
Can LLMs really reason and plan?
I see so many articles talking about all the great things that can be achieved by LLMs, but often in this massive hype, we overrely and overuse LLMs, even in places where we don’t need them; places where much simpler systems would have been sufficient. LLMs are great, but still not perfect. In this blog, I’ll try to show how bad they actually might be in certain tasks and we might need something completely different to build the next generation of intelligence. We will also try to talk about different types of problems that have been created by this massive hype of LLMs, but more importantly, how we conceptualize these great machines. As of now, there is no consistency in viewpoints about LLMs behavior among the top scientists.
It is going to be a very interesting article, giving you not the answers but queues to build your own understanding of these models and moreover of intelligence and intelligent behavior.
Table of Contents
- Socio-economic problems with LLMs
- How top AI researchers think about LLMs
- A more comprehensive and inclusive viewpoint on LLMs
- LLMs are N-gram models on steroids
- Memory retrieval or generalization
- The broken academia
- LLMs keep fooling us about their reasoning capabilities
- LLMs are great, but why such a divide?
- Conclusion
Check out the other two parts of this series:
Socio-economic problems with LLMs
There is no doubt that the release of ChatGPT made AI a household thing, everyone suddenly started talking about AI. Everyone suddenly became an AI expert, and this created quite a big problem, for both people learning AI and people seeking AI experts. The below image perfectly summarizes the current market situation. People are confused about how to learn it properly, because there are so many gimmicks, tips, and tricks types of content out there, and for industry, it is becoming increasingly tough to find or filter out good AI candidates because everyone is a data scientist these days. Being able to use GPT APIs doesn’t make someone an AI expert.
Not only that, there is a very good chance that investors (in AI companies) might lose a lot of money because of all the hype, and this can create a vacuum in coming years for AI development. For instance, with OpenAI’s valuation of 100 billion, no one knows when will this money be made back, because Open Source LLMs are also getting pretty damn close to these proprietary ones.
There are other types of problems, like children depending upon these tools too much and not being able to learn things anymore, people cheating in exams, etc. There are far more great social consequences of technology like LLMs and a robust and healthy framework is required to integrate these massive changes brought by technology like LLMs.
Enough with the socio-economic impact of LLMs, it’s a technical blog, so let’s get back to that.
How top AI researchers think about LLMs
There are primarily three sets of viewpoints about LLMs, and how to think about them.
Position I (Skepticism): A few scientists like Chomsky view LLMs as highly advanced statistical tools that don’t equate to intelligence at all. The viewpoint is that these machines have seen so much data they can just give responses to any question we might come up with. Mathematically, they have calculated conditional probability for every possible question we can come up with.
My viewpoint: The flaw here might be an underestimation of the nuanced ways in which data modeling can mimic certain aspects of cognition, albeit not true understanding. How do we know even humans are not doing the same, we are constantly being fed data by our different senses. So, differentiating between understanding and mimicking an understanding might also need the development of some other type of intelligence.
Position II (Hopeful Insight): Ilya Sutskever (creator of ChatGPT) and Hinton seem to suggest that LLMs have developed internal models reflective of human experience. Their position is that, since the text on the internet is a representation of human thoughts and experience, and by being trained to predict the next token in this data, these models have somehow built an understanding of the human world and experience. They have become intelligent in a real sense or at least appear to be intelligent and have created world models as humans do.
My viewpoint: This might overstate LLMs’ depth, mistaking complex data processing for genuine comprehension and overlooking the absence of conscious experience or self-awareness in these models. Also, if they have built these internal world models, then why do they fail miserably on some fairly simple tasks that should have been consistent with these internal world models?
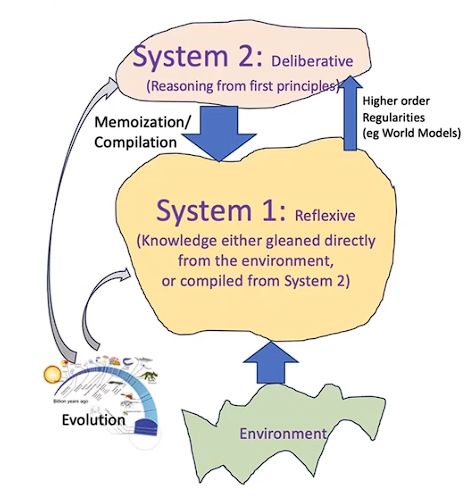
Position III (Pragmatism): A lot of scientists like LeCun and Kambhampati see LLMs as powerful aids but not as entities possessing human-like intelligence or even something that is remotely close to human intelligence in terms of experience or internal world models. LLMs, while impressive in their memory and retrieval abilities, fall short in genuine reasoning and understanding. They believe that LLMs should not be anthropomorphized or mistaken for having human-like intelligence. They excel as “cognitive orthotics,” aiding in tasks like writing, but lack the deeper reasoning processes akin to humans’ System 2 thinking.
Note: We believe that current LLMs are System 1 intelligence, that’s why every problem takes almost the same time to be solved, be it linear, quadratic, or exponential.
LLMs resemble human System 1 (reflexive behavior) but lack a System 2 (deliberative reasoning) component. They don’t have the capacity for deep, deliberative reasoning and problem-solving from first principles.
They believe that future advancements in AI will rely on fundamentally different principles, and the emergence of AGI can’t be just achieved by scaling.
My viewpoint: This view might underestimate the potential future evolution of LLMs, especially as we move towards more integrated, multimodal AI systems. I strongly agree with a lot of the points in position III, yet I also believe in internal world models.
A more comprehensive and inclusive viewpoint on LLM
NOTE: By no means, have I captured the nuances of the above three positions. Nor do I believe that any of their position is wrong and right. With a very high probability, I believe that my own position is likely to be equally wrong and right with the above three positions.
I believe that all three positions make some good points and I agree with a lot of points from positions 2 and 3. Let’s break it down, what is likely happening in these LLMs?
As we all know NN are universal function approximators. So, we know these functions are indeed trying to model the world (assuming the real world has some function).
Now the problem is that there are different types of data distributions, some are easy and some are complex. For instance, the research in Mechanistic Interpretability (click here to know more on this topic) has revealed that models can learn mathematical algorithms.
But that doesn’t mean that models can learn all the underlying structures, sometimes they are just answering the stuff from memorization.
There is a concept called Grokking, it is defined as the network going from memorizing everything to generalizing. A sudden jump in test accuracy is the sign where the model groks. When you train a network, your train loss keeps decreasing constantly, but the test loss doesn’t. But somewhere down the line, it decreases exponentially, and that’s when the model goes from memorization to generalization.
So, I believe that these LLMs are part memorization and part generalization. Now the concepts that are simple and have clear data distributions, LLMs will pick those structures and will create an internal model of those.
But I can’t say with confidence that the internal world model is good enough to create intelligence. Now when we ask questions from that world model, the model appears to get everything correct and even shows generalization capabilities, but what happens when it is asked questions from different views and perspectives, it fails completely, something revealed in a paper called LLM reversal curse.
The way I think about this is: that a biologist can explain the cells and structure of a flower, but can never describe its beauty, but a poet can describe its essence. Meaning, a lot of human experiences are so visceral, that they are not just a mapping problem. Most neural networks are just mapping one set of information to another.
Let’s summarize how I think about the human brain and LLM. Human brain has different concepts and experiences turned into the internal world model. These internal models have both abstractions and memory. Now we have many such internal world models, and the way we make sense of the world is to have consistency in these world models within themselves, more importantly, we should be able to navigate from one model to another, and that’s the conscious experience of the human mind, asking the right questions to reach different world models. Human mind can automatically activate and deactivate these internal world models and look at other internal models in combination with the generalization of other models.
As far as LLMs are concerned, first and foremost, they might have world models for a few concepts that has a good data distribution. And for a lot of these internal world models, it might completely rely on memorization rather than generalization. But more importantly, it still doesn’t know how to move from one internal world model to the other or use the abstraction of other internal world models to analyze the present internal world model. The conscious experience of guiding intelligence to ask the right question to analyze something in detail and use system 2 intelligence is completely missing. And I do believe that it is not going to be solved by the Neural scaling law. All scaling will most likely do is create a few more internal models that rely more on generalization and less on memorization.
But the bigger the size of the models, the less we know whether it is responding out of memorization or generalization.
So, in short, LLMs don’t have any mechanism to know what question to ask and when to ask. This is expressed beautifully by the below diagram.
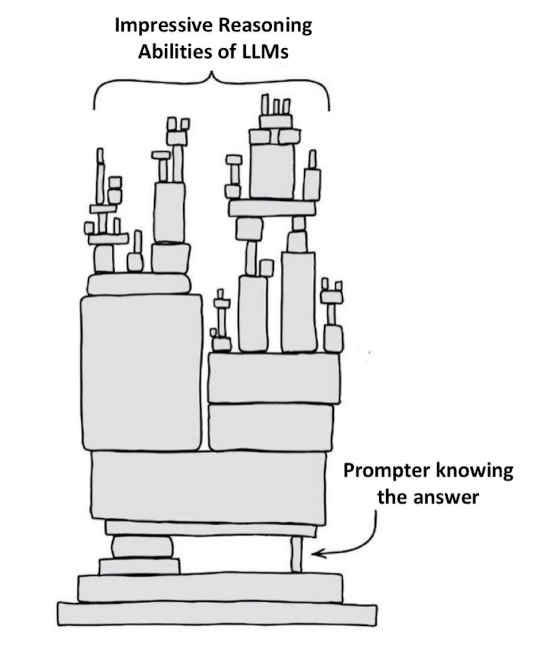
LLMs are N-gram models on Steroids
Text in language models is treated as a sequence of words, including spaces and punctuation. An n-gram model learns to predict the nth word based on the preceding n-1 words. For instance, a unigram predicts each word independently, a bigram uses the previous word, and a 4k-gram model, like ChatGPT, predicts based on the previous 4000 words. The efficacy of such a model depends on the training data size, the context length (n), and the capacity of the function learning probabilities.
GPT trained on Terabyters of text, uses a model with trillions of parameters to approximate the probabilities for sequences in its vocabulary. Traditional n-gram models require tracking conditional distributions for each possible sequence, which becomes impractical for large n-values. It would become so large that entire world memory would not be enough to store the conditional probabilities. {(50000)⁴⁰⁰⁰ > number of atoms in the universe, if we imagine a vocab size of 50k and context length of 4k}
Then how do we train such systems, if we can’t even store the conditional probabilities?
We achieve this by compression, if you know something about compression, you will know that doing any form of compression automatically creates a form of generalization. Thus LLMs show the ability to generalize and abstract from its training data, a capability beyond mere pattern matching.
But the question remains, is it the right generalization? Nobody knows.
Memory retrieval or generalization
There is this idea that our brain works in two modes, one where it just retrieves information and the other where it has to think consciously. If someone asks you 2+2, we don’t actually think, we just retrieve this information, but if someone asks 1089x12, we have to consciously calculate it.
Another way to think about this System 1 and System 2 type of intelligence, is blitz chess where you play instinctively compared to regular chess where you analyze everything in detail.
So we believe that current LLMs are System 1 intelligence, that’s why every word (for any problem) is taking almost the same time to be predicted. But the problem lies in the training data itself, we don’t know what’s present in the training data and we often get confused by retrieval with generalization. For instance, there are wesbsites that explain jokes, that explain movie endings, and when we discovered these behaviors we thought that these models have truly developed an understanding of these worlds.

Broken academia
The problem with current papers on LLMs capabilities and capacities is that in a hurry to publish papers on what’s currently hot, a lot of papers have come out without proper systematic analysis.
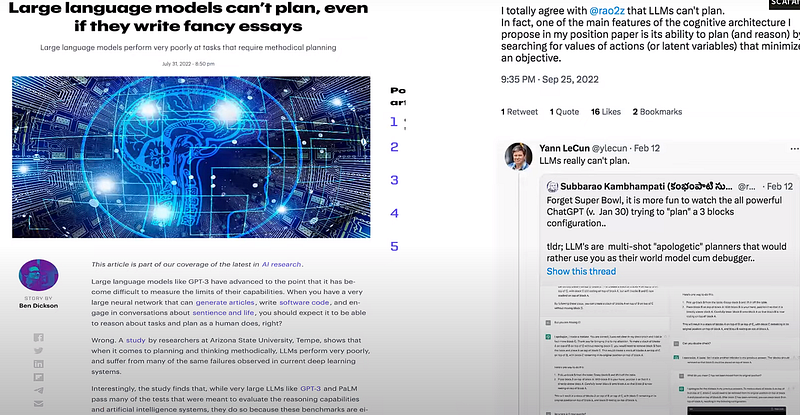
LLMs have been shown to fail many times in the most basic tasks. It failed in creating a plan for a 3-block world problem. For GPT 4 it showed around 34% of accuracy. Now you might say it is not able to plan as well as humans, but it would easily surpass within just one or two iterations.
To test out this claim researchers just changed the words in 3 block world problem. Just look at the below diagram to see the results.

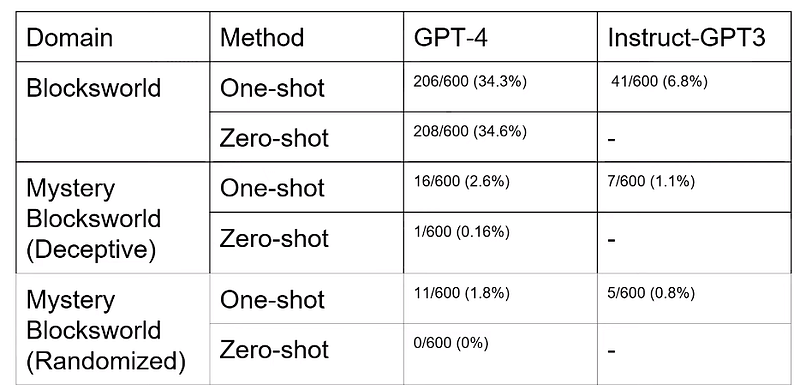
This shows that there is a good chance that it was bringing out all these plans from memorization not by generalization.
Note: They even tried fine tuning and chain of thoughts, yet there was no significant improvement on GPTs planning capacity. Because fine tuning is not going to give any reasoning capabilites but just make the problem about local retrieval.
In the end, we need to ask ourselves, why do LLMs behave the way they do?
Basically, they are just still autocomplete machines, now we have fine-tuned their behavior by doing pre-trained finetuning or RLHF, but that doesn’t mean that they are thinking intelligently just like humans do.
Some of you here might ask, why do even create an intelligent system like humans, why not different, humans have so much lacking in their own intelligent system.
Correct, I don’t know the answer to why we want to create intelligent machines like us. But what other way do we have to evaluate intelligence other than our own type of intelligence?
Both of these papers show much more about how bad GPTs are in planning:
Initially, people thought these models would naturally get better at reasoning as they grew larger, but recent examples have shown this isn’t necessarily true. The belief that LLMs can critique and improve their own work might be overstated. A study on the graph coloring problem, a complex task, showed that GPT-4 struggles both in solving and checking its own solutions. It seems that any success in iterative (step-by-step) problem-solving by LLMs may just be luck in picking correct solutions from many options, rather than true self-critiquing ability. This challenges the idea that current LLMs have advanced self-critiquing capabilities, and goes totally against the Chain of thoughts or Tree of thoughts ideas.
Chain or Tree of Thought methods involve the LLMs articulating their reasoning process step-by-step, similar to how a human might break down a problem. However, the study suggests that LLMs may not genuinely reason or self-critique effectively; their success in iterative tasks might be more about stumbling upon correct answers rather than true analytical thinking. This difference points to a gap between the appearance of methodical problem-solving (Chain/Tree of Thought) and the actual reasoning capabilities of current LLMs.
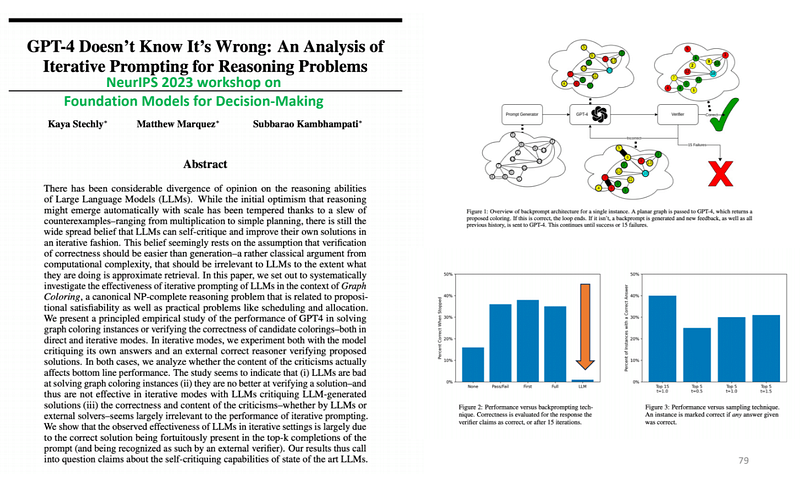

LLMs keep fooling us about their reasoning capabilities

When I came across the above prompt I was mildly surprised, this appears quite tough, but this can easily give us a sense that systems have built a good understanding of texture and context.
But then why does this happen?
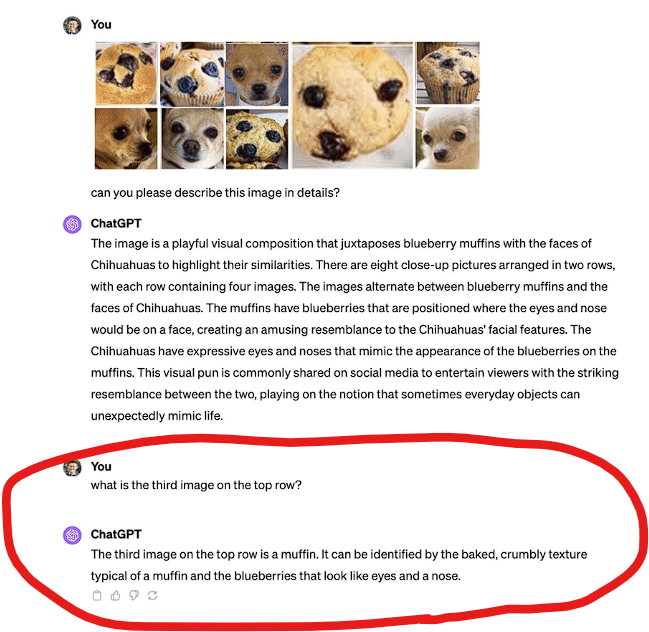
It shows that there is a great chance GPT answered correctly, in the first response because it has seen that image in its training data. People did more experiments with this image, they just shifted the images here and there and GPT gave completely wrong responses. That again puts a big question on what it is understanding and what it is retrieving.
Let’s look at another case, where we seem to have sparks of AGI.

GPT fails miserably when it is asked to decode text by shifting words by 8, but it works perfectly when it is asked to do the same thing but with 13-length shifting, why? Because the internet is filled with 13-shift problems.
The same thing has been observed in Goat, lion, feed, and farmer crossing the river problem.
All these impressive results often confuse and give us a wrong sense of generalization planning capabilities. An interesting parallel to GPT's clever performance is the Clever Hans Effect.
LLMs are great, but why such a divide?
Don’t get me wrong, LLMs are great and they are intelligent idea-generating machines, but that’s not the extent of intelligence. Even the human mind keeps generating ideas all the time, but the real thing is can it come up with a plan of action to verifiably prove or justify that idea, that is something in which LLMs suck really hard. That’s why they are approximate idea-generating machines and out of those ideas, how to judge which one is good and which one is bad, meaning it still lacks the understanding of the world.
Planning is not just idea generation, but also validating the plan of action. That’s why plans generated by GPT might look like actual plans, but they only become actual plans if they can be validated, till then they are just approximate ideas.


So, at last, you might ask, what about all those complex problems, I solved using GPT or methods like Chain of Thoughts?
Ask yourself, was it GPT who solved it or do you already know how to prompt it to get to the solution? You just couldn’t put that in a proper format. Because GPT doesn’t know when a task is solved, it is still you identify what looks like solved.
This is something I’ve come across many times, when I ask it to give or create a completely new DL architecture or something similar, it hallucinates so much, it never says that I’m unable to come up with anything, but will give you a very generic response. But then if you inject a new idea, it will suddenly, respond much better and will be able to correlate with other ideas. Now the problem is that if your initial idea was wrong but still a new idea. It will still find a reason to unnecessarily justify the correlation and validity of that idea with other ideas. And that exactly tells you what LLMs can and can’t do. Understand what’s correct and what’s not, and plan the execution of those ideas.
There are still many things that we’ve not explored, LLMs are great and can be used in combination with other planers and software to create completely new types of AI solutions to existing problems.
Conclusion
So, I’m reiterating that we understand very little about LLM's working and capabilities. Given their huge size, it becomes very tricky, whether it is reasoning and planning or just generating approximated ideas. Evaluating this in a good way is quite tricky, but hopefully, this blog gave you a new direction to think about LLMs, an approximate idea generation machine, not a machine that understands the idea’s validity and its execution.
Check out the other two parts of this series: Part 1 and Part 2
Thanks for reading and reaching the end. If you like this type of content, check my Newsletter. I try to write beyond the hype and go in as much technical detail as I can, consider following me on Medium if you like my work.
References
[1] https://arxiv.org/abs/2302.06706





