
What is a Data Mesh?
New Technology or just an Approach for efficient Data Platforms?

Data Lakes and Data Warehouses or even the combination in a Data Lakehouse are considered to be the key to the use of Big Data. However, these approaches often bring the problem that with data from many sources and formats, they can become too complex and prevent efficient use. This often results in frustrated users.
Recap Data Lake vs. Data Warehouse
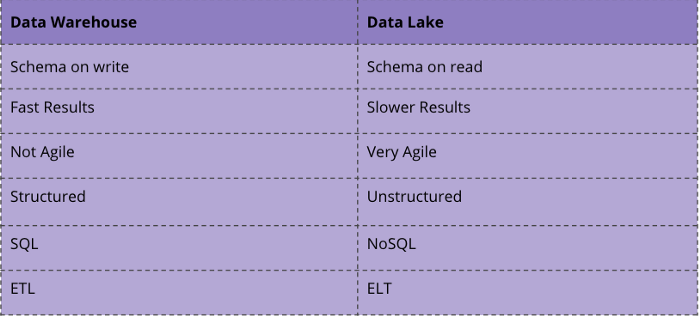
To understand the topic holistically a short recap on the topic Data Warehouse vs. Data Lake and where the differences lie. Data Lakes and Data Warehouses are established terms when it comes to storing Big Data, but the two terms are not synonymous. A Data Lake is a vast pool of raw data that has not a specific use case yet. A Data Warehouse, on the other hand, is a repository for structured and organized data that has already been dedicated to a specific purpose [1].
While Data Warehouses use the common ETL process in combination with already organized data in a relational database, a Data Lake uses paradigms such as ELT and a schema on read in relation to unstructured data [2].
Data Lakehouses combine both
Storing raw data in Data Lakes, while loading parts of it into the Data Warehouse for purposes like Self-Service BI or ML Services makes it a Data Lakehouse. The Data Lakehouse should combine the advantages of Data Lakes and Data Warehouses into a hybrid concept. The two systems are not operated side by side, but as a novel single system. Benefits of a Data Lakehouse could be [3]:
- Decoupling data storage from data processing to achieve better scalability.
- Open standardized storage formats and interfaces.
- Support for different data types, from unstructured to structured data.
- Support for various workloads, such as data science, machine learning, SQL, and analytics.
- End-to-end streaming: streaming support eliminates the need for separate systems to serve real-time data applications.
- Shorter time-to-value compared to a Data Warehouse.
So what is a Data Mesh Approach?
A Data Mesh approach could improve the Data Lake as the dominant architectural paradigm. It is important to understand that the Data Mesh concept primarily establishes a new organizational perspective and is less based on technical problem solving. Therefore, you should consider this four principles when building up a Data Mesh organization [4]:
- Domain-oriented decentralized data ownership and architecture: A Data Mesh should serve the individuals business units. Herefore, one or different Data Lakehouses could be build.
- Data as a product: The Data Lakehouse architecture helps to manage data as a product by providing different data team members in domain-specific teams complete control over the data lifecycle.
- Self-serve data infrastructure as a platform: Users can supply themselves with data in a self-service BI tool, while data scientists, for example, access the same data and develop models.
- Federated computational governance: The data should be backed up and distributed with a role concept. Data catalogs are also helpful here, for example.
How Agility and Product Owners create additional Value
Of course, when Data Lakehouses are built for individual departments, it is important to include these units in the development process. This is where product owners help, because they are the link between departments and developers and data scientists. The next logical step is to enable the departments themselves to define data products that will help them. And then to develop and maintain these themselves usually with initial support from a data product owner already active elsewhere. This requires systematic communication between data providers and data users to align needs and intentions on the one hand and potentially usable data for this purpose on the other.
Summary
The data mesh is therefore not a new type of technology like Data Warehouses are, but an organizational approach to distribute data in the company securely, transparently and efficiently. A Data Lakehouse is a hybrid approach between a Data Lake and a Data Warehouse. This is not a new technology but an efficient way to operate Data Warehouse and Data Lake as one and to build a modern data platform. Practically, Data Lakehouses support the principles of building a data mesh. In order to develop data-driven products really close to the customer, Agile Team and Product Owner are recommended.
Sources and Further Readings
[1] talend, Data Lake vs. Data Warehouse
[2] IBM, Charting the data lake: Using the data models with schema-on-read and schema-on-write (2017)
[3] Stefan Koch, Können Lakehouses einen Paradigmenwechsel anstossen? (2021)
[4] Michael Armbrust, Ali Ghodsi, Bharath Gowda, Arsalan Tavakoli-Shiraji, Reynold Xin and Matei Zaharia, Frequently Asked Questions About the Data Lakehouse (2021)





