
Decoding AI Blackbox: Mechanistic Interpretability
This is part 1 of the series of blogs on Explainable AI.
Anyone who has worked with Deep learning models knows that Neural Networks are black boxes in nature. This is something that has really troubled scientists a lot. Trust is an important factor in making technology reach critical areas like medicine, autonomous driving, etc. In life-and-death situations, we do not want to relinquish our freedom of choice to a machine; we still trust humans more. The reason for trusting humans is not that humans are better decision-makers, but they can be penalized and made responsible in case anything goes wrong. You are not going to argue with a machine. The question is who is responsible for an incident, and that’s why we can’t trust AI in critical missions.
In the past few years, there has been a lot of effort in explaining the black-box nature of AI, but we are still very far from reaching a state of trust and explainability. In today’s blog, we are going to uncover the most important developments in the field of AI safety and Ethical AI, Mechanistic Interpretability being one of them.
Table of Content
- What exactly is the problem of Interpretability?
- What has happened till now in the field of AI explainability?
- Understanding Mechanistic Interpretability

What exactly is the problem?
Technical problems that impede the explainability of AI systems typically stem from the inherent characteristics of machine learning models, especially those using deep learning, as well as the complexity of the tasks they are designed to perform. Here are some specific technical challenges:
- Complex Models and Big Data: Think of deep learning like a complex recipe with millions of ingredients (parameters). It’s like a chef who can’t explain why the dish tastes good because there’s so much going on. Similarly, AI uses a lot of data points, like all the pixels in a photo or all the words in a conversation. This makes it hard to explain how AI makes its choices, just like it’s tough to point out which ingredient made a dish tasty.
- We Don’t Fully Understand AI: Many advanced AI systems work amazingly well, but even the experts don’t fully understand why. It’s like using a magic spell without knowing why it works. This mystery makes it hard to explain AI decisions in simple terms.
- Hard to Measure Good Explanations: There’s no easy way to measure how good an explanation is. What makes sense to one person might not for another. Plus, as things change over time, like the stock market or traffic patterns, explanations have to keep up, and that’s tough.
- AI Finds Patterns, Not Causes: AI is good at finding patterns — for example, noticing that ice cream sales go up when the number of sunburns goes up. But it doesn’t understand that hot weather causes both. Understanding “why” things happen is much harder for AI than just spotting the “what.”
What has happened till now?
- Development of Interpretable Models: Efforts have been made to develop models that are inherently interpretable, such as decision trees or generalized additive models (GAMs). Read more Here
- Post-hoc Interpretability: Techniques like LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations) have been developed to explain predictions after the model has made them.
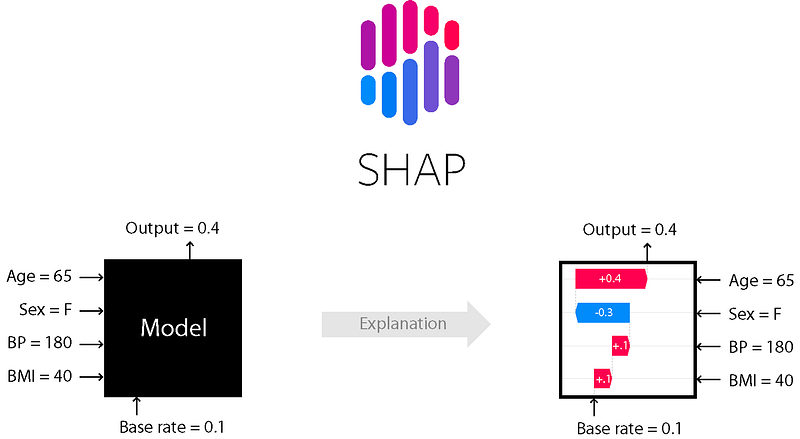
3. Feature Visualization: Methods for visualizing the features that neural networks focus on have been developed, particularly in the field of computer vision.

4. Attention Mechanisms: In natural language processing, attention mechanisms can sometimes offer insights into which parts of the input data the model is focusing on.

All of this is fine, but there is a big problem in all these models. All of them are looking at input and output pairs and trying to understand the model’s behavior. What if the model starts lying? How would you judge that it is going to be safe?
The idea behind mechanistic interpretability is that instead of looking at the input-output pair to understand the model’s behavior, we should move towards algorithmic understanding of these models so that we are 100% sure that the model will never operate beyond certain behaviors. This is the only way to safeguard humans against rogue AI.
Understanding Mechanistic Interpretability
Mechanistic interpretability in the context of neural networks involves delving into the inner workings of these models to understand how individual components contribute to overall behavior. To put it technically, we want to elucidate the function of each neuron, layer, and pathway within the network with respect to how they process inputs and affect the final output.
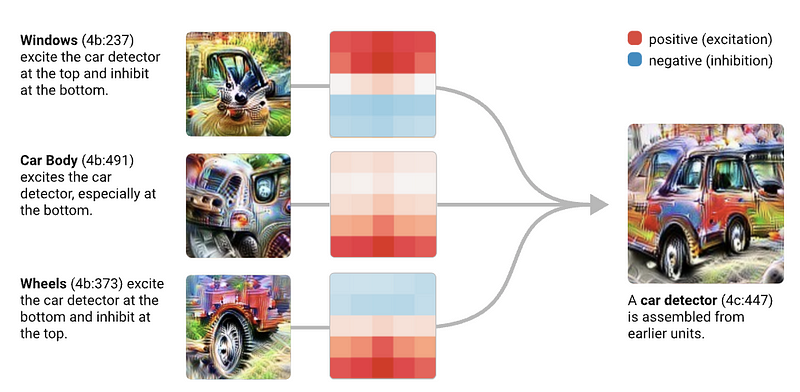
To dive deeper into the concept of mechanistic interpretability in neural networks, we must explore the ways in which we can understand and map the function of these complex systems.
Neuron-Level Analysis
Activation Maximization: This technique involves finding an input pattern that maximally activates a particular neuron, essentially answering the question, “What does this neuron look for in the data?” We do this by optimizing the input to increase the neuron’s activation, often resulting in a synthetic image or pattern that represents the neuron’s preferred stimulus.
Tuning Curves: In some models, especially those related to vision processing (like CNNs), neurons can be characterized by tuning curves which describe their response to specific orientations, spatial frequencies, or other image statistics.
Layer-Level Analysis
Feature Visualization: By visualizing the activations at each layer, we can infer what sort of features each layer is extracting. Early layers might focus on edges and textures, while deeper layers might represent more complex patterns or parts of objects.
Dimensionality Reduction: Techniques like t-SNE or PCA can be applied to the activations to visualize the high-dimensional space in which the network operates, giving insight into the data’s structure and how the network separates different classes or types of data.
Pathway Analysis
Activation Atlases: These are comprehensive visualizations of activations across many layers and neurons, providing a broad view of the feature space the network has learned.
Pathway Ablation: By systematically deactivating parts of the network (such as certain neurons or channels), we can observe the effect on output to understand which pathways are crucial for certain decisions.
Attribution Methods
Layer-wise Relevance Propagation (LRP): This approach redistributes the output prediction value backwards through the layers of the network, attributing the prediction to the input features in a layer-wise manner.
Integrated Gradients: This method computes the path integral of gradients for an input feature along the path from a baseline (zero input) to the actual input, thus attributing the prediction score to each feature.
Network Dissection
Semantic Dictionary: Building a semantic dictionary of neuron activations where each neuron is labeled with a concept (e.g., textures, shapes, objects) based on datasets where these concepts are labeled. This allows us to say, for example, “Neuron 256 is sensitive to circular patterns.”
Abstraction and Modularity
Functional Clustering: Grouping neurons into clusters based on similarity in their activation patterns can reveal functional modules within the network.
Representation Similarity Analysis: Comparing representations across different models or different layers to understand how information processing changes and how abstraction levels increase in higher layers.
Causality and Intervention
Counterfactuals: Modifying inputs to see how outputs change, for example, changing pixels in an image to see if the network’s classification changes. This helps in understanding what the model considers necessary information for its decisions.
Ablation Studies: Systematically removing or altering parts of the network to study the impact on performance. This can pinpoint parts of the network that are critical for certain tasks.
By employing these methods, researchers can create a detailed map of how neural networks operate on a mechanistic level. Such a map not only helps in making the model’s decisions more transparent but also aids in improving model design and ensuring that decisions are made for the right reasons, thus mitigating issues of bias and unfairness. It’s an ongoing field of study, given that fully understanding the intricacies of deep learning models is a complex and challenging task.
NOTE: Don’t worry if you didn’t understand everything in detail. In the upcoming blogs, we will break this down in complete detail.
Click here for Part 2
This is in no way complete; this is just an introduction to the idea, soon we will discover how this idea works in full detail in upcoming blogs. This has been one of the most important research areas in AI that I have come across lately. AI ethics and AI safety are of utmost importance.
Ethical AI and AI safety need 30 times more researchers than what we currently have. Developing safe AI is key to a better and sustainable future.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
And if you want to up your AI game, please check my new book on AI, which covers a lot of AI optimizations and hands-on code:





{kind=link}
{kind=link}