
RAG 2.0: Retrieval Augmented Language Models
Language models have led to amazing progress, but they also have important shortcomings. One solution for many of these shortcomings is retrieval augmentation. There have been plenty of articles written about Retrieval Augmented Generation (RAG) pipelines, which as a technology is quite cool. But today, we are taking it one step further and truly exploring what’s next for the technology of RAG. What if we can create models with trainable retrievers, or in short, the entire RAG pipeline is customizable like fine-tuning an LLM? The problem with current RAGs is that they are not fully in tune within it’s submodules, it’s like a Frankenstein monster, it somehow works, but the parts are not in harmony and perform quite suboptimally together. So, to tackle all the issues with Frankenstein RAG, let’s take a deep dive into RAG 2.0.
Table of Contents
- What Are RAGs?
- What RAG 2.0 Achieves?
- How Does RAG Solve Issues of Intelligence?
- Better Retrieval Strategies
- SOTA Retrieval Algorithms
- Contextualizing the Retriever for the Generator
- Combined Contextualized Retriever and Generator
- SOTA Contextualizaton
- Conclusion
Please take a moment to share the article and follow me, only if you see the hard work. It takes weeks to write such articles, some love would be highly appreciated.

What Are RAGs?
Simply put, RAG is the technique to put additional context for our LLMs to generate better and more specific responses. LLMs are trained on the publicly available data, they are really intelligent systems independently, yet they can’t answer specific questions, because they lack the context to answer those queries. With RAG, we provide the necessary context for them to answer our queries correctly.
RAG is a way to insert new knowledge or capabilities into our LLMs, though this knowledge insertion is not permanent. Another method to add new knowledge or capabilities to LLMs is through Fine Tuning LLMs to our specific data.
Adding new knowledge through fine-tuning is quite tricky, tough, expensive, and permanent. Adding new capabilities through fine-tuning even impacts the previous knowledge it had. During fine-tuning, we can’t control which weights will be changed and thus which capability will increase or decrease.
Now, whether we go for fine-tuning, RAG or a combination of both depends totally upon the task at hand. There is no one fit for all.
- Split up documents) into even chunks.
- Each chunk is a piece of raw text.
- Generate embedding for each chunk (e.g. OpenAl embeddings, sentence_transformer) using an encoder and store it in a database.
- Find the Top-K most similar encoded chunks, get the raw text of those chunks, and feed it as context alongside the prompt to the generator.
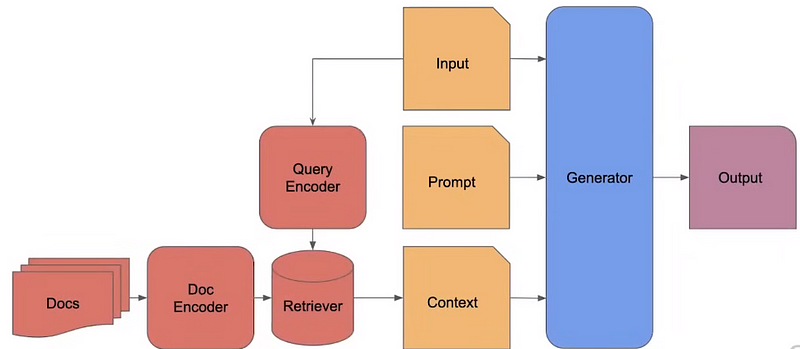
Please take a look at our RAG Pipeline other blogs:
What RAG 2.0 Achieves?
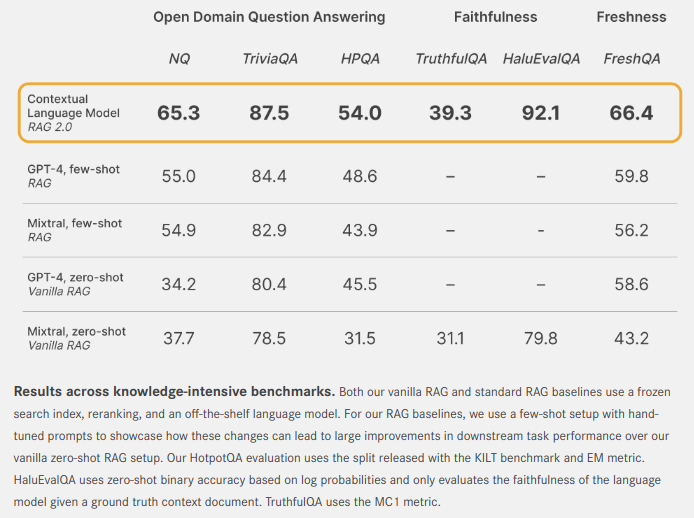
Comparing Contextual Language Models (CLMs) with frozen RAG systems across a variety of axes as explained by Contextual.AI:
Open domain question answering: We use the canonical Natural Questions (NQ) and TriviaQA datasets to test each model’s ability to correctly retrieve relevant knowledge and accurately generate an answer. We also evaluate models on the HotpotQA (HPQA) dataset in the single-step retrieval setting. All datasets use the exact match (EM) metric.
Faithfulness: HaluEvalQA and TruthfulQA are used to measure each model’s ability to remain grounded in retrieved evidence and hallucinations.
Freshness: We measure the ability of each RAG system to generalize to fast-changing world knowledge using a web search index and show accuracy on the recent FreshQA benchmark.
Each of these axes is important for building production-grade RAG systems. We show that CLMs significantly improve performance over a variety of strong frozen RAG systems built using GPT-4 or state-of-the-art open-source models like Mixtral.
How Does RAG Solve Issues of Intelligence?
We’ve already defined in the above section what RAG does, but let’s take a more nuanced look at it.
RAG is a semi-parametric type of system, where the parametric part is the Large Language Model and the rest is the non-parametric part. Combining all the different parts gives us the Semi-parametric system. LLMs have all the information stored in their weights or parameters (in an encoded form) whereas the rest of the system has no parameters defining that knowledge.
But why does this solve the issue?
- Swapping in and out indices (specific information in LLMs) gives us customization, which means that we don’t suffer staleness and also we can revise what is in the index.
- Grounding LLMs with these indices means we have less hallucination, and we can do citations and attribution by pointing back to the source.
So in principle, RAG gives us the ability to create better contextualization for our LLMs to perform well.
But is it actually that simple? NO
We’ve many issues that need to be answered to create a modern scalable RAG pipeline.
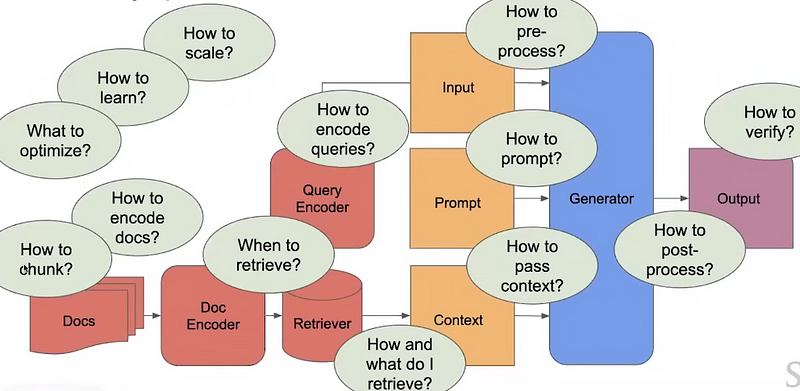
However current RAG systems are not that intelligent, and they are quite simple and unable to solve complex tasks that require a lot of custom context. We are talking here about the Frozen RAG.
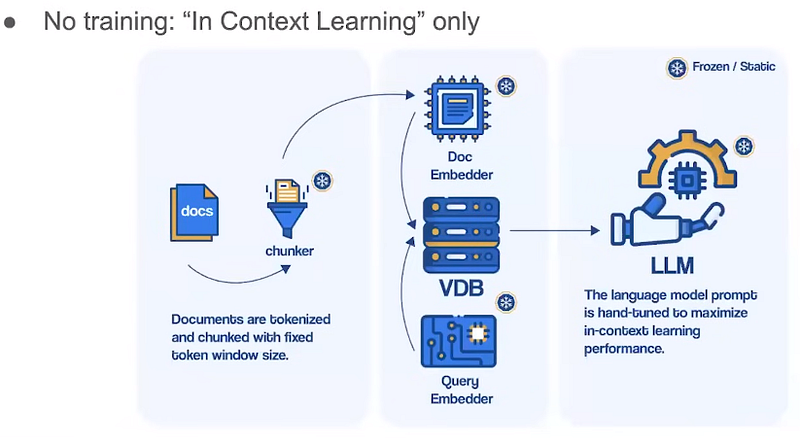
So, the frozen RAG has LLM as the only parametric part. Let’s look into more advanced architectures.
Better Retrieval Strategies
Spare Retrieval
TF-IDF: According to Wiki: TF–IDF or the term frequency-inverse document frequency, is a measure of the importance of a word to a document in a collection or corpus, adjusted for the fact that some words appear more frequently in general.[1] It was often used as a weighting factor in searches of information retrieval, text mining, and user modeling.

BM25 (Best Match 25): It can be seen as an improvement on TF-IDF.
The BM25 for the query “Machine Learning” would be the summation of BM25Score(Machine)+BM25Score(Learning)
The first part of the formula is the IDF of the term.
The second part in the formula represents the TF of the word which is normalized by the length
f(q(I), D) is the Term frequency of the word q(i) in document D
K and b are the parameters that can be tuned. |D| represents the length of the document and avgdl represents the average length of all the documents in the database.
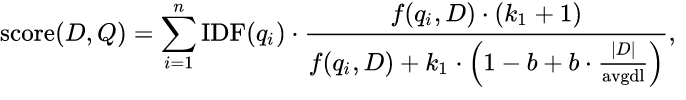
So these are some of the early steps in Sparse retrieval.
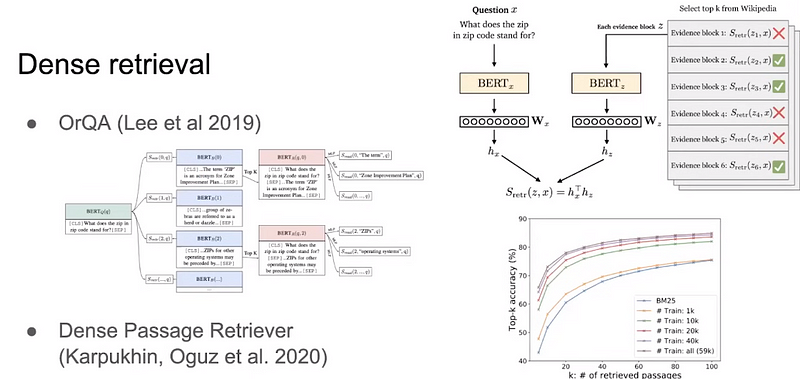
Dense Retrieval
The reason why we need dense retrieval is because language is not that straightforward. For instance, if we have synonyms the sparse retrieval fails completely. We don’t just want to retrieve something on exact keyword match but more on the semantics of the sentence. BERT sentence embedding is an example of Dense retrieval. Basically, we use dot product or cosine similarity once the sentences are converted into a vector and that’s how we retrieve the information.
The nice thing about dense retrieval is that it is easy to parallelize, with the help of GPUs it can easily run on billion-scale similarity search and that’s how the FAISS was developed by Meta.
Read this paper that talks about the problems with cosine similarity:
But how do we go beyond the simple dot product?
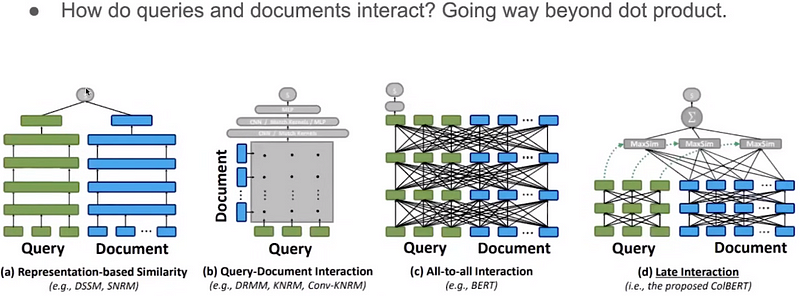
There are multiple ways in which a document and a query can interact, much like a Siamese network or any other different combination. This is called ColBERT.
SOTA Retrieval Algorithms
The ColBERT is a very nice retrieval strategy, but that’s not the end of the information retrieval. We have other more advanced algorithms and strategies like SPLADE, DRAGON, and Hybrid search.
SPLADE: Sparse meets dense with query expansion.


We can see that with query expansion more context is covered and this potentially helps in better retrieval.
DRAGON: Generalize dense retriever via progressive data augmentation.
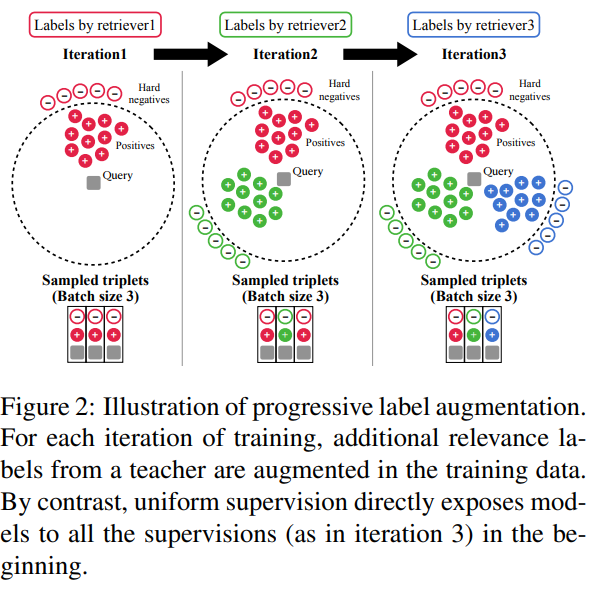
Let’s understand DRAGON working with an example
- Initial Inquiry: “How do I care for a spider plant?”
- DRAGON's Action: Recognizing the plant-care theme, DRAGON crafts a targeted retrieval query to gather general care information specifically about spider plants.
- Initial Retrieval: DRAGON delves into its database, retrieving documents that throw light on sunlight requirements, watering schedules, and suitable fertilizers for these leafy companions. DRAGON generates a response, “Spider plants need moderate, indirect sunlight and should be watered once a week. They benefit from monthly fertilization during the growing season.”
- User Update: The conversation takes a turn as the user inquires, “What happens if the leaves turn brown?”
- DRAGON Adapts: DRAGON refines the retrieval query to home on the issue of brown leaves in spider plants.
- Dynamic Retrieval in Action: DRAGON retrieves information about the common culprits behind browning leaves, such as overwatering or excessive direct sunlight.
- Knowledge Delivered: By leveraging the newly retrieved data, DRAGON tailors its response to the evolving dialogue: “Brown leaves on a spider plant could be a sign of overwatering or too much direct sunlight. Try reducing water frequency and moving the plant to a shadier spot.”
DRAGON dynamically adjusts its retrieval queries based on the user’s evolving interests within the conversation. Each input from the user prompts a real-time update in the retrieval process, ensuring that the information provided is both relevant and detailed according to the latest context.
Hybrid Search: Here we interpolate between Dense and Sparse search. This is where the RAG community is, where we take something like BM25 and combine it with SPLADE or DRAGON.
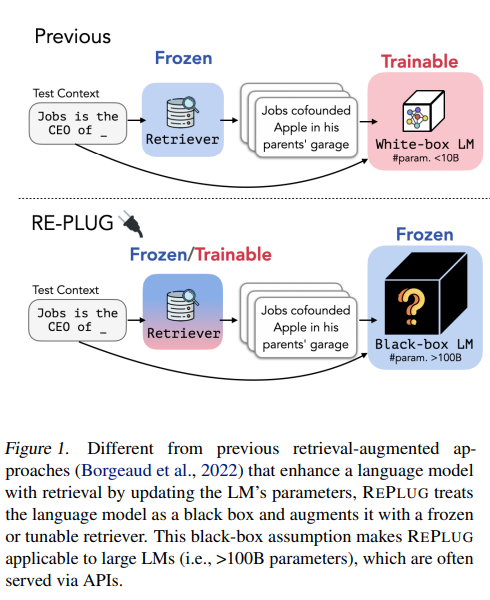
But our retrievers are still FROZEN.
Contextualizing the Retriever for the Generator
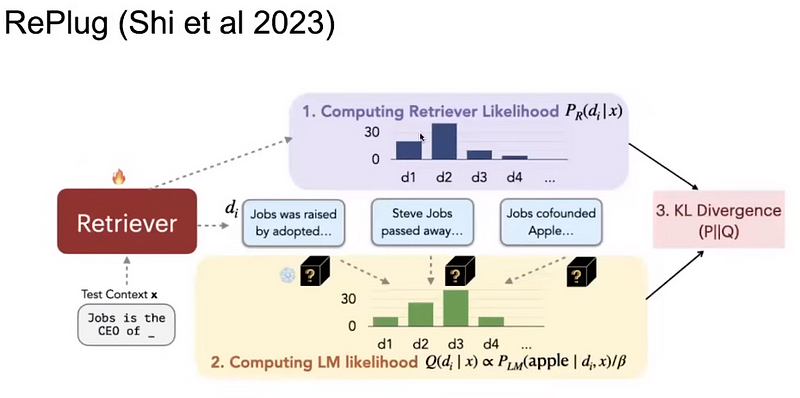
RePlug
This is one of the very interesting papers in retrieval called RePlug. For a given query we retrieve top-K documents, and after doing a normalization (calculating their likelihood), we get a distribution, and we feed each document separately to a generator along with the query. Now we look at the perplexity of the correct answer for the language model. Now we have two likelihood distributions, on which we calculate the KL Divergence loss, such that KL divergence is minimized leading to the retrieved document with the lowest perplexity on the right answer.
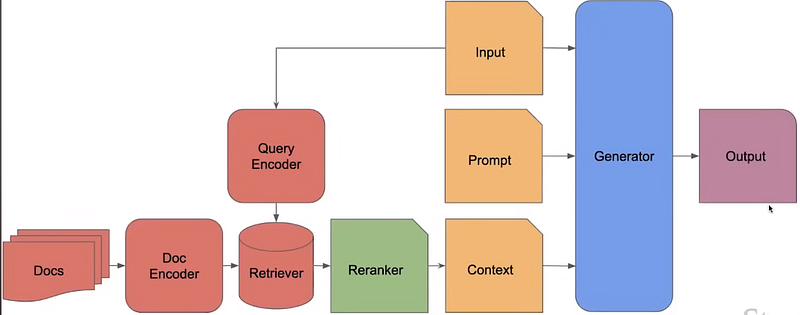
In-Context RALM
It uses Frozen RAG and BM25 and then specializes only the retrieval part via reranking.
- Zero-shot with an LM
- Trained Reranker

In this setting, the Language model is fixed and we only backpropagate to or train the reranker part. This is not very advanced and yet performs decently well compared to a simple frozen RAG.
But the question is how do we backpropagate or update the Retriever’s parameters if we don’t have access to the LLM parameters?
So what we do is use reinforce style loss on the retrieval to train the retrievers. The retriever’s effectiveness is judged by how well the information it fetches enhances the language model’s output. Therefore, improvements to the retriever are focused on maximizing this enhancement. This can involve adjusting the retrieval strategy (what and how information is fetched) based on performance metrics derived from the language model’s outputs. Common metrics might include coherence, relevance, and the factual accuracy of the generated text.
Combined Contextualized Retriever and Generator
So the idea here is that instead of optimizing the LLM or Retriever separately, what if we could optimize the entire pipeline in one go?

There are a lot of things to optimize for when we retrieve the documents, at every nth token or in one go. In the RAG-token model, we can retrieve different documents at different target tokens compared to the single-time retrieval of the RAG-Sequence model.
Other problems include not being able to load enough context or documents.
Fusion In Decoder: One solution is to use the encoder to encode all the k documents, followed by a concert, and then decode before giving it as context to the input prompt.

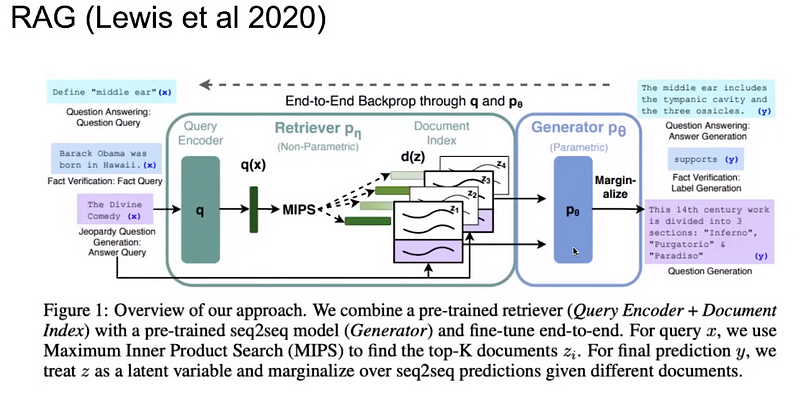
Other interesting ideas in advanced RAG systems include k-NN LM:
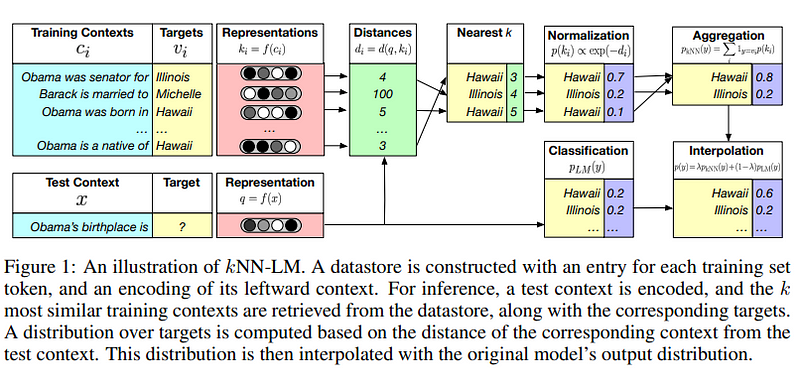

In another paper, researchers showed that they could create 25x smaller models if they train them in a RAG setting
SOTA Contextualization
Contextualizing the LLM part is quite tricky and expensive.
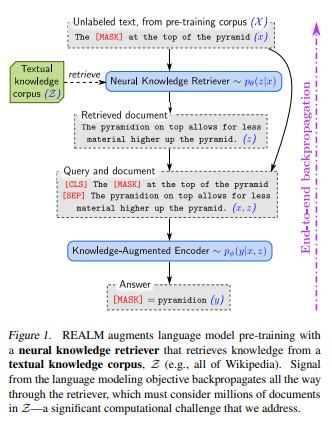
To reupdate the entire LLM is not quite easy, it is billions and probably trillions of tokens that need to be updated. If you want an early paper on it read the REALM paper where they use a BERT model to show training of end-to-end pipeline, although it is not fully generative AI.
Another interesting paper on the same topic is from the Meta FAIR research group called ATLAS
So, the paper discusses first different types of loss functions that can be used to train certain sections of the entire RAG pipeline and then compares their performance.

The EMDR has already been discussed in the above-mentioned In-Context RALM, the likelihood is mentioned in the RePlug part and the leave one out is the inverse of Likelihood distillation.
To keep it simple we are not going to look at FiD style attention distillation.
So, here’s the performance comparison of all the different losses from the ATLAS paper:
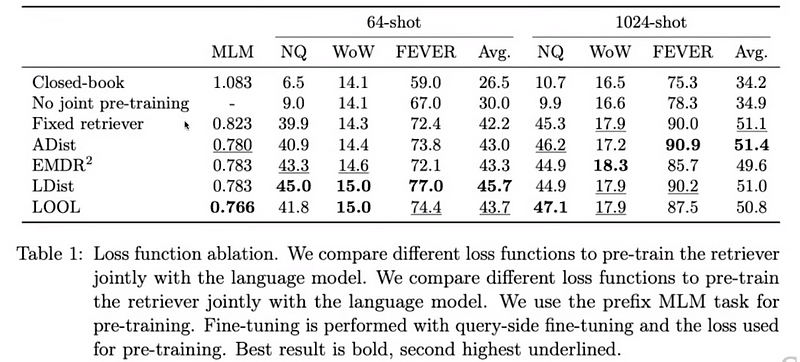
ATLAS is a carefully designed and pre-trained retrieval augmented language model able to learn knowledge-intensive tasks with very few training examples. ATLAS integrates these loss functions into a cohesive training pipeline that allows the retriever to be fine-tuned directly based on its impact on the language model’s performance, rather than relying on external annotations or pre-defined relevance scores. This integration enables the system to improve over time by adapting to the specific demands of the tasks it is trained on.
- ATLAS uses a dual-encoder framework for its retrieval system, where one encoder is dedicated to encoding the query and the other for the documents.
- The retrieved documents are then fed, along with the query, into a powerful sequence-to-sequence language model based on the T5 architecture, acting as the decoder in the system, generating the final textual output
- ATLAS uses a Fusion-in-Decoder approach, which integrates the information from the retrieved documents directly within the decoder of the sequence-to-sequence model. This method allows the language model to dynamically utilize the retrieved information throughout the generation process, enhancing the relevance and accuracy of its outputs.
Explaining full ATLAS architecture in detail is beyond the scope of this article.
Summary
There are three types of RAGs:
- Frozen RAG: We see these all over the industry, they are just POCs.
- SemiFrozen RAG: Here we implement smart Retrievers and try to make them adaptive somehow. We don’t touch the LLM here, only play with retrievers and combine them with the final output.
- Fully trainable RAG: Quite hard to train end-to-end but if done correctly, offers the best performance. Very resource-intensive.
Conclusion
There are a lot of unexplored areas that still need quite a lot of research. But we can surely say that RAG currently is in its infancy stage especially when we talk about what people have been implementing in the industry.
Joint from-scratch pretraining of retrieval-augmented generation (RAG) models, whether to scale the language model in terms of parameters or tokens and how to effectively scale the retriever, be it through parameters or data chunks, decoupling memorization from generalization and separating knowledge retrieval from the generation process, etc. are all the other questions that still need answers.
References:
[1] https://contextual.ai/introducing-rag2/
[2] https://arxiv.org/abs/2208.03299
[3] https://arxiv.org/pdf/2002.08909.pdf
Please check out Solving Production Issues In Modern RAG Systems-I & II and Agentic workflows
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter





