
Giving self-reflection capabilities to LLMs
By now, everyone would have used ChatGPT or some other LLMs. ChatGPT is great, but it still hallucinates, especially with complex problems. LLMs hold tremendous power, but most of us cannot utilize it to the full extent. The way we prompt can completely change the response. Usually, ChatGPT tries to give politically correct and generalized answers, often lacking nuance and a lot of verbiage. A verbiage is a sentence or paragraph that has a lot of words but doesn’t make any specific point. It is not that ChatGPT can’t answer nuance, but it needs specific instruction to do so. Let’s see how to solve the problem of nuance and how to make it better at responding to complex queries.

Problems with LLMs
There are basically five major problems with ChatGPT or other LLMs.
- They give a very generalized response, often lacking nuance. At times, it repeats itself.
- There is a lot of verbiage and unnecessary words that don’t say anything.
- They often try to tell things politically correctly and can’t make good arguments from a given worldview.
- It hallucinates and often gets things wrong with complex problems that might require the answer to be spoken in more than 8k or 16k tokens.
- Runs out of memory to store the relevant context for the given problem.
Why do LLMs Hallucinate?
No one truly knows why LLMs hallucinate; people have different hypotheses and explanations, but none of them could be theoretically proved right or wrong.
Often in my experiment, it will miss out on the important context, and when you tell it that you missed out on this, it corrects its response and produces much better results.
Some hypotheses say that it needs time to think about its response to generate a better response. Let it think for a moment, let it generate the text in an uninterrupted way, do some self-reflection, and then it can finally produce much better results. This strategy basically allows LLMs to think about sub-topics individually and later on combine them in a much more comprehensive way rather than directly writing a nuanced solution to a given problem. The idea is that when it considers a problem as a subset of subproblems, it uses a different set of activations compared to solving it in one go.
Now you might say, all of this sounds cool but how do we actually go on and make LLMs self-reflect?
Making LLMs capable of self-reflection
There have been quite a few strategies to give LLMs self-reflection capability. It is primarily done by saving the relevant contextual information.
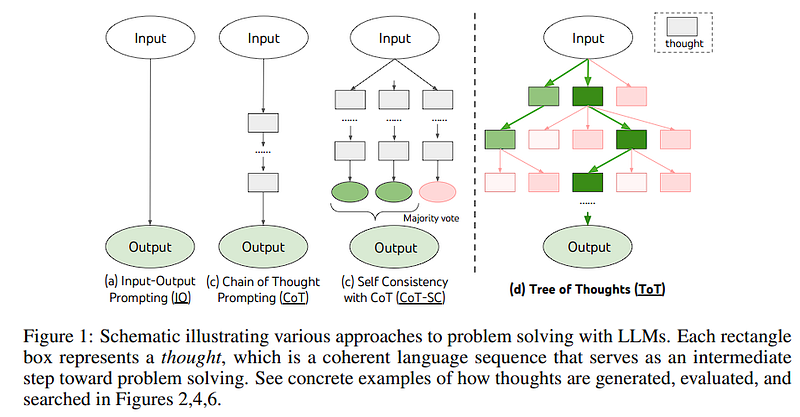
The above image shows how we make our ChatGPT or LLM smart. Let’s talk about each one of them, starting from the left.
The most basic way to use ChatGPT is to ask a question, and in response, it will write a small paragraph in return.
But with slightly better prompting, we can ask to give responses in a proper format. For instance, we can ask it to produce all the output in JSON format or Yes/No format. This is the most basic way to control the output of LLMs.
Next comes the Chain of Thought. The idea is that whatever we are asking, let a summary of that be stored in a db, and when you ask the question next time, we give all the previous summaries along with our query as context. This might help you to choose whatever is necessary to solve a particular task. Generally, ChatGPT has some memory built into it, but its relevance decreases as we keep asking more and more questions. Now, it’s possible that you need more context from your first question rather than your last five queries to solve something. The best example of a Chain of thoughts is a PDF chatbot; before asking questions to chatGPT about a specific PDF, we first pull up all the relevant context using other NLP techniques and then use it as context.
The next idea is Self-consistency combined with Chain of thoughts. It is similar to COT; the primary difference is that we generate several responses for the same subproblem parallelly; we generate new responses for each sub-response, and at last, we do a majority vote, choosing a better strategy to solve the given problem. In this way, we explore novel paths to solve a complex problem.
Next, we have a very interesting idea coming from the Tree of Thoughts paper.
We put our query in the root node, and in the child node, we break our problems into sub-problems. We generate a subset of strategies for each subproblem, and each strategy is ranked and put up in a tree structure. Now, we use BFS or DFS to navigate this tree of thoughts; we use the best path to generate a solution to our complex problem. Note it is not trivial to put this in action; designing this type of system can be quite complex.
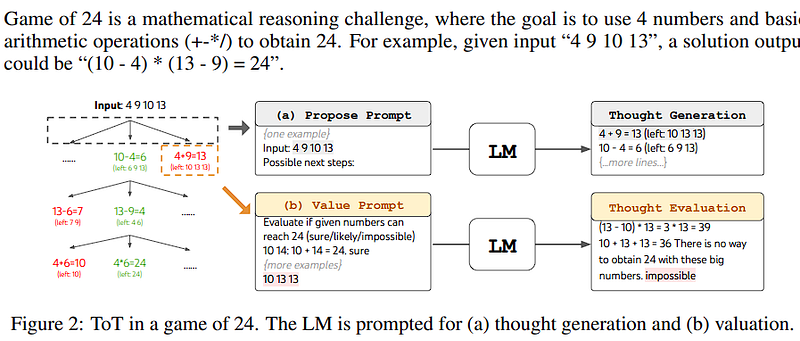
Here’s a simpler version of the text you provided:
Setting Up the Task: - Gather data from a website called 4nums.com. - This site has 1,362 games that people have ranked from easy to difficult. - We only look at games ranked from 901 to 1,000 because they’re harder. - We’re trying to see if the computer can come up with a math equation from the game numbers that equals 24. - We check 100 games and then tell you how well the computer did.
How We Test: - We start with a basic way of giving the computer the game numbers and see if it can solve it. We give it 5 practice rounds. - Then, we try a method where we give the computer some hints. For the game “4 9 10 13”, the hints are: — First, subtract 9 from 13. You get 4. — Then, subtract 4 from 10. You get 6. — Finally, multiply 4 by 6. You get 24. - We test both methods 100 times to see which one works better. - We also try another method where we let the computer guess and check its work up to 10 times.
A Different Approach (ToT Setup): - We think of the Game of 24 in steps, like making three math moves. - At each step, we look at the numbers left and give the computer some options. - We go through these options one by one (like going level by level in a video game). - We also ask the computer to think ahead: can this option lead to an answer of 24? - The computer labels each option as “sure”, “maybe”, or “impossible”. - We do this step 3 times for each game number.
At last, we have a brand new paper called Algorithms of Thoughts.
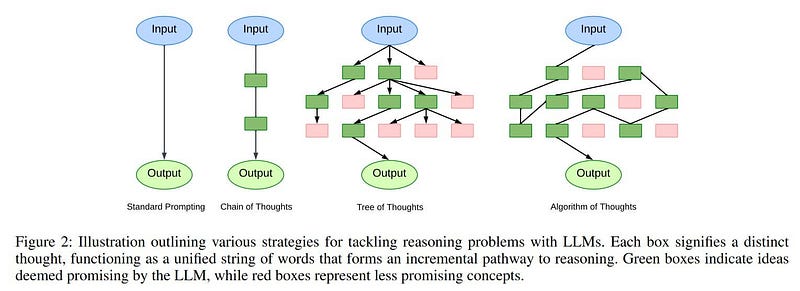
The idea behind this new paper is the same as Tree of Thoughts but with the primary difference in how the context is saved. In Tree of Thoughts, we use Tree-based Data structure but here we use graph-based structure, thus giving us a much better way to navigate all the knowledge graph than using simple BFS or DFS. Another advantage is that the Algorithm of Thoughts uses far fewer prompts to LLM to achieve similar results.
NOTE: The number of prompts required to run Tree of Thoughts can scale up very rapidly, theoretically ending up creating an infinite tree, there must be some hard limit put on how long the Tree of Thoughts can grow up.
The below diagram shows how the Algorithm of Thoughts works on the game of 24.
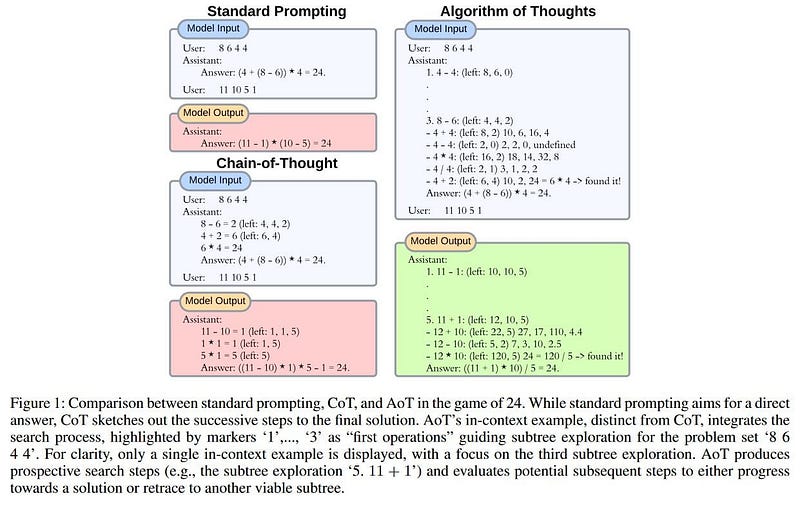
Conclusion
Now, I know that this doesn’t solve the problem of hallucinations or other problems we have mentioned above. But all these strategies surely make these problems appear much less compared to simple prompting.
Implementing either Tree of Thoughts or Algorithms is beyond the scope of this blog. But here’s another resource that talks about the same from the implementation point of view.
If this brings value to you, please follow me for such wonderful articles. Thanks for your time and patience, Happy learning ❤




