
Mechanistic Interpretability for decoding black box AI — III
This is Part 3 of our Interpretability series. In the past two blogs, we’ve covered a lot of ground, especially how to think about the black-box nature of AI and the ways to decode it. In the first blog, we answered the following questions: What exactly is the problem of Interpretability? What has happened till now in the field of AI explainability? Understanding Mechanistic Interpretability.
Read part 2 here:
And in the second one, we went even one step further to answer the questions about how to think about AI. Can there be a theoretical understanding of the AI model’s internal workings? We took a look at: What’s wrong with current interpretability methods? Why should we care to research Mechanistic Interpretability? How will Interpretability work in the age of GPT-like models? Are there universal structures in DL or not? Constraints in the internal model structure? Grokking and how it works? How do ML models represent their thoughts?
I highly recommend reading both the blogs fully to make sense of the problem. It’s quite a complex topic (probably one of the hardest in all AI research), and it needs a good understanding of the basics.
In today’s blog, we are going to look into the nitty gritty and maths of how researchers are solving this.
Table of Contents:
- Defining Mechanistic Interpretability
- The Setup
- What is grokking, and why does it happen?
- AI Safety
- Induction Heads
- Superposition in DL models
- Interpretability in the wild
Defining Mechanistic Interpretability
Hypothesis
DL models can learn human-comprehensible algorithms. These models can be understood, but by default, they have no incentive to make themselves legible to us.
Mechanistic interpretability in the context of DL involves delving into the inner workings of these models to understand how individual components contribute to overall behavior. To put it technically, we want to elucidate the function of each neuron, layer, and pathway within the network with respect to how they process inputs and affect the final output.
Simply put, we somehow need to reverse-engineer the weights of the trained neural networks and convert them into a large binary file or Python code that, later on, we can use to know the limits of what the given model can’t do. It’s easier said than done; doing this is extremely hard; even small models of a few layers forget about models like GPT.
But how are we making these claims that DL models can be broken down and interpreted? The hunch is that in the end, DL models are just a bunch of neurons performing linear algebra, so theoretically, it should be possible to break it down in a human understandable form.
The Setup
Can a one-layer transformer learn modular addition?
What is modular addition? (a+b)%m
Here’s an example to illustrate:
- Suppose you’re working with a modulus of
m = 5. - Let’s add
a = 3andb = 4. - The regular sum is
3 + 4 = 7. - Applying the modulus:
7 mod 5 = 2. - So, in modular addition with a modulus of 5,
3 + 4equals2.
Let’s look at the setup.
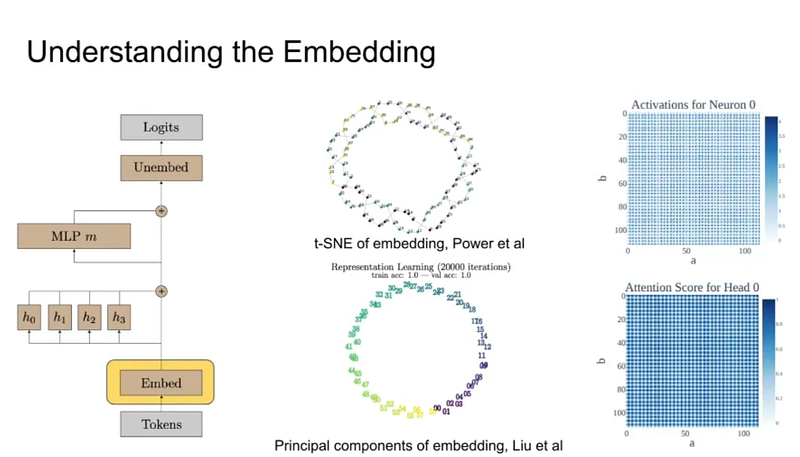
Why do we see a well-defined structure of embeddings? They could have been completely random looking when learning about modular addition, but they aren’t; it tells that our 1-layer Transformer uncovered some general structure.
At a high level, modular addition is similar to composing rotation around a unit circle.

The above diagram shows the algorithm implemented by the one-layer transformer for modular addition.
Embedding and Rotation:
- The transformer takes two inputs,
aandb, which you can think of as positions on a circle. It uses a special matrix (the embedding matrix) to rotate these points to new positions on the circle that are determined by the information contained inaandb.
Combining Inputs:
- The network then combines these two rotated positions to find a new position on the circle that corresponds to the sum of
aandb.
Modular Addition:
- In normal addition, you just add the numbers together. But here we’re doing “modular” addition, which means if the sum goes past a certain point (in this case,
P), it wraps around back to the beginning, just like the hours on a clock wrap around after 12.
Outputting Results (Logits):
- Now, the transformer wants to find the “logits,” which are indicators of the result of this modular addition. It does this by effectively rotating the circle backward by each possible result (
c), which goes from 0 up to one less thanP(so ifPis 12, it would go up to 11, like the hours on a clock). - When it rotates backward by the right amount, the position on the circle points straight up. This is when
a + bminus the amount it rotated by (c) is exactly at the top of the circle. When it's straight up, the cosine function gives a maximum value, which means the transformer has found the correct answer toa + b mod P.
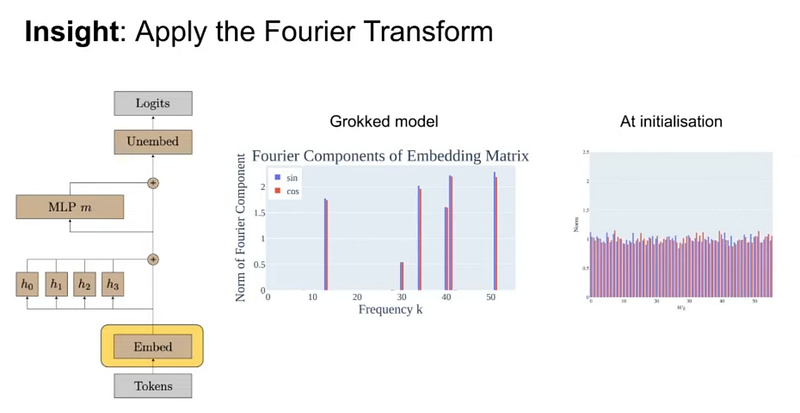
We are saying it used Fourier multiplication for modular addition, but how are we sure? It is possible that the network learned this, but it is solved in some other ways.
Look at the diagram below: What do you see?
At initialization, all the weights are contributing. Still, by the time the model learns to do modular addition, all the weights have become irrelevant, and all we are left is a function comprised of certain sine and cosine wave frequencies, like when we do a Fourier transform.
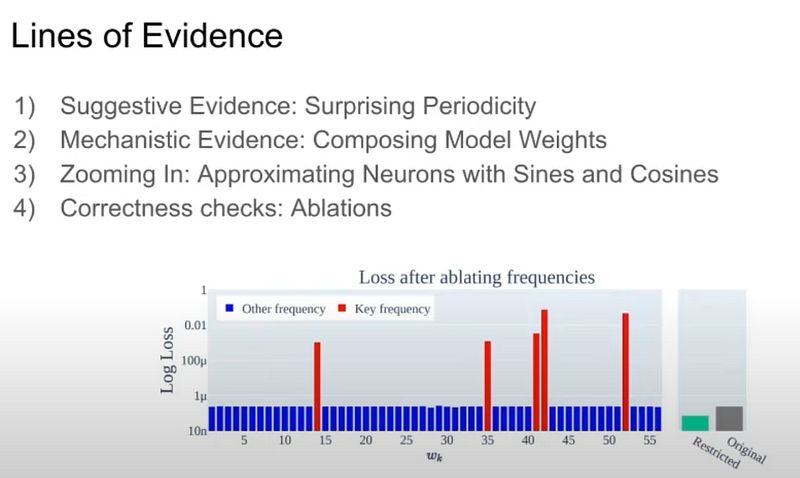
They even performed ablations when they made the corresponding high-frequency weight 0, performance tanked, but when they made other weights 0 nothing happened, that means somehow some specific neurons have learned the algorithm, not just memorized everything and stored it in an encoded form.
What is grokking, and why does it happen?
Grokking, if defined, is the network going from memorizing everything to generalizing. A sudden jump in test accuracy is the sign where the model groks. When you train a network, your train loss keeps decreasing constantly, but the test loss doesn’t. But somewhere down the line, it decreases exponentially, and that’s when the model goes from memorization to generalization.
But the question remains: why do models grok?
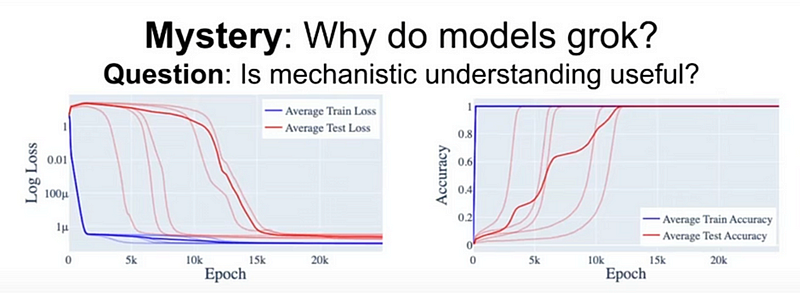
A few of the answers given by the early researcher were as follows.

But the reality is a bit different.
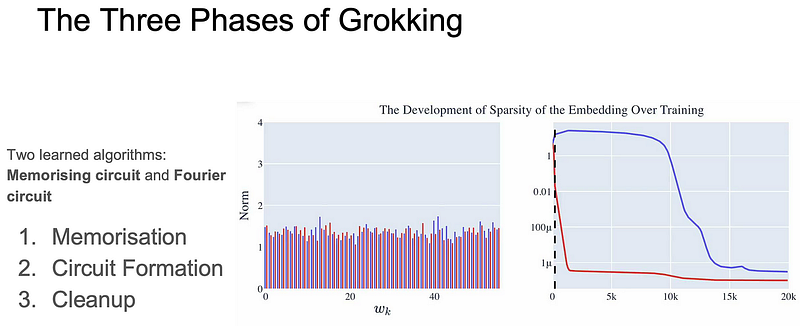
Here’s how it works:
- Look at the black dashed line (right side); till that point, the model is memorizing; that’s why on the (left) diagram, you can see all the weights contribute fairly equally.
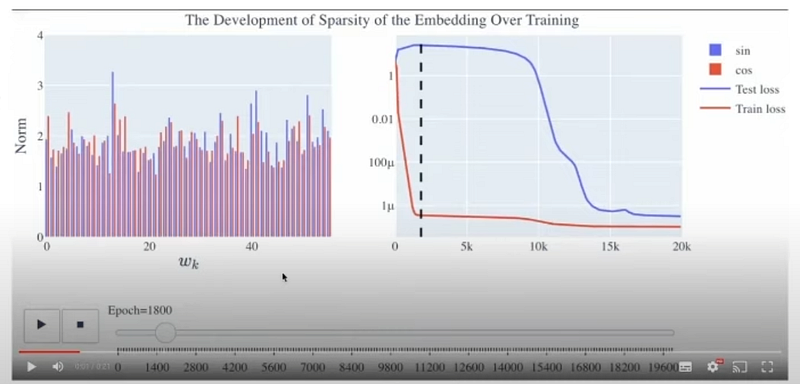
2. Now, look at the black dashed line. Until this point, the model identifies the internal circuits (Circuit formation) to represent the different internal structures or algorithms. Test loss is yet to decrease.
An important point to note is that test loss is not decreasing because, till this point, it has not activated the found circuits. We know that memorization performs extremely badly on out-of-distribution data.
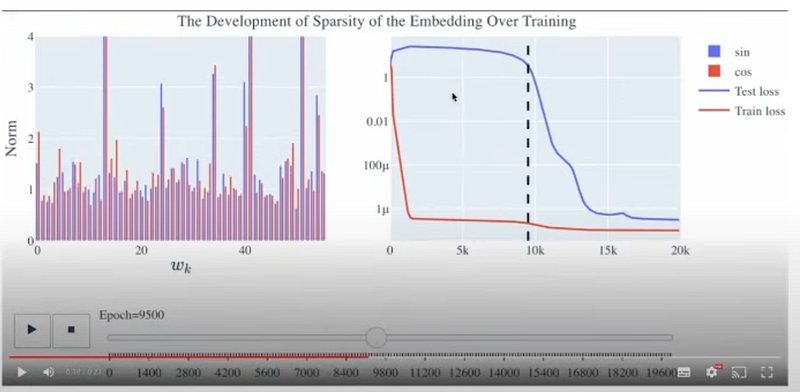
3. Now look at the black dashed line; the test loss decreases rapidly as soon as the model cleans up the memorization weights and starts using circuits to make predictions rather than from memorization weights. This is where the model has become fully generalized.
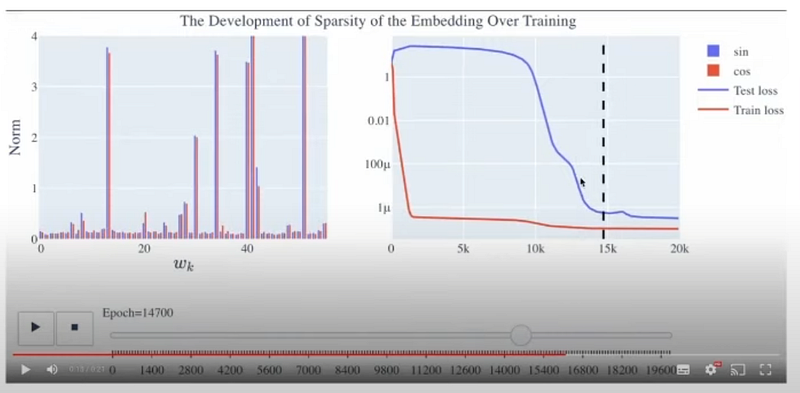
And this whole phenomenon is called grokking.
AI Safety
The reason we want something like Mechanistic Interpretability is to create a safe AI that is aligned with human goals and values.

We’ve discussed in full detail about AI safety framework in this blog:
Induction Heads
The idea of the “induction head” in the context of Transformer language models is an interesting concept. To explain it with an example, let’s consider how Transformers work and the role of induction heads within them.
Induction Heads in Transformers:
The induction head is a specialized component within a Transformer model that helps it to “complete patterns” based on previous occurrences within the input data. Let’s use a simple text example to illustrate how induction heads work:
- Imagine you have a sequence of tokens (words) representing a nursery rhyme that the model has seen during training: “Twinkle, twinkle, little star, how I wonder what you are…”
- Now, when the model sees the sequence “Twinkle, twinkle, little…” during inference, the induction head’s job is to recognize that the current token “little” was previously followed by “star”.
- The model does this by using a pair of attention heads:
- The first attention head (the “previous token head”) looks at the token “little” and copies relevant information forward in the sequence, which can be used to predict the next token.
- The second attention head (the “induction head” itself) uses the information provided by the first head to identify that “little” was previously followed by “star” and predict that “star” should be the next token in the sequence.
Importance of Induction Heads:
- In-context learning: Induction heads enable the Transformer to learn from the context within the input data. They can recognize patterns and use those patterns to make predictions, which is a form of learning from the context without additional input labels.
- Mechanistic interpretability: By decomposing the functions of Transformer models, researchers can identify components like induction heads that provide insights into how these models process language and learn from sequences.
- Pattern completion: Induction heads help the model to “complete” sequences or patterns based on previous data, which is crucial for tasks like text completion, translation, or even generating coherent text.
Superposition in DL models
It would be very convenient if the individual neurons of artificial neural networks corresponded to cleanly interpretable features of the input. For example, in an “ideal” ImageNet classifier, each neuron would fire only in the presence of a specific visual feature, such as the color red, a leftfacing curve, or a dog snout. Empirically, in models we have studied, some of the neurons do cleanly map to features. But it isn’t always the case that features correspond so cleanly to neurons, especially in large language models where it actually seems rare for neurons to correspond to clean features. This brings up many questions. Why is it that neurons sometimes align with features and sometimes don’t? Why do some models and tasks have many of these clean neurons, while they’re vanishingly rare in others?
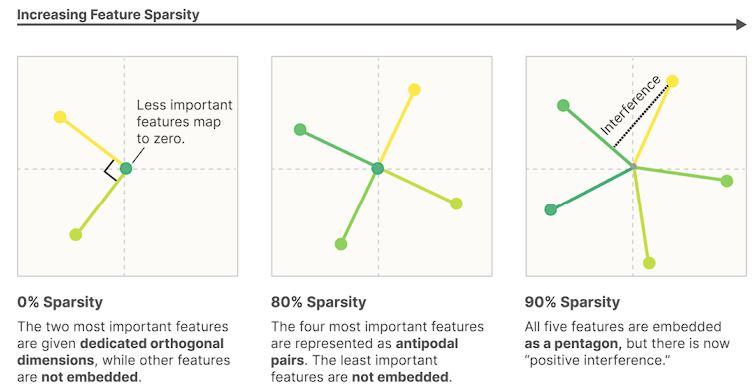
To answer that, researchers found that not only can models store additional features in superposition by tolerating some interference, but they showed that, at least in certain limited cases, models can perform computation while in superposition. (In particular, they showed that models can put simple circuits computing the absolute value function in superposition.) This leads them to hypothesize that the neural networks we observe in practice are, in some sense,noisily simulating larger, highly sparse networks. In other words, it’s possible that models we train can be thought of as doing “the same thing as” an imagined much larger model, representing the exact same features but with no interference.
This superposition makes the neuronal level decomposition hard.
Interpretability in the wild
The research focused on understanding how GPT-2 small, a transformer-based language model, performs the task of indirect object identification. This task involves completing sentences like “When Mary and John went to the store, John gave a drink to…” with the correct indirect object (in this case, “Mary”). The researchers identified a circuit within the model comprising 26 attention heads, divided into 7 main classes, responsible for this task. This discovery was made using a combination of interpretability approaches, including causal interventions.
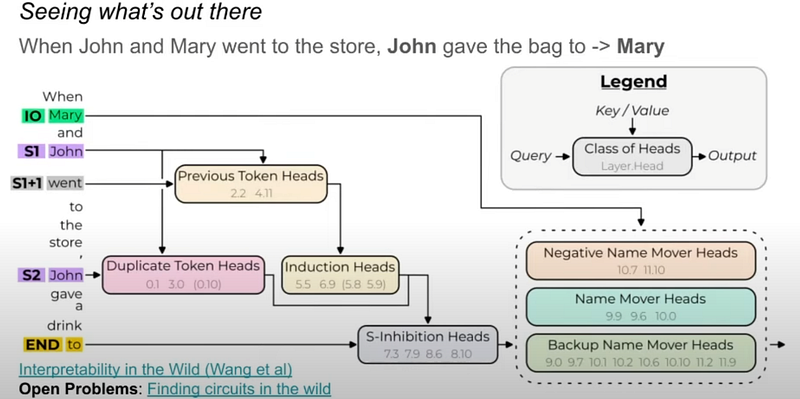
Mechanistic Interpretability and Its Challenges: The study highlights the challenges in mechanistic interpretability, especially in understanding the full functionality of model components and the occurrence of redundant behaviors. For instance, they discovered “Backup Name-Mover Heads,” which take over the function of regular Name-Mover Heads when they are disabled. This points to the complexity and redundancy in model structures.
Path Patching and Circuit Discovery: The paper introduces a method called “path patching,” used for tracing important components in the model’s computational graph. This method, combined with attention pattern analysis and activation patching, helped in understanding the behavior of different components.
Circuit Components and Functions: The identified circuit’s components include Duplicate Token Heads, S-Inhibition Heads, Name Mover Heads, and others like Induction Heads and Previous Token Heads. Each class of heads has a specific role in processing the input to identify indirect objects correctly.
There is an insane amount of literature to be covered and discovered. I know it’s not easy to understand, but if it were, we would have solved the black box problem long back.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
And if you want to up your AI game, please check my new book on AI, which covers a lot of AI optimizations and hands-on code:




