
Paper Review: Grokking-generalization and over-fitting
After the release of VGG16 in 2012, for the next few years, the networks became larger and larger. But in the last 2 years, we have seen a lot of trends of shrinking the networks be it the use of depth separable convolution or some other techniques. But let’s ask ourselves, why do we need to reduce the number of parameters of our current models? Given the advancements in nanofabrication technology, we can certainly keep pace with the advancements in the field of Deep Learning. One word answer to our question, OVERFITTING. The larger the model we make, the better chance it has of overfitting than actually learning the generalization behind the problem. Always remember, the goal of any deep learning architecture is not to learn a massive amount of data but to learn the underlying pattern. Once it has learned the pattern, it can easily handle many cases that it has not seen previously. So, without further ado, let’s jump into the GROKKING, and understand the behavior of small networks on specially crafted datasets.
The Grokking paper is a result of research at the OPEN AI labs, and it talks about something very important, generalization and over-fitting. The goal of the paper is to know about data efficiency, memorization, generalization, and speed of learning can be studied in great detail.
Long after severely overfitting, validation accuracy sometimes suddenly begins to increase from chance level toward perfect generalization. We call this phenomenon ‘grokking’.
Three key findings of the paper:
- In some situations neural networks learn through a process of “grokking” a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in generalization can happen well past the point of overfitting.
- Smaller datasets require increasing amounts of optimization (number of iterations) for generalization.
- Weight decay is particularly effective at improving generalization on the tasks we study.
Detailed overview
Let’s dig a little deeper into this wonderful paper, researchers of this paper showed that training networks on small algorithmically generated datasets in many cases can generate better generalization than the model trained on the naturally available data. This is not just limited to a small dataset as mentioned in the paper, because few other researchers showed that they got better face detection with face generated from GAN.
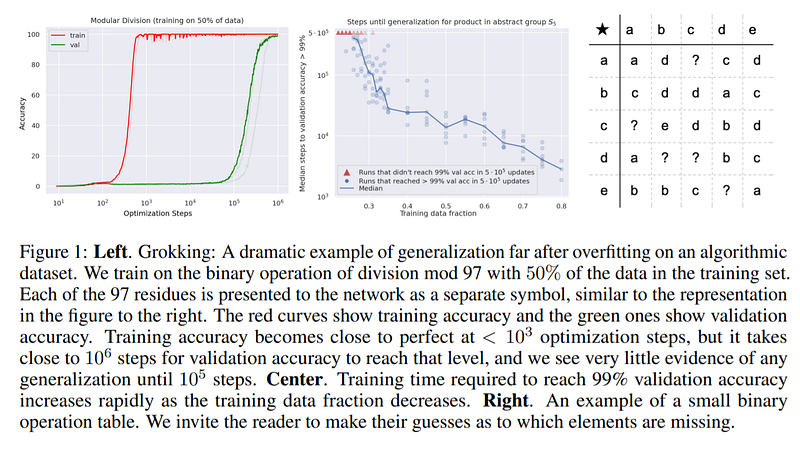
In the above figure, we see that a network was trained to do the binary operation of division modulo 97, training accuracy reached almost 100% before 10³ optimization steps but for validation, anything is moved till 10⁵, this shows that the network only reached true generalization only after 10⁶ optimizations. The datasets considered in the paper are binary operation tables of the form a ◦ b = c where a, b, c are discrete symbols with no internal structure and ◦ is a binary operation. Examples of binary operations include addition, the composition of permutations, and bivariate polynomials. Right image on the above figure is an example of the dataset being used. Distinct abstract symbols are used for all distinct elements a, b, c involved in the equations, thus the network is not aware of any internal structure of the elements, and has to learn about their properties only from their interactions with other elements. The network doesn’t see numbers in decimal notation or permutations in line notation.
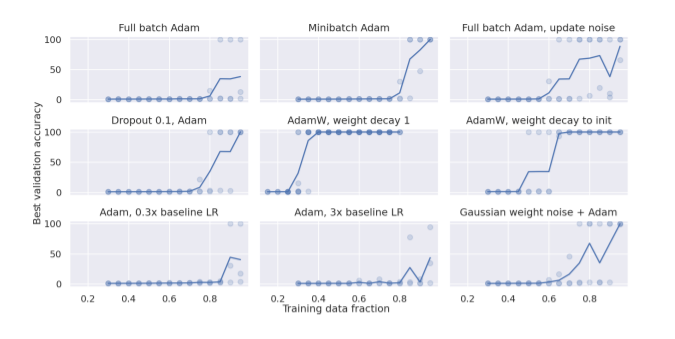
If we look at the above chart we can see that adding weight noise and decay factor helps achieve generalization quickly. Weight decay improves generalization the most, but some generalization happens even with full batch optimizers and models without weight or activation noise at high percentages of training data. Also, suboptimal choice hyperparameters severely limit generalization.
Other small thins they noted were that problems symmetric with respect to the order of the operands (x + y, x ∗ y, x² + y² and x² + x∗y + y²) are easy to generalize compared to non-symmetrical counterparts (x − y, x/y, x²+ x∗y + y² + x). It might be partially architecture-dependent since it’s easy for a transformer to learn a symmetric function of the operands by ignoring positional embedding.
Some operations (for example x³ + xy² + y (mod 97)) didn’t lead to generalization within the allowed optimization budget at any percentage of data up to 95%. The converged models effectively just memorized the training dataset without finding any real patterns in the data. To such a model, the data is effectively random.
There are a few other things like topology, for that you can click here for the original paper.
The goal of this blog post is to present the original paper in a simple and easy-to-read format and also give you the key takeaways in bullet points.
Thanks for giving your time and if you think that this blog added something to your knowledge base, please consider following the AIGuys Blog, and if you are interested to become a writer at AI guys you can follow this link.





