
NLP & fastai | Sequence-to-Sequence Model (seq2seq)
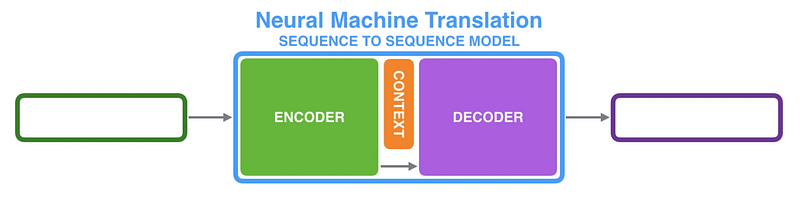
Ce post concerne les vidéos 12 et 14 du cours fastai de Rachel Thomas sur NLP (A code-first introduction to NLP) et la vidéo 11 (notes, 2018) du cours de Jeremy Howard (Introduction to Machine Learning for Coders). Son objectif est d’expliquer les concepts clés des modèles sequence-to-sequence en NLP présentés dans les vidéos et leurs notebooks associés: 7-seq2seq-translation.ipynb (NLP, 2019), bleu_metric.ipynb (NLP, 2019), 7b-seq2seq-attention-translation.ipynb (NLP, 2019), translate.ipynb (fastai 0.7, DL2, 2018) et translate.ipynb (fastai 1.0, DL2, 2018).
Autres posts de la série NLP & fastai: Topic Modeling | Sentiment Classification | Language Model | Transfer Learning | ULMFiT | MultiFiT | French Language Model | Portuguese Language Model | RNN | LSTM & GRU | SentencePiece | Attention Mechanism | Transformer Model | GPT-2
Motivation
De nombreux processus de transformation ou création délivrent une sortie comme un texte dont la taille n’est ni fixe, ni prévisible. Il peut s’agir par exemple de processus de traduction, de création de titres ou résumés à partir d’un texte, de création de légendes d’images…
Les modèles classiques de Deep Learning (Full Connected Network, ConvNet, RNN…) ne peuvent alors être utilisés pour ce type de processus puisque leur sortie est de taille fixe que ce soit une ou plusieurs classes, une ou plusieurs valeurs ou même une image.
En revanche, les modèles seq2seq de Deep Learning (DL) s’appliquent parfaitement à ces processus puisque par nature leur sortie n’est pas contrainte par une taille fixe.
Applications des modèles seq2seq
En plus des processus de traduction, les applications des modèles seq2seq sont multiples comme le montre le slide suivant:

Cependant, comme les principes sont les mêmes quelque soit les applications, il est intéressant de comprendre le codage d’un seq2seq pour la traduction afin de pouvoir le réutiliser pour d’autres situations.
Neural Machine Translation (NMT)
Ainsi, les modèles seq2seq avec Deep Learning (DL) sont utilisés avec succès depuis 2015 pour le Neural Machine Translation (NMT) et ont dépassé en terme de performance les modèles statistiques de traduction dès 2016 selon la métrique BLEU.
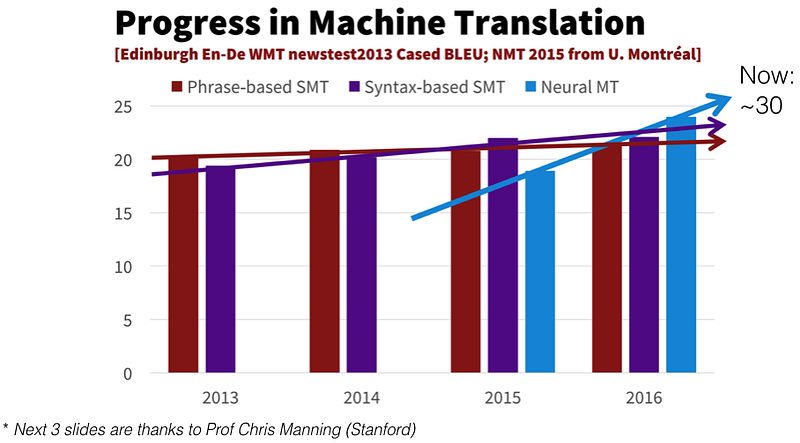
Le slide suivant met en avant 4 raisons pour lesquelles le NMT améliore nettement les résultats de traduction:

Architecture | Encoder/Decoder
De manière générale, il faut 3 choses pour entraîner un modèle de Machine Learning: des données, une architecture et une fonction de coût.
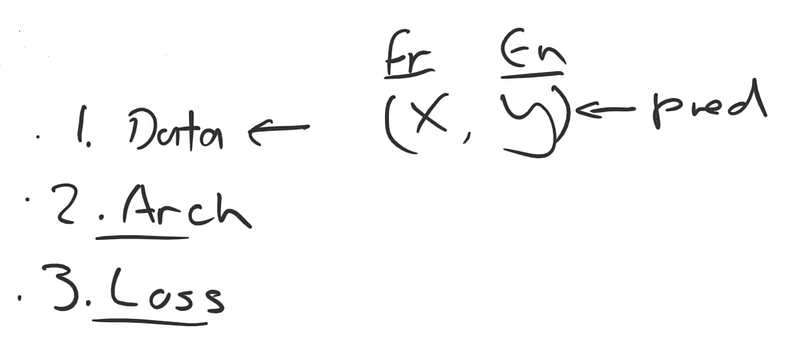
En fonction de l’objectif (classification, régression, entrée/sortie de taille fixe ou variable…), une peut être plus importante que les autres. Lorsqu’il s’agit de modèle seq2seq, c’est bien l’architecture du modèle qui est le point le plus important car c’est elle qui autorise que les données en entrée et sortie soient de taille variable et c’est elle qui permet au modèle d’avoir une mémoire et de faire attention au contexte.
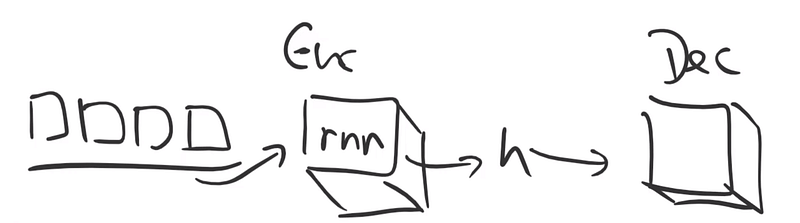
Diagramme
Voici ci-dessous un diagramme de l’architecture d’un modèle seq2seq:
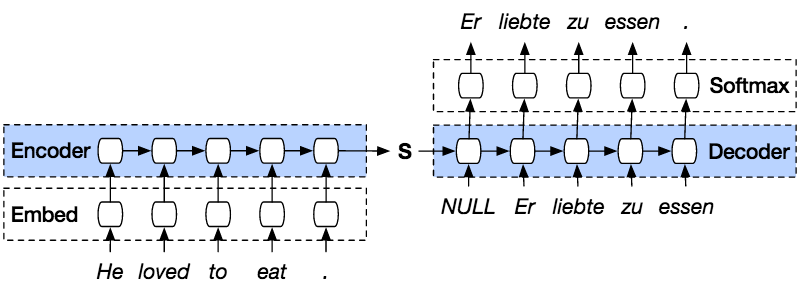
Principe
Le principe général est le suivant:
- chaque token en entrée (ici des mots ou ponctuation) est transformé en vecteur d’embedding (word vector) de taille identique (dimension de l’espace des embeddings, généralement de 200 ou 300) qui via l’encoder (RNN du backbone) va être transformé à son tour en vecteur d’état (ou vecteur de contexte).
- Une fois que l’ensemble des tokens de la séquence sont ainsi transformés, un vecteur d’état de l’ensemble de la séquence est généré (s: state vector, context vector, hidden vector ou hidden state): il contient donc toutes les informations décrivant la séquence (sa taille est généralement de 256, 512 ou 1024).
- Il est alors mis en entrée d’un decoder (un autre RNN) qui va générer au fur et à mesure les tokens de la séquence de sortie.
BLEU | Evaluation d’un modèle Seq2Seq
(source: Wikipedia) BLEU (BiLingual Evaluation Understudy) est un algorithme pour évaluer la qualité du texte qui a été traduit automatiquement d’une langue naturelle à une autre. La qualité est considérée comme la correspondance entre la traduction d’une machine et celle d’un humain: “plus une traduction automatique est proche d’une traduction humaine professionnelle, mieux c’est” — telle est l’idée centrale derrière BLEU. BLEU a été l’une des premières mesures à revendiquer une forte corrélation avec les jugements humains de qualité et demeure l’une des mesures automatisées et les moins chères les plus populaires.
Les scores sont calculés pour chaque segment traduit, généralement des phrases, en les comparant à un ensemble de traductions de référence de bonne qualité. Ces scores sont ensuite moyennés sur l’ensemble du corpus pour obtenir une estimation de la qualité globale de la traduction. L’intelligibilité ou la correction grammaticale ne sont pas prises en compte.
La sortie de BLEU est toujours un nombre compris entre 0 et 1. Cette valeur indique la similitude du texte candidat avec les textes de référence, les valeurs plus proches de 1 représentant des textes plus similaires. Peu de traductions humaines atteindront un score de 1, car cela indiquerait que le candidat est identique à l’une des traductions de référence. Pour cette raison, il n’est pas nécessaire d’atteindre un score de 1. Parce qu’il y a plus de possibilités de correspondance, l’ajout de traductions de référence supplémentaires augmentera le score BLEU.
Conseils pour améliorer un modèle Seq2Seq
3 procédés classiques peuvent être appliqués à un modèle Seq2Seq pour améliorer sa performance: Bidirectional (encoder), Teacher forcing et Attention.
Bidirectional
Vidéo & notes de la leçon 11 (DL2, 2018) — Timestamp [ 1:16:33 ] — notes
Ce procédé s’applique uniquement à l’encoder. Cependant, avec plusieurs couches dans l’encoder (Google Translate en a 8), il faut choisir laquelle(s) des couches est bidirectionnelle sinon des problèmes de performance comme le temps d’entraînement peuvent apparaître (Google Translate applique le procédé bidirectionnel seulement dans la première couche de son modèle Seq2Seq).
Teacher Forcing
Vidéo & notes de la leçon 11 (DL2, 2018) — Timestamp [ 1:22:39 ] — notes
Au début de l’entraînement, le modèle ne sait rien (paramètres avec des valeurs aléatoires) et donc s’il n’est pas aidé lors de la génération des premiers tokens par le decoder (comme un professeur peut aider un élève au début d’un exercice), il va avoir beaucoup de mal à commencer à apprendre.
Le procédé de Teacher Forcing permet ainsi de fournir en entrée de l’encoder les premiers tokens corrects de la séquence cible.
Attention
Vidéo & notes de la leçon 11 (DL2, 2018) — Timestamp [ 1:31:00 ] — notes
Pourquoi utiliser seulement le vecteur d’état final de la séquence (et espérer qu’il sera suffisant pour obtenir au moment du décodage toutes les caractéristiques de la séquence d’entrée) alors que nous disposons du vecteur d’état après chaque nouveau token de la séquence d’entrée?
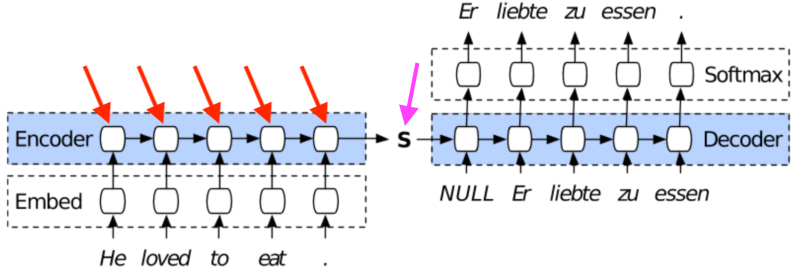
En entraînant un réseau neuronal, nous pouvons alors apprendre une matrice de valeurs pondérées de chacun de ces vecteurs d’état de la séquence d’entrée, ce qui permettra de prendre en compte de manière relative et appropriée chacun des tokens de la séquence d’entrée au moment de générer un token de la séquence de sortie par le decoder.
Ces valeurs pondérées représentent à chaque fois une estimation de l’attention à porter aux différents tokens de la séquence d’entrée lors de la génération séquentielle d’un nouveau token (par exemple, dans le cadre d’un modèle Seq2Seq de traduction de l’allemand vers le français, il faudra porter une attention aussi sur les derniers tokens de la phrase allemande en entrée lors de la génération des tokens de verbe de la phrase française en sortie et pas seulement sur les tokens correspondants en terme de position dans la séquence).

Pour aller plus loin
- Vidéos “Sequence to Sequence Models” (Deep Learning Specialization, Andrew Ng)
- Sequence to Sequence Learning with Neural Networks (septembre-décembre 2014, auteurs: Ilya Sutskever, Oriol Vinyals, Quoc V. Le)
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation (juin-septembre 2014: Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio)
- Neural Machine Translation by Jointly Learning to Align and Translate (2014–2016: Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio): nn article étonnant qui a initialement introduit cette idée d’attention ainsi que quelques éléments clés qui ont vraiment changé la façon dont les gens travaillent dans ce domaine. Le modèle d’attention a été utilisé non seulement pour le texte mais aussi pour d’autres choses comme lire du texte sur des images ou dans le cadre de la vision par ordinateur.
- Grammar as a Foreign Language (2014–2015: Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, Geoffrey Hinton): le deuxième article dans lequel Geoffrey Hinton a été impliqué a utilisé cette idée de RNN avec attention pour essayer de remplacer la grammaire basée sur des règles par une RNN qui a automatiquement marqué chaque mot en fonction de la grammaire. Il s’est avéré que cela fonctionnait mieux que tout système basé sur des règles, ce qui semble évident aujourd’hui, mais à l’époque, il était considéré comme vraiment surprenant. Ils résument le fonctionnement de l’attention, ce qui est vraiment agréable et concis.
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) (mai 2018)
- How To Create Data Products That Are Magical Using Sequence-to-Sequence Models (janvier 2018)
À propos de l’auteur: Pierre Guillou est consultant en Intelligence Artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.