
What’s next for AI: AI agentic workflows?
I’m sure that most of you would have recently heard about Devin AI, it gathered a lot of attention as the world’s first AI Software developer. Now we have another one from India called Devika. So, is this the future of AI development, AI Agents? Let’s try to go a layer deeper into what are AI agents, how they are evolving, and how they are going to change the workflow of AI development. And the most important of all, is this going to be the next steps towards AGI or AGI itself? So, without further ado, let’s jump right into AI agents and AI agentic workflows.
In general, an AI agent is a system that perceives its environment through sensors and acts upon that environment using actuators based on its perception, internal states, and experiences to achieve specific goals. But in this article, we are specifically talking about LLM-based AI agents. They operate autonomously on the web or an OS (Operating System), can learn from their interactions, and make decisions to pursue their objectives, often optimizing for certain criteria.
Table of Contents
- History of AI Agents
- Improving the Prompts
- Giving Self-Reflection Capabilities to LLMs
- Using Tools to Operate Autonomously
- Understanding AI Agents
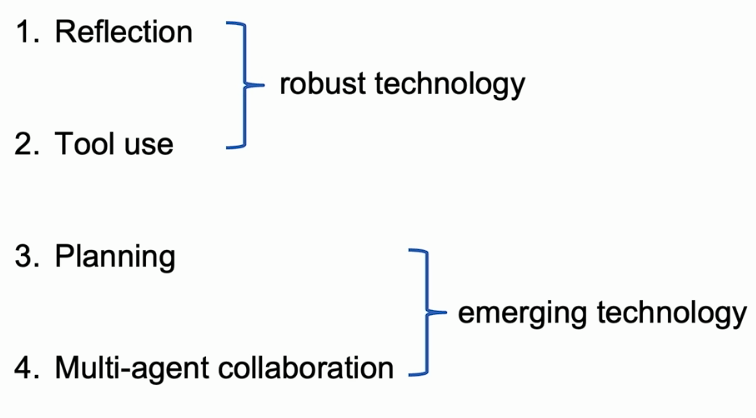
- Agentic Workflows
- Conclusion

History of AI Agents
Back in 2016, RL agents were hype, people were trying to create different types of RL agents to play games like Atari, and other similar games. There was no concept of AI agents back then. However, a few researchers from OpenAI, including Jim Fan, Karpathy, and Tim Shee wanted to use these RL agents to get a few things done that current AI agents are doing. The project was called World of Bits, and the idea was that they would create an agent that could go on a webpage and handle small requests like ordering a pizza and stuff. They wanted to navigate the operating systems through an agent. But they were way ahead of the game, the technology hadn’t been invented and they couldn't get it to work properly.
What was missing exactly? LLMs.
They were still 5 years away from creating the basics of a much more generalized intelligent behavior. What LLM became good at was understanding the language, so good, that they were able to modify their output and behavior based on the instruction. LLMs became the right recipe, that could be instructed in a human language, and eventually tasked with creating workflows. Creating an Agentic workflow was the most logical next step.
A bit of warning about building AI agents.
It is not as simple as people might be thinking and hyping right now. It is like the autonomous car, easy to think of, easy to create a proof of concept, but really hard to make it actually usable. We still don’t have fully autonomous cars after decade's worth of research and billions of dollars. Another such technology is VR, we have had the idea and the POCs of VR since the late 2000s, and yet, it is still not scalable.
So, the same might be true with AI agents.
Improving the Prompts
The first step to creating a good agent is to give it good prompts. But are humans really good at creating good prompts? For a given subject an expert might be able to create an optimized prompt, but what about others? So, there is a strategy called PROMPTBREEDER. It is a self-improving system that evolves prompts for specific domains.
- Using LLMs, it adjusts and assesses task prompts based on training data over multiple iterations.
- PROMPTBREEDER also refines the rules (mutation-prompts) guiding task-prompt adjustments. This results in a dual layer of self-improvement: refining prompts and refining methods (self-referential).
- PROMPTBREEDER outperforms leading strategies in arithmetic and reasoning tests.
- It can also create detailed prompts for complex challenges like hate speech classification.
Read the full article here on how to create better prompts using genetic algorithm concepts:
Giving Self-Reflection Capabilities to LLMs
In order to give self-reflection capabilities to LLMs, we need to first understand the problems with current LLMs.
- They give a very generalized response, often lacking nuance. At times, it repeats itself.
- There is a lot of verbiage and unnecessary words that don’t say anything.
- They often try to tell things politically correctly and can’t make good arguments from a given worldview.
- It hallucinates and often gets things wrong with complex problems that might require the answer to be spoken in more than 8k or 16k tokens.
- Runs out of memory to store the relevant context for the given problem.
Hallucination is one of the biggest problems of LLMs. But what exactly are these hallucinations?
Instead of me explaining and talking about LLM hallucinations. Look at what the man himself has to say about it.

The probable solution to hallucinations is to let the system think more before it responds. And that’s where we have several strategies like Chain of Thought, Tree of thought and Algorithm of Thought.
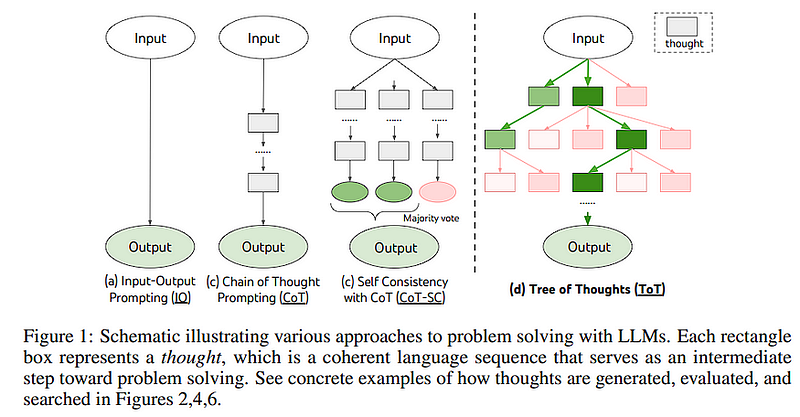
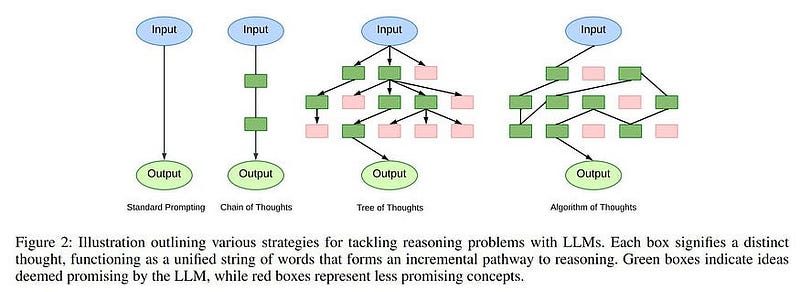
The idea behind the self-reflection is to let the system explore diverse paths before answering any question. The given system should have some capability to backtrack on its path and re-evaluate its own response. Tree/Algorithm of Thoughts uses a Tree-based or graph-based Data structure to navigate all the knowledge graphs.
To know more about self-reflection, Chain of Thought, Tree of Thought and Algorithm of Thought:
But I’m personally a bit cautious about these prompting strategies. We often think that LLM comes up with better planning when prompted through these advanced prompting strategies. But it has been shown by a few researchers, that we inadvertently feed the answer or hint to the the answer in these prompting strategies.
Read this awesome article to understand why LLMs can’t reason and plan?:
Using Tools to Operate Autonomously
An AI agent would definitely need the capability to use different types of tools, without this ability, we can’t have AI agents that can operate our computers and achieve certain tasks.
But why do we need tools, why can’t we give all the knowledge directly to the LLM itself?
LLMs are really bad at doing mathematical calculations. Earlier they couldn’t even access the internet, now they can. But why they are bad at even basic calculation? Baking precise information in LLMs is quite tough, that’s why it’s better that instead of LLM calculating a mathematical answer on its own, it uses a calculator or a similar tool.
But the question is how does an LLM know when to use a tool?
The newer version of LLMs can not only produce text, but they can also use different tools. For instance, LLMs have been given the capability to search the internet and use that information to give more up-to-date and better answers.
And this is how it works:

If you want a complete overview of LLMs:
Understanding AI Agents
Currently, AI agents are used in the context of LLMs. They are being looked at as the future of RAG pipelines or the next step towards AGI. The below diagram summarises what AI agents are:
An “agent” is an automated reasoning and decision engine. It takes in a user input/query and can make internal decisions for executing that query in order to return the correct result. The key agent components can include, but are not limited to:
- Breaking down a complex question into smaller ones
- Choosing an external Tool to use + coming up with parameters for calling the Tool
- Planning out a set of tasks
- Storing previously completed tasks in a memory module
We have different types of agents that can do from simple to very complex tasks like Dynamic planning. Or let me correct myself as RaoK puts it, can help in generating plans, that can be later on checked with automated planners for feasibility.
Agentic Workflows
Let’s look at how can we make LLM think a little more. But the real question is whether breaking down the problems into simpler problems makes LLMs smart. And the answers are YES and NO.
Keep in mind, that we are still using the same LLM, then why should the performance increase? The answer to this lies in context.
When we break down the problem into simpler problems, LLM will answer all of them and thus add more context while solving the overall problem.
But inadvertently we ourselves tell the LLM, how to break down the problem, thus it is we who do the planning. LLM can’t understand which plan is better and which is not. But in the coming months, we can train or instruct the LLM in such a way that it first breaks the problem into subproblems. And then use that to add more context and then solve the problem. But here lies the problem, it itself doesn’t know whether the sub-problems it came up with are correct or not. As of now, humans have to decide which subproblems to use to solve the main task.
Now, I know that this doesn't make much sense, but please check out https://twitter.com/rao2z he will explain in great detail why LLMs appear to plan but can’t actually plan. In the best case, they can just come up with average plans for similar problems.

I myself have seen that this revised behavior keeps breaking so many times when prompted about certain topics.
Check out this awesome lecture on LLM's limitations:
Please don’t get me wrong AI agents can really help us in planning, but they can’t themselves create self-consistent plans.
I’m not the only one who thinks similarly, even Lecun aligns with the same thought that LLMs can’t self-reflect.
Anyways let’s look at what the other side has to say about LLMs' planning and reasoning capabilities and more importantly about AI agents.
Reflection
The idea of reflection is to have two LLMs where one acts as a critic, and the other is a Coder LLM. Now this has been shown to improve the coding performance by a lot at least on the HumanEval coding benchmark.
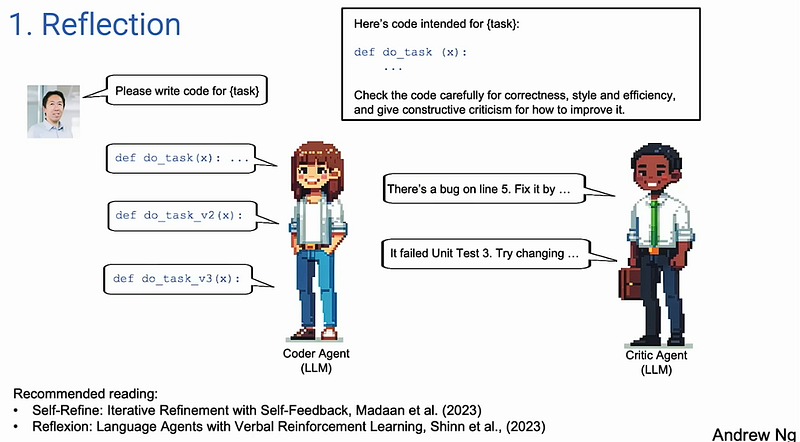
Implementing this workflow is quite easy, this is exactly what we do when we use the GPT app, we keep asking it again and again till it gets the correct answer. Now while using the app, we decide whether the given iteration answer is correct or not. But for Coder AI agents, we probably will have the answer stored somewhere so that the script provided by GPT is run on some VS code or something, produces an output, and then matches that output with the correct answer.
Tool Use
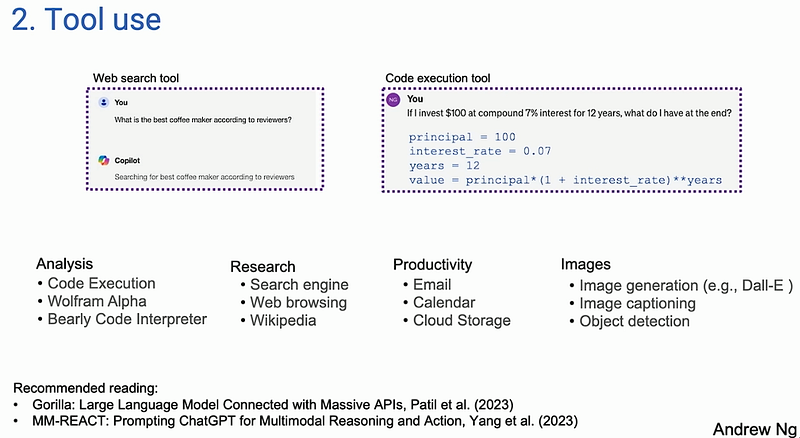
Tool use helps in reducing the wrong answers. Already explained about tools in the above sections.
Planning
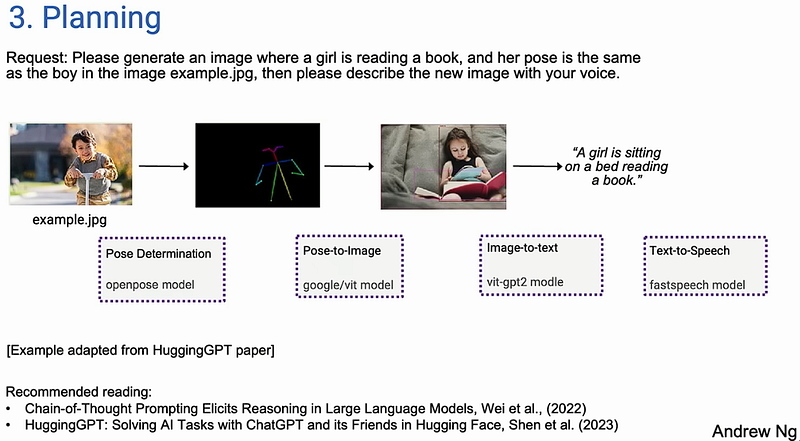
The planning is still very far from being usable, it's a hit-and-miss because it doesn’t know when to stop. It needs to rely on the external planner, to tell whether the generated plan is correct or not.
Multi-Agent Collaboration

This is what Devin does, where it can take different roles in a software engineering domain. Different agents can take up roles of a tester, a developer, etc.
Here multiple agents are using different tools and behaving differently, you can think of different LLMs instructed on different behavior.
Agentic Workflow is going to be huge in the next few months and years, but that doesn’t mean the LLMs in themselves have become more intelligent. It’s like automation being introduced for the first time, but for LLMs. Automation in itself is not smart, it makes the LLMs appear smarter.
This was an introduction to AI agents and Agentic workflow. Next, we will try to look into the more technical understanding of these agents and talk about ReAct: Reasoning + Acting with LLMs, More Agent Is All You Need paper, LLM compiler, and actual workflow implementation from the Llama Index.
Conclusion
1. Definition and Capabilities of AI Agents: There’s no consensus on what exactly constitutes an AI agent, with terms like “AI agents” and “autonomous agents” often used interchangeably. However, defining characteristics include the ability to reason and act using technologies like LLMs, maintain short and long-term memory, and utilize external tools via APIs for tasks such as web browsing and making payments.
2. Evolution from Standalone Products to Integrated Features: The trend is shifting from standalone AI agent products to incorporating them as invisible features within larger applications. This includes personal assistants and GitHub assistants, among others, indicating an increase in the complexity and integration of agent technologies.
3. Challenges in Reliability for Enterprise Use: Enterprises demand high reliability (~99.9%), a standard that AI agents currently struggle to meet due to issues like testing, debugging, latency, and monitoring. This is further complicated by concerns over privacy, security, and data retention.
4. Need for Specific SDKs and Frameworks: Developers use a mix of traditional software solutions and agent-specific tools to address challenges unique to AI agents. However, the field lacks standard tools and frameworks, making development cumbersome.
5. Community Efforts for Standardization: There’s a growing discussion on establishing standards for autonomous agents to aid in benchmarking, safety considerations, and performance evaluation. Efforts include the Agent Protocol, which aims to standardize interactions with agents.
6. Trend Towards Specialization and Vertical Markets: The initial broad exploration of AI agents is giving way to specialized applications aimed at perfecting specific functions, such as coding or personal task management. This specialization suggests a future where apps are powered by multiple specialized AI agents working in concert.
Please check out Solving Production Issues In Modern RAG Systems-I & II:
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter




