
Implementing Reasoning Algorithms Using GPT-3 (Chain of Thoughts, Tree of Thoughts…)

Reasoning algorithms often stand out as one of the most intriguing and sophisticated areas of research. With the rise of powerful models like OpenAI’s GPT-3, there has been a profound shift in how we approach complex problem-solving and logical reasoning tasks. Beyond mere text generation, GPT-3 showcases the potential to simulate intricate ‘thought processes’, much akin to a human’s chain or tree of thoughts. This article delves into the intricacies of implementing reasoning algorithms using GPT-3, exploring its ability to emulate human-like patterns of thought and providing insights into how one might harness this capability for various applications. Whether you’re a machine learning aficionado or someone simply curious about the confluence of AI and human reasoning, prepare to embark on a journey into the cognitive mechanics of one of the most advanced models in the AI landscape.
Reasoning: Theoretical Foundations and Functionality
Reasoning, at its core, refers to the cognitive process of drawing conclusions or making inferences from available information. It’s the mechanism through which humans (and some advanced AI models) process information, connect disparate ideas, and derive new knowledge. While it is an intricate and multi-faceted phenomenon, a broad theoretical understanding can be outlined through its primary types and foundational principles.
Types of Reasoning:
1. Deductive Reasoning: This is a top-down approach where one starts with a general principle or premise and moves towards a specific conclusion. If the premises are true and the deductive process is valid, then the conclusion is guaranteed to be true. A classic example is: — All men are mortal. — Socrates is a man. — Therefore, Socrates is mortal.
2. Inductive Reasoning: This is a bottom-up approach where one observes specific instances and tries to derive general principles or rules from them. While it can’t guarantee the truth of the conclusion, it can suggest a plausible outcome. An example might be observing that the sun rises every day and then concluding that the sun will rise tomorrow.
3. Abductive Reasoning: This involves creating the best possible explanation for a set of observations. It’s essentially an educated guess. For instance, if you see wet streets, you might infer that it rained.
4. Analogical Reasoning: This involves drawing parallels between two situations based on their similarities. For example, if you know how a specific business model works in the automobile industry, you might use that knowledge to understand its application in the bicycle industry, assuming there are analogous factors at play.
How Reasoning Works:
1. Information Acquisition: The first step involves obtaining data or premises from perception, memory, or external sources. 2. Processing: This is where the cognitive machinery or algorithms come into play. The brain (or an AI system) processes the information using patterns, heuristics, or logical operations. 3. Conclusion Derivation: Based on the processed information, a conclusion or inference is drawn.
4. Evaluation: Especially in complex reasoning tasks, there’s an iterative process where the derived conclusion is evaluated, refined, or even rejected based on its coherence with other known facts or principles.
Chain of Thought Reasoning for Large Language Models
Chain of thought are a series of intermediate reasoning steps which, as recent research suggests, can substantially amplify the reasoning capabilities of LLMs. The concept is highlighted in a study titled “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” by researchers Jason Wei, Xuezhi Wang, among others.
Central Premise: The central thesis of the study revolves around the idea that producing a chain of thought — a sequence of logical steps that connects an initial problem to its solution — can greatly bolster the complex reasoning abilities of LLMs. This phenomenon is not merely an added layer but seems to emerge organically in adequately extensive language models.
Methodology: Chain-of-Thought Prompting: This unique methodology involves a process wherein a select few “chain of thought” demonstrations are provided as benchmark examples during the prompting phase. It’s a straightforward technique but has profound implications. By leveraging these exemplars, the language models can generate intricate reasoning pathways, often mimicking human-like thought processes.
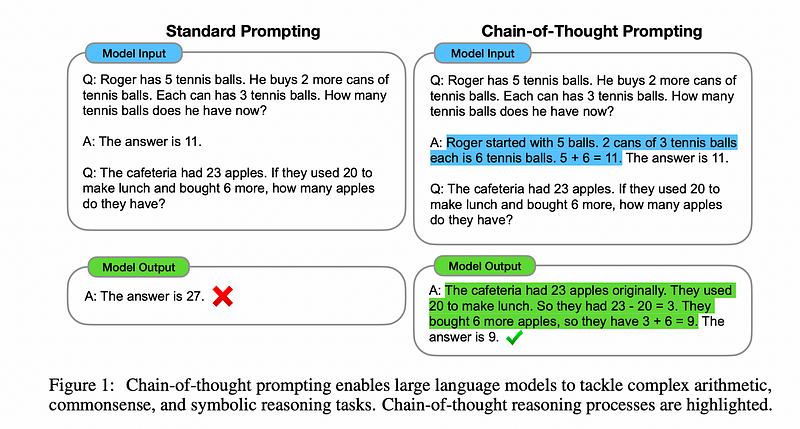
Achieving consistent and accurate reasoning can be a challenge with LLMs like GPT-3, because they do not always give the same answer to the same question. The “chain of thoughts” method, combined with self-consistency, offers a novel way to address this. Let’s delve into its implementation.
I first created a simple wrapper around OpenAI API’s. The goal of the wrapper is to simplify how I get outputs from GPT-3:
import openai
import time
class LLM:
def __init__(self, api_key, model="gpt-3.5-turbo", temperature=0.5):
self.api_key = api_key
self.model = model
self.temperature = temperature
openai.api_key = self.api_key
def generate_text(self, prompt, n_completions=1, max_tokens=None):
retry_delay = 0.1 # initial delay is 100 milliseconds
while True:
try:
params = {
"model": self.model,
"messages": [
{
"role":"system",
"content": "You are a helpful assistant."
},
{
"role":"user",
"content": prompt
}
],
"temperature": self.temperature,
"n": n_completions
}
if max_tokens is not None:
params["max_tokens"] = max_tokens
response = openai.ChatCompletion.create(**params)
# Extract the 'choices' from the dictionary
choices = response["choices"]
# Get the 'content' of each choice and store it in a list
responses = [choice["message"]["content"] for choice in choices]
return responses
except openai.error.RateLimitError as err:
# If we hit the rate limit, wait for the specified delay and try again
print(f"Hit rate limit. Retrying in {retry_delay} seconds.")
time.sleep(retry_delay)
retry_delay *= 2 # double the delay each time we hit the rate limit
except Exception as err:
print(f"Error: {err}")
breakThen I imported the necessary modules: the custom gpt_wrapper which houses the LLM class or function, the OPENAI_API_KEY from the apikey module for authentication, and the List type from the typing module to ensure proper type hinting.
After setting up the groundwork, I initialized an instance of the LLM using the API key. This step is pivotal, bridging the connection to the GPT model and making it ready for our inquiries.
To better structure the response selection, I devised the voter function. Its role is to take a list of responses and the original problem as parameters. By crafting a prompt around these inputs, it delegates the task to the LLM, asking it to decide on the most suitable answer from the given responses.
Building on this, I established the solver function, which acts as the heart of our problem-solving process. It first instructs the LLM to generate five different completions of an input problem. With these options in hand, it summons the voter function to sieve out the best response. Finally, the top answer, found at the beginning of the response list, is chosen as the solution.
from gpt_wrapper import LLM
from apikey import OPENAI_API_KEY
from typing import List
llm = LLM(api_key=OPENAI_API_KEY)
def voter(responses: List[str], problem) -> str:
prompt = f"""
Given the following list of responses: {responses} for the
following user input: {problem}. craft a response. """
return llm.generate_text(prompt)
def solver(initial_input: str) -> str:
responses = llm.generate_text(initial_input, n_completions=5)
response = voter(responses, initial_input)
return response[0]
# Set the problem
problem = """Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?"""
solution = solver(problem)
print(problem)
print(solution)Here is the solution provided by the LLM:
A: The cafeteria started with 23 apples. They used 20 for lunch, so they have 23–20 = 3 apples left. Then they bought 6 more apples, so they now have 3 + 6 = 9 apples. The answer is 9.
This experiment made me strongly believe that providing “in context” learning really is a powerful prompting technique. It also convinced me on the importance of self consistency as a way to mitigate LLM hallucinations.
But I still noticed that LLM are not good at certains tasks, like complex multiplication. It is useful in that case to give LLMs the ability to use external modules for calculations for example. I will write an article about how to do that in the future.
Attempts to Create a General Tree of Thoughts Algorithm
I then embarked on the ambitious project of constructing a ‘Tree of Thoughts’ algorithm. The essence of this mechanism is to derive a structured process, similar to that of traditional tree-based algorithms in computer science, to guide the model through an interconnected web of thoughts. The hope was that this systematic navigation could enable more consistent and nuanced reasoning capabilities.
Structuring Thought States
To represent individual nodes in our tree, the ThoughtState class was designed. Every state contains the original problem or input (initial_input) and an evolving sequence of thoughts (sequence_of_thoughts). This sequence aims to trace the logic progression the model follows. Conveniently, the __lt__ method allows us to compare states based on the length of their thought sequences, and the __repr__ method provides a neat way to visualize these states.
Generating and Evaluating Thoughts
Two crucial components of this framework are the ThoughtGenerator and the StateEvaluator classes. The former focuses on generating potential next steps or "thoughts" based on the current state. By juxtaposing the original problem and the most recent thought, the generator seeks the next logical progression and also executes that thought, appending the results. The latter class, StateEvaluator, assesses the value of these thought sequences. Using the language model, it gauges the relevance and coherence of a sequence in addressing the initial problem, returning a simple 1-10 integer rating.
The Tree of Thoughts Algorithm
Armed with the tools to generate and evaluate thoughts, I conceptualized the TreeOfThoughts class to harness these utilities for structured reasoning. Two search strategies are outlined: Breadth-First Search (BFS) and Depth-First Search (DFS). In the BFS approach (run_bfs), I started with the initial state and progressively expanded it with potential next-step thoughts. At each step, states are evaluated, and the most promising ones, based on the set breadth_limit, are taken to the next iteration. This process iteratively refines and prunes the tree of thoughts. The DFS approach (run_dfs), meanwhile, dives deep into a single thought sequence, only branching when it encounters a thought with high evaluative value.
from typing import List, Set
from gpt_wrapper import LLM
from apikey import OPENAI_API_KEY
class ThoughtState:
def __init__(self, initial_input: str, sequence_of_thoughts: List[str]):
self.initial_input = initial_input
self.sequence_of_thoughts = sequence_of_thoughts
def __repr__(self) -> str:
thoughts_str = "\n".join(
f"{i+1}. {thought}"
for i, thought in enumerate(self.sequence_of_thoughts))
return f"Initial input: {self.initial_input}\nThoughts:\n{thoughts_str}"
def __lt__(self, other):
return len(self.sequence_of_thoughts) < len(other.sequence_of_thoughts)
class ThoughtGenerator:
def __init__(self, language_model: LLM):
self.language_model = language_model
def execute_thought(self, thought: str) -> str:
# Assume the thought is a prompt for the executor language model
try:
result = self.language_model.generate_text(f"Do this {thought}")[0]
except Exception as e:
print(f"Error executing thought: {e}")
result = None
return result
def generate_thoughts(self, current_state: ThoughtState,
number_of_thoughts: int) -> List[str]:
# Extract initial input and the last thought
initial_input = current_state.initial_input
last_thought = current_state.sequence_of_thoughts[
-1] if current_state.sequence_of_thoughts else "no thought yet"
# Construct the prompt
prompt = f"Initial request: {initial_input}. Last thought: {last_thought}. Think step by step. What is the next step to solve the initial request? If no next step reply 'stop thinking'"
# Generate the response
responses = self.language_model.generate_text(
prompt, n_completions=number_of_thoughts)
# Execute each thought using the executor language model, adding the result to the thought
for i, thought in enumerate(responses):
result = self.execute_thought(thought)
responses[i] = f"{thought}. Result: {result}"
# Return only the specified number of thoughts
return responses
class StateEvaluator:
def __init__(self, llm: LLM):
self.language_model = llm
# self.language_model.model = "gpt-4"
def evaluate_states(self, states: Set[ThoughtState]) -> dict:
evaluation_results = {}
for state in states:
# Prepare prompt
prompt = f"{str(state)} Rate this sequence of thoughts from 1 to 10 (integer) based on its ability to respond in a satisfying way to {state.initial_input}. Only provide the rating and nothing else."
response_list = self.language_model.generate_text(prompt,
max_tokens=5)
if response_list is not None:
response = response_list[0]
else:
response = 1
# We'll assume that the response from the model is just a number from 1 to 10.
# In a more robust application, you would probably want to add some error checking here.
print("rate", response)
try:
rating = int(response)
except ValueError:
print(
f"Warning: Could not parse rating '{response}' for state '{state}'. Defaulting to 1."
)
rating = 1
evaluation_results[state] = rating
return evaluation_results
class TreeOfThoughts:
def __init__(self, language_model: LLM, number_of_thoughts: int,
max_steps: int, breadth_limit: int, value_threshold: float):
self.language_model = language_model
self.number_of_thoughts = number_of_thoughts
self.max_steps = max_steps
self.breadth_limit = breadth_limit
self.value_threshold = value_threshold
def run_bfs(self, initial_input: str) -> List[str]:
thought_generator = ThoughtGenerator(self.language_model)
state_evaluator = StateEvaluator(self.language_model)
current_states = {ThoughtState(initial_input, [])}
for i in range(1, self.max_steps + 1):
next_step_states = {
ThoughtState(state.initial_input,
state.sequence_of_thoughts + [thought])
for state in current_states
for thought in thought_generator.generate_thoughts(
state, self.number_of_thoughts)
}
evaluation_values = state_evaluator.evaluate_states(
next_step_states)
current_states = set(
sorted(next_step_states,
key=evaluation_values.get,
reverse=True)[:self.breadth_limit])
# print the current states at each step
print(f"Step {i}:")
for state in current_states:
print(state)
print("\n")
# Calculate evaluation values for all states
evaluation_values = state_evaluator.evaluate_states(current_states)
# Get the state with the maximum evaluation value
best_state = max(current_states, key=evaluation_values.get)
# Generate thoughts for the best state
return thought_generator.generate_thoughts(best_state, 1)
def run_dfs(self, current_state: ThoughtState, current_step: int) -> List[str]:
thought_generator = ThoughtGenerator(self.language_model)
state_evaluator = StateEvaluator(self.language_model)
if current_step > self.max_steps:
return thought_generator.generate_thoughts(current_state, 1)
for thought in thought_generator.generate_thoughts(current_state, self.number_of_thoughts):
next_state = ThoughtState(current_state.initial_input, current_state.sequence_of_thoughts + [thought])
if state_evaluator.evaluate_states({next_state})[next_state] > self.value_threshold:
return self.run_dfs(next_state, current_step + 1)
return []
# Initialize the LLM
llm = LLM(OPENAI_API_KEY)
# Initialize the TreeOfThoughts
tree_of_thoughts = TreeOfThoughts(language_model=llm,
number_of_thoughts=2,
max_steps=10,
breadth_limit=5,
value_threshold=7.0)
# Set the problem
problem = "Game of 24 with these 4 numbers: 1, 3, 4, 6"
current_state = ThoughtState(problem, [])
# Run the BFS
solution = tree_of_thoughts.run_dfs(current_state, 1)
# Print the solution
print("############################################################")
print(solution)Reflections on the Approach
Executing this framework using a math game, the “Game of 24”, demonstrated the method’s viability. The DFS search was applied, which recursively evaluated and expanded upon thought sequences to derive a potential solution.
However, a key takeaway from this exploration was that the ‘Tree of Thoughts’ approach introduced substantial complexity without necessarily delivering proportionate gains in reasoning quality. While the method holds conceptual appeal, I found that it was less dependable than the simpler ‘Chain of Thoughts’ methodology. The intricacies involved in crafting a dynamic tree of interconnected thoughts can sometimes lead to convoluted or inconsistent reasoning paths. Moreover, the success of this approach hinges critically on devising a deterministic state evaluator tailored to the specific problem domain, which can be a challenging feat. In summation, while it offers an innovative perspective on structured reasoning with language models, the Tree of Thoughts method might not always be the optimal choice.




