
AI Agents Are All You Need
LLMs have been around for a few years now, and they are rapidly evolving towards AI Agents and Agentic workflows. Don’t get me wrong, LLMs are great, but they are still not efficient at automating the stuff on their own. LLMs combined with other tools are a really efficient way to utilize the general intelligence LLMs possess, by consuming massive amounts of language data. The biggest problem with LLMs is their tendency to get lost (hallucination and self-consistency) here and there, we never know when the LLMs or agents might fail. There have been few guardrails around these failures, but we are far from over to exploit the full capabilities of LLMs general intelligence.
So, in today’s blog, we are going to take a deep dive into what the future of LLMs looks like, how are we moving towards agents from RAG pipelines, and what are the challenges in creating a feasible LLM-based AI agent (tool usage, memory, and planning)? And lastly, we look into different types of agents and what the future of AI Agents and RAG looks like.

From RAG to Agents
RAG is a semi-parametric type of system, where the parametric part is the Large Language Model and the rest is the non-parametric part. Combining all the different parts gives us the Semi-parametric system. LLMs have all the information stored in their weights or parameters (in an encoded form) whereas the rest of the system has no parameters defining that knowledge.
But why does this solve the issue?
- Swapping in and out indices (specific information in LLMs) gives us customization, which means that we don’t suffer staleness and also we can revise what is in the index.
- Grounding LLMs with these indices means we have less hallucination, and we can do citations and attribution by pointing back to the source.
So in principle, RAG gives us the ability to create better contextualization for our LLMs to perform well.
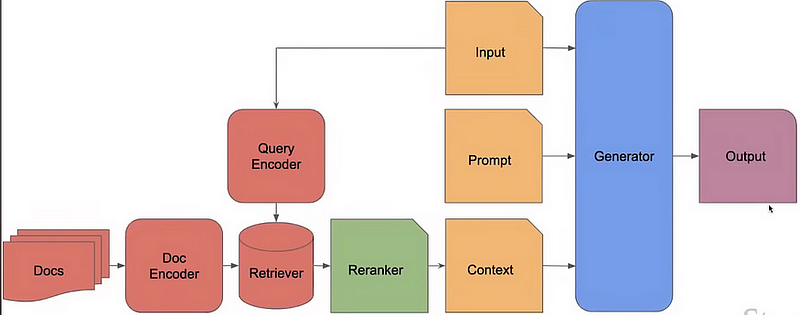
To make much better sense of RAG, don’t forget to check out this RAG 2.0 article.
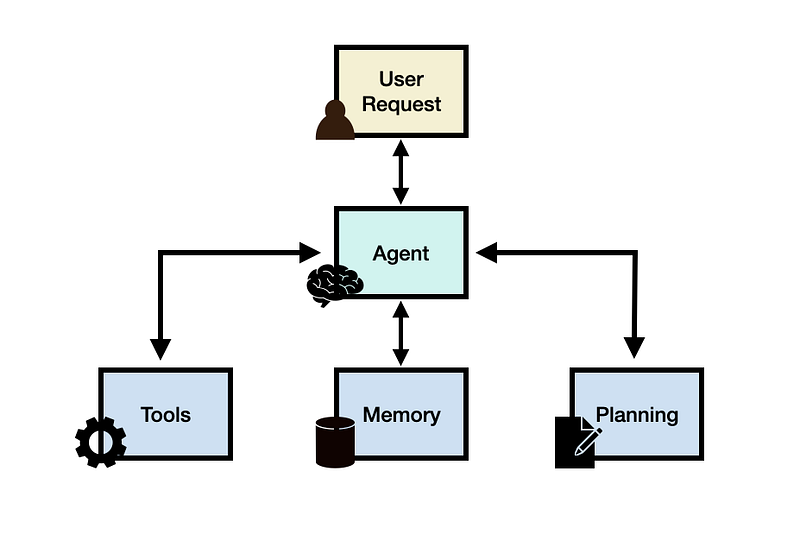
An “agent” is an automated reasoning and decision engine. It takes in a user input/query and can make internal decisions for executing that query in order to return the correct result. The key agent components can include, but are not limited to:
- Breaking down a complex question into smaller ones
- Choosing an external Tool to use + coming up with parameters for calling the Tool
- Planning out a set of tasks
- Storing previously completed tasks in a memory module
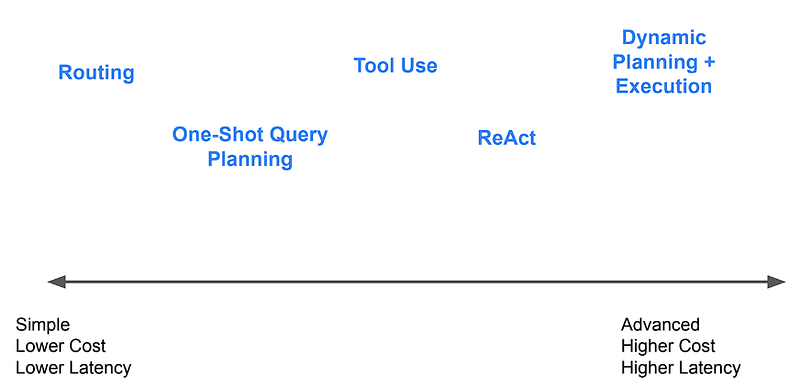
We’ve got different types of agents, from simple to extremely complex ones. Depending upon the complexity of the task, we design these agents so that they can autonomously decide to choose the tools available to them. Devin AI is one such AI agent that recently got a lot of hype. Given below image shows different types of agents and their level of complexity.
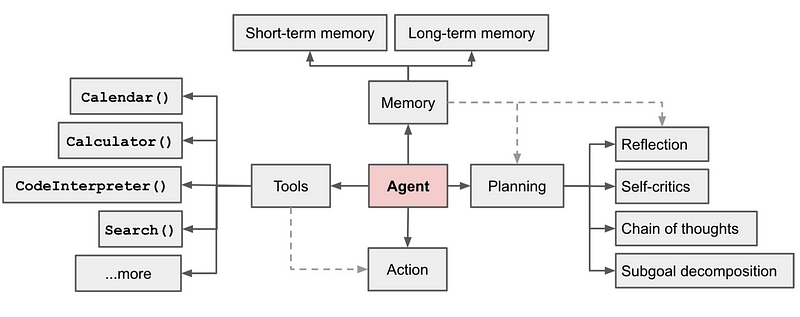
Agent System Overview
In an LLM-powered autonomous agent system, LLM functions as the agent’s brain, utilizing different components to act out in the digital world.
Tool use
- The agent learns to call external APIs or tools for extra information/context or capability that might be missing in the model weights (often hard to change after pre-training). This includes things like current information, mathematical engines, code execution capability, access to proprietary information sources, and many more.
Memory
- Short-term memory: In-context learning (See Prompt Engineering) can be thought of as utilizing short-term memory of the model to operate on a given problem. The context length window can be thought of as Short-term memory.
- Long-term memory: Providing the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval. The Retrieval part in RAG can be thought of as Long-term memory.
Planning
- Subgoal & task decomposition: The agent breaks down larger tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.
- Reflection and refinement: The agent can do self-criticism (though doubtful in certain ways) and self-reflection over past actions, learn from mistakes, and refine them for future steps, thus improving the final results.
Tool Usage for AI Agents
Being able to use tools is what distinguishes humans from other creatures in many ways. We create, modify, and utilize external objects to expand our physical and cognitive capabilities. Similarly, equipping LLMs with external tools can significantly extend their capabilities.
In the AI Agent setting, tools correspond to a set of tool/s that enables the LLM agent to interact with external environments such as Google Search, Code Interpreter, Math Engine, etc. Tools could also be some form of databases, knowledge bases, and external models. When the agent interacts with external tools it executes tasks via workflows that assist the agent in obtaining observations or necessary context to complete the given subtasks and ultimately the full task.
A few examples of how tools are leveraged in different ways by LLMs:
- MRKL (Modular Reasoning, Knowledge, and Language) is a framework that combines LLMs with expert modules that are either LLMs or symbolic (calculator or weather API).
- HuggingGPT — an LLM-powered agent that leverages LLMs as a task planner to connect various existing AI models (based on descriptions) to solve AI tasks.
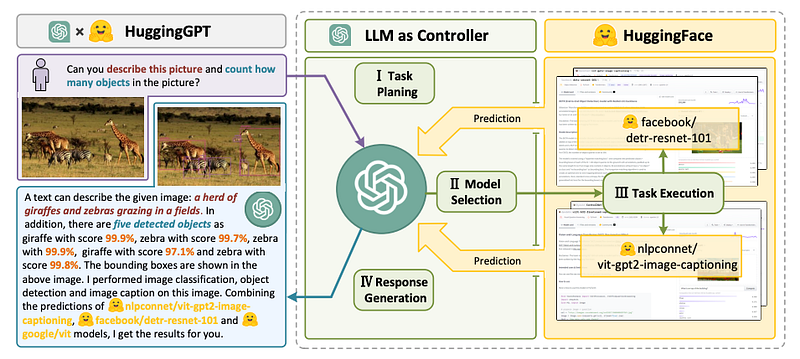
The whole process of HuggingGPT, illustrated in the above figure, can be divided into four stages as mentioned in the original paper:
Task Planning: Using ChatGPT to analyze the requests of users to understand their intentions, and disassemble them into possible solvable tasks.
Model Selection: To solve the planned tasks, ChatGPT selects expert models that are hosted on Hugging Face based on model descriptions.
Task Execution: Invoke and execute each selected model, and return the results to ChatGPT.
Response Generation: Finally, ChatGPT is utilized to integrate the predictions from all models and generate responses for users.
Please go through the below image carefully to understand how HuggingGPT works in a real example.

ChatGPT Plugins and OpenAI API function calling are good examples of LLMs augmented with tool use capability working in practice. The collection of tool APIs can be provided by other developers (as in Plugins) or self-defined (as in function calls).
Solving Memory Issues in Agentic Workflows
Memory can be defined as the resource or store used to acquire, store, retain, and later retrieve information. There are several types of memory in any computing system.
Buffer Memory (Sensory Memory): Just as sensory memory acts as a brief holdout (goes away as soon as the task is finished) for sensory information, buffer memory in computer systems can hold transient data, like an instruction set. For LLMs, this could refer to token buffers or input queues.
Working Memory (Short-Term Memory, STM): LLMs, while processing text, employ mechanisms that resemble human working memory. They use attention mechanisms to maintain a ‘focus’ on certain parts of the input. In transformer-based models like GPT, the attention weights serve a similar function to STM, holding onto and processing several pieces of information at once. Working Memory for LLM is the context length of it.
Parameter Memory (Long-Term Memory, LTM): The parameters (or weights) of LLMs can be viewed as a form of long-term memory. Once trained, these parameters encode vast amounts of information gleaned from the training data and can be retained indefinitely.
- Explicit/Declarative Memory → In LLMs, the equivalent of declarative memory would be the weights that are used to generate responses based on learned facts and concepts. These can be accessed and used to produce explicit outputs related to knowledge the model has ‘memorized’ during training. For example, Elon Musk is the Owner of Tesla, this is a specific thing stored in the model’s weight.
- Implicit/Procedural Memory → This is a more generalized memory system that captures the abstraction or concepts rather than straight-up facts through repeated practice (training) on various tasks. For example, what is beauty? There is no specific answer to this and yet system will be able to answer this.
In LLMs, ‘memories’ are not stored as discrete events but are represented as patterns (abstract world models, not fully though) across a network of interconnected nodes, and the model ‘recalls’ information by dynamically generating responses based on its trained state.
To know more about hardware memories, check out Notes on AI Hardware.
The external memory can solve the problem of finite attention span. Standard practice is to save the embedding vectors (text converted into dense vectors) into a vector store database that can support fast maximum inner-product search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN) algorithm to return approximately the top-k nearest neighbors to trade off a little accuracy lost for a huge speedup.
A few algorithms for this retrieval: LSH, ANNOY, HNSW, FAISS and ScaNN
The general principle behind all these methods — LSH, ANNOY, HNSW, FAISS, and ScaNN — is to efficiently approximate nearest neighbor searches in high-dimensional spaces. These methods are designed to overcome the computational intensity of exact searches by using strategies that group similar data points together in a way that allows for faster retrieval.
Planning: Biggest problem of current AI Agents
Agents can sometimes make a large number of calls to answer a single/simple question, accumulating tokens for each query made to LLM. Not only is this costly, it introduces latency. Token generation is still a relatively slow process, most (not all) of the latency in LLM-based applications comes from generating output tokens. Calling an LLM repeatedly and asking it to provide thoughts/observations, we end up generating a lot of output tokens (cost) resulting in high latency (degraded user experience).
An example of this is shown in the below image. In order to reach the correct answer or action LLMs make several requests often introducing a lot of delay due to the inherent structure of the agentic workflow in the form of Trees or Graphs.
There have been a lot of papers like this namely Chain of Thought, Tree of Thoughts, Algorithm of Thoughts
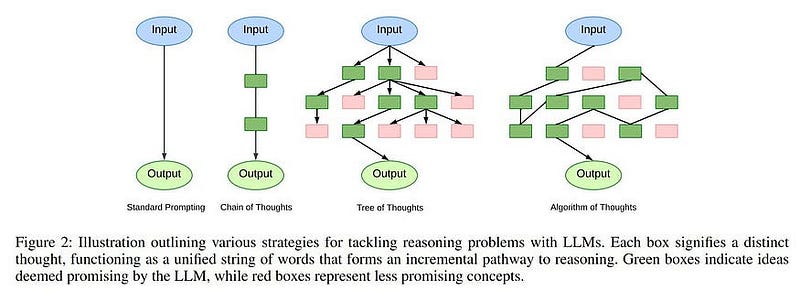
The latest in these advanced-level prompting strategies is the Algorithm of Thoughts: The idea behind this new paper is the same as the Tree of Thoughts paper but with the primary difference in how the context is saved. In Tree of Thoughts, we use Tree-based Data structure but here we use graph-based structure, thus giving us a much better way to navigate all the knowledge graph than using simple BFS or DFS.
Another advantage is that the Algorithm of Thoughts it uses far fewer prompts to LLM to achieve similar results. The whole idea behind these prompting strategies is to get the most context with the least amount of calls to the LLM.
Read a great blog on all these different strategies: Giving Self-reflection Capabilities to LLMs and PromptBreeder.
Another problem with AI agents is that LLMs are non-deterministic. While beneficial for idea generation, this poses a serious challenge in scenarios requiring predictability. For instance, if we’re writing an LLM-backed chat application to make Postgres queries (Text2SQL), we want high predictability.
Self-Reflection
The planning modules above don’t involve any feedback which makes it quite hard to achieve long-horizon planning, especially necessary to solve complex tasks. To address this challenge, we can create a process to iteratively reflect and refine the execution plan based on past actions and observations. The goal is to correct and improve on past mistakes which helps to improve the quality of final results. This is particularly important in complex real-world environments and tasks where trial and error are key to completing tasks.
ReAct combines reasoning and acting aimed at enabling an LLM to solve complex tasks by interleaving between a series of steps (repeated N times): Thought, Action, and Observation. ReAct prompts LLMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while also enabling interaction to external environments (e.g., Wikipedia) to incorporate additional information into the reasoning.
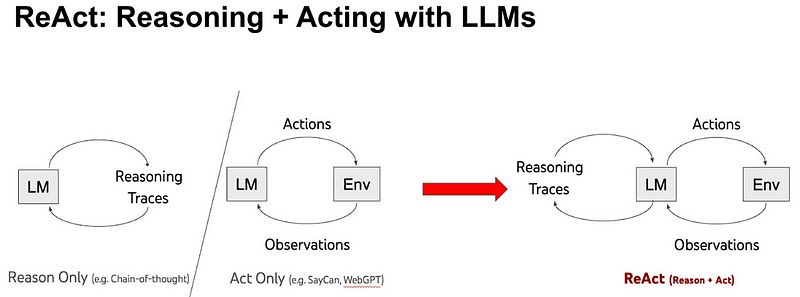
The figure below shows an example of ReAct and the different steps involved in performing question answering.

This is a framework to equip agents with dynamic memory and self-reflection capabilities to improve reasoning skills. Reflexion has a standard RL setup, in which the reward model provides a simple binary reward and the action space follows the setup in ReAct where the task-specific action space is augmented with language to enable complex reasoning steps. After each action 𝑎𝑡, the agent computes a heuristic ℎ𝑡 and optionally may decide to reset the environment to start a new trial depending on the self-reflection results.
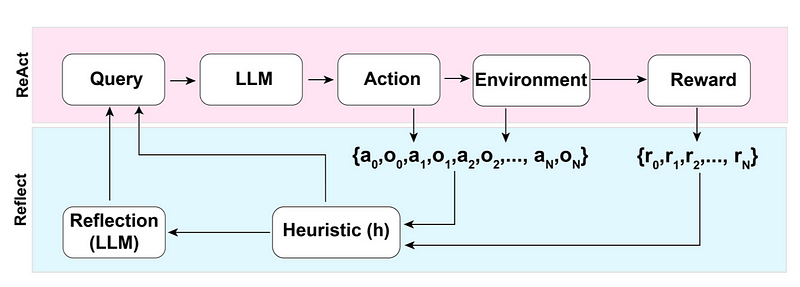
The heuristic function determines when the trajectory is inefficient or contains hallucination and should be stopped. Inefficient planning refers to trajectories that take too long without success. Hallucination is defined as encountering a sequence of consecutive identical actions that lead to the same observation in the environment.
There are two more interesting papers on creating better self-reflection capabilities Chain of Hindsight (CoH; Liu et al. 2023) and Algorithm Distillation (AD; Laskin et al. 2023).
In CoH, the model is asked to improve itself by looking at its own past work, rated, and with notes on how to do better next time. The model practices by trying to produce a new output that would get a better rating, using the history of its own attempts and feedback. To keep the model from just memorizing the answers, some parts of the history are hidden during training.
AD applies a similar idea to robots or agents learning tasks (like RL agents in video games). The agent looks back at how it performed over several past attempts and tries to figure out a pattern of improvement. It then predicts the next move that should be better than the previous ones, learning the strategy of getting better rather than just solutions to specific problems.
AD focuses on the idea of learning from the history of the agent’s own interactions with the environment. By looking at sequences of past actions and their outcomes, the agent tries to distill the successful strategies into its policy.
On the other hand, Reflexion gives agents the ability to remember past actions and reflect on their effectiveness, particularly focusing on detecting and avoiding repetitive or unproductive strategies (like hallucinations).
Types of Agents
Routing Agents
The simplest form of agentic reasoning. Given the user query and set of choices, output a subset of choices to route the query to.
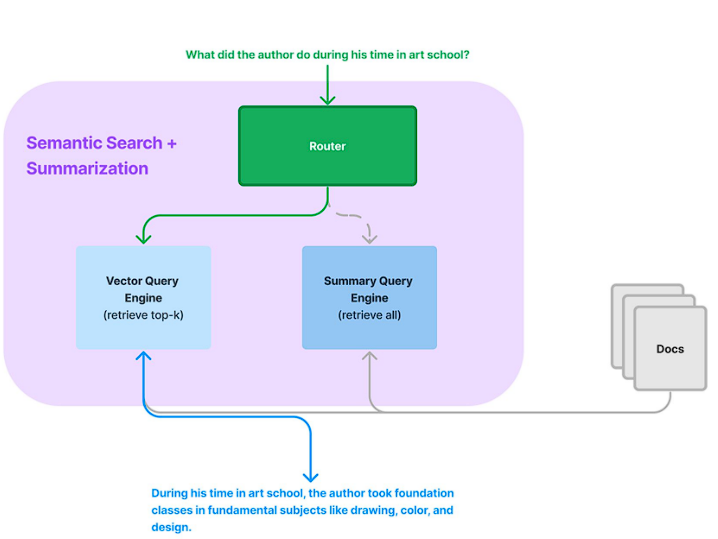
In the above query, “What did the author do during his time in art school?” is passed to a Router. The Router’s job is to determine the best path for the query through the system to retrieve the most relevant information.
There are two possible paths the Router can choose:
Vector Query Engine: This engine retrieves the top-k relevant documents from a larger collection based on the semantic similarity between the query vector and the document vectors. This uses vector space models to understand and retrieve documents that are semantically closest to the query.
Summary Query Engine: This engine retrieves all documents and provides a summarization of their contents. It allows the system to understand a topic broadly without going through each document individually.
Based on the decision made by the Router, either a specific subset of documents (from the Vector Query Engine) or a summarization of all relevant documents (from the Summary Query Engine) is returned to answer the user’s query. This fundamentally changes what type of Output is returned by the LLM finally. Some queries might need a detailed answer and some might be fine with a broader answer. These router agents help us to modify the behavior of LLMs.
Query Planning Agents
The idea behind Query Planning Agents is to first break down the complex query into sub-questions for each relevant data source, then gather all the intermediate responses and synthesize a final response.
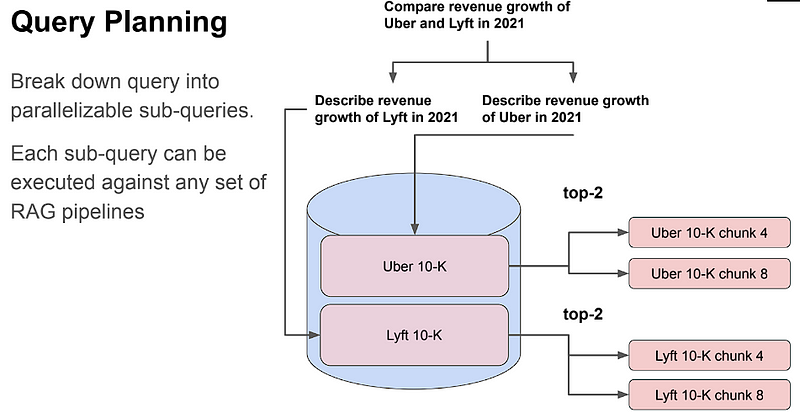
Look at how Query planning agents get better responses through sub-querying. Check out Llama Index for Sub-Querying.
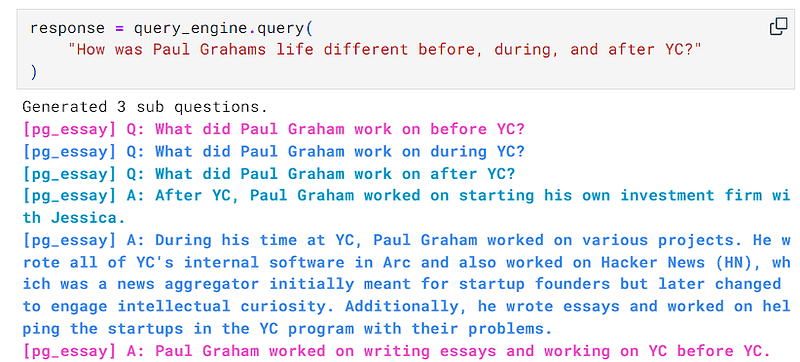
Tool Using Agents
These are types of Agents that can use a tool or API, infer the parameter required to run that tool, and return its results to the LLM context, for a more accurate answer.
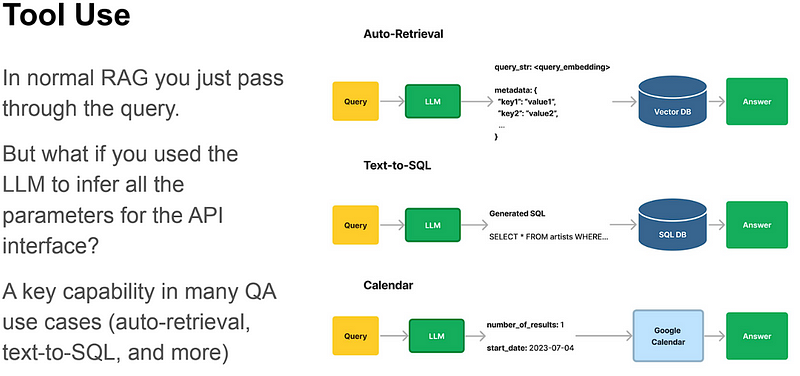
All of this is cool, but how can an agent tackle sequential multi-part problems? How can an agent maintain a state over time?
This is where more advanced agents like HuggingGPT (explained above) and ChemCrow come into the picture. In these multi-agent setting the system can use multiple tools and often have a dynamic memory integrated as well. These systems often use methods like ReAct and Reflexion to have a nuanced self-consistent approach within the agent’s environment and action.
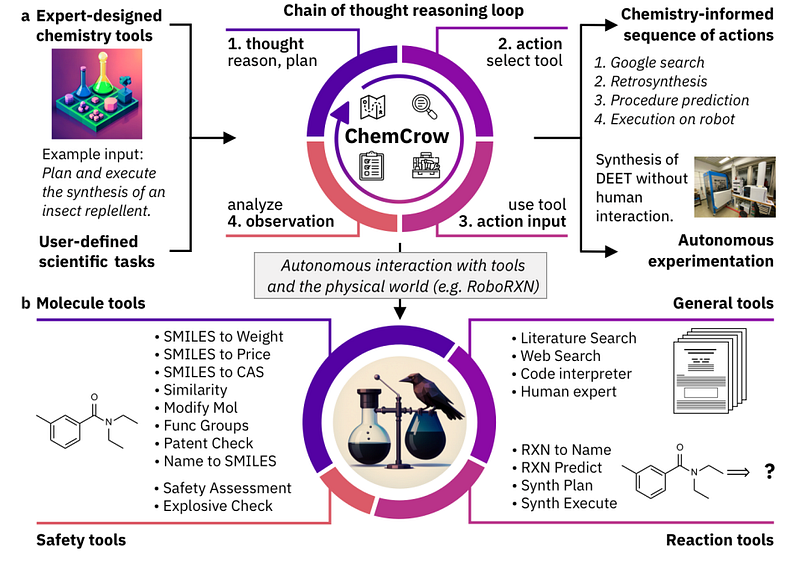
Below are notable examples of tools and frameworks that are used to build LLM agents:
- LangChain(opens in a new tab): a framework for developing applications and agents powered by language models.
- AutoGPT(opens in a new tab): provides tools to build AI agents.
- AutoGen(opens in a new tab): a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks.
- LlamaIndex(opens in a new tab) — a framework for connecting custom data sources to large language models.
- GPT Engineer(opens in a new tab): automate code generation to complete development tasks.
- DemoGPT(opens in a new tab): autonomous AI agent to create interactive Streamlit apps.
and many more.
At last, we should understand that frameworks are valuable whether or not RAG/AI agents live or die. Certain concepts from these recent developments will go away, but others will remain and evolve. This is by no means the end of this pretty big topic, many more to come, stay tuned.
Conclusion
LLM agents are still in their infancy, and many challenges and limitations remain when building them, like LLM-based agents needing to adapt a role to effectively complete tasks in a domain, being able to do long-term planning, generalized human alignment, reliability, knowledge limitation, and many more.
In the future, we might look into even more advanced concepts like KV Caching and LLM compiler & OS.
Please check out Solving Production Issues In Modern RAG Systems-I & Part-II, Agentic workflows, and RAG 2.0.
Writing such articles requires considerable effort and time. I would highly appreciate your support through claps and shares. Your engagement motivates me to write more beyond the hype, on SOTA AI topics with utmost clarity and simplicity. Don’t miss out on future insights — make sure to follow me on 𝕏 as well. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter
References
[1] https://readmedium.com/solving-production-issues-in-modern-rag-systems-b7c31802167c
[2] https://readmedium.com/solving-production-issues-in-modern-rag-systems-ii-43c5fb557d27
[3] https://readmedium.com/next-for-llms-and-rag-ai-agentic-workflows-1869ba0a6796
[4] https://readmedium.com/rag-2-0-retrieval-augmented-language-models-3762f3047256
[5] https://www.youtube.com/watch?v=mE7IDf2SmJg&list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM&index=26
[6] https://drive.google.com/file/d/1Ckw4kWj-DS27aCAFdmxg8gQFtr2adQAH/view
[7] https://www.promptingguide.ai/research/llm-agents
[8] https://arxiv.org/pdf/2303.17580.pdf
[9] https://arxiv.org/pdf/2308.10379.pdf





