponding header prompt and sends it to the GPT-3 API.
5. Test the pipeline
The pipeline brings everything together and it looks like this.
Now let’s test the pipeline. I have prepared some short examples for each case and two Jupyter notebooks in my repository to get you started.
5.1 Metabolic capacity relationships
Let’s test the metabolic capacity relationship extraction first with a text like this.
Cells are Gram-stain-positive, non-motile, non-spore-forming rods, 0.8–1×1–2 µm, that usually occur singly, in pairs or in short chains. Colonies on mMRS agar are circular, with entire margins, smooth, convex, white and approximately 1 mm in diameter after 2 days incubation at 30 °C. Arginine is not deaminated. Can grow on mMRS agar supplemented with 5 % (w/v) NaCl, but not on mMRS agar supplemented with 6 % (w/v) NaCl. Negative for nitrate and nitrite reduction, indole production, urease production, pyruvate utilization, hydrolysis of hippurate, gas production from glucose and catalase production. The type strain is strain 47–3T (=NCIMB 15165T =CCM 8903T=LMG 31064T), isolated from traditional pickle in Heilongjiang Province, PR China. The DNA G+C content of the type strain is 50.9 mol%.
And the outputs are:
“Arginine is not deaminated.”
{“arginine deamination”: “negative”}
“Can grow on mMRS agar supplemented with 5 % (w/v) NaCl, but not on mMRS agar supplemented with 6 % (w/v) NaCl.”
{“5% NaCl”:”positive”, “6% NaCl”:”negative”}
“Negative for nitrate and nitrite reduction, indole production, urease production, pyruvate utilization, hydrolysis of hippurate, gas production from glucose and catalase production.”
{“nitrate reduction”: “negative”, “nitrite reduction”: “negative”, “indole production”: “negative”, “urease production”: “negative”, “pyruvate utilization”: “negative”, “hippurate hydrolysis”: “negative”, “gas production from glucose”: “negative”, “catalase production”: “negative”}
As you can see, spaCy and Hugging face have done a nice job. Sentences without biochemical words were filtered out. GPT-3 has also amazed me. In the first submitted sentence, you can see that GPT-3 has converted “deaminated” to “deamination” and combined it with “arginine” to construct the correct concept name “arginine deamination”. The third submitted sentence is quite convoluted even for humans. But it was not a problem for GPT-3, either. It has correctly segmented the concepts and expanded “nitrate and nitrite reduction” to “nitrate reduction” and “nitrite reduction”. It was the second submitted sentence that has tripped GPT-3 up. GPT-3 has missed the “mMRS agar” in both relationships.
The second example showcases the great entity expansion ability of GPT-3.
…
“Optimum growth is at 28 °C, 1.5 % (w/v) NaCl and pH 7.0.”
{“optimum growth temperature”: “28 °C”, “optimum growth NaCl concentration”: “1.5% (w/v)”, “optimum growth pH”: “7.0”}
…
GPT-3 was able to add “temperature” and “concentration”, both of which do not appear in the original text, to the output and to make the concepts correct.
5.2 Gene regulation relationships
Now it is time for us to extract some gene regulations. My first example has the following outputs.
“At 0.3 microM, retinoic acid (RA), a common morphogen and gene expression regulator in vertebrates had no noticeable influence on sponge development, slightly up-regulating EmH-3 expression.”
retinoic acid,upregulate,EmH-3
“In contrast, in sponges reared in 10, 8 microM and to a lesser extent 2 microM RA, there was a strong down-regulation of EmH-3 expression after hatching.”
RA,downregulate,EmH-3
…
“The inhibition of morphogenesis and down-regulation of EmH-3 expression were reversible when sponges were no longer subjected to retinoic acid (RA), a common morphogen and gene expression regulator in vertebrates.”
retinoic acid,downregulate,EmH-3
The seemingly contradictory results emphasized that context is crucial. When I submitted the sentences one by one, GPT-3 had difficulties in understanding that the expression of EmH-3 depends on the concentrations of Retinoic acid (RA). But if I submitted the three sentences together, GPT-3 omitted the information from the first sentence and only returned the down-regulation relationship (Figure 2).
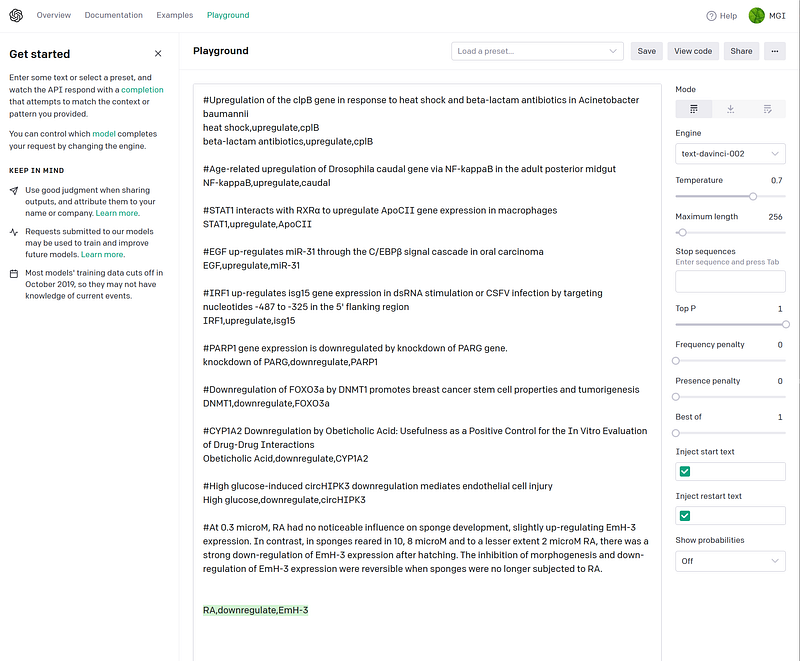
In my opinion, the best outcomes would be “0.3 microM RA,upregulate,EmH-3” and “10, 8, 2 microM RA,downregulate,EmH-3”. Interestingly, we can also see that Crosslingual Coreference has correctly replaced the pronouns in the first and third sentences (bold words) but missed it in the second one. And it is a surprise that GPT-3 was able to correctly extract just the essential part of the subject without the modifiers.
My second example is as follows.
bcl-2 and p53 gene products have been both linked to programmed cell death pathways. We have analyzed several human breast cancer cell lines for the expression of bcl-2 and p53. We found an inverse correlation between the expression of the two proteins. The result suggested that mutant p53 could substitute for bcl-2 function in breast cancer cells and that could also down-regulate bcl-2 expression. We found, indeed, that overexpression of a mutant p53 (mut 175) in MCF-7 cells could induce down-regulation of bcl-2 both at protein and mRNA level. However, the promoter region of the human bcl-2 gene does not contain the negative regulatory element responsible for the down-regulation. If this mechanism will be proved also for the wild-type p53 allele, it may disclose a possible mechanism for p53-induced apoptosis: down-regulation of bcl-2.
The pipeline was able to present me with the following results.
“The result suggested that mutant p53 could substitute for bcl-2 function in breast cancer cells and that could also down-regulate bcl-2 expression.”
mutant p53,downregulate,bcl-2
“We found, indeed, that overexpression of a mutant p53 (mut 175) in MCF-7 cells could induce down-regulation of bcl-2 both at protein and mRNA level.”
mutant p53,downregulate,bcl-2
“However, the promoter region of the human bcl-2 gene does not contain the negative regulatory element responsible for down-regulation of bcl-2.”
So, the answer is: There is no one definitive answer to this question.
“If this mechanism will be proved also for the wild-type p53 allele, it may disclose a possible mechanism for p53-induced apoptosis: down-regulation of bcl-2.”
p53,downregulate,bcl-2
It is interesting that GPT-3 has established the relationship that “mutant p53” “downregulates” “bcl-2”. To my understanding, the mutant p53 is a gene in this case. So the relationship extracted by GPT-3 seems correct, even though I would argue that “overexpression of mutant p53” is better.
The output for the third submitted sentence is not correct. In fact, it should not have been submitted in the first place, even though it contains a gene entity and a key verb. But we can remove it in a future post-processing step based on its incomplete semantic structure. And I have noticed that Crosslingual Coreference has modified “down-regulation” with “of bcl-2”. That is a nice touch and it can be helpful for some use cases.
The third submitted sentence has been processed correctly.
It is worth mentioning that we can observe the asynchronous nature of the pipeline unexpectedly. “We found …” appears before “The result …” in the original text. But the orders of their outputs were swapped in both of my runs. Perhaps the sentence “We found …” required longer GPT-3 processing time.
Conclusion
Success. In this article, I have presented my simple but powerful pipeline that extracts relationships from long texts. As you can also see in the article, Crosslingual Coreference is able to resolve many of the pronouns and acronyms. And it adds modifiers to nouns, too. spaCy splits the sentences and Hugging face filters them with domain specific NER. Finally, GPT-3 does its magic. It converts verbs to nouns, sometimes cleans and sometimes trims the entities. The results are well-formatted subject-verb-object triplets ready for Neo4j or other databases.
But this all-star NLP is still not perfect. Crosslingual Coreference missed an acronym in my example. spaCy misjudged the endings of a sentence and Hugging face did not recognize some letters as a part of the entity. GPT-3 missed or misinterpreted the contexts. In summary, this pipeline is a great productivity boost for your relationship extraction tasks, but you need to curate the results and ensure the accuracy in the end.
You can also further expand this pipeline. You can remove the duplicate outputs, post-process the results and remove those incomplete extractions, like the one in the last example. Finally, you can improve GPT-3 with fine tuning or include more examples in the prompt. You can even set the components up as microservices in Kubernetes. The possibility is endless.





