
Is the Zero ETL Approach the End of the Data Engineer?
Data Integration and Data Pipelines at the Snap of a Finger?

New SaaS cloud-based services make everything easy. One can imagine IT Services and a Data Lake like electricity that easily comes from the socket, so to speak. Is this really this easy so that these services can even make Data Engineers superfluous in the future?
Just imagine: no more bad-tempered IT infrastructure tech guys and architects who only see risks, or Data Engineers who cost a lot of money and laboriously build data pipelines. At most, there would only be Data Scientists who integrate the data themselves simply by dragging and dropping using a zero ETL approach and then make the data usable and evaluate it profitably. This sounds like a wonderland dream for every CIO. However, how reliable could be this whole thing?
First, let’s talk about the technology: What does Zero ETL even mean? At the end of the day, it means that modern cloud-based Data Warehouses or even Data Lakehouses use the services of the large cloud providers to analyze data directly from other sources. So instead of extracting data from SQL or NoSQL databases, transforming and then storing it twice into your Data Lake or Data Warehouse, etc. You just simply access the data directly (often simply via SQL). This has several advantages:
- No more need for data pipelines, especially less effort if you have previously programmed them.
- No duplicate data storage, which can cost money and performance.
- The data is always up-to-date.
One of the most exciting projects in this area is Google BigLake, for example, with which you can access various data sources and even across platforms, such as Azure and AWS, in order to analyze data via SQL. The advantages described above are actually given here and of course you ask yourself, ok but where is the catch?
If you now counter that with this, the result can quickly lead to a data chaos with the Data Lakehouse quickly becoming a Data Swamp. This is due to the fact that the data is everywhere and is only analyzed by the end user, and this is here not the case.
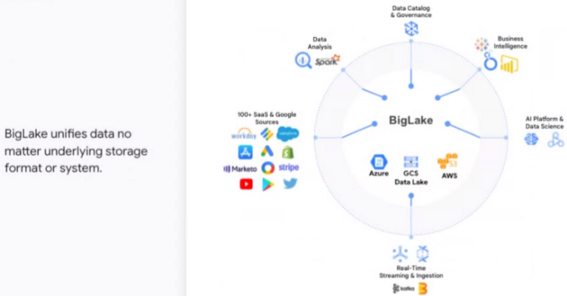
With new services such as DataPlex, with which you can also assign access rights to such external data sources, provide them with view logic and also integrate them into a Data Catalog, a Data Governance with a secured Data Mesh is also possible. Of course, the other big cloud platforms like AWS and Azure offer similar products.
So you can really say that this will make data integration much easier. Fewer services, less duplicate data storage, less custom programming. So it can be said that some of the tasks of the Data Engineer have actually been taken over by the technical solutions, or made more simpler. However, there are difficulties existing: Companies that do not work in the cloud cannot not profit from the situation, since these architectures are usually only feasible in the cloud.
Nonetheless, companies that do outsource their IT into the cloud can also not pass up on Data Engineers, because there are still systems that are not yet so easy to integrate. Perhaps the scope of tasks will simply change, instead of building ELT and ELT pipelines themselves using CDC, etc. They will now use such easily integrable services and will then be more concerned with topics such as Data Governance and Data Meshes, in which the distribution and protection of the data as well as the manifestation of the Data Culture in the company are at stake. If you are interested in the topic of Data Culture, feel free to look into the article below.
Sources and Further Readings
[1] THENEXTPLATFORM (2022)





