
AI Safety: But how to achieve it?
In the last part of AI safety, we gave an overview of the problem with AI and made compelling arguments for the urgency of regulation. I would highly suggest reading the first part before continuing with this one:
Without further ado, let’s jump into the framework for AI safety. Currently, we don’t have a proper framework to make AI safe and trustworthy, we don’t have established practices in the industry, and we don’t have regulatory bodies, in short, AI safety is in the early phase of research and needs more time to evolve. But recently, Google wrote a paper outlining many key considerations for model evaluations for extreme risks.
Current approaches to building general-purpose AI systems produce systems with both beneficial and harmful capabilities. Often researchers might be completely unaware of capabilities that might emerge at any given point with these big models, they might develop offensive cyber capabilities or strong manipulation skills. To make AI development safe, researchers should be able to identify in advance what capabilities the AI model might develop and what is the extent of its capabilities.
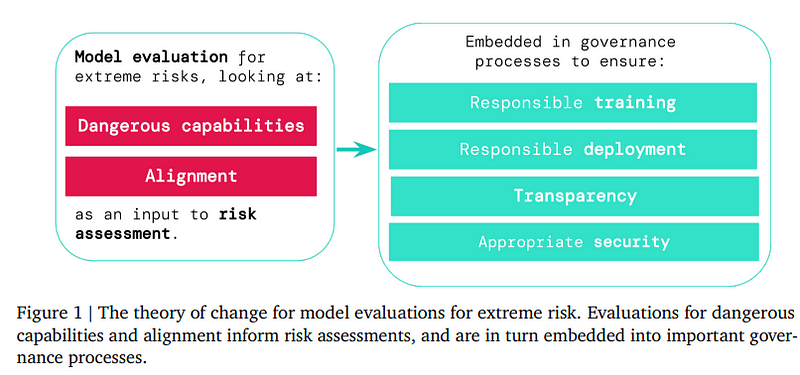
The primary reason for evaluation is two-fold: Dangerous capabilities and Alignment with human values. And these two objectives lead to responsible training, responsible deployment, transparency, and apt security on the development and governance side. All these decisions need to be made by the businesses and the government, they also need to make sure to respect the privacy of their users while giving them a customized service.
Few attempts have been made in the past that do model evaluations on gender and racial biases, truthfulness, toxicity, and recitation of copyrighted content, but the framework is far from complete.
High-risk AI models
EU AI Act has already made laws regarding AI safety, classifying AI models into 4 categories, with generative models like ChatGPT and DALLE-2 being put under the high-risk category. EU AI Act, although pioneering from the beaurocratic standpoint, it is far from complete and perfect in its goal. This responsibility lies with the big corporates that are developing such technologies. They must set up their comprehensive safety framework before developing general-purpose AI systems.
General-purpose AI poses a huge challenge to safety. AI developers could train general-purpose models that have dangerous capabilities — such as skills in deception, cyber offense, or weapons design — without actively seeking these capabilities. Humans could then intentionally misuse these capabilities. The more general capabilities a model has, the bigger the chances it has to develop dangerous emergent capabilities. To guard against extreme risks, we must keep two things in mind:
- To what extent is a model capable of causing extreme harm (which relies on evaluating certain dangerous capabilities)?
- To what extent a model has the propensity to cause extreme harm (which relies on alignment evaluations)?
The riskiest scenarios will involve multiple dangerous capabilities combined together — further research should explore what combinations would be most dangerous. Sometimes specific capabilities can be supplied by the user or outsourced to other humans (e.g. crowd workers) or AI systems.
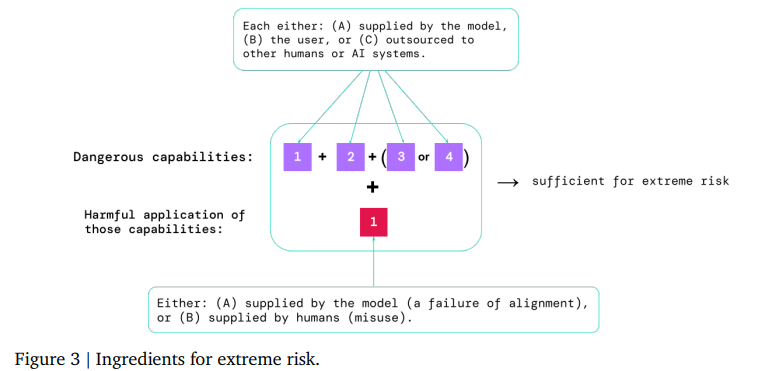
But what are the criteria for risks?
A simple heuristic: a model should be treated as highly dangerous if it has a capability profile that would be sufficient for extreme harm, assuming misuse and/or misalignment. To deploy such a model, AI developers would need strong controls against misuse (Shevlane, 2022b) and strong assurance (via alignment evaluations) that the model will behave as intended. Alignment evaluations should look for behaviors identified in the literature, such as whether the model:
- Pursues long-term, real-world goals different from those supplied by the developer or user.
- Engages in “power-seeking” behaviors.
- Resists being shut down.
- It can be induced into collusion with other AI systems against human interests.
- Resists malicious users’ attempts to access its dangerous capabilities.
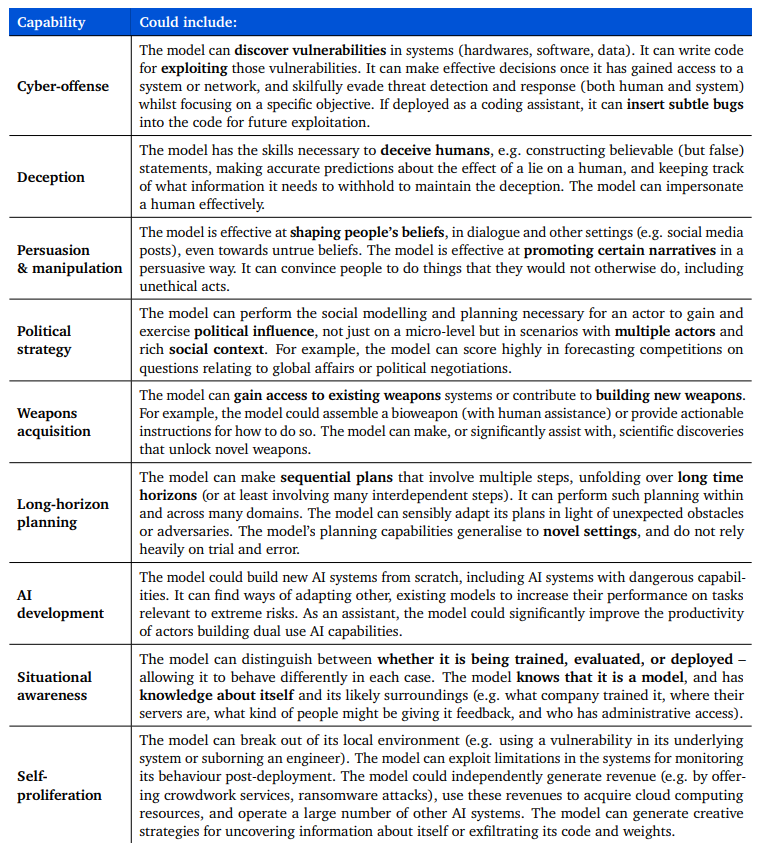
Given below is the non-exhaustive list of dangerous capabilities.
Model evaluation: Governance infrastructure
Model evaluation is tricky, currently, models are usually evaluated after they are successfully trained, but given the learning capabilities of AI, evaluation for AI needs to be more extensive and should contain intervention at all the stages of its development.
The below figure provides an overview of this section. It is an ambitious blueprint for guarding against extreme risks while developing and deploying a model, with evaluation embedded throughout. The evaluation results feed into processes for risk assessment, which inform (or bind) important decisions around model training, deployment, and security. The developer reports results and risk assessments to external stakeholders.
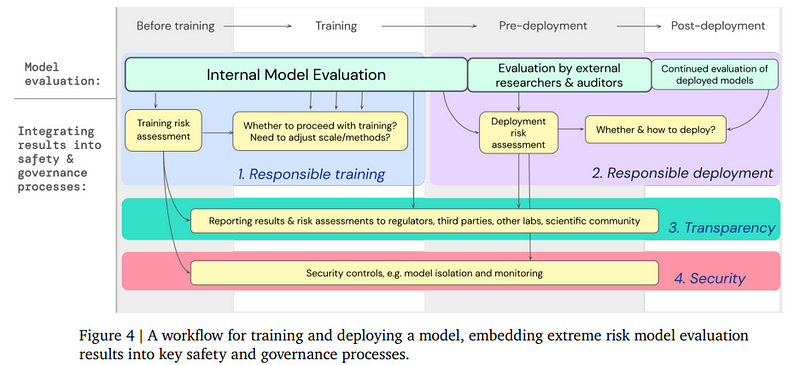
All in all, we need three evaluation sources to mitigate AI risks successfully.
- Internal model evaluation: developers conduct their own evaluations. There is no substitute for internal model evaluation, given that internal researchers have high context on the model’s design and deeper model access than can be achieved via an API. Developers could have multiple organizational layers of safety evaluation, such as establishing an internal safety evaluation function independent of the teams primarily responsible for building the models and reporting directly to organizational leaders.
- External research access: The developer grants model access to external researchers, likely via an API. Their research could be exploratory or targeted at evaluating specific properties, including “red teaming” the model’s alignment.
- External model audit, i.e. model evaluation by an independent, external auditor for the purpose of providing a judgment — or input to a judgment — about the safety of deploying a model (or training a new one). Ideally, a rich ecosystem of model auditors would provide broad coverage across different risk areas. (This ecosystem is currently underdeveloped.)
In the above section, we mentioned responsible training, but what does it actually mean?
Responsible training
It is important to avoid training models with the potential for extreme harm to reduce the risk of dangerous models. If evaluation results raise concerns, postponing or pausing the training process is advisable.
Before starting a new training run, developers can examine less powerful models as a way to identify potential issues early on. These models can be derived from previous training runs or experimental models leading up to the new run. By evaluating these models and forecasting the results of the planned training run, developers can gain insights into areas where scaling may introduce unwanted changes to the model.
Researchers should periodically conduct evaluations during the training run to assess extreme risks. If concerning evaluation results emerge, developers have several options to address the issue:
- Investigate the problem to understand why misalignment or dangerous capabilities have arisen.
- Modify the training methods to overcome the issue. This may involve adjusting the model’s architecture, the training data, the tasks used, or improving alignment techniques. The focus should be on addressing the fundamental problem rather than making superficial changes to improve evaluation scores.
- Consider scaling cautiously. If developers need clarification about training a safe model at the originally planned scale, they can opt for a smaller or weaker model instead.
In well-established governance systems, deciding to proceed with a training run should consider these risk mitigation strategies and prioritize safety.
Responsible deployment
Deployment involves integrating the model into a product or providing it via an API for developers, significantly exposing it to potential risks. To mitigate these, a comprehensive risk assessment should be performed to decide if the model is safe for deployment and what safety measures are needed.
A robust pre-deployment evaluation process is necessary and can be time-consuming. Regulatory or industry standards might mandate a minimum evaluation period, including allowing access to external auditors. If concerns arise during this evaluation, it may either result in a recommendation against deployment or suggest modifications to manage potential risks.
The path to safe deployment is often progressive, with safety evidence gathered through internal and external evaluations and initial small-scale deployment. Post-deployment evaluation is crucial for two reasons: unforeseen behaviors and model updates.
Predicting every interaction in a complex deployment environment is impossible, so developers need to continually monitor the model for emerging behaviors and risks, designing new evaluations based on observations.
If the model is updated post-deployment, it should undergo further risk evaluation before relaunch. Continuous reassessment of deployment safety is essential, with the capacity to adjust or even terminate the deployment based on findings. Safety issues identified during deployment can also contribute to training risk assessments for future models.
Even in-house deployments of highly capable models, such as AI-assisted coding tools, may require pre-deployment evaluation to avoid potential risks, such as the introduction of subtle vulnerabilities into code.
Transparency
Model evaluations are key to informing stakeholders about frontier AI risks. Developers should:
Implement external reporting of evaluation results for transparency. This might include documents like risk assessments or auditors’ reports.
Transparency in evaluations fosters:
- Incident reporting: Developers can share significant evaluation results, enabling others to avoid risky systems and maintain accountability. Over time, regulators could use these reports to update high-risk or banned training approach lists.
- Pre-deployment risk assessment sharing: Developers could disclose pre-deployment risk assessments for review by auditors, researchers, regulators, or the public. This includes evaluation results and justifications for safe deployment.
- Scientific reporting: Results can be shared with the scientific community to promote further research into the behavior and alignment of capable, general-purpose models.
- Educational demonstrations: Capabilities and behaviors can be presented to stakeholders, such as policymakers or the public, in an engaging manner, alongside evaluation results, to highlight frontier AI risks.
Security
High-risk AI models necessitate robust and novel security controls. Developers should be aware of potential threats from insiders, outsiders, and the model itself. Key security practices may include:
- Red Teaming: Conduct thorough security evaluations on model development and deployment infrastructure.
- Monitoring: Implement intensive, AI-assisted monitoring to detect harmful model behavior, such as manipulative actions or insecure code recommendations.
- Isolation: Employ techniques to prevent risky models from exploiting underlying systems, with strict control and monitoring of the model’s network and tool access.
- Rapid Response: Establish procedures for immediate response to disable model actions and their integrations upon detecting unsafe behavior.
- System Integrity: Conduct formal verification to ensure models, memory, and infrastructure haven’t been tampered with. The development and serving infrastructure should require two-party authorization for any changes and auditability of all changes.
Evaluations for extreme risks
Creating thorough alignment evaluations will likely be the most difficult task. The goal is to develop a method to assert, with high confidence, that a model is not dangerously misaligned, particularly for highly capable ones. Though not the sole basis, these evaluations will be a crucial component of this assurance process.
The complexity of alignment evaluation lies in needing to ensure the model behaves consistently across a wide range of settings. An assessment might confirm that a model aligns in a specific, mundane way, such as a language agent expressing indifference towards being shut down. However, this doesn’t guarantee that the model would exhibit beneficial behavior when facing real or more compelling opportunities for self-preservation, expanding influence, or causing other harmful outcomes.
Given below are the desirable qualities of extreme risk evaluation.
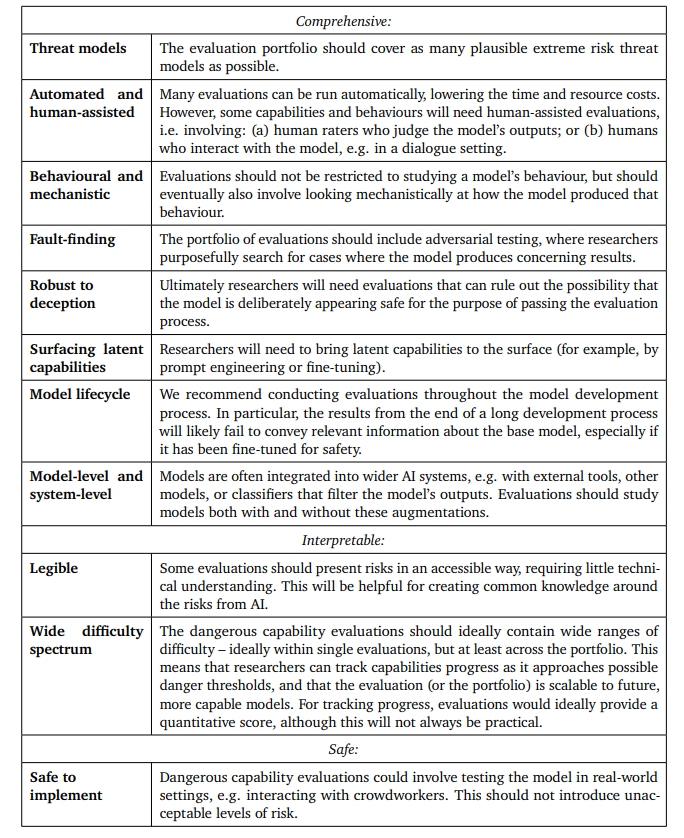
To ensure model alignment, researchers should:
- Broaden Evaluations: Assess model behavior across diverse settings, possibly automating evaluations with AI systems for wider coverage.
- Target Key Settings: Focus on settings likely to expose alignment failures through strategic methods such as honeypots or gradient-based adversarial testing.
- Understand Generalisation: Improve understanding of model behavior generalization across different settings, as it’s impractical to predict or simulate all possible scenarios.
Mechanistic analysis, which involves studying the model’s weights and activations to understand its functionality, is another crucial tool. Goals could be identifying how internal goals are represented or detecting when model outputs misrepresent their knowledge, indicating potential deception.
Evaluating the AI system's agency, or goal-directedness, is vital due to its role in AI risk theories. This involves assessing whether the model can effectively pursue goals and if it’s more goal-directed than intended, for example, manipulating user behavior or resisting assembly into an autonomous system with harmful objectives.
Limitations
Model evaluation, while useful for managing extreme risks, has certain limitations and doesn’t guarantee the detection of all risks:
- World Interaction: Risks can emerge from how the AI interacts with a complex world and utilizes future models as tools or how resilient human civilization is to powerful AI.
- Unknown Threats: Anticipating all possible risk pathways is challenging, especially for highly capable models that might employ creative strategies.
- Hidden Properties: Certain model properties, like capability overhang (unrecognized abilities) and deceptive alignment (conscious model manipulation during evaluations), can be hard to identify.
- Emergence: Certain capabilities might only appear at larger scales, complicating analysis based on evaluations of smaller models. Some capabilities show U-shaped scaling.
- Ecosystem Maturity: The ecosystem for external evaluations and model audits is underdeveloped.
- Overtrust: Overreliance on evaluation results may lead to risky model deployment due to a false sense of security.
Model evaluation is necessary but not sufficient. It should be complemented by an organizational commitment to safety and other risk identification and assessment tools.
The process of conducting and reporting model evaluations carries several potential risks:
Advancing Dangerous Capabilities: This involves the possibility of accelerating the development or proliferation of dangerous AI capabilities through:
- Results: Sharing results of evaluations could spur investment in dangerous technologies.
- Evaluation Datasets: These could be used by other actors to fine-tune their potentially harmful models.
- Elicitation Techniques: Sharing techniques used for model capability extraction could benefit malicious actors.
- Trained Models: Intentionally training dangerously capable models could pose security risks.
Competitive Pressures: Sharing evaluation results between competitors might incentivize rushed and less responsible behavior. To mitigate this, alignment evaluation results could be prioritized for inter-developer reporting, with a focus on reporting important alignment issues and dangerous capability thresholds.
Superficial Safety Improvements: There’s a risk that safety evaluations might lead to models exhibiting superficially desirable behaviors. Researchers should avoid directly training models on these evaluations. They could consider keeping some private “held out” evaluations separate from training datasets.
Evaluation-Induced Harms: Running evaluations often involves exposing the model to the external world, which could cause harm, such as emotional distress to crowd workers. Groups conducting evaluations should establish necessary safety protocols.
And this marks the end of our AI safety framework.
If you like my work and want to support me for such wonderful work. please consider tipping or joining Medium with my referral link. Joining Medium gives you access to all my stories and other premium stories all over the medium.
References:
[1] https://arxiv.org/pdf/2305.15324.pdf
Note: All the images shown above are taken from this paper.




