
Solving Production Issues In Modern RAG Systems-I
LLMs are great, but can we use them to answer our queries on our private data? This is where the Retrieval Augmented Generation or RAG comes in. RAG usage has been growing rapidly as most companies have a lot of proprietary data and they want their chatbots or other text-based AI to be specific to their company. RAG is a very interesting use case of LLMs, they are in direct competition with the increasing context length of LLMs, and I don’t know which one out of these two will prevail. But I’m positive that a lot of techniques that are developed to create better RAGs will be used in future systems, RAG might or might not be gone in a few years, but a few interesting techniques might inspire the next generation of systems. So, without further ado, let’s look into the details of creating next-generation AI systems.
Table of Contents
- What is RAG?
- Building a basic RAG Pipeline
- Overall Challenges
- 9 Challenges and Solutions to Modern RAG Pipelines
- Scalability
- Conclusion
What is RAG?
Simply put, RAG is the technique to put additional context for our LLMs to generate better and more specific responses. LLMs are trained on the publicly available data, they are really intelligent systems, yet they can’t answer our specific questions, because they lack the context to answer those queries. With RAG, we provided the necessary context, so that we can optimize the use of our awesome LLMs.

In case if you want a refresher on LLMs, please check out this article:
RAG is a way to insert new knowledge or capabilities into our LLMs, though this knowledge insertion is not permanent. Another method to add new knowledge or capabilities to LLMs is through Fine Tuning LLMs to our specific data.
Adding new knowledge through fine-tuning is quite tricky, tough, expensive, and permanent. Adding new capabilities through fine-tuning even impacts the previous knowledge it had. During fine-tuning, we can't control which weights will be changed and thus which capability will increase or decrease.

Now, whether we go for fine-tuning, RAG or a combination of both depends totally upon the task at hand. There is no one fit for all.
Building a basic RAG Pipeline
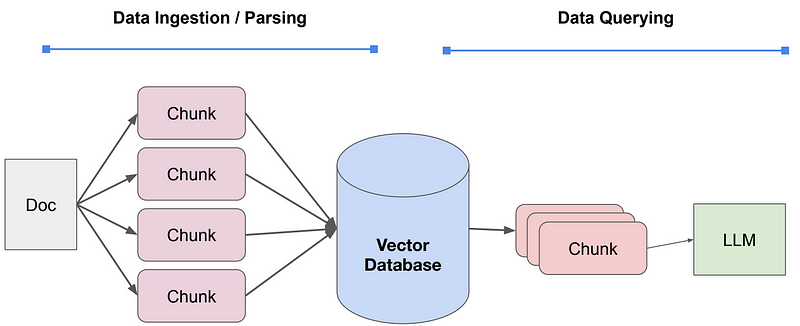
Process:
- Split up documents) into even chunks.
- Each chunk is a piece of raw text.
- Generate embedding for each chunk (e.g. OpenAl embeddings, sentence_transformer)
- Store each chunk in a vector database.
- Find the Top-k most similar chunks from the vector database collection
- Plug into the LLM response synthesis module.
!pip install llama-index
# My OpenAI Key
import os
os.environ['OPENAI_API_KEY'] = ""
import logging
import sys
import requests
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from IPython.display import Markdown, display
# download paul graham's essay
response = requests.get("https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1")
essay_txt = response.text
with open("pg_essay.txt", "w") as fp:
fp.write(essay_txt)
# load documents
documents = SimpleDirectoryReader(input_files=['pg_essay.txt']).load_data()
index = VectorStoreIndex.from_documents(documents)
# set Logging to DEBUG for more detailed outputs
query_engine = index.as_query_engine(similarity_top_k=2)
response = query_engine.query(
"What did the author do growing up?",
)
print(response.source_nodes[0].node.get_text())The above code shows how to make a simple RAG pipeline. We just loads an essay, chunk it, and use the llama-index library to create a Naive RAG pipeline.
Naive RAG approaches tend to work well for simple questions over a simple, small set of documents. ● “What are the main risk factors for Tesla?” (over Tesla 2021 10K) ● “What did the author do during his time at YC?” (Paul Graham essay)
But real life is rarely this simple. So, in the next section let’s look at the challenges and possible remedies. And later on, define the future of such systems.
Overall Challenge
But before we look at each pain point let’s define overall challenges. AI systems are quite different from current software systems.
AI-powered software is defined by a black-box set of parameters. It is really hard to reason about what the function space looks like. The model parameters are tuned, and the surrounding parameters (prompt templates) are not.
If one component of the system is a black box, all components of the system become black boxes. The more components, the more parameters we have to tune. Every parameter affects the performance of the entire RAG pipeline. Which parameters should a user tune? There are too many options!
Bad Retrieval
- Low Precision: Not all chunks in the retrieved set are relevant — Hallucination + Lost in the Middle Problems
- Low Recall: Now all relevant chunks are retrieved. — Lacks enough context for LLM to synthesize an answer
- Outdated information: The data is redundant or out of date.
Bad Response Generation
- Hallucination: The model makes up an answer that isn’t in the context.
- Irrelevance: The model makes up an answer that doesn’t answer the question.
- Toxicity/Bias: The model makes up an answer that’s harmful/offensive.
So, the best practice is to categorize our RAG pipeline with specific pain points and address them individually. Let’s look at the specific problems and their solution in the next section.
9 Challenges and Solutions to Modern RAG Pipelines
Response Quality Related
1. Context Missing in the Knowledge Base 2. Context Missing in the Initial Retrieval Pass 3. Context Missing After Reranking 4. Context Not Extracted 5. Output is in the Wrong Format 6. Output has an Incorrect Level of Specificity 7. Output is Incomplete
Scalability
8. Can’t Scale to Larger Data Volumes 9. Rate-Limit Errors
Recently there was a paper called Seven Failure Points When Engineering a Retrieval Augmented Generation System that talked about why it is so hard to create a production level RAG. Today, we are looking at these engineering challenges and trying to come up with a new innovative approach.
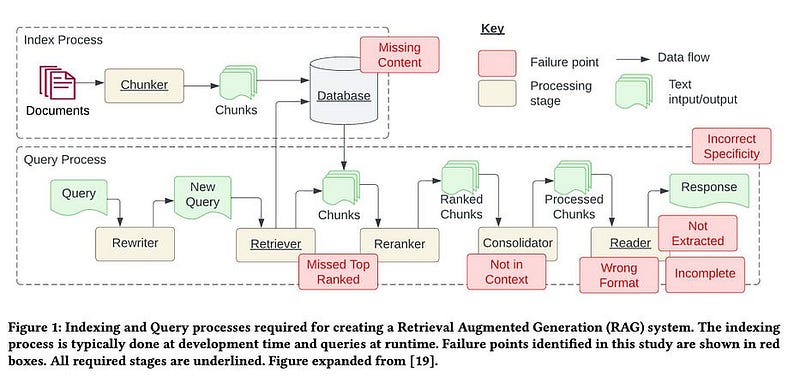
Context Missing in the Knowledge Base
This is quite simple to understand, the question you asked needed some context to be answered, and if your RAG system didn’t pick up the correct document chunk or the context was missing in the source data itself, it would just give a generic answer, not specific enough to solve the user query.
We have a few proposed solutions:
Clean your data:
If your source data is of poor quality, such as containing conflicting information, no matter how well we build our RAG pipeline, it cannot do the magic to output gold from the garbage we feed it.
There are some common strategies to clean your data, to name a few:
- Remove noise and irrelevant information: This includes removing special characters, stop words (common words like “the” and “a”), and HTML tags.
- Identify and correct errors: This includes spelling mistakes, typos, and grammatical errors. Tools like spell checkers and language models can help with this.
- Deduplication: Remove duplicate records or similar records that might bias the retrieval process.
Unstructured.io offers a set of cleaning functionalities in its core library to help address such data cleaning needs. It’s worth checking out.
Better Prompting:
By instructing the system with prompts such as “Tell me you don’t know if you are not sure of the answer,” you encourage the model to acknowledge its limitations and communicate uncertainty more transparently. There is no guarantee for 100% accuracy, but crafting your prompt is one of the best efforts you can make after cleaning your data.
Add in Metadata:
Inject global context to each chunk
Context Missing in the Initial Retrieval Pass
The essential documents may not appear in the top results returned by the system’s retrieval component. The correct answer is overlooked, causing the system to fail to deliver accurate responses. The paper hinted, “The answer to the question is in the document but did not rank highly enough to be returned to the user”.
There are two solutions for this pain point:
Hyperparameter tuning for chunk size and top-k:
Both chunk_size and similarity_top_k are parameters used to manage the efficiency and effectiveness of the data retrieval process in RAG models. Adjusting these parameters can impact the trade-off between computational efficiency and the quality of retrieved information. LlamaIndex offers great support for this, check out the below article.
Check out the documentation for hyperparameter tuning.
# contains the parameters that need to be tuned
param_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}
# contains parameters remaining fixed across all runs of the tuning process
fixed_param_dict = {
"docs": documents,
"eval_qs": eval_qs,
"ref_response_strs": ref_response_strs,
}
def objective_function_semantic_similarity(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build index
index = _build_index(chunk_size, docs)
# query engine
query_engine = index.as_query_engine(similarity_top_k=top_k)
# get predicted responses
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# run evaluator
eval_batch_runner = _get_eval_batch_runner_semantic_similarity()
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)
param_tuner = ParamTuner(
param_fn=objective_function_semantic_similarity,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
results = param_tuner.tune()Reranking:
Reranking retrieval results before sending them to the LLM has significantly improved RAG performance. This LlamaIndex notebook demonstrates the difference between:
- Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
- Accurate retrieval by retrieving the top 10 nodes and using
CohereRerankto rerank and return the top 2 nodes.
import os
from llama_index.postprocessor.cohere_rerank import CohereRerank
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from reranker
query_engine = index.as_query_engine(
similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrieval
node_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors
)
response = query_engine.query(
"What did Elon Musk do?",
)A cool Blog on custom Reranker: click here
Context Missing After Reranking
The paper defined this point: “Documents with the answer were retrieved from the database but did not make it into the context for generating an answer. This occurs when many documents are returned from the database, and a consolidation process takes place to retrieve the answer”.
Better retrieval strategies
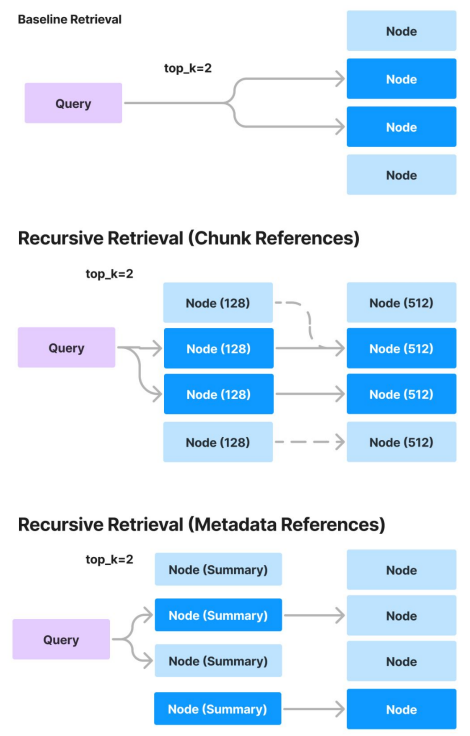
LlamaIndex offers an array of retrieval strategies, from basic to advanced, to help us achieve accurate retrieval in our RAG pipelines.
- Basic retrieval from each index
- Advanced retrieval and search
- Auto-Retrieval
- Knowledge Graph Retrievers
- Composed/Hierarchical Retrievers
Finetune embeddings
If the model doesn’t perform well even after changing the retrieval strategy, we should fine-tune our model on our data, thus giving the context to the LLM itself. In this process, we get the embedding model that is later on used to convert our raw data to vector db with the help of these custom embedding models.
Context Not Extracted
The system struggles to extract the correct answer from the provided context, especially when overloaded with information. Key details are missed, compromising the quality of responses. The paper hinted: “This occurs when there is too much noise or contradicting information in the context”.
Here are a few proposed solutions.
Prompt compression
Prompt compression in the long-context setting was introduced in the LongLLMLingua research project/paper. With its integration in LlamaIndex, we can now implement LongLLMLingua as a node postprocessor, which will compress context after the retrieval step before feeding it into the LLM. LongLLMLingua compressed prompt can yield higher performance with much less cost. Additionally, the entire system runs faster.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessor
from llama_index.core import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
retrieved_nodes = retriever.retrieve(query_str)
synthesizer = CompactAndRefine()
# outline steps in RetrieverQueryEngine for clarity:
# postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=query_str)
)
print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))
response = synthesizer.synthesize(query_str, new_retrieved_nodes)LongContextReorder
A study observed that the best performance typically arises when crucial data is positioned at the start or conclusion of the input context. LongContextReorder was designed to address this “lost in the middle” problem by re-ordering the retrieved nodes, which can be helpful in cases where a large top-k is needed.
from llama_index.core.postprocessor import LongContextReorder
reorder = LongContextReorder()
reorder_engine = index.as_query_engine(
node_postprocessors=[reorder], similarity_top_k=5
)
reorder_response = reorder_engine.query("Did the author meet Sam Altman?")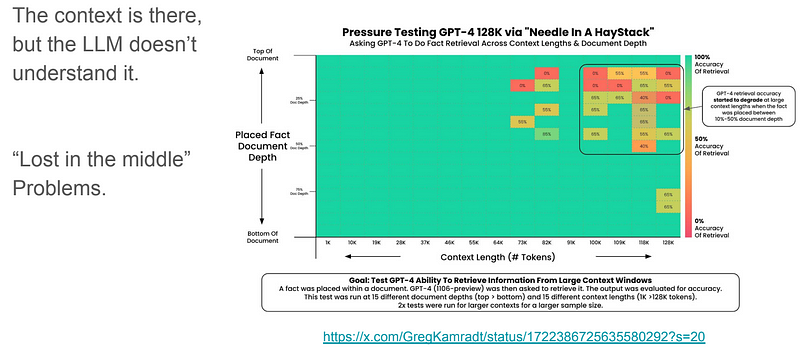
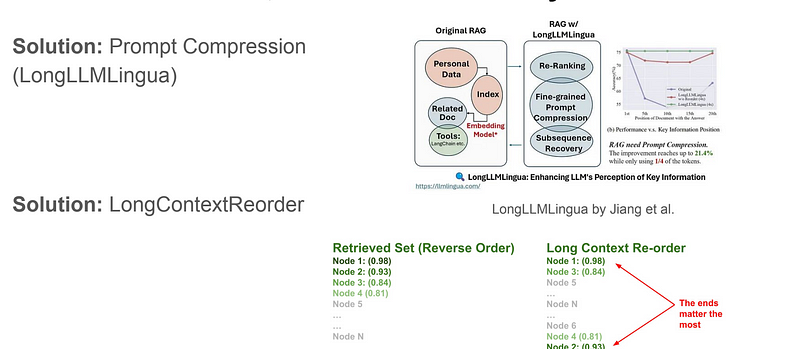
This is one of the very interesting papers throwing light on how the Attention mechanism is not uniform and looks at certain parts more and thus important information is at the start of the attention.
Output is in the Wrong Format
A lot of use cases require outputting the answer in JSON format.
- Better text prompting/output parsing.
- Use OpenAI function calling + JSON mode
- Use token-level prompting (LMQL, Guidance)
LlamaIndex supports integrations with output parsing modules offered by other frameworks, such as Guardrails and LangChain.
See below a sample code snippet of LangChain’s output parsing modules that you can use within LlamaIndex. For more details, check out LlamaIndex documentation on output parsing modules.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.output_parsers import LangchainOutputParser
from llama_index.llms.openai import OpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex.from_documents(documents)
# define output schema
response_schemas = [
ResponseSchema(
name="Education",
description="Describes the author's educational experience/background.",
),
ResponseSchema(
name="Work",
description="Describes the author's work experience/background.",
),
]
# define output parser
lc_output_parser = StructuredOutputParser.from_response_schemas(
response_schemas
)
output_parser = LangchainOutputParser(lc_output_parser)
# Attach output parser to LLM
llm = OpenAI(output_parser=output_parser)
# obtain a structured response
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query(
"What are a few things the author did growing up?",
)
print(str(response))Pydantic offers great support for structuring the output of the LLMs.
from pydantic import BaseModel
from typing import List
from llama_index.program.openai import OpenAIPydanticProgram
# Define output schema (without docstring)
class Song(BaseModel):
title: str
length_seconds: int
class Album(BaseModel):
name: str
artist: str
songs: List[Song]
# Define openai pydantic program
prompt_template_str = """\
Generate an example album, with an artist and a list of songs. \
Using the movie {movie_name} as inspiration.\
"""
program = OpenAIPydanticProgram.from_defaults(
output_cls=Album, prompt_template_str=prompt_template_str, verbose=True
)
# Run program to get structured output
output = program(
movie_name="The Shining", description="Data model for an album."
)This will fill the data from LLM into the class objects.
- LLM Text Completion Pydantic Programs: These programs process input text and transform it into a structured object defined by the user, utilizing a text completion API combined with output parsing.
- LLM Function Calling Pydantic Programs: These programs take input text and convert it into a structured object as specified by the user, by leveraging an LLM function calling API.
- Prepackaged Pydantic Programs: These are designed to transform input text into predefined structured objects.
Check out another similar thing from W&B: https://github.com/wandb/edu/tree/main/llm-structured-extraction
OpenAI JSON mode enables us to set response_format to { "type": "json_object" } to enable JSON mode for the response. When JSON mode is enabled, the model is constrained to only generate strings that parse into valid JSON objects. While JSON mode enforces the format of the output, it does not help with validation against a specified schema. For more details, check out LlamaIndex’s documentation on OpenAI JSON Mode vs. Function Calling for Data Extraction.
Output has an Incorrect Level of Specificity
The responses may lack the necessary detail or specificity, often requiring follow-up queries for clarification. Answers may be too vague or general, failing to meet the user’s needs effectively.
Advanced retrieval strategies
When the answers are not at the right level of granularity you expect, you can improve your retrieval strategies. Some main advanced retrieval strategies that might help in resolving this pain point include:
Output is Incomplete
Partial responses aren’t wrong; however, they don’t provide all the details, despite the information being present and accessible within the context. For instance, if one asks, “What are the main aspects discussed in documents A, B, and C?” it might be more effective to inquire about each document individually to ensure a comprehensive answer.
Query transformations
Comparison questions especially do poorly in naïve RAG approaches. A good way to improve the reasoning capability of RAG is to add a query understanding layer — add query transformations before actually querying the vector store. Here are four different query transformations:
- Routing: Retain the initial query while pinpointing the appropriate subset of tools it pertains to. Then, designate these tools as the suitable options.
- Query-Rewriting: Maintain the selected tools, but reformulate the query in multiple ways to apply it across the same set of tools.
- Sub-Questions: Break down the query into several smaller questions, each targeting different tools as determined by their metadata.
- ReAct Agent Tool Selection: Based on the original query, determine which tool to use and formulate the specific query to run on that tool.
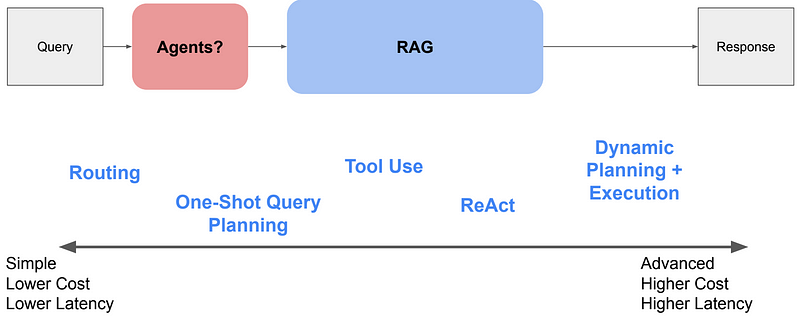
Check out LlamaIndex’s Query Transform Cookbook for all the details.
Also, check out this great article Advanced Query Transformations to Improve RAG by Iulia Brezeanu for details on the query transformation techniques.
Scalability
Can’t Scale to Larger Data Volumes
Processing thousands/millions of docs is slow. The other question is how do we efficiently handle document updates? A simple Ingestion pipeline can’t scale to larger data volumes.
Parallelizing ingestion pipeline
● Parallelize document processing ● HuggingFace TEI ● RabbitMQ Message Queue ● AWS EKS clusters
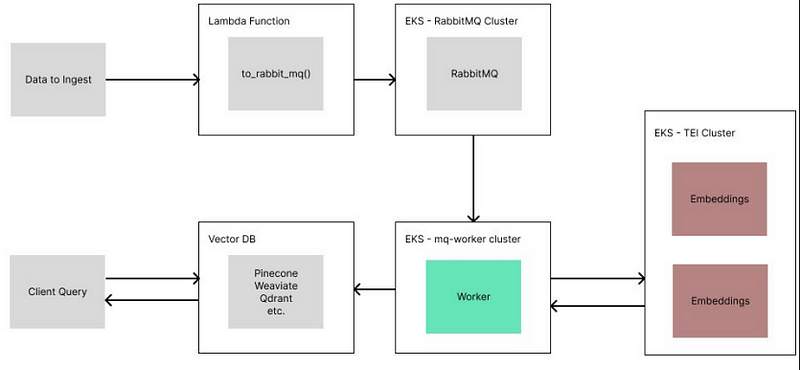
LlamaIndex offers ingestion pipeline parallel processing, a feature that enables up to 15x faster document processing in LlamaIndex.
# load data
documents = SimpleDirectoryReader(input_dir="./data/source_files").load_data()
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=1024, chunk_overlap=20),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# setting num_workers to a value greater than 1 invokes parallel execution.
nodes = pipeline.run(documents=documents, num_workers=4)Rate-Limit Errors
If the API’s terms of service permit, we can register for multiple API keys and rotate them in our application. This approach effectively multiplies our rate limit quota. However, ensure this is compliant with the API provider’s policies.
If we’re working within a distributed system, we can spread requests across multiple servers or IP addresses, each with its rate limit. Implementing load balancing to dynamically distribute requests in a way that optimizes rate limit usage across our infrastructure.
Conclusion
We explored 9 pain points (7 from the paper and 2 additional ones) in developing RAG pipelines and provided corresponding proposed solutions to all of them. This is part 1 of our RAG series, in the next blog, we will go deeper into how to process tables and other advanced things, how to use caching, etc.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter





