
How to make your Data Swamp a Data Lake
What is a Data Swamp?
Reasons for why you should avoid it

By definition, a Data Swamp is an unmanaged Data Lake that is either inaccessible to intended users or provides little value. Data swamps occur when adequate data quality and data governance measures are not implemented. Sometimes a Data Swamp can also arise from a Data Warehouse due to existing hybrid models.
What is a Data Lake again?
To explain the emergence of Data Swamp in more detail, it is first necessary to understand the concept of a Data Lake. A Data Lake is a large pool of raw data for which no use has yet been determined. A Data Warehouse, on the other hand, is a repository for structured, filtered data that has already been processed for a specific purpose [1].
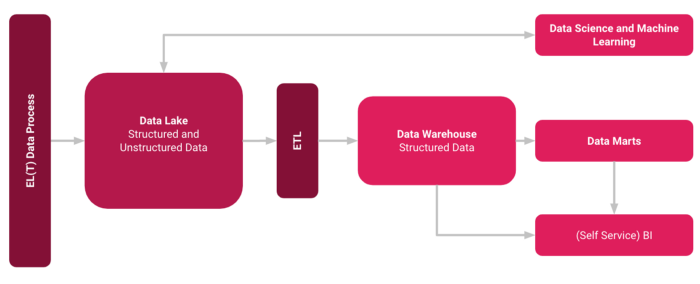
What Problems can occur?
If a Data Lake holds too much data in a poorly organized manner without suitable metadata management and a reliable data governance, relevant data becomes increasingly difficult to find. The information content of the Data Lake decreases, even though new data is constantly being added. A lack of life cycle management of the data also leads to the silting up of a Data Lake. After a certain time, data loses its relevance. If the data still remains in the data depot, more and more data with a lack of relevance accumulates over long periods of time. Incorrect time stamps of a data set also lead to information that cannot be found or evaluated.
Typical Characteristics of a Data Swamp
There are typical characteristics of a Data Swamp that you can check your Data Lake for (and better get rid off):
- Big Data without any organization and documentation through a Data Catalog or a role concept for example.
- Missing meta-information of the structured or unstructured data.
- Outdated and faulty data.
- No Chief Data Officer or Product Owner who manages the platform.
- Missing or broken relationships between the information.
How to clean your Data Swamp up again
As previously mentioned, an active management would be useful. Modern roles such as the product owner or a CDO are helpful here, who organize and further develop this Data Lake. Furthermore, a data catalog should be built, which creates clarity about the data. Together with a role concept, it ensures that the data reaches the right people. Faulty and old data should be deleted or archived, as this is often desired by regulations anyway and can also result in cost benefits. Requirements for data recording are, for example, the labeling of the data origin, metadata labeling and a meaningful nomenclature.
Summary
Data Lakes and hybrid Data Warehouses are certainly a wonderful tool to make the company data-driven and to bring it forward. However, such a Data Lake must be managed and maintained, otherwise it degenerates into a Data Swamp. This often leads to the fact that information is wrong and users do not use it at all, then Data Lakes do not create any advantages but only produce costs.
Sources and Further Readings
[1] talend, Data Lake vs. Data Warehouse





