
What is a Data Lakehouse?
New Paradigm or just a Buzzword?

What are Data Lakehouses? Just another buzzword or actually the successor to Data Lakes and Warehouses? In order to combine the advantages of Data Warehouses and Lakes, many companies have developed a hybrid BI environment. They store raw data in Data Lakes, while loading parts of it into the Data Warehouse as needed. The Data Lakehouse should combine the advantages of Data Lakes and Data Warehouses into a hybrid concept. The two systems are not operated side by side, but as a novel single system.
Data Warehouses vs. Data Lakes
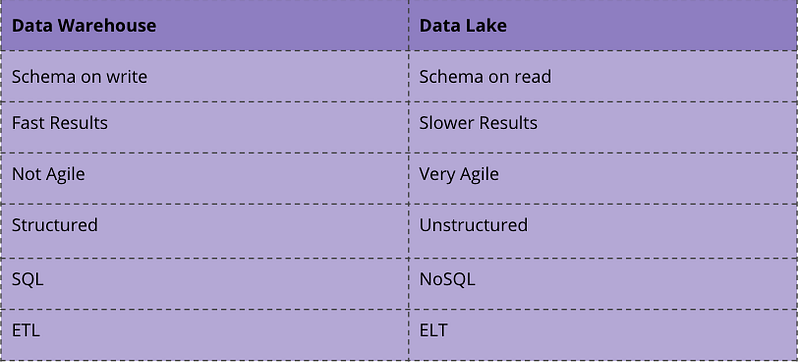
Both, Data Lakes and Data Warehouses are established terms when it comes to storing Big Data, but the two terms are not synonymous. A Data Lake is a large pool of raw data for which no use has yet been determined. A Data Warehouse, on the other hand, is a repository for structured, filtered data that has already been processed for a specific purpose [1].
While Data Warehouses use the classic ETL process in combination with structured data in a relational database, a Data Lake uses paradigms such as ELT and a schema on read as well as often unstructured data [2].
So what is a Data Lakehouse?
It is not just about integrating a Data Lake with a Data Warehouse, but rather integrating a Data Lake, a Data Warehouse, and purpose-built storage to enable unified governance and ease of data movement[3]. From my own experience has often shown that a Data Lakes can be realized much faster. Once all data is available, Data Warehouses can still be built on top of it as a hybrid solution.
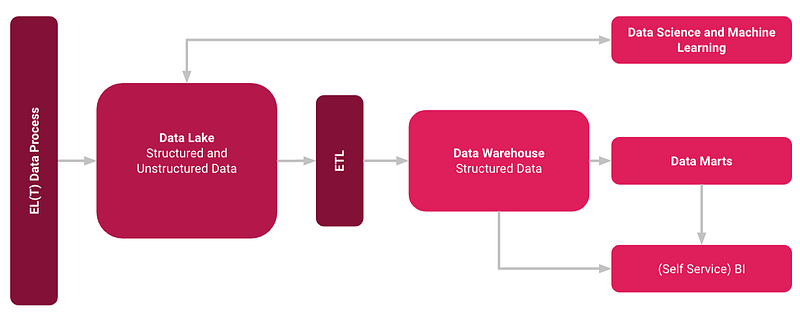
This makes rigid and classically planned Data Warehouses a thing of the past. This greatly accelerates the provision of dashboards and analyses and is a good step towards a data-driven culture. An implementation with new SaaS services from the cloud and approaches such as ELT instead of ETL also accelerate the development.
In my opinion, this approach has been around for some time, especially in the area of Cloud Data Warehousing and Data Lakes. Here, these two technologies have long been combined with each other in a hybrid approach (Read here more about it). In my opinion, the new trend term Data Lakehouse simply describes this established approach.
How to build up a Data Lakehouse?
To be a bit more concrete, we can take a look at how and with which technologies and services such Data Lakehouses can be built. In the figure below, an architecture is shown that was realized in the Google Cloud. Here, Cloud Storage and BigQuery are used as storage. Due to the good connectivity in the Google Cloud, the services can easily exchange data with each other and thus be used for analysis, machine learning and other topics.
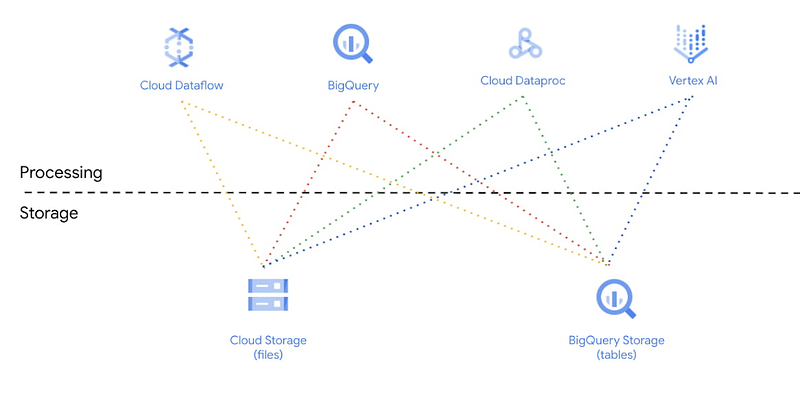
This architecture is of course also possible with other providers such as AWS or MS Azure. Microsoft for example offers with Azure Synapse Analytics such an analysis platform. Azure is already using several Data Lakehouse approaches, such as the option of integrating data from a Data Lake as a virtual table.
Summary
For me, the topic of Data Lakehouses is not new, this hybrid approach has been around for some time in the area of Cloud Data Warehousing and Lakes, and the term Data Lakehouse now describes this approach. In this article, I have shown you the difference between Data warehouses, Data Lakes and Data Lakehouses and an example of how such a Data Lakehouse can be technically implemented.
Sources and Further Readings
[1] talend, Data Lake vs. Data Warehouse
[2] IBM, Charting the data lake: Using the data models with schema-on-read and schema-on-write (2017)
[3] AWS, What is a Lake House approach? (2021)
[4] Google Cloud, Open data lakehouse on Google Cloud (2021)





