
A Detailed Look at Self-Attention and Transformers
A deep intuition behind Transformer architecture.
Attention, most of you already know about this or at least heard the term in the context of NLP and LLMs. After all, Attention Is All You Need has been one of the most groundbreaking papers in the entire AI field. All the LLMs are primarily built on this, even the newer multi-modal or vision-based models are using Attention in some way or the other. Yet, I find it quite surprising that a lot of people lack a sufficiently good understanding of Attention; why it was such a big deal, and how it achieved so many things in all the sub-fields of AI. In today’s blog, we will uncover all of this and build a simplistic understanding of Attention Mechanism.
Let’s simplify the Attention for everyone. But before we do that, let me ask you something, when you were learning a new subject, did you look back and forth to understand what was written in that line or paragraph? You were building a better context, that was the exact motivation to build the Attention mechanism.
Table of Contents
- The idea behind the Attention Mechanism and Reweighing Method
- Understanding Key, Query, and Value (Analogy and Technical Breakdown).
- Different Interpretations and Insights on Attention
- Transformer Architecture (Detailed Breakdown of Encoder, Positional Encoding, and Decoder)
- Challenges

The idea behind Attention
Reweighing is a method where you adjust the importance of data. Let’s use a simple classroom example to understand it. Imagine you have a class of students studying for a final exam. The final exam covers five subjects, each with an equal weightage of 20%. This means that all subjects are equally important for the final score.
Now suppose after analyzing past exams, one subject tends to be more difficult for students, and they usually score lower in that subject. To boost overall scores, you decide to spend more time on that difficult subject and less time on the others. In effect, you’re giving more weight to the difficult subject in your study schedule.
Now, let’s talk about the self-attention mechanism in the context of natural language processing (NLP) and how it uses the idea of reweighting.
Self-attention, also known as Transformer attention, is a component of the Transformer model, which has been used in many state-of-the-art models for NLP tasks, like BERT, GPT-3, and others.
Imagine you have a sentence: The cat chased its tail. The word its refers to The cat in this sentence. When processing this sentence, the self-attention mechanism in the Transformer model allows the model to associate its with The cat.
Here’s how it works:
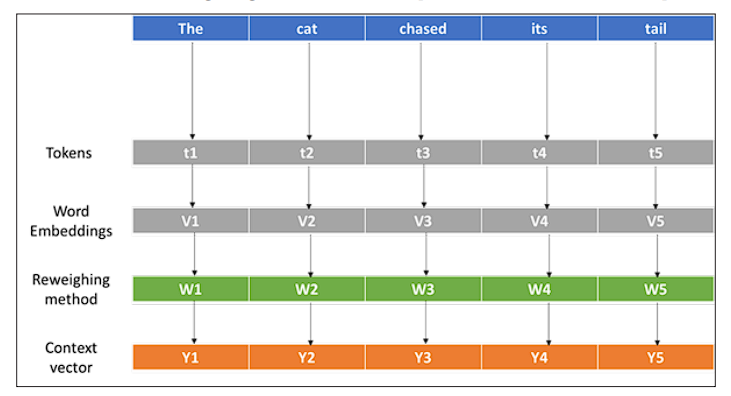
- Embedding: Each word in the sentence is first converted into a vector representation (or embedding).
- Attention Scores: The model then calculates attention scores. These scores determine how much focus should be on each word in the sentence when trying to understand a specific word. For instance, when trying to understand its, the model will put more attention (or weight) on The cat and less attention on the other words. This is the reweighing part.
- Context Vector: The attention scores are then used to create a weighted combination of the word vectors, resulting in a context-aware representation for each word. This means that the representation of its now contains information from The cat.
This process allows the model to understand the context and relationships between words in a sentence. The self-attention mechanism helps the model understand each word in isolation and the context of other words in the sentence. But the question now remains, how do we achieve this?
The below diagram shows the representation of the entire process.
Reweighing method in action
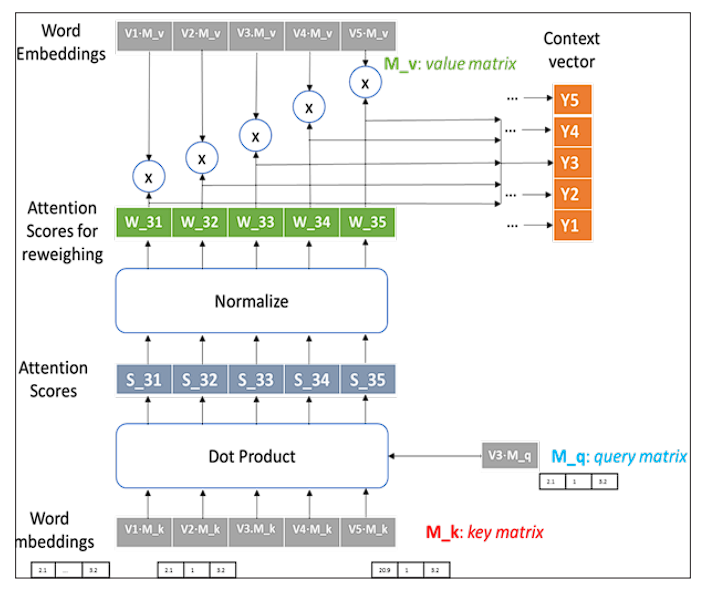
What are these W’s? How do we get these, and where is learning involved in all of this?
W1 = [w11, w12, w13, w14, w15]; …; …; W4 = [w41, w42, w43, w44, w45]
w11 = V1xV1; w12 =V1xV2; w13 = V1xV3; w14 = V1xV4; w15 = V1xV5
Here, we see how we are just doing basic maths and doing multiplication of the embedding vectors with each other and themselves. Small note here, we need to normalize the W1 vector. Let’s use this information to build upon our context vectors:
Y1 = w11xV1 + w12xV2 + w13xV3 + w14xV4 + w15xV5
…
Y5 = w51xV1 + w52xV2 + w53xV3 + w54xV4 + w55xV5
We used the initial embeddings of all the tokens, multiplied them with each other, and then used them to rescale the initial embedding vectors.
Is there anything more to it? Definitely, yes, we still haven’t made these trainable; right now, we are assuming the fixed, predetermined vectors here. Also, proximity has no influence here. This is the basic idea behind Self-Attention
Understanding Key, Query, and Value
The concepts of key, query, and value come into play in the context of the self-attention mechanism in Transformer models, which is used for tasks like understanding language.
Imagine you’re at a party full of people, and you’re trying to find your friend, Bob. In this scenario:
Query: This is you asking, “Where is Bob?” The query represents what you’re looking for.
Key: These are the name tags people are wearing. When you approach someone and look at their name tag, you compare your query “Bob” to the key (the name on their tag).
Value: This is the information or characteristics associated with each person. Once you find Bob (where the query matches the key), you gain access to all the value information about him, like his conversation, his outfit details, etc.
Now let’s apply this to Transformer models in the context of a sentence: The cat chased its tail.
Query: When processing the word its, the query is a representation of its.
Key: These are representations of all the other words in the sentence. The Transformer model compares the query to these keys to find matches.
Value: These are also representations of all the words in the sentence. The associated value is used in the output when a match is found between the query and a key.
In the self-attention mechanism of Transformers, for each word (like its in our example), the model creates a query, a key, and a value. It then calculates a score by comparing the query of the current word to the key of every other word. These scores are used to weigh the values (which is the information from each word) before summing them up to produce the final context-aware representation of the current word.
In simple terms, the Transformer uses these queries, keys, and values to figure out which words in the sentence are important to each other, helping it understand the context and meaning of each word.
Technical Breakdown
Let’s see this in the idea of keys, queries, and values in more detail.
- Embedding: Each word in a sentence is represented as a vector. For example, the sentence “The cat chased its tail” would involve converting each word into a vector representation, say:
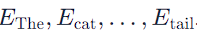
2. Generation of Query, Key, and Value Pairs: — For each word, the model generates Query (Q), Key (K), and Value (V) vectors. — This is done by multiplying the word’s embedding with three different weight matrices:
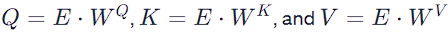
For the word “its”, we would have:
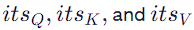
3. Score Calculation: — The attention score for each word pair is calculated. For instance, the score between “its” and another word in the sentence is calculated as:
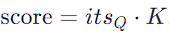
This score is a measure of the relevance of other words to the current word.
4. Softmax Function: — The scores are normalized using the Softmax function to convert them into probabilities, ensuring that their sum equals 1.
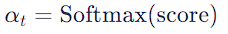
5. Weighted Sum: — The model then calculates a weighted sum of the Value vectors, using the Softmax scores as weights.
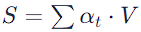
This sum represents the context-aware representation of the current word.
6. Repeat for All Words: This process is applied to each word in the sentence, ensuring that each word gets a new vector representing its context within the sentence.
7. Feed-Forward Neural Network: Finally, these context-aware vectors are processed through a feed-forward neural network for further processing.
Interpretations and Insights
- Geometric Interpretation: Think of each word as a point in a high-dimensional space. The transformation via Query, Key, and Value matrices can be thought of as rotating, scaling, or otherwise transforming these points to highlight their relational dynamics. - Probabilistic Interpretation: The Softmax function’s output can be viewed as the probability that each word is relevant to the context of the target word. This probabilistic framework allows for a nuanced understanding of word relationships in a sentence.
- Architectural Flexibility: The architecture of self-attention can, theoretically, exist without trainable weights.
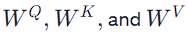
Do you know that even if we remove the above matrices, it still allows for a form of attention, albeit less sophisticated and lacking the ability to learn and adapt from data.
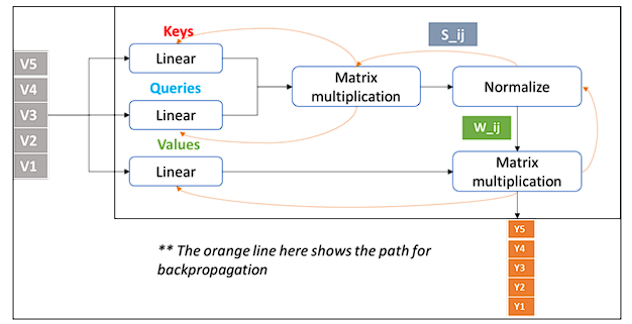
This self-attention mechanism allows the model to focus more on words that are relevant to the current word and less on words that are not relevant. For instance, when trying to understand its, the model can pay more attention to cat and less attention to chased or tail.
What we describe above is a single module of self-attention, but in reality, we always use multiple modules in parallel, called multi-head attention. The following diagram shows the architecture of multi-head attention. There is nothing new in multi-head attention, it’s just that this captures more context and can work better for longer sequences especially.
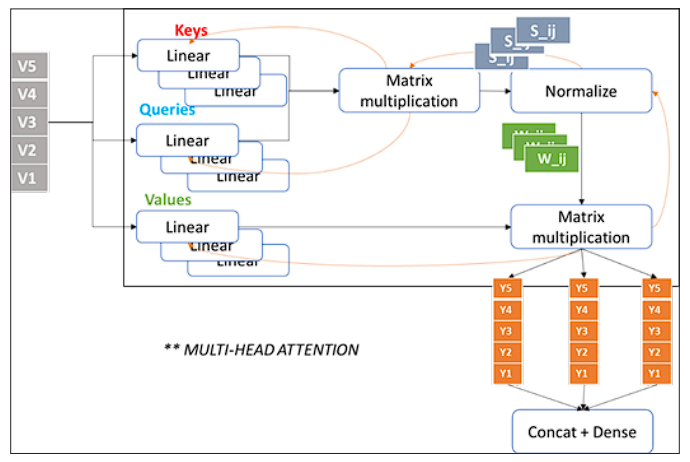
Transformer Architecture
I wasn’t able to find detailed mathematical explanations and context for the Transformer architecture in my current resources. However, I can provide a comprehensive overview using the information available and my existing knowledge.
The Transformer model is a breakthrough in handling sequential data, particularly in natural language processing tasks.
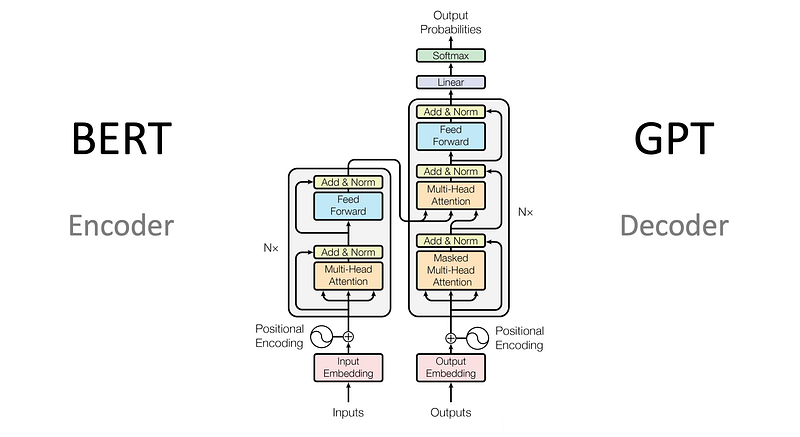
Encoder:
Each layer of the encoder contains two sublayers. The first is a self-attention mechanism implemented via multi-head attention, allowing the model to focus on different parts of the input sequence. The second sublayer is a feed-forward neural network. Each sublayer has its own set of weights and biases and includes residual connections and layer normalization for stability and efficiency.
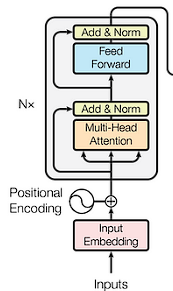
The integration of multi-head attention, normalization, and skip connections in the Transformer encoder represents a harmonious balance between the depth required to capture complex sequential relationships and the need for efficient, stable training. Multi-head attention expands the model’s focus, layer normalization maintains training stability, and skip connections ensure efficient information flow and gradient propagation. Collectively, these components enable the Transformer to learn rich, nuanced representations of sequential data, making it a powerful tool in various natural language processing tasks.
Positional Encoding:
Positional encodings are added to the input embeddings to provide information about the word order, as the model doesn’t inherently understand sequence order. Positional encoding is a very important bit of the entire Transformer puzzle.

Limitations of Linear Incremental Encoding:
- A straightforward approach to encode position might involve simply adding a unique number or incrementally increasing value to each position. However, this method poses a problem: as the sequence gets longer, the positional values continue to increase linearly, potentially leading to very large numbers that could adversely affect the training process and model stability.
- Additionally, linearly incremental encodings do not repeat, making it difficult for the model to generalize patterns across different positions in longer sequences.
Requirement for a Repeating, Yet Distinguishable Pattern:
- The Transformer model needed a positional encoding scheme that can accommodate sequences of variable and potentially very long lengths without leading to overly large values.
- It was essential that the encoding repeats in some fashion, so the model can recognize and generalize positional patterns even in long sequences. However, this repetition couldn’t be simple or periodic in a manner that makes different positions indistinguishable.
Solution with Sine and Cosine Functions:
- Sine and cosine functions address these requirements elegantly. These functions naturally repeat, but their combination can provide a unique encoding for each position due to their phase difference.
- For any two different positions, the pair of sine and cosine values will be distinct, even though each individual function repeats. This ensures that the model can differentiate between positions in the sequence.
- The wave-like nature of these functions means that the values stay bounded, avoiding the issue of increasingly large positional values.
Facilitating Relative Positioning:
- An additional advantage of using sine and cosine functions is their ability to facilitate the understanding of relative positioning, which is crucial in many language tasks. The model can infer the distance between positions based on the pattern of sine and cosine values, enhancing its ability to interpret and process the sequence meaningfully.
Read this to learn more about positional encoding: here
Decoder
The design of the Transformer decoder, including its receipt of inputs from both the encoder and a shifted version of its own output, is pivotal for its functioning in sequence-to-sequence tasks, such as translation. Let’s expand on the roles and reasons behind this architecture:
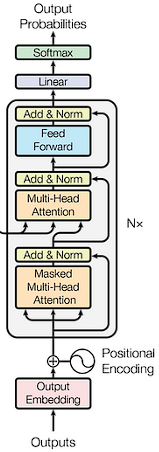
Decoder’s Layered Structure
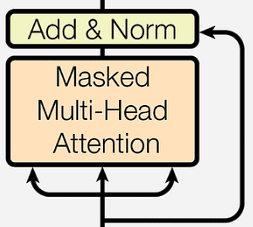
- First Sublayer — Masked Multi-Head Attention: — The decoder’s first sublayer is a masked multi-head attention mechanism, ensuring that each position can only attend to earlier positions in the output sequence. This masking prevents positions from attending to subsequent positions, which is crucial in generation tasks where the future tokens are not yet known. — This design simulates the sequential generation of output, where each word is predicted based on the preceding words, mirroring how humans generate language.
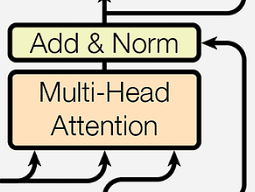
2. Second Sublayer — Multi-Head Self-Attention: — The second sublayer, similar to the encoder, implements multi-head self-attention. However, unlike the encoder, this layer receives an additional input: the output from the encoder. — This mechanism allows the decoder to focus on different parts of the input sequence (as processed and encoded by the encoder) while generating each word in the output sequence. It helps the decoder to align the output with relevant parts of the input sequence, which is especially important in tasks like machine translation where alignment between source and target sequences is crucial.
3. Third Sublayer — Feed-Forward Network: — The third sublayer in each decoder layer is a feed-forward neural network, which applies further transformations to the data.
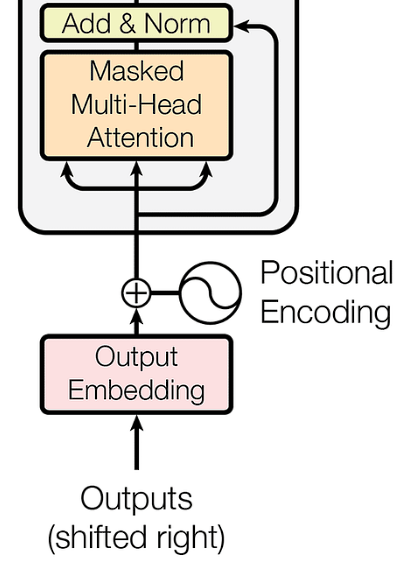
Shifted Output as Input: The input to the decoder is a “shifted” version of the output sequence. In training, since the target sequence is known, the decoder is provided with this sequence shifted by one position. This shift means that the prediction of each word is conditioned on the preceding words. - During inference, where the target sequence is not known, the decoder generates one word at a time, conditioned on the previously generated words. This mimics the training condition and provides a coherent and contextually relevant generation process.
Integration with Encoder Output: The decoder’s attention mechanism that integrates the encoder’s output allows it to understand which parts of the input sequence are relevant at each step of generating the output sequence. This is particularly important in tasks where the relationship between the input and output sequences is not one-to-one but rather more complex (e.g., summarization, translation).
By attending to the encoder’s output, the decoder can effectively “choose” which parts of the input sequence it needs to focus on to generate the next word in the output sequence.
In conclusion, the Transformer decoder’s design, with its masked multi-head attention, integration of the encoder’s output, and the use of shifted output for predictions, is a sophisticated mechanism that allows for effective and contextually aware generation of sequential data. This design ensures that the decoder not only generates grammatically and semantically coherent sequences but also maintains relevance and accuracy concerning the input sequence.
Mathematically, the core of the Transformer’s self-attention mechanism can be described as:

The Transformer’s ability to process elements of the input sequence in parallel, as opposed to the sequential processing in RNNs, significantly improves training efficiency and model performance. This architecture forms the basis for many state-of-the-art models in NLP, like BERT, GPT-4, Llama and others.
Challenges
1. Scalability: Transformers have a quadratic relationship between the sequence length and computation, primarily due to self-attention mechanisms. Longer sequences require significantly more computational resources, making it challenging to apply them to tasks with very long inputs.
2. Large Memory Footprint: Transformers require substantial memory, especially for models with a large number of parameters. This can be a limiting factor for deployment on devices with limited memory, like mobile phones or edge devices.
3. Attention Overhead: Self-attention involves computing pairwise interactions between all tokens in a sequence. This results in high computational complexity, making it less efficient for very long sequences.
4. Overfitting: Transformers, especially large ones, are prone to overfitting, especially when trained on small datasets. Regularization techniques are often required to mitigate this issue. Transformers often require large amounts of data for training, which may not be readily available for all tasks or languages. Few-shot or zero-shot learning with Transformers is an area of active research.
5. Interpretability: The attention mechanism in Transformers can be challenging to interpret. Understanding why the model attends to specific parts of the input can be crucial for certain applications but remains an ongoing research challenge.
6. Fine-tuning Complexity: Fine-tuning a pre-trained Transformer model for specific tasks can be complex and require careful hyperparameter tuning.
In conclusion, while Transformers and attention mechanisms have revolutionized various AI tasks, they come with their set of challenges, primarily related to scalability, efficiency, and interpretability. Researchers and practitioners are actively working on addressing these issues and exploring alternative architectures to overcome these limitations.
Thanks for reading. If you like this type of content check my Newsletter-





