
NLP & fastai | Attention Mechanism

Faire attention à ce que l’on lit, entend ou voit peut faire une grande différence dans notre compréhension d’une situation et donc sur notre réponse cognitive ou corporelle. En intelligence artificielle appliquée au NLP, il est également possible d’entraîner un modèle séquentiel (seq2seq) dont la qualité de la sortie textuelle (traduction, titre, résumé, légende d’image…) dépendra du mécanisme d’attention sur l’entrée (texte, son, image, vidéo). Dans ce post, j’explique comment fonctionne un tel mécanisme et comment le coder.
Autres posts de la série NLP & fastai: Topic Modeling | Sentiment Classification | Language Model | Transfer Learning | ULMFiT | MultiFiT | French Language Model | Portuguese Language Model | RNN | LSTM & GRU | SentencePiece | Sequence-to-Sequence Model (seq2seq) | Transformer Model | GPT-2
Références fastai
Ce post concerne les vidéos 12, 14 et 17 du cours fastai de Rachel Thomas sur NLP (A code-first introduction to NLP) et la vidéo 11 (notes, 2018) du cours de Jeremy Howard (Introduction to Machine Learning for Coders).
Notebooks associés: 7-seq2seq-translation.ipynb (NLP, 2019), 7b-seq2seq-attention-translation.ipynb (NLP, 2019), translate.ipynb (fastai 0.7, DL2, 2018) et translate.ipynb (fastai 1.0, DL2, 2018).
Motivation
“Fais attention à ce que tu fais!” C’est une phrase que vous avez certainement souvent entendue dans votre enfance. En effet, dans la vie de tous les jours, les capacités d’attention visuelle, auditive et cognitive font toute la différence pour la compréhension d’une situation.
Par exemple, vous ne comprenez bien un texte que si vous faites attention lors de sa lecture aux mot et expressions qui sont plus importants que d’autres pour sa compréhension globale, et cela est d’autant plus vrai quand le texte est long. De même, après avoir visité un nouveau lieu, vous vous souvenez mieux des objets auxquels vous avez prêté attention que des autres.
Porter son attention sur une situation puis utiliser ses souvenirs permet ainsi d’être plus performant comme par exemple lors d’une traduction d’un texte d’une langue vers une autre car non seulement tous les mots du texte initial à traduire n’ont pas la même importance mais en plus l’ordre des mots traduits ne suit pas nécessairement celui des mots du texte initial.
L’image suivante illustre bien ce principe: afin de générer le token “zone” dans la séquence de sortie, le decoder B utilise l’importance relative des mots “Area” puis “Economic” qui sont pourtant des tokens avec une position supérieure dans la séquence d’entrée de l’encoder A.
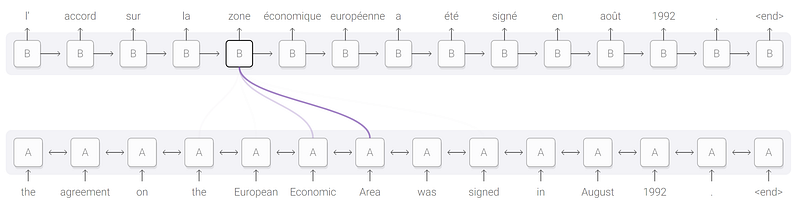
Mécanisme d’attention dans un modèle SeqToSeq
Dans un modèle Seq2Seq de type encoder-decoder RNN utilisé dans le NMT (Neural Machine Translation), le mécanisme d’attention consiste, au moment de la génération par le decoder d’un nouveau token de la séquence de sortie, à prendre en compte un vecteur de contexte spécifique qui est une somme pondérée de tous les vecteurs d’état émis par l’encoder lors de l’encodage de la séquence d’entrée et pas seulement le dernier vecteur d’état du decoder.
Ainsi, à partir d’une requête émise par le decoder (en utilisant son dernier vecteur d’état), chaque vecteur d’état généré par l’encoder lors de l’encodage des tokens de la séquence d’entrée est noté (scored) à l’aide d’un réseau de neurones fully-connected. Ces scores sont alors normalisés en probabilités qui sont ensuite utilisées pour calculer une somme pondérée des vecteurs d’état de l’encoder. Le vecteur résultant dit vecteur de contexte spécifique est finalement utilisé dans le décodeur pour la génération d’un nouveau token de la séquence de sortie.
On pourrait alors résumer le mécanisme d’attention sur une séquence d’entrée d’un modèle Seq2Seq comme un procédé de notation (score) de chaque vecteur d’état émis par l’encoder afin d’améliorer la génération par le decoder de chaque nouveau token de la séquence de sortie.
Note: le réseau neuronal fully-connected est un réseau neuronal à une couche cachée dont les valeurs des paramètres sont apprises classiquement lors de l’entraînement de l’ensemble du modèle Seq2Seq (ie, par backpropagation du gradient de la fonction d’erreur). Il n’y a donc ni entraînement indépendant de ce réseau neuronal, ni besoin de modifier la fonction d’erreur du modèle Seq2Seq.
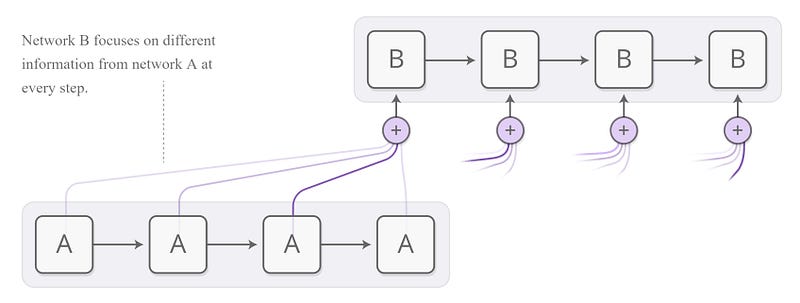
Note: ce mécanisme d’attention a été présenté en 2014 (puis révisé en 2016) dans le papier Neural Machine Translation by Jointly Learning to Align and Translate de Dzmitry Bahdanau, Kyunghyun Cho et Yoshua Bengio. Il permet de solutionner en partie le problème de traduction des phrases longues où l’utilisation d’un vecteur de contexte unique ne permet pas d’obtenir une bonne traduction, ce vecteur ne pouvant pas contenir toutes les caractéristiques de la phrase à traduire.
Codage du mécanisme d’attention
Le principe du codage du mécanisme d’attention est illustré dans l’image ci-dessous et décrit dans le texte suivant. Le code correspondant issu du notebook 7b-seq2seq-attention-translation.ipynb de fastai est également donné ci-après.
1. Illustration
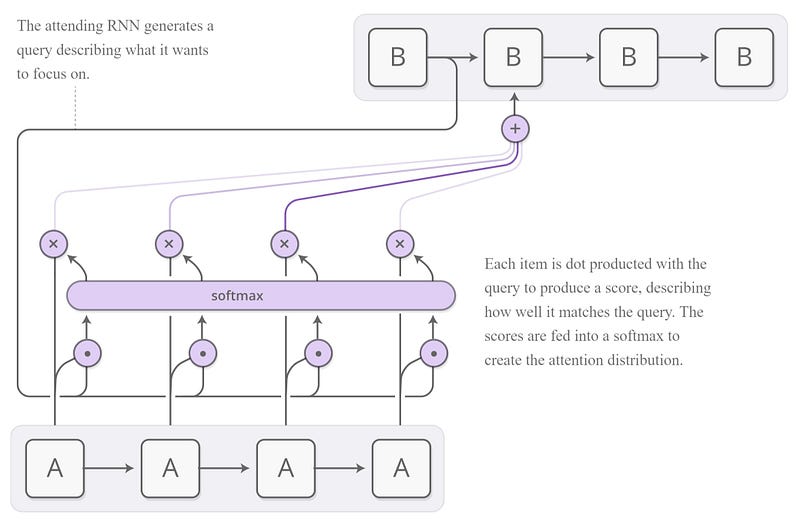
2. Explication
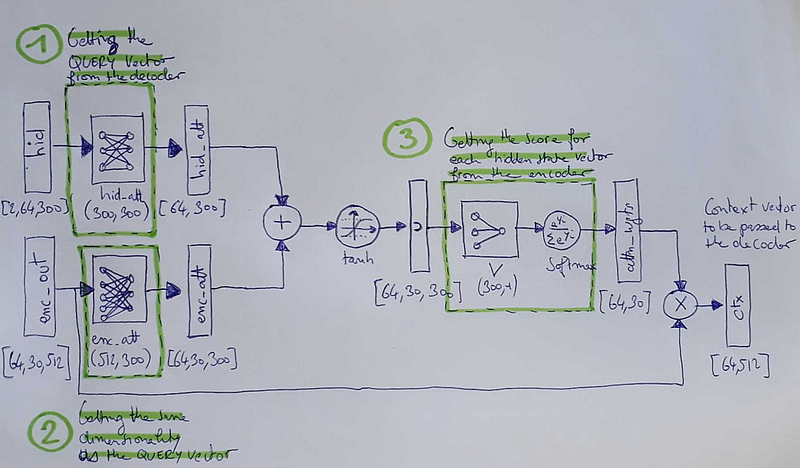
- [ hid_att — création d’un vecteur de requête spécifique ou query] A chaque émission d’un token par le decoder (réseau B), le vecteur d’état (hid) issu de ce décodage est passé en entrée d’un réseau de neurones linéaire (hid_att) sans couche cachée et qui ne modifie pas la dimensionnalité du vecteur d’état (dimension = nombre d’embeddings du vecteur d’état du decoder). Le but de cette transformation linéaire est de créer un vecteur de requête spécifique ou query (hid_att) vis-à-vis de la séquence d’entrée, requête dépendante de l’état actuel du décodage (ce que représente le vecteur d’état hid). Note: les valeurs des paramètres de ce réseau seront apprises lors de l’entraînement de l’ensemble du modèle Seq2Seq.
- [ enc_att — adaptation de la dimensionnalité du vecteur enc_out ] Le vecteur enc_out comporte l’ensemble des vecteurs d’état émis par l’encoder lors de l’encodage des tokens de la séquence d’entrée (ie, un vecteur d’état par token). Afin d’adapter sa dimensionnalité à celle du vecteur de requête hid_att, il est transformé linéairement en vecteur d’attention de l’encoder enc_att.
- [ u — création d’un vecteur de scores des vecteurs d’état de l’encoder ] Les vecteurs enc_att et hid_att sont alors additionnés linéairement et une fonction d’activation non-linéaire (tanh) est alors appliquée au vecteur résultant pour donner le vecteur u. Ce vecteur u est donc une combinaison altérée des vecteurs d’état de la séquence d’entrée ou encore un vecteur de scores de ces vecteurs. Il représente ainsi leur importance relative à ce moment de la génération d’un token de la séquence de sortie. A chaque nouvelle situation, le vecteur u est par conséquent différent.
- [ attn_wgts — création du vecteur des poids d’attention ] Le vecteur u est alors transformé en le vecteur attn_wgts via un réseau de neurones linéaire sans couche cachée (via une multiplication avec la matrice V initialisée avec des paramètres aléatoires qui seront ensuite appris lors de l’entraînement) avec en sortie une fonction d’activation softmax. Cela revient à transformer le vecteur u en probabilités qui sont ensuite normalisées. Ce vecteur attn_wgts contient ainsi les poids relatifs des vecteurs d’état de la séquence d’entrée à ce moment du décodage (ie, certains tokens de la séquence d’entrée ont plus d’importance que d’autres à ce moment du décodage). Il s’agit du vecteur des poids d’attention.
- [ ctx — création du vecteur de contexte ] En multipliant alors le vecteur enc_out (qui pour rappel est composé des vecteurs d’état créés par l’encoder de la séquence d’entrée) avec ce vecteur attn_wgts, nous obtenons alors le vecteur de contexte ctx qui est donc la somme pondérée des vecteurs d’état créés par l’encoder de la séquence d’entrée. Ce vecteur ctx représente ainsi l’importance relative de chaque token de la séquence d’entrée à ce moment du décodage.
- [ torc.cat([emb,ctx]) — prise en compte de l’attention lors du décodage ] Afin de prendre en compte ce vecteur ctx lors du décodage, il est concaténé avec le vecteur d’embeddings du token mis en entrée du decoder. Le vecteur résultant représente à la fois le précédent token de la séquence de sortie (généré par le decoder) mais aussi l’importance relative des tokens de la séquence d’entrée à considérer à ce moment du décodage. Le decoder reçoit alors ce vecteur de concaténation ainsi que le vecteur d’état précédent de décodage et peut alors générer le token suivant de la séquence de sortie “en faisant attention” et un nouvel état de décodage.
3. Code fastai




4. Applications
(source des exemples ci-dessous: “Attention and Augmented Recurrent Neural Networks”)
L’exemple le plus connu de l’utilisation du mécanisme d’attention dans un modèle seq2seq est la traduction (machine translation) où le mécanisme d’attention permet au decoder de tenir compte à chaque nouvelle étape (step time) de l’importance relative de l’ensemble des mots à traduire à ce moment du décodage et pas seulement du mot présenté en entrée du decoder.
Une autre application est la reconnaissance de paroles (voice recognition) où le premier RNN encode l’audio de la voix et le second donne une transcription en utilisant un mécanisme d’attention (papier “Listen, Attend and Spell” de 2015).
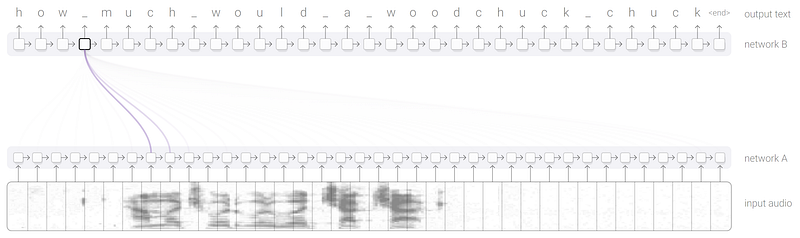
Parmi les autres utilisations de ce mécanisme d’attention, nous pouvons citer l’analyse de texte (parsing text), qui permet au modèle de générer l’arborescence d’analyse syntaxique (papier “Grammar as a foreign language” de 2015) ainsi que la modélisation conversationnelle (conversational modeling) qui permet au modèle de se concentrer sur les parties précédentes d’une conversation afin de générer sa réponse (papier “A Neural Conversational Model” de 2015).
Enfin, en ce qui concerne les modèles seq2seq avec du texte en entrée et en sortie, nous pouvons encore citer les applications suivantes: question/answering, summary, creation of a title et text generation.
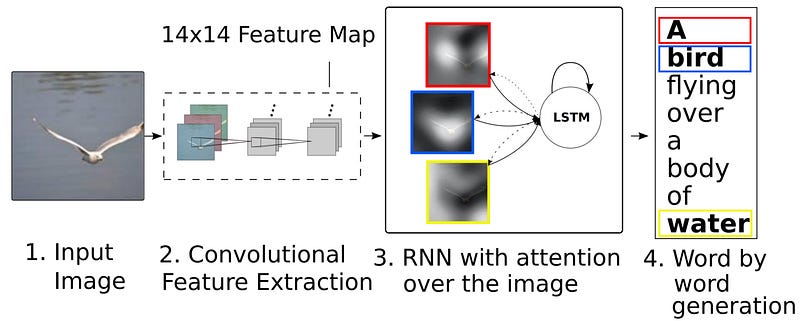
Le mécanisme d’attention peut également être utilisé dans un modèle seq2seq avec une entrée et une sortie de type différents. Nous avons déjà cité comme entrée non textuelle l’audio mais cela peut être aussi des images. Dans ce cas, l’encoder RNN est précédé d’un CNN et le décoder est un RNN. Une utilisation courante de ce type d’attention est le sous-titrage des images: le CNN va extraire les caractéristiques de l’image (features extraction), chaque plan de caractéristiques (feature maps) devenant alors l’équivalent d’un token qui est alors passé en entrée de l’encoder RNN alors que le decoder va générer ensuite une description de l’image utilisant un mécanisme d’attention sur les plans de caractéristiques. Ainsi, lorsqu’il génère chaque mot de la description, le RNN decoder se concentre sur l’interprétation des parties pertinentes de l’image. Nous pouvons explicitement visualiser ceci dans le papier “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention” de 2016.

Pour aller plus loin
- Neural Machine Translation by Jointly Learning to Align and Translate (2014–2016: Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio): un article étonnant qui a initialement introduit cette idée d’attention ainsi que quelques éléments clés qui ont vraiment changé la façon dont les gens travaillent dans ce domaine. Le modèle d’attention a été utilisé non seulement pour le texte mais aussi pour d’autres choses comme lire du texte sur des images ou dans le cadre de la vision par ordinateur.
- Grammar as a Foreign Language (2014–2015: Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, Geoffrey Hinton): le deuxième article dans lequel Geoffrey Hinton a été impliqué a utilisé cette idée de RNN avec attention pour essayer de remplacer la grammaire basée sur des règles par une RNN qui a automatiquement marqué chaque mot en fonction de la grammaire. Il s’est avéré que cela fonctionnait mieux que tout système basé sur des règles, ce qui semble évident aujourd’hui, mais à l’époque, il était considéré comme vraiment surprenant. Ils résument le fonctionnement de l’attention, ce qui est vraiment agréable et concis.
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (2015–2016: Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, Yoshua Bengio)
- (Global Attention) Effective Approaches to Attention-based Neural Machine Translation (2015: Minh-Thang Luong, Hieu Pham, Christopher D. Manning)
- Sequence to Sequence Learning with Neural Networks (septembre-décembre 2014, auteurs: Ilya Sutskever, Oriol Vinyals, Quoc V. Le)
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation (juin-septembre 2014: Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio)
- How Does Attention Work in Encoder-Decoder Recurrent Neural Networks in Deep Learning for Natural Language Processing (October 13, 2017: Jason Brownlee)
- Gentle Introduction to Global Attention for Encoder-Decoder Recurrent Neural Networks (October 31, 2017: Jason Brownlee): “The hidden state for each input time step is gathered from the encoder, instead of the hidden state for the final time step of the source sequence. A context vector is constructed specifically for each output word in the target sequence. First, each hidden state from the encoder is scored using a neural network, then normalized to be a probability over the encoders hidden states. Finally, the probabilities are used to calculate a weighted sum of the encoder hidden states to provide a context vector to be used in the decoder.”
- Let’s Pay Attention Now from “Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)” (mai 2018)
- How To Create Data Products That Are Magical Using Sequence-to-Sequence Models (janvier 2018)
- Brief Introduction to Attention Models (septembre 2019)
- Vidéos “Sequence to Sequence Models” (Deep Learning Specialization, Andrew Ng)
À propos de l’auteur: Pierre Guillou est consultant en Intelligence Artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.