
Machine Learning Art
“The GAN is dead, long live the DALL·E 2!”
DIFFUSION MODELS — unCLIP

🟠 Edit & Train and Run Your own DALL-E. CODE + DEMOS
Open.AI helps us comprehend how advanced AI systems see and ponder our world. Art is the key to this. By exploring the art that is generated by AI and looking at what captures and inspires us, we can test a broader range of ideas and fixable limitations in order to refine our systems.
🟠 New AI Art Generators You Should Know About [Aug 2022]
The choice of algorithm — diffusion (instead of generative adversarial networks) was informed by an in-depth exploration of the strengths and weaknesses of each approach.
The system architecture combines techniques from machine learning, computer vision, natural language understanding (NLP), natural language generation (NLP), and synthesis.
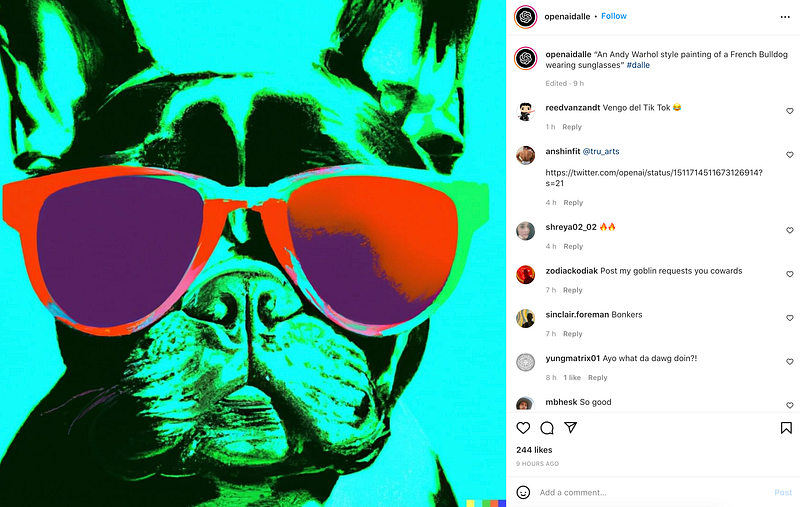
DALL·E 2 can:
🔵 from a written description, generate original, realistic visuals and art. It has the ability to mix and match ideas, properties, and styles. 🔵 From a natural language caption, perform realistic modifications to existing photos. It has the ability to add and remove items while taking into consideration shadows, reflections, and textures. 🔵 take one image and make several versions based on the original.
Scaling models on enormous datasets of annotated pictures acquired from the internet has fueled recent advances in computer vision. CLIP has shown to be an effective image representation learner inside this framework. CLIP embeddings offer a number of desired qualities, including being resistant to picture distribution shift, having excellent zero-shot capabilities, and having been fine-tuned to deliver state-of-the-art outcomes on a variety of vision and language tasks. Diffusion models, on the other hand, have emerged as a potential generative modeling framework, advancing the state-of-the-art in picture and video creation problems. Diffusion models use a guiding strategy to increase sample fidelity (for photos, photorealism) at the expense of sample diversity in order to attain the best results.
Encoding and decoding an input picture yields semantically identical output images, akin to GAN inversion. By reversing interpolations of respective image embeddings, we may also interpolate between input pictures. One major advantage of employing the CLIP latent space is the ability to semantically transform pictures by moving in the direction of any encoded text vector, whereas detecting these directions in the GAN latent space requires chance and meticulous manual study.
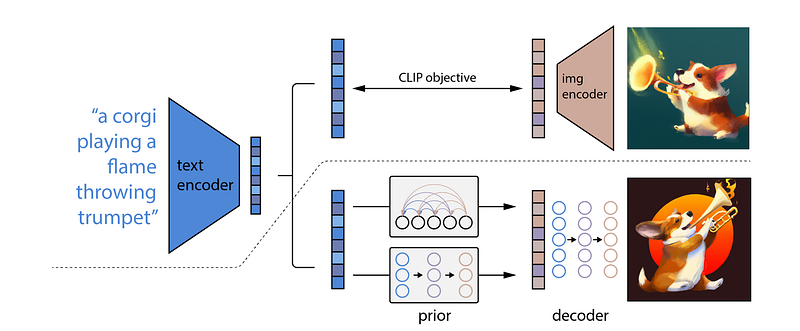
The above image: An overview of unCLIP at a high level. The CLIP training process is depicted above the dotted line, in which we learn a shared representation space for text and pictures. We show the text-to-image creation method below the dotted line: a CLIP text embedding is fed to an autoregressive or diffusion precursor to generate an image embedding, which is then used to condition a diffusion decoder, which produces a final picture. It’s worth noting that the CLIP model is frozen while the prior and decoder are being trained.

By interpolating their CLIP image embedding and then decoding with a diffusion model, we may see differences between two pictures. The decoder seed is fixed in each row. The content and style of both input photos are organically blended in the intermediate variants.
The authors combine the CLIP image embedding decoder with a previous model that creates probable CLIP image embeddings from a given text caption to obtain a comprehensive generative model of pictures. They compare the text-to-image system to other systems like DALL-E and GLIDE, finding that their samples are equivalent to GLIDE in terms of quality, but with more variation in the generations. They also create techniques for training diffusion priors in latent space, demonstrating that they function similarly to autoregressive priors while training significantly faster. Because it creates pictures by reversing the CLIP image encoder, they call the whole text-conditional image generating stack unCLIP.
@article{mishkin2022risks,
title={DALL·E 2 Preview - Risks and Limitations},
author={Mishkin, Pamela and Ahmad, Lama and Brundage, Miles and Krueger, Gretchen and Sastry, Girish},
year={2022}
url={[https://github.com/openai/dalle-2-preview/blob/main/system-card.md](https://github.com/openai/dalle-2-preview/blob/main/system-card.md)}
}
Project Page:
https://cdn.openai.com/papers/dall-e-2.pdf
Github:
https://github.com/openai/dalle-2-preview/blob/main/system-card.md
How to create AI art like DALL-E2 today : HERE
Keywords: Computer Vision, Pattern Recognition, Artificial Intelligence, Graphics, Machine Learning, AI art, art, digital art, DALL·E 2, DIFFUSION, unCLIP
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (7.7K+ ML-professionals)
- Twitter (4.7K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
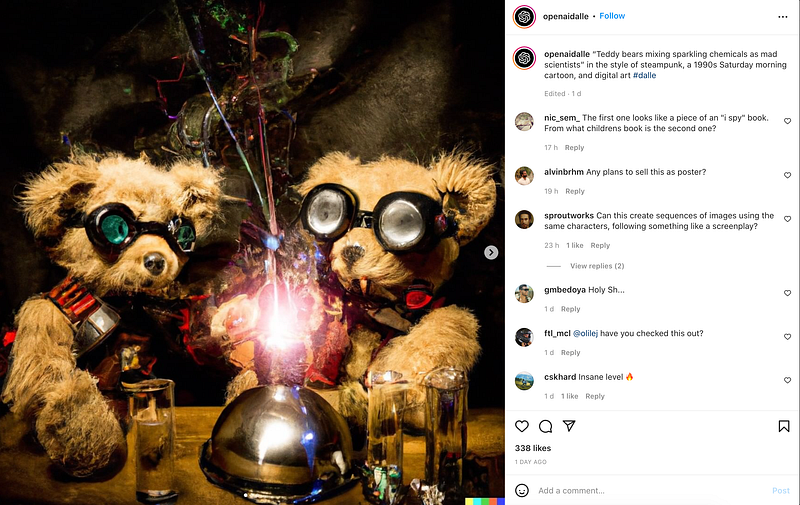
All images in this article are generated by DALL·E 2, the version of OpenAI’s generative model released in April 2022. They were generated using the caption matching method and differ from previous examples only insofar as they were generated using a single photo rather than a photo mosaic of multiple images.





