
Stable Diffusion XL 1.0 Is Close
Stable Diffusion XL Discord Bot Is Live As Research Beta
Use the SD XL Discord bot to help training the next Stable Diffusion model
The Stable Foundation’s Discord server is currently inviting everybody to participate in an exciting beta test, where you can create images with candidates of the upcoming Stable Diffusion XL model and evaluate them.
The upcoming release of Stable Diffusion XL is expected to be a real game changer, as it can take open source AI image generation to a whole new level of quality, usability, and innovation.
Here’s how you can get involved to not only create stunning images with the new Stable Diffusion bot, but also help train the new model.
How To Use The Stable Diffusion Bot
If you want to participate in this exciting community effort, all you have to do is join the Stable Foundation Discord server with this link.
Once you’re on the server, you will find #bot-channels where you can create images using the Stable Diffusion Discord bot using this command:
/dream prompt: [YOUR_IMAGE_PROMPT]
Next, you will see the results that have been generated by different candidates for the final Stable Diffusion XL model. It’s now up to you to evaluate which model’s result you prefer:
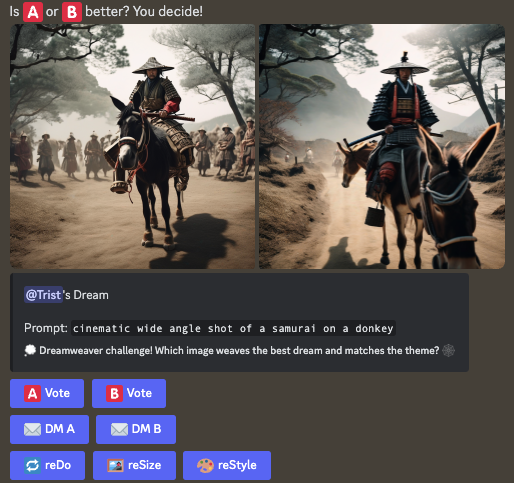
By participating in the voting, you’re helping to train the upcoming Stable Diffusion model with feedback on which images are preferred by humans.
Here are the two options separately. How would you vote, A or B?


Additionally, you can use ReSize, ReDo and ReStyle buttons to further test the model’s capabilities.
I’m not sure if the candidates are also rotated in this process or only between channels and commands.
Either way, the results are pretty interesting:




Since there are multiple candidates rotating in all the #bot-channels, you’re likely to experience a range of quality, coherence, and aesthetics if you use the bot for a while.
(Note: You can use the /dream_stats command to get a summary of your voting activity)
What’s Next?
Stable Diffusion XL is already used in a variety of apps and has received many positive reviews from users for its ability to create realistic photos, legible text, and versatile artworks.
The next step will be the release of version 1.0 of the model, which will make the new features available to everyone, regardless of whether you prefer to use third-party apps or cloud services, or run Stable Diffusion locally.
Also, we will see these insane improvements in all upcoming customized versions of the model:
- enhanced face generation
- next-level photorealism capabilities
- use of shorter prompts to create descriptive imagery
- greater capability to produce legible text
If you ask me, there’s a serious competitor on the way for companies like Midjourney, Adobe Firefly and DALL-E.
I mean, consider that the Stable Diffusion community has been the leading innovator of workflows that have only recently been adapted by corporate players:
- Inpainting
- Outpainting
- Image-to-image
- Video workflows
When the final candidate of Stable Diffusion XL1.0 is announced, we should expect another wave of innovative model customizations and workflow improvements.
If you’d like to experiment with these workflows and run other Stable Diffusion models in the cloud, check this out: