
NLP & fastai | Transformer Model

Autres posts de la série NLP & fastai: Topic Modeling | Sentiment Classification | Language Model | Transfer Learning | ULMFiT | MultiFiT | French Language Model | Portuguese Language Model | RNN | LSTM & GRU | SentencePiece | Sequence-to-Sequence Model (seq2seq) | Attention Mechanism | GPT-2
Références fastai
Ce post concerne les vidéos 17 et 18 du cours fastai de Rachel Thomas sur NLP (A code-first introduction to NLP).
- Notebook: 8-translation-transformer.ipynb (NLP, 2019)
- Présentation: Attention.pptx
Motivation
Les modèles Seq2Seq utilisant des RNNs (Recurrent neural Network) avec mécanisme d’attention proposés dès 2014 notamment par Yoshua Bengio ont permis d’ouvrir un nouveau champ de recherche en particulier en NLP (Neural language Processing) en montrant que les modèles de Deep Learning permettaient d’améliorer et surpasser les performances de modèles plus anciens et non neuronaux dans des tâches comme la traduction, la création de titres ou de résumés, la détection d’entités conceptuelles ou de mots/expressions à retirer d’un texte, la création de légendes à des images, etc.).
Cependant, la nature séquentielle des RNNs a ensuite été régulièrement désignée comme un frein pour l’entraînement de ces modèles sur des textes longs à la fois pour des questions de temps (les GPUs même modernes ne parallélise pas bien ce type de processus) et de pertes de gradient malgré l’utilisation de modèles LSTM (Long Short-Term Memory Network).
Après une période qui a vu l’utilisation de convolutions dynamiques (WaveNet, ByteNet…) afin de ne plus dépendre d’un traitement séquentiel mais au contraire parallèle de l’ensemble des mots d’une séquence à encoder, le modèle Transformer de Google AI présenté en juin 2017 dans le papier “Attention Is All You Need” a révolutionné à la fois l’encodage d’une séquence mais aussi le mécanisme d’attention à utiliser (l’encodage n’est plus séquentiel mais matriciel de l’ensemble de la séquence et le mécanisme d’attention appelé self-attention n’est plus unique mais se répète 3 fois). Il permet en effet d’obtenir une meilleure performance et de faire davantage de calculs en parallèle, ce qui le rend plus rapide à entraîner que les modèles basés sur les RNNs.
Nous pouvons résumer en 3 points les avantages du modèle Transformer:
- la distance entre 2 tokens éloignés n’est plus un paramètre pris en compte par le modèle (ie, le modèle peut prendre en compte de long-term dependencies): le nombre de calculs de la self-attention à porter à un token (cad ses relations avec les autres tokens) est le même pour tous les tokens quelle que soit leur position dans la séquence.
- le multi-head permet de faire attention à différents types de relations entre tokens.
- le calcul matriciel de l’attention permet de paralléliser le processus d’encodage puis décodage des séquences, donc d’accélérer les calculs.
Voici un extrait du papier “Attention Is All You Need”:
“La nature intrinsèquement séquentielle [des RNN] empêche la parallélisation dans les exemples d’apprentissage, ce qui devient critique pour des séquences plus longues, car les contraintes de mémoire limitent le traitement par batch entre les exemples.” (en anglais: “This inherently sequential nature [of RNNs] precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.”)
Note: le papier Pay Less Attention with Lightweight and Dynamic Convolutions de 2019 semble cependant relativiser cette affirmation sur la contrainte de mémoire des modèles Seq2Seq, ce qui viendrait de fait à les condamner, puisqu’il prouve qu’un usage “dynamique” de convolutions les rend performants et moins gourmand en calcul que les modèles avec attention. La recherche de la solution la plus performante entre RNNs, convolutions dynamiques et transformers continuent donc…
Historique des modèles Transformer
Avant d’étudier le fonctionnement du modèle Transformer, il est intéressant de constater à quel point ce modèle a impacté jusqu’à aujourd’hui la recherche en NLP.
En effet, depuis 2017 et le premier modèle Transformer, de nombreux modèles ont été développés par tous les grands laboratoires en Intelligence Artificielle et les GAFAMs comme Allen Institute (ELMo), OpenAI (GPT-2), Google (BERT, XLNet), Facebook (RoBERTa) et très récemment (janvier 2020), Microsoft (Turing-NLG) avec un modèle à 17 milliards de paramètres!
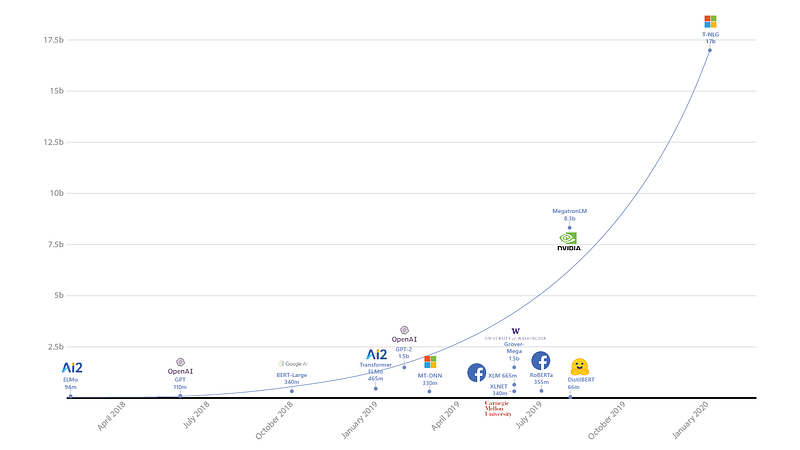
Principe de l’attention, clé du NLP
Nous avons déjà présenté le principe et l’implémentation du mécanisme d’attention encoder-decoder (cf. le post Attention Mechanism) inventé en 2014 en particulier par Yoshua Bengio et dévoilé dans le papier scientifique “Neural Machine Translation by Jointly Learning to Align and Translate”: il s’agissait pour la première fois dans un modèle de Deep Learning (ici, un modèle Seq2Seq avec RNNs pour de la traduction instantanée) d’utiliser un vecteur de contexte spécifique au moment de générer par le decoder un nouveau token (mot ou signe de ponctuation) de la séquence de sortie, vecteur résultant de la somme pondérée des vecteurs d’état émis par l’encoder lors de l’encodage de chaque token de la séquence d’entrée.
Note: ce vecteur est dit de contexte car les valeurs des poids de pondération (scores) qui sont utilisés pour le créer témoignent de l’importance relative des tokens de la séquence d’entrée à prendre en compte à ce moment de la génération d’un nouveau token de la séquence de sortie.
Plus tard, en juin 2017, lors de la présentation du modèle Transformer par l’équipe Google AI dans le papier scientifique “Attention Is All You Need”, un nouveau mécanisme d’attention dit “self-attention multi-head avec 3 implémentations (encoder-encoder, decoder-decoder, encoder-decoder)” est venu améliorer considérablement l’efficacité de ce mécanisme initial mais toujours avec la même idée centrale “le vecteur de contexte” qui permet lors de l’encodage d’un token d’une séquence de tenir compte de l’importance relative des autres tokens (plus exactement, qui permet de tenir compte de ses relations au sens large avec comme les relations grammaticales, de sens, de co-référence, etc.).
L’intuition derrière l’utilisation du mécanisme de self-attention du modèle Transformer à 3 étapes différentes du processus de traduction est qu’il correspond sensiblement à ce que fait un humain:
- encoder-encoder: il faut comprendre un texte pour pouvoir le traduire
- encoder-decoder: il faut faire davantage attention à certaines parties de la séquence d’entrée au moment de générer un nouveau mot de la traduction
- decoder-decoder: il faut faire attention à ce que l’on vient de traduire pour continuer la traduction
Enfin, plus récemment lors de NeurIPS 2019 en décembre 2019, Yoshua Bengio est revenu sur l’importance des mécanismes d’attentions utilisés à présent dans tous les modèles de Deep Learning (et pas uniquement les modèles de NLP) en introduisant la conscience dans le vocabulaire traditionnel de l’apprentissage automatique. Il considère en effet que l’ingrédient central de la conscience est l’attention. Il a comparé les mécanismes d’attention utilisés dans l’apprentissage machine à la façon dont notre cerveau choisit ce à quoi il faut prêter attention:
“L’apprentissage automatique peut être utilisé pour aider les scientifiques du cerveau à mieux comprendre la conscience, mais ce que nous comprenons de la conscience peut également aider l’apprentissage automatique à développer de meilleures capacités.” (en anglais: “Machine learning can be used to help brain scientists better understand consciousness, but what we understand of consciousness can also help machine learning develop better capabilities.”)
Selon Yoshua Bengio, une approche inspirée par la conscience est la voie à suivre si nous voulons des algorithmes d’apprentissage automatique qui peuvent se généraliser à des exemples hors des distributions utilisées pour leur entraînement.
Modèle Transformer de Google AI
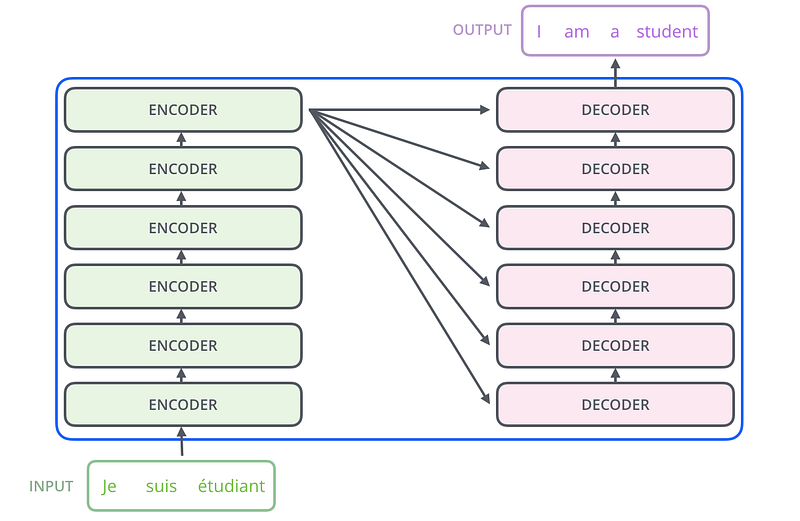
Voici ci-dessous le modèle Transformer développé par Google AI, entraîné 12 heures sur 8 GPUs NVIDIA P100 et présenté dans le papier scientifique “Attention Is All You Need” en juin 2017. Il présente 2 grands modules: l’ensemble des 6 encoders qui encode une séquence d’entrée qui est alors décodée dans un ensemble de 6 decoders pour générer une séquence de sortie.
Nous pouvons également remarquer que le modèle Transformer possède 3 mécanismes d’attention et non pas un seul comme les modèles Seq2Seq: encoder-encoder dans chaque encoder, decoder-decoder et encoder-decoder (semblable aux modèles Seq2Seq) dans chaque decoder.
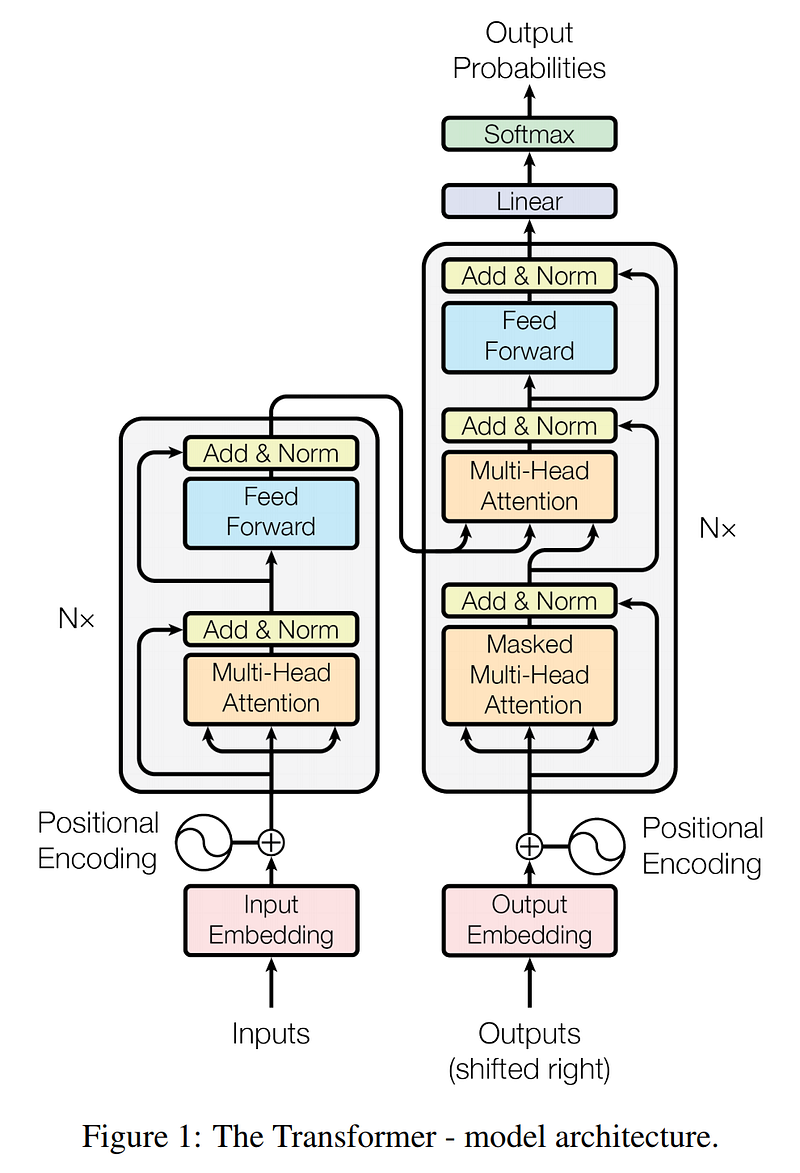
Comme le fait le post “The Illustrated Transformer” ou la vidéo ci-dessous, examinons fonctionnement du modèle Transformer d’abord de manière générale vers ensuite plus de détails.
Modèle en couches
Comme le cerveau dont les neurones fonctionnent en couches et les modèles ConvNet qui se sont inspirés de ce fonctionnement, le modèle Transformer est construit également en couches à la fois dans sa partie encodage et sa partie décodage (6 couches d’encodage puis 6 couches de décodage), chaque couche apprenant des caractéristiques particulières qu’elle fournit alors à la couche suivante (note: ce nombre de 6 n’est pas magique: il constitue plus un compromis pour avoir un temps d’entraînement acceptable selon les possibilités de computation de l’époque: le modèle BERT développé plus tard en novembre 2018 possède par exemple 24 couches et le modèle Turing-NLG révélé en février 2020 en possède 78).
Encoder
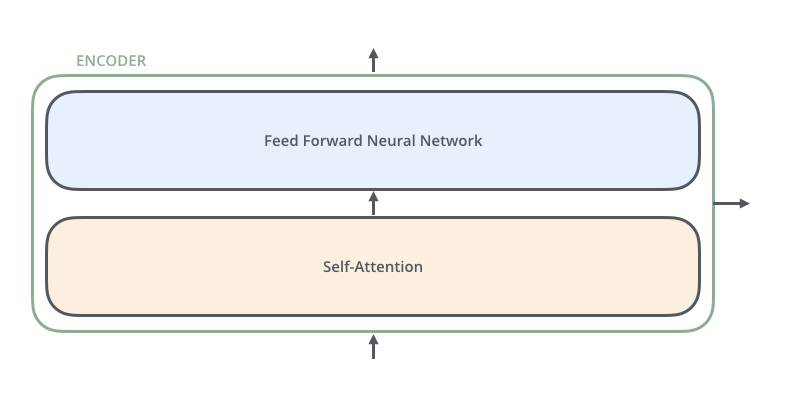
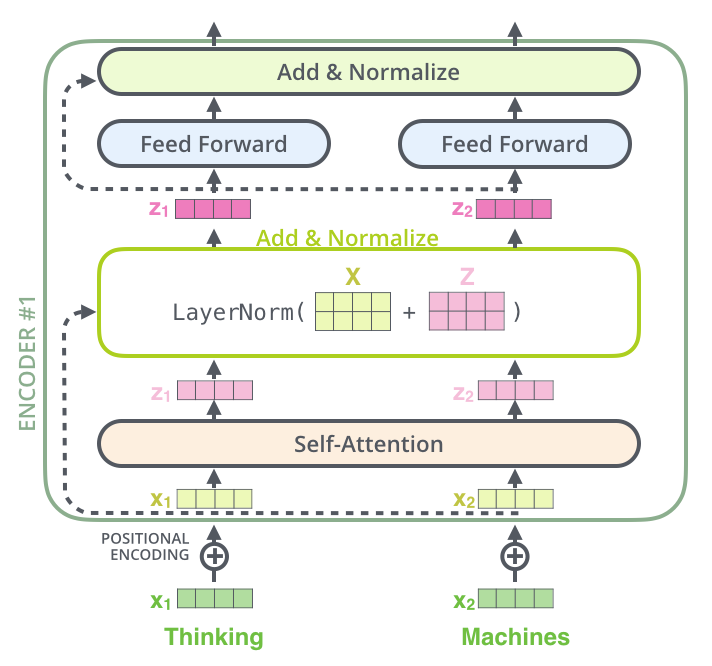
Chacun des 6 encoders est identique avec un mécanisme de self-attention multi_head suivi par un un réseau fully-connected, chacun suivi par une couche de concaténation puis de normalisation des vecteurs.
La notion de multi-head signifie que le processus d’attention (cf. paragraphe ci-après) est répliqué plusieurs fois dans chaque encoder (8 fois dans ce modèle mais là-aussi ce nombre n’est pas magique: il est de 28 dans le modèle Turing-NLG de Microsoft de janvier 2020).
Self-attention dans l’encoder
Le mécanisme de self-attention (ou d’attention interne puisqu’il intervient dès l’encodage de la séquence d’entrée et non seulement à partir du décodage comme dans un modèle Seq2Seq avec RNNs) revient à transformer chaque vecteur x représentant le token de la séquence d’entrée en un vecteur de contexte z qui prend en compte une relation particulière avec les autres tokens de la séquence. Cette notion de relation est vaste et est apprise par l’entraînement: certaines “head” vont faire attention aux relations grammaticales, d’autres aux relations de co-référence, etc. C’est pour cela qu’il y a plusieurs “head” (ie, il y a plusieurs relations à apprendre entre des mots et ponctuations d’une phrase).
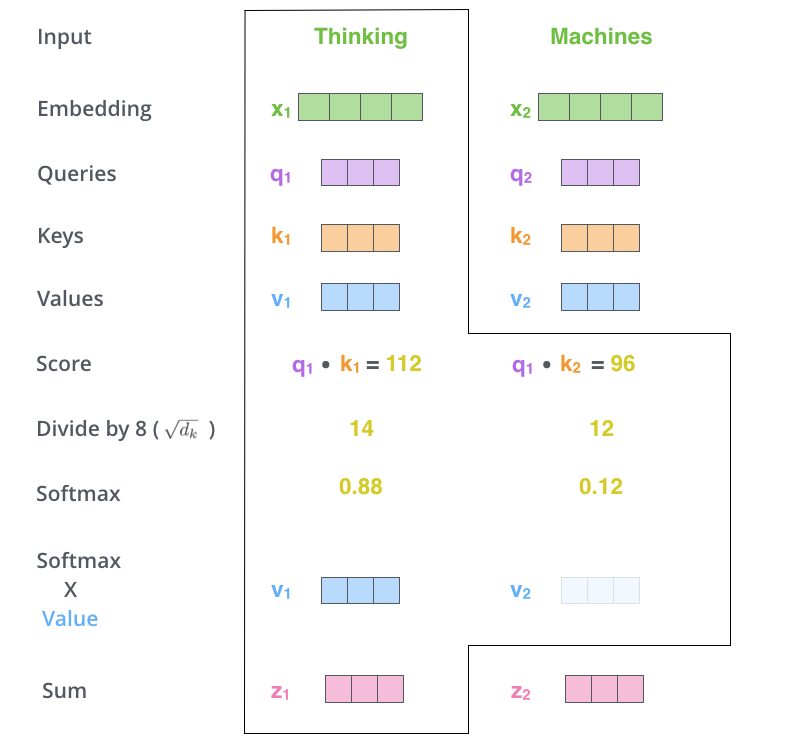
Comme le montre l’image ci-dessous issue du post The Illustrated Transformer, le mécanisme de self-attention demande l’entraînement de 3 matrices qui pour chaque token d’une séquence vont créer un vecteur par multiplication avec son vecteur d’embeddings (en fait le vecteur d’embeddings sommé au vecteur de position).
Pour chaque token de la séquence d’entrée:
- la matrice Q qui permet de créer un vecteur de QUERY (q), vecteur qui représente principalement le token dont il est issu dans le cadre de la séquence,
- la matrice K qui permet de créer un vecteur de KEY (k) pour chaque token de la séquence, vecteurs qui représentent la singularité (une relation particulière) de chacun des tokens de la séquence par rapport au token dont on est entrain de calculer le vecteur de contexte (nous pouvons aussi imaginer les vecteurs k comme des vecteurs d’indexation),
- la matrice V qui permet de créer un vecteur de VALUE (v) pour chaque token de la séquence, vecteurs qui représentent la valeur de chacun des tokens de la séquence.
Ainsi en faisant un dot produit du vecteur de QUERY q avec chacun des vecteurs de KEY k, on obtient un score pour chacun des tokens de la séquence qui après passage par un softmax représente un poids entre 0 et 1 avec une somme de tous les poids à 1. Ces poids vont permettre de faire ensuite une somme pondérée des vecteurs de VALUE v et créé ainsi le vecteur de contexte z.
Pour tous les tokens d’une séquence, il va donc être possible de calculer de manière parallélisée son vecteur de contexte. Le problème de traitement séquentiel des modèles Seq2Seq est éliminé par cette architecture.
Ces multiplications de matrices suivie par un softmax et une normalisation peuvent se résumer par le calcul matriciel suivant (ce qui explique la rapidité de calcul d’un modèle Transformer):
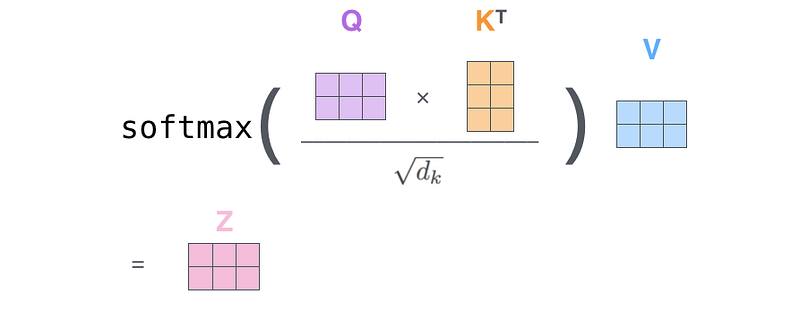
Vecteur de position (positional encoding)
Afin de ne pas traiter les tokens d’une séquence d’entrée comme un “bag of words”, un vecteur de position est ajouté à son vecteur d’embeddings avant que le vecteur résultant n’entre dans le premier encoder.
Afin de comprendre comment est calculé ce vecteur de position, lire le paragraphe “Representing The Order of The Sequence Using Positional Encoding” du post The Illustrated Transformer. L’idée principale est de coder sa position dans la séquence de manière fréquentielle.
Autre post sur le même thème: Transformer Architecture: The Positional Encoding (septembre 2019: Amirhossein Kazemnejad)
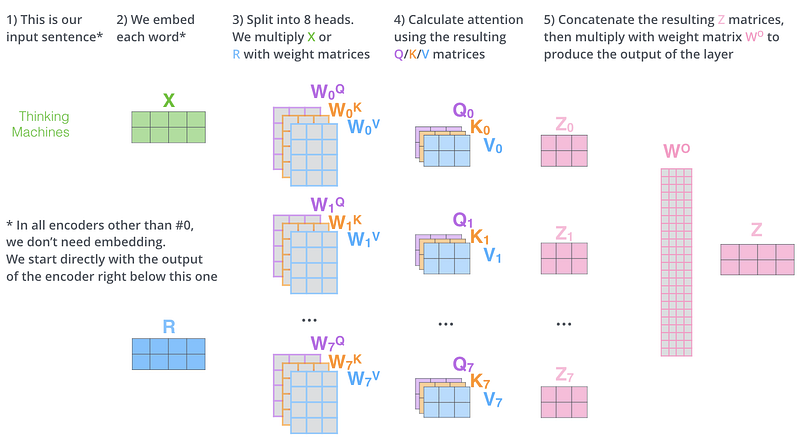
Multi-Head
Comme nous l’avons noté, chaque encoder possède 8 “head” qui permettent chacune de caractériser des relations différentes entre les tokens. Au final, chaque “head” produit une matrice de vecteurs de contextes Z (le nombre de ligne est égal au nombre de tokens et le nombre de colonnes est la dimensionnalité des matrices Q, K et V, ici 64). Ces matrices Z sont concaténées puis multipliées par une matrice 0 (dont les paramètres seront appris par entraînement) qui permettra de retrouver une seule matrice Z de sortie qui sera mise en entrée du Feed-Forward de l’encoder.
Les “residuals”, les normalisations et le réseau fully-connected de sortie de l’encoder
Ce vecteur Z est alors additionné au vecteur d’entrée (residual) puis normalisé avant d’être passé à un réseau Feed-Forward (dont les paramètres seront appris par entraînement), qui lui même sera suivi par une telle procédure (residuals puis normalisation). Le vecteur résultant sera passé à l’encoder suivant.
Sortie de l’ensemble des encoders vers les decoders
2 ensembles de matrices K et V sont produites par l’ensemble des 6 encoders et mis en entrée de la sous-couche “self-attention multi-head” de chaque decoder. Associés à la matrice Q qui est produite par la sous-couche “self-attention multi-head masquée” et qui encode la séquence de sortie, le même procédé de self-attention permet au decoder de “faire attention” au moment de générer un nouveau token de la séquence de sortie.
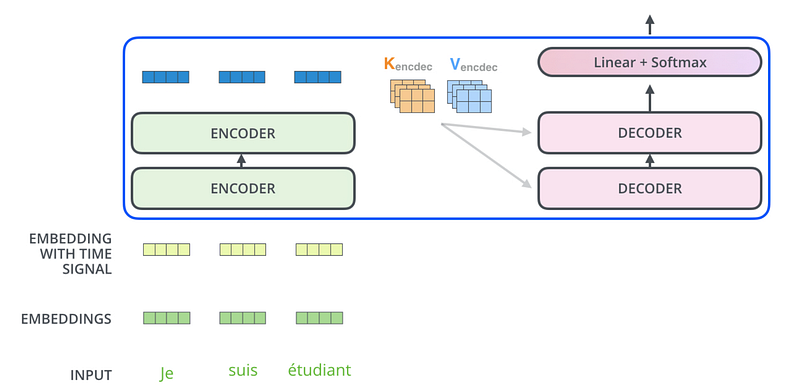
Decoder, couche linéaire et softmax finale et fonction de loss
Afin de comprendre les particularités du décodage (6 decoders), de la couche linéaire et softmax finale et de la fonction de loss utilisée, lire les paragraphes The Decoder Side, The Final Linear and Softmax Layer et The Loss Function du post The Illustrated Transformer.
Pour aller plus loin
- Attentional interfaces (2016: Chris OLAH et Shan CARTER de Google Brain)
- Attention Is All You Need (juin — décembre 2017: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin) et le post sur Google AI: Transformer: A Novel Neural Network Architecture for Language Understanding (août 2017: Jakob Uszkoreit — Google AI)
- Vidéo Attention is all you need; Attentional Neural Network Models (octobre 2017: Masterclass of Łukasz Kaiser — Google AI)
- Vidéo “Attention Is All You Need” (novembre 2017: Yannic Kilcher)
- Transformer: A Novel Neural Network Architecture for Language Understanding (août 2017: Jakob Uszkoreit — Google AI)
- The Annotated Transformer (avril 2018: Harvard NLP)
- Paper Dissected: “Attention is All You Need” Explained (décembre 2017: Keita Kurita)
- Pay Less Attention with Lightweight and Dynamic Convolutions (2019: Felix Wu, Angela Fan, Alexei Baevski, Yann N. Dauphin, Michael Auli)
- The Illustrated Transformer (juin 2018: Jay Alammar)
- Transformer — Attention is all you need (octobre 2019: Pranay Dugar)
- MASS: Masked Sequence to Sequence Pre-training for Language Generation (juin 2019: Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu — Microsoft Research Asia & pre-training for transformers)
- GPT — Improving Language Understanding by Generative Pre-Training (juin 2018: Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever) et le post sur OpenAI: Improving Language Understanding with Unsupervised Learning
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (octobre 2018 — mai 2019: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova — Google AI Language)
- GPT-2 — Language Models are Unsupervised Multitask Learners (février 2019: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever — OpenAI) et le post sur OpenAI: Better Language Models and Their Implications
- Top 8 trends from ICLR 2019 (mai 2019: Chip Huyen)
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang — OpenAI) et le post sur OpenAI: GPT-2: 6-Month Follow-Up
- Hello, It’s GPT-2 — How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems (août 2019: Paweł Budzianowski, Ivan Vulić — Cambridge University, UK)
- MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism (août 2019: NVIDIA)
- Transformers from scratch (août 2019, Peter Bloem)
- GPT-2 — Fine-Tuning Language Models from Human Preferences (septembre 2019 — janvier 2020: Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving — OpenAI) et le post sur OpenAI: Fine-Tuning GPT-2 from Human Preferences
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août — novembre 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang) et le post sur OpenAI: GPT-2: 1.5B Release
- Key trends from NeurIPS 2019 (décembre 2019: Chip Huyen)
À propos de l’auteur: Pierre Guillou est consultant en Intelligence Artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.