
Decoding AI Blackbox: Mechanistic Interpretability — II
We want to understand DL models. A sad fact about DL models, they are weird, and they work; they represent concepts differently than how we think about them, and that’s why reverse engineering a DL model is quite tricky. The current problem is that we don’t have a good enough conceptual framework to reason about why the model works and even how to interpret it. We don’t have a theory on why they work and how they work, and even if we have some hypothesis of the model’s working nature they often are disproved in empirical testing. Then the question arises, how do we understand and reason about model understanding?
This blog will be big, I mean big; I don’t know the answers to everything, and a few things are just speculation and hypothesis!!! Enjoy the rest of the read, and ask your own questions while reading it.
I recommend checking out Part 1 first to better understand the problem and what has been done till now.
Read part 3 here:
Table of Content
- Can there be a theoretical understanding of the AI model’s internal workings?
- What’s wrong with current interpretability methods?
- Why should we care to research Mechanistic Interpretability?
- How will Interpretability work in the age of GPT-like models?
- Are there Universal structures or not in DL?
- Constraints in the internal model structure
- Grokking and how it works?
- How do ML models represent their thoughts?

Can there be a theoretical understanding of the AI model's internal workings?
The core operations of AI models, particularly neural networks, are grounded in linear algebra. However, the intricacies arise from non-linear activation functions, high-dimensional parameter spaces, and the dynamic learning process, which make these models behave in complex ways that are not immediately explainable by simple linear algebraic structures.
The theoretical understanding of these models is further complicated by their “black box” nature, which often obscures the internal workings and decision-making processes within the network.
Efforts are underway to develop theoretical frameworks to explain the behavior of AI models better. For instance, studies around neural tangent kernels and Information Bottleneck Theory attempt to provide a theoretical basis for understanding learning dynamics and information flow in networks.
While much of the progress in deep learning has been empirical, the quest for a stronger theoretical foundation is a vibrant area of research. It’s possible that future work might unveil mathematical structures or theorems that can better explain AI behavior, aligning with your hypothesis of an underlying theoretical modeling of AI behavior. But it is also possible that Mechanistic interpretability fails completely and utterly and there is no mathematical structure to what a model learns.
What’s wrong with current interpretability methods?
Current interpretability methods often fall short of providing a clear understanding of the internal mechanisms of complex models like deep neural networks.
Current method are too much dependent upon input and output, not on what’s going on inside the model.
Here are a few examples illustrating a scenario where tracing a chain of thoughts to interpret a model’s behavior is challenging:
Consider a convolutional neural network (CNN) trained to identify diseases from medical imaging data. A simplistic interpretability method might highlight regions in an image that the model deems important for its classification. However, this doesn’t provide insight into the underlying biological or medical reasoning.

In another recent paper by Miles Turpin, the author explores the limitations of a concept known as “chain of thought” in AI models. The experiment involved presenting the model with multiple-choice questions and asking it to explain its reasoning before providing an answer. They initially trained the model using a method known as “five-shot learning” by providing it five examples. In a particular scenario, even though the correct answer was “A” and the model also selected “A”, the reasoning or the “chain of thought” it provided to reach this answer was incorrect. Despite arriving at the right answer, the flawed reasoning process showcased the limitations in the model’s chain of thought.
Why should we care to research Mechanistic Interpretability?
Ambitious Interpretability: Striving for deeper interpretability could lead to meaningful discoveries, even if full interpretability may not be achievable. Models with legible algorithms are ripe for reverse engineering to understand their internal workings.
Engagement with Mechanisms: Delving into the actual mechanisms, computations, and algorithms the model has learned can provide a richer understanding beyond just looking at input-output relationships.
Feature Analysis: Analyzing how models compute features from earlier features can give insight into the hierarchical learning process. This is relevant for understanding complex models, possibly leading to better interpretability.
Causal Interventions: Applying causal interventions helps in understanding the actual mechanisms at play rather than just observing correlations, making the interpretation more robust and meaningful.
Avoiding Self-Deception: By striving for mechanistic interpretability, it’s easier to avoid being misled by superficial or spurious findings, which is crucial for both the reliability and trustworthiness of AI systems.
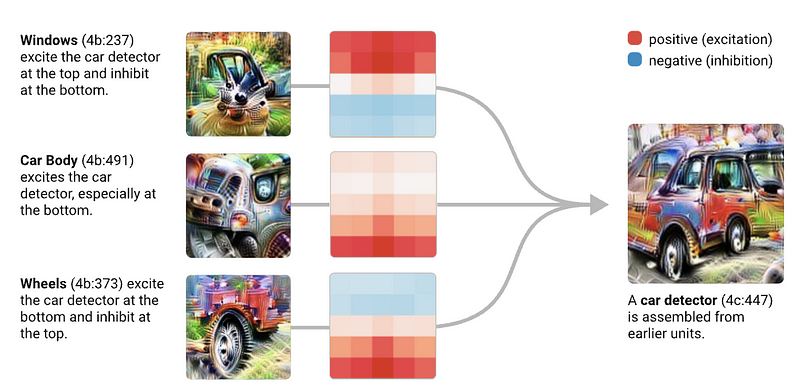
How will Interpretability work in the age of GPT-like models?
The idea here is about enhancing the interpretability of large AI models like GPT-4 to understand their internal workings better. Instead of just seeing them as black boxes that may sometimes produce deceptive or manipulative outputs due to learned patterns, the goal is to dive deeper into their “internal circuitry.” By analyzing crucial parts and asking important questions like how the model perceives its interactions and its self-awareness as a machine learning system, we aim for a clearer understanding of its behavior. This process might be labor-intensive, but with the help of automated tools and techniques like causal abstractions and interventions, it can become more efficient. For instance, a project where GPT-4 was used to analyze GPT-2 neurons is mentioned as a step in this direction, although it requires further development to be applied effectively and on a larger scale. Through such efforts, the aspiration is to decode the behavior of these models on various inputs, enabling a better grasp of why they respond the way they do.
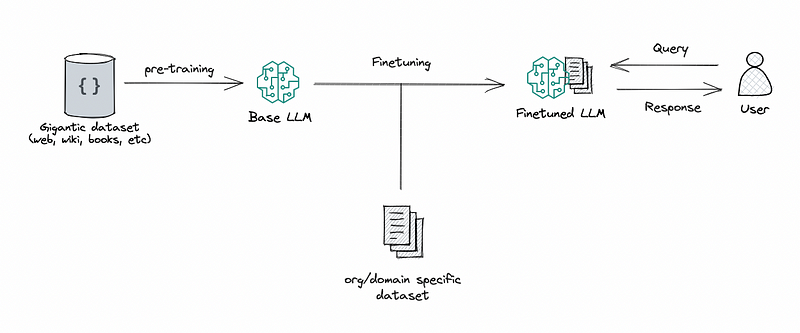
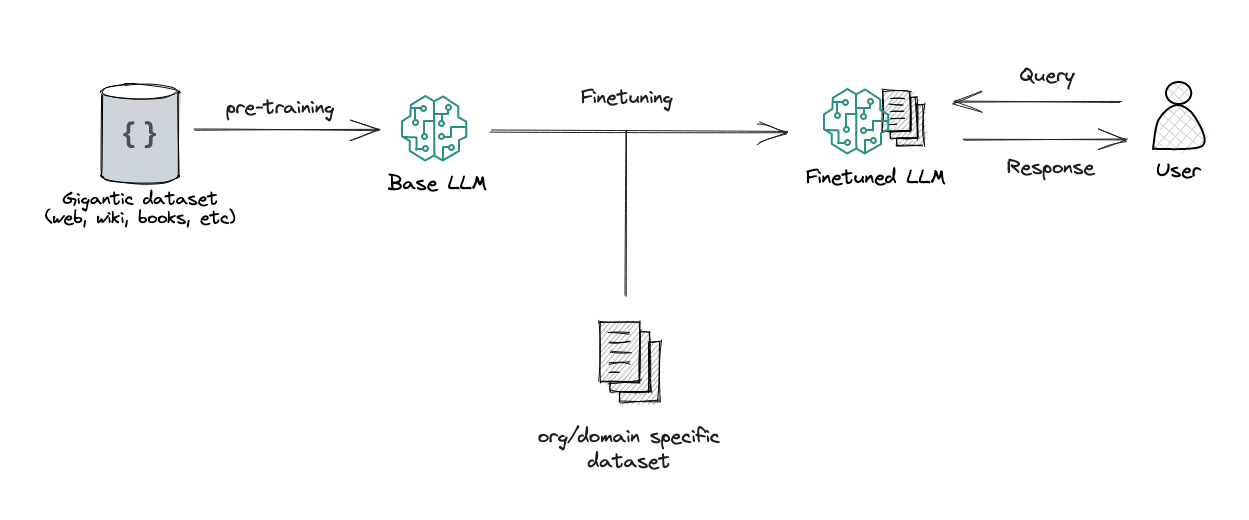
What does happen when LLMs are fine-tuned?
Fine-tuning a model essentially tweaks its internal workings to better align with a specific task. For instance, when fine-tuning a model for Wikipedia, it’s like you’re adjusting the model’s internal knobs to emphasize factual recall while maybe dialing down other aspects. This fine-tuning can indeed enhance performance as the model becomes more adept at the desired task. However, if you fine-tune for a longer duration or employ complex techniques like reinforcement learning from human feedback, the model begins to evolve further, learning more features and potentially altering its internal circuitry significantly. This continuous evolution could lead to uncertainty regarding how the model is functioning internally, and if every fine-tuning session drastically changes the model’s internal circuitry, it could be concerning. Yet, there’s hope that with advancements, we might get better at automating and managing these adjustments effectively.
Are there Universal structures or not in DL models?
There is a dichotomy in AI research called Neats and Scruffies; it represents two distinct approaches towards understanding AI models. Neats seek a clear, mathematical understanding, hoping to find universal principles that explain the models’ behavior. They aim for a clean, elegant understanding that simplifies the complex phenomena within AI models. On the flip side, Scruffies embrace the complexity and messiness of AI models, accepting that the behavior may be too intricate to distill into simple principles. They delve into the specific, unique details of each model, appreciating the complex reality of AI.
In exploring AI, a notion has arisen that amidst the complex behavior of AI models, there could be structured patterns or motifs that hint at a deeper structure. For instance, in language models, it’s speculated that universal cognitive priors could be present, leading to a hierarchical understanding of their behavior. However, the optimism for such neat, symbolic decomposition is balanced by the recognition that AI models might inherently be messy and complex, resisting straightforward theoretical interpretation. This ongoing discourse between seeking elegant theoretical frameworks and acknowledging the models’ convoluted nature continues to influence the trajectory of AI research.
Constraints in the internal model structure
Different AI models might need different types of explainability. In the past CNNs have been the focus now it's all about explaining Transformer models. Each model, with its unique architecture, imposes certain constraints on how it processes information.
For instance, Transformers, with their parallelized nature and attention mechanism, have a distinct way of moving information between positions, which could be likened to the flow of biological signals in an organism. This structural constraint shapes how algorithms are implemented within these models, potentially creating recognizable patterns akin to biological structures.
Just like organisms share common structures like bones and cell nuclei due to shared evolutionary history, AI models too might exhibit common algorithmic or operational structures owing to shared architectural principles or training methodologies. But there can always be unexplained behaviors, we do not know, all of these are just speculations and hypotheses to understand the black box.
Grokking and how it works?
In the domain of AI, the phenomenon of ‘grokking’ denotes a pivotal moment where a model transitions from merely memorizing data to generalizing from it, thereby acquiring a deeper understanding of the underlying task. The term finds its roots in a sci-fi novel but has found relevance in AI, representing a leap in the model’s learning curve. But what exactly unfolds during grokking? Let’s delve into a mechanistic interpretation of this phenomenon, informed by a study on a one-layer transformer model trained for modular addition.
The journey towards grokking unfolds in three distinct phases: Memorization, Circuit Formation, and Grokking.
Memorization: Initially, the model embarks on a memorization spree, acing the training data but faltering on unseen data, a testament to its inability to generalize.
Circuit Formation: As training progresses, the model enters a plateau phase dubbed ‘Circuit Formation’. Here, it begins transitioning from memorization to generalization, albeit at a pace so gradual it’s almost imperceptible. The training performance dips when restricted to memorization, indicating a shift in the model’s strategy.
Grokking: The final stage is where grokking manifests. The model, now adept at a trigonometric-based generalization algorithm, relinquishes its memorization parameters. This transition isn’t abrupt but is a culmination of the gradual generalization honed during the Circuit Formation phase. The sudden cleanup of memorization noise heralds the grokking phase, reflecting in a stark improvement in test performance.
In the landscape of AI, grokking signifies a model’s maturation from a data memorizer to a pattern generalizer, akin to a mind developing a deeper understanding over rote memorization. The exploration of grokking, enriched by mechanistic insights, paves the way for a more nuanced understanding of how AI models evolve and mature during training.
Read more about grokking here:
How do ML models represent their thoughts?
There are multiple ways to imagine and think about ML representation and we don’t know which one is the correct one. Here are a few ways to think about it.
Geometric and Linear Representations:
Geometric Representation: Think of images of cats and dogs being represented as points in a 3D space where the x, y, and z axes could represent features like fur length, ear shape, and tail length. In this space, all cat images would cluster together, and all dog images would form a separate cluster, showcasing geometric relationships.
Linear Representation: In Word2Vec, words are represented as vectors in a multi-dimensional space. The famous example is the vector arithmetic: King — Man + Woman ≈ Queen, illustrating how relationships between words can be captured as directions in this space.
Intentional and External Attributes
Intentional Attributes: In a statement like “Paris is the capital of France”, the intentional attributes are “Paris”, “capital”, and “France”, which define the relationship.
Extensional Attributes: In the same statement, the fact that Paris is the capital of France is the extensional attribute, representing the outcome of the relationship.
Neural Networks as Hash Tables
Imagine a neural network trained to identify landmarks. When it sees an image of the Eiffel Tower, it maps this image to a specific location in its geometric or vector space, much like how a hash table maps keys to values.
Algorithmic Generalization
Consider a Graph Neural Network learning to solve a maze. It generalizes the algorithm of finding the shortest path, applying it across various maze configurations.
Residual Streams in Transformers
In language translation, a Transformer might need to carry the gender of a pronoun through layers of processing to ensure correct translation. Residual streams help in preserving such crucial pieces of information through the layers.
Compositionality
A phrase like “The Colosseum is older than the Eiffel Tower” combines simpler concepts (the individual landmarks and the comparison of age) to express a more complex idea.
Models as Representations of Algorithms
When a model learns to play chess, it’s exploring a space of algorithms — different strategies for playing the game. The model’s understanding and representation of these strategies are critical to its performance in the game.
All the above examples illustrate how different frameworks and concepts delineate the way machine learning models process, represent, and generalize information, forming a semblance of ‘thought representation’ within their computational realms.
For now, that’s it; let’s meet soon in the next blog to throw more light on the topic of safe and explainable AI. Click here for Part 1.
This is in no way complete; we will discover far more interesting ideas and delve in more detail about this topic in much more detail. In the next blog, we will talk about superposition and understand grokking through interesting results.
Once again, Ethical AI and AI safety need 30 times more researchers than what we currently have. Developing safe AI is key to a better and sustainable future.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
And if you want to up your AI game, please check my new book on AI, which covers a lot of AI optimizations and hands-on code:





{kind=link}
{kind=link}
{kind=link}
{kind=link}