
Decentralize Knowledge Graph with GUN
Build a decentralized protein-protein interaction STRING database

A crafty rabbit has three burrows.
— Chinese idiom
This old Chinese idiom says it all: don’t put all your eggs in one basket. It is true for a crafty rabbit. It is also true for us data scientists.
During the development of our electronic health record (EHR) chatbot Doctor.ai (here, here, here and here), one issue emerges: where should we put all these private medical records? The first option is the cloud. However, the accompanying risk of privacy breaches unsettles patient advocates. Also, there is a small chance that a cloud provider may shut down their business one day and along goes our data.
The second option is to deposit the data in a P2P network. That is, we distribute the data to many independent and voluntary computers. It is quite similar to how BitTorrent works. As a result, no one can have the sole control over the data. And everyone with the entry point and credential can access the data.
This is an interesting idea. So I want to try it out. Because the backend database of Doctor.ai is a Neo4j graph, I searched around for a P2P graph database. And I was rewarded with GUN. Here is the official description:
It is a graph database that can store SQL-like tables, JSON-like documents, files and livestreaming video, plus relational and hypergraph data! … The universal GUN graph is distributed across all peers participating in the network. Browser peers use localStorage or IndexedDB to store only a subset of the graph they are subscribed to, synced using WebRTC, Websockets, or other transports. The same browser code also runs in NodeJS with adapter plugins for
fs, S3-like storage backups, UDP multicast, and other features that let it stay in "relay" mode only or to store everything.
Check out Fireship’s two introductory videos on YouTube (the other one is here):
This whole concept excited me. Even though I am very green in JavaScript, I tried GUN hands-on to see whether it is a good backend for Doctor.ai. In this tutorial, I will show you my own GUN journey: I imported the protein-protein interactions of a bacterium — Formosa agariphila from STRING. I implemented an example query script. All were written in JavaScript. The code for this tutorial is on my GitHub page:
1. Import CSV files into GUN
It turned out that importing normal-sized CSV files into GUN was not trivial. First download the two CSV files for this project from STRING here, or you can do it like this:
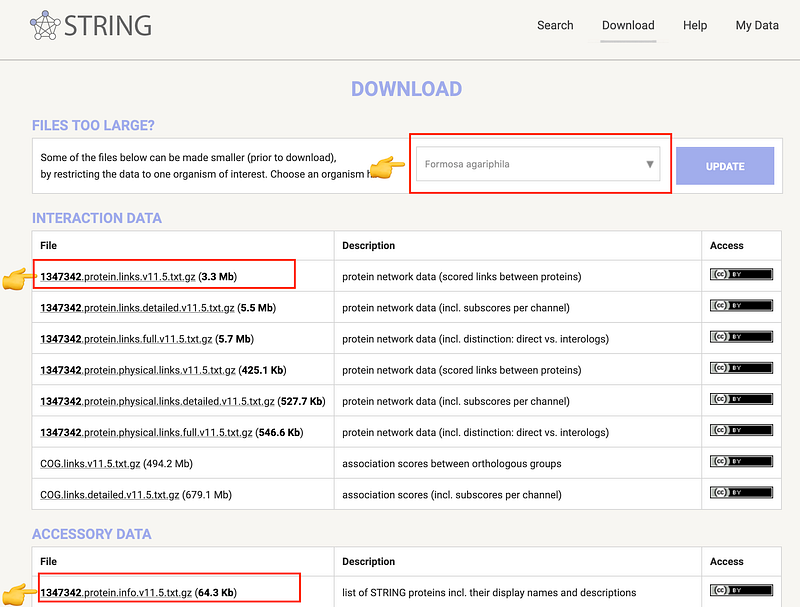
The “links” file contains the protein-protein interactions, while the “info” file contains information about each protein. After some experiments, I decided to import them separately with two scripts.
We need just three packages. After some trials and errors, I found out that Papa Parse can do the job:
Then comes the import. It turned out that the getters and setters in GUN are asynchronous. Without special measures, the main event loop would end before the imports can finish. In this project, I used Promises. For example, the following code imports the nodes:
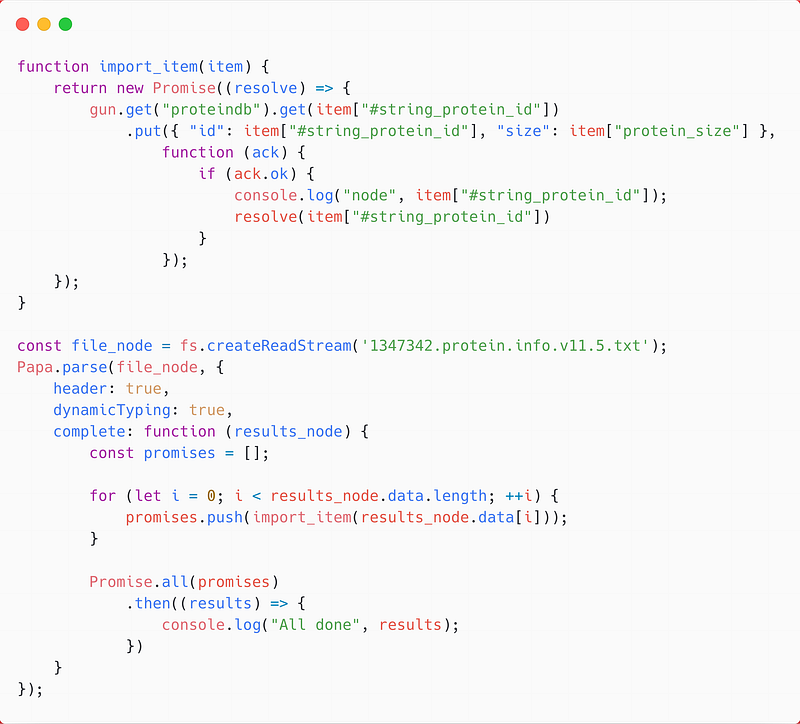
The import_item does the actual importing with its gun.get().put() chain. The get() function returns a pointer to a node, while the put() function sets the values in that node. But this function chain is asynchronous. For this reason, I wrapped it around a Promise. The main loop Papa.parse collects all these promises and waits for their completions with Promise.all. As a result, the nodes can be imported properly.
The script for link import is similar. In GUN, a relationship can be understood as a property of a node. In our case, this property is a set called STRING. It contains the ids and scores of all the proteins that are connected to this particular protein node. In this project, only links with combined scores higher than 800 are kept. Here is the import_item function for import_edge.js.

2. Query the database
Once the data is imported, we can query the database either in the Node CLI or in a JavaScript.
2.1 Overview statistics
First off, I want to see all the protein-protein interactions with combined scores higher than 900. Type node in your console to open the Node CLI. Then type the following commands one by one:
The first two lines initialize GUN. The third line queries the database. It first uses the map function to get all the proteins in the proteindb. The once function goes into each protein, gets their STRING property and uses the map function to print out those connections whose scores are higher than 900.
And you can see the output like this:
2.2 Examine one protein
We can also examine only one particular protein 1347342.BN863_5660 and its connections:
And the console should show something like this:
2.3 Aggregation
Finally, let’s get all the proteins that are connected to 1347342.BN863_5170 and calculate the average protein size:
Because the function chain is asynchronous and we can’t know in advance when the data will arrive from the peers, we can only aggregate the sum and average whenever a data point is available. The result is a running tally like this:
It is interesting that although we can take the last line as our final answer, we are not 100% sure that it is the correct answer in this implementation! So if you have a better solution, please tell me.
3. Decentralization
The main selling point of GUN is its P2P feature. It works on my computer across two different folders. Unfortunately, when I set up relay peers on Heroku or AWS EC2 according to the official instructions and connected GUN with them, the data synchronization was a failure — only a piece or two were synchronized.
Conclusion
Even though I failed to make data decentralization happen in this project, it is a very appealing idea. When deployed optimally, this model means high data availability. And nobody can have full control over the dataset. Even though many people can have access to the data, GUN can control data editing via its User system. I have not touched this topic in this article, but I encourage you to explore it further.
As a graph database, GUN is harder to use than Neo4j in my opinion. Neo4j has a very expressive query language called Cypher. Its ASCII art style syntax is concise and easy to understand. In addition, Neo4j has an extensive collection of aggregate functions, machine learning utilities and visualization tools. They enable the users to quickly navigate the data and get new insights. These features are absent in GUN. Finally, the asynchronous nature of GUN takes some getting used to for the synchronous mind.
On its official website, you can see many interesting projects with GUN. And the online community is very active and responsive. But I still feel that there are too few examples for this good library. So I hope that you can keep learning it and use it in your project too.
License
STRING is freely available under a ‘Creative Commons BY 4.0’ license.
More content at plainenglish.io. Sign up for our free weekly newsletter. Get exclusive access to writing opportunities and advice in our community Discord.





