
Using Over-Sampling Techniques for Extremely Imbalanced Data
In the previous post “Using Under-Sampling Techniques for Extremely Imbalanced Data”, I described several under-sampling techniques to deal with extremely imbalanced data. In this post, I describe over-sampling techniques to attack the same issue.
I have written articles on a variety of data science topics. For ease of use, you can bookmark my summary post “Dataman Learning Paths — Build Your Skills, Drive Your Career” which lists the links to all articles.
Oversampling increases the weight of the minority class by replicating the minority class examples. Although it does not increase information, it raises the over-fitting issue, which causes the model to be too specific. It may well be the case that the accuracy for the training set is high, yet the performance for new datasets is worse.
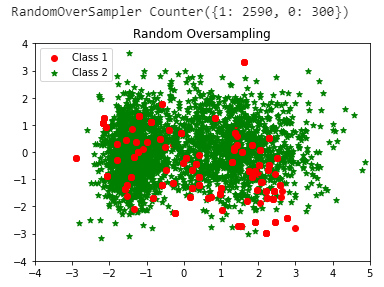
(1) Random oversampling for the minority class
Random oversampling simply replicate randomly the minority class examples. Random oversampling is known to increase the likelihood of occurring overfitting. On the other hand, the major drawback of Random undersampling is that this method can discard useful data.
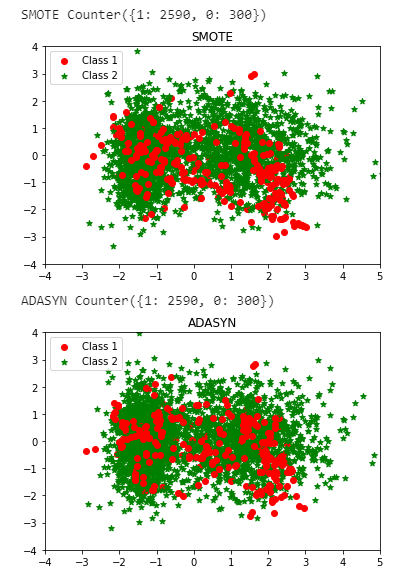
(2) Synthetic Minority Oversampling Technique (SMOTE)
To avoid the over-fitting problem, Chawla et al. (2002) propose the Synthetic Minority Over-sampling Technique (SMOTE). This method is considered a state-of-art technique and works well in various applications. This method generates synthetic data based on the feature space similarities between existing minority instances. To create a synthetic instance, it finds the K-nearest neighbors of each minority instance, randomly selects one of them and then calculates linear interpolations to produce a new minority instance in the neighborhood.
(3) ADASYN: Adaptive Synthetic Sampling
Motivated by SMOTE, He et al. (2009) propose the Adaptive Synthetic sampling (ADASYN) technique, and receive wide attention.
ADASYN generates samples of the minority class according to their density distributions. More synthetic data is generated for minority class samples that are harder to learn, compared to those minority samples that are easier to learn. It calculates the K-nearest neighbors of each minority instance, then gets the class ratio of the minority and majority instances to generate new samples. Repeating this process adaptively shifts the decision boundary to focus on those samples that are difficult to learn.
Below I demonstrate the three oversampling methods. The notebook is available via this Github link.
Have you read the previous article “Using Under-Sampling Techniques for Extremely Imbalanced Data”? The two articles together can give you a comprehensive view of both the under-sampling and over-sampling techniques!
Additional Note when Applying in H2O
For data scientists who use H2O.ai, how do you apply the above sampling techniques? If you are not familiar with H2O, the post “My Lecture Notes on Random Forest, Gradient Boosting, Regularization, and H2O.ai” shows the H2O code snippets for various algorithms.
It is fairly easy to do so. From the above sampling code snippets, you get the sampled data X_rs and the corresponding y labels y_rs. All you need to do is to concatenate X_rs and y_rs to a data frame, then convert to an H2O data frame as usual:
References
- NV Chawla, KW Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research (JAIR), 16:321–357, 2002.
This chapter is part of the book series “Handbook of Anomaly Detection with Python Outlier Detection.” For easy navigation to chapters, I list the chapters at the end.
- Chapter 1 — Introduction
- Chapter 2 — Histogram-Based Outlier Score (HBOS)
- Chapter 3 — Empirical Cumulative Outlier Detection (ECOD)
- Chapter 4 — Isolation Forest (IForest)
- Chapter 5 — Principal Component Analysis (PCA)
- Chapter 6 — One-Class Support Vector Machine (OCSVM)
- Chapter 7 — Gaussian Mixed Models (GMM)
- Chapter 8 — K-nearest Neighbors (KNN)
- Chapter 9 — Local Outlier Factor (LOF)
- Chapter 10 — Clustering-Based Local Outlier Factor (CBLOF)
- Chapter 11 — Extreme Boosting-Based Outlier Detection (XGBOD)
- Chapter 12 — Autoencoders
- Chapter 13 — Under-sampling for Extremely Imbalanced Data
- Chapter 14 — Over-sampling for Extremely Imbalanced Data
Readers are recommended to purchase books by Chris Kuo:

- The explainable AI: https://a.co/d/cNL8Hu4
- Transfer learning for image classification: https://a.co/d/hLdCkMH
- Modern time series anomaly detection: https://a.co/d/ieIbAxM
- Handbook of Anomaly Detection: https://a.co/d/5sKS8bI




