
NLP & fastai | MultiFiT
L’objectif de ce post est de présenter les concepts clés de la méthode MultiFiT de fastai et son architecture associée. Son contenu a été présenté par Pierre Guillou lors du séminaire sur le “Processamento de Linguagem Natural” du Groupe d’Etude du Deep Learning à Brasília le lundi 02/12/2019.
Autres posts de la série NLP & fastai: Topic Modeling | Sentiment Classification | Language Model | Transfer Learning | ULMFiT | French Language Model | Portuguese Model Language | RNN | LSTM & GRU | SentencePiece | Sequence-to-Sequence Model (seq2seq) | Attention Mechanism | Transformer Model | GPT-2
BLOG | Efficient multi-lingual language model fine-tuning
Source: http://nlp.fast.ai/classification/2019/09/10/multifit.html
Le 10 septembre 2019, Sebastian Ruder publiait sur le site de fastai le post “Efficient multi-lingual language model fine-tuning”.
Ce post annonçait la publication d’une nouvelle méthode de classification de textes appelée MultiFiT (Multi-lingual Language Model Fine-tuning), évolution de la méthode ULMFiT (Universal Language Model Fine-tuning for Text Classification) publiée presque 2 ans auparavant au début de l’année 2018.
L’idée du MultiFiT était double:
- faciliter le téléchargement et la formation de modèles sur Wikipédia dans n’importe quelle langue (Wikipedia ou potentiellement sur CommonCrawl à l’avenir).
- fournir un zoo modèle constitué de modèles de langues pré-entraînés dans de nombreuses langues, que les utilisateurs peuvent ensuite simplement ajuster pour leurs propres applications.

PAPER | MultiFiT: Efficient Multi-lingual Language Model Fine-tuning
Source: https://arxiv.org/abs/1909.04761
Le post de Sebastian Ruder — publié en association avec Julian Eisenschlos, Piotr Czapla, Marcin Kardas, Sylvain Gugger, Jeremy Howard — présentait à la fois le concept idéologique sous-jacent au MultiFiT (ne pas laisser croire qu’un classificateur entraîné sur un corpus en anglais puisse classifier avec un haut niveau de performance — et sans Transfer Learning , ni fine-tuning— un texte dans une autre langue comme le fait Multi-Lingual BERT), sa nature qui est d’entraîner un modèle de langage par langue (pour ensuite le mettre à disposition en ligne afin de pouvoir le spécialiser sur des tâches comme la classification) et son architecture qui diminue fortement le temps d’entraînement tout en augmentant la performance (principalement: remplacement du tokenizer SpaCy par SentencePiece, des 3 couches AWD-LSTM par 4 couches QRNN avec 1550 activations chacune et de la fonction de loss par Smooth Loss).

CÓDIGO | Github
Source: https://github.com/n-waves/multifit
MultiFiT fait parti aujourd’hui de la bibliothèque fastai. Son code est disponible en ligne sur github ainsi que 7 modèles entraînés sur les langues suivantes: allemand, espagnol, français, italien, japonais, russe et chinois.
Comment ajuster (fine-tune) un modèle MultiFiT déjà entraîné avec fastai v1.0
Source: https://github.com/n-waves/multifit#how-to-use-it-with-fastai-v10
Le code suivant permet de spécialiser (fine-tune) un modèle MultiFiT (déjà entraîné) sur un corpus de la même langue et d’en extraire son encoder qui permettra alors de créer un modèle particulier comme un classificateur.
from fastai.text import *
import multifitexp = multifit.from_pretrained("name of the model")
fa_config = exp.pretrain_lm.tokenizer.get_fastai_config(add_open_file_processor=True)
data_lm = (TextList.from_folder(imdb_path, **fa_config)
.filter_by_folder(include=['train', 'test', 'unsup'])
.split_by_rand_pct(0.1)
.label_for_lm()
.databunch(bs=bs))
learn = exp.finetune_lm.get_learner(data_lm)
# learn is a preconfigured fastai learner with a pretrained model loaded
learn.fit_one_cycle(10)
learn.save_encoder("enc")
...Architecture et entraînement d’un modèle MultiFiT
Source: https://arxiv.org/abs/1909.04761 (cf dernière page)
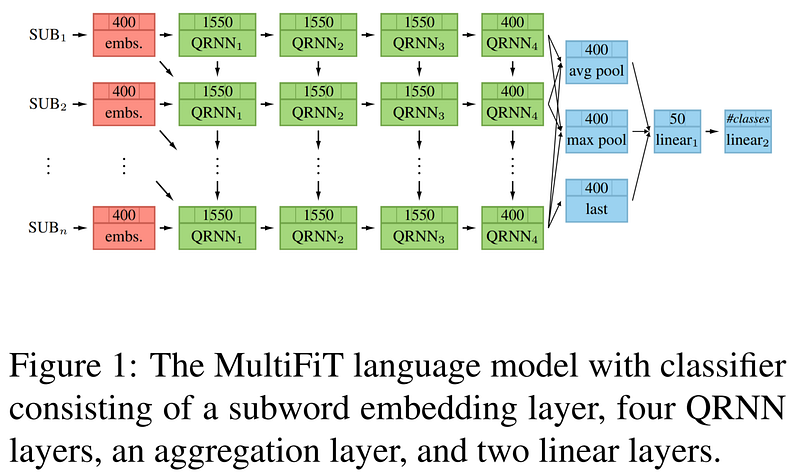
Voici copié/collé du paper MultiFiT, les explications en anglais sur l’architecture du MultiFiT et sa méthode d’entraînement:
(from the paper) The MultiFiT architecture has:
- 4 QRNN layers with a hidden dimensionality of 1550,
- a vocabulary size of 15,000 subword tokens (SentencePiece)
- and an embeding size of 400.
The vocabularies were computed using the SentencePiece unigram language model (Kudo, 2018) with 99% character coverage for Chinese and Japanese and 100% for the rest. The encoder’s and decoder’s weights are shared (Press and Wolf, 2017).
The output of the last QRNN layer (the last time step concatenated with an average and maximum pooled over time steps) is passed to the classifier with 2 dense layers. Our language models were trained for 10 epochs on 100 million tokens of Wikipedia articles and then fine-tuned for 20 epochs on the corresponding dataset (MLDoc or CLS).
The classifier was fine-tuned for 4 to 8 epochs. Results of the best model based on accuracy on the validation set are reported.
We used a modified version of 1-cycle learning rate schedule (Smith, 2018) that uses cosine instead of linear annealing, cyclical momentum and discriminative finetuning (Howard and Ruder, 2018).
Our batch size for language model training was 50 and for classification tasks 18. We were using BPTT of length 70. Due to the large amount of available training data our pretrained language models were trained without any dropout.
We used the same dropout values as (Howard and Ruder, 2018) multiplied by 0.3 and 0.5 for fine-tuning of language models and the classification task respectively. We used weight decay of 0.01 for both tasks. The final regularization method was label smoothing (Szegedy et al., 2016) with epsilon of 0.1.
fastai | Passer de ULMFiT à MultiFiT
Si vous voulez créer votre propre code (ie, sans utiliser celui sur github), vous pouvez réutiliser les 2 notebooks présentés ci-après dans le paragraphe “MultiFiT pour le portuguais”.
Vous verrez que le code du MultiFiT réutilise le code du ULMFiT à 2 changements près:
1. Utilisation du tokenizer SentencePiece au lieu de SpaCy
Comme le tokenizer par défaut dans fastai v1 est SpaCy, il faut spécifier l’utilisation de SentencePiece lors de l’entraînement du modèle de langage général. Pour cela, il faut donner la taille du vocabulaire lors de la création du Databunch et utiliser la class SPProcessor.
Voici ci-dessous un exemple de code fastai avec un vocabulaire de taille 15 000:
data = (TextList.from_folder(dest, processor=[OpenFileProcessor(), SPProcessor(max_vocab_sz=15000)])
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=1))Lors du Transfer Learning du modèle de langage général pour le spécialiser à un corpus de la même langue, il faut passer dans le Databunch du nouveau corpus le modèle et le vocabulaire créés par SentencePiece dans le corpus du modèle général.
Voici ci-dessous un exemple de code fastai:
# un répertoire tmp dans le répertoire corpus_general a été automatiquement créé lors de la première utilisation de SentencePiece (databunch du modèle de langage général) afin d'enregistrer les paramêtres du modèle et le vocabulaire détecté
dest = path/corpus_generaldata_lm = (TextList.from_df(df_trn_val, path, cols=reviews, processor=SPProcessor.load(dest))
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=1))2. Changement de l’architecture du modèle
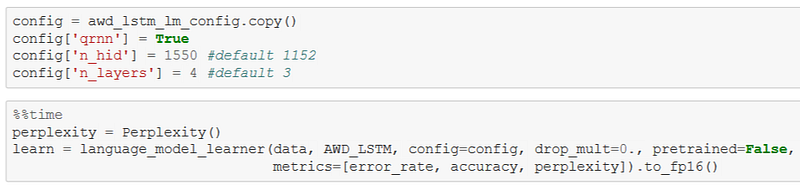
MultiFiT utilise une architecture QRNN en 4 couches avec 1550 activations chacune. Pour utiliser cette architecture dans le modèle à entraîner, il suffit de changer la configuration (argument config dans language_model_learner()) du modèle ULMFiT qui utilise un AWD-LSTM en 3 couches avec 1152 activations chacune.
Voici ci-dessous un exemple de code fastai:
Applications
MultiFiT pour le portugais
Source: NLP & fastai | Portuguese Language Model

Notebooks
- lm3-portuguese.ipynb (nbviewer): modèle de langage général bidirectionnel du portugais (MultiFiT) entraîné sur un corpus de 100 millions de tokens extraits de Wikipedia en portugais.
- lm3-portuguese-classifier-TCU-jurisprudencia.ipynb (nbviewer): modèle de langage bidirectionnel du portugais (et classificateur associé) spécialisé sur un corpus de documents de jurisprudence de la Cour Fédérale des Comptes (TCU, Tribunal de Contas da União à Brasilia (Brésil)) à partir du modèle de langage général bidirectionnel du portugais précédent utilisant la technique du Transfer Learning.
- Paramètres à télécharger: Models and Vocabularies
MultiFiT pour le français
Source: NLP & fastai | French Language Model
Tous les liens vers les notebooks et les explications se trouvent dans le post.

Ressources
- Understanding building blocks of ULMFIT
- (fastai) Using QRNN in Language Models
- (fastai) Multilingual ULMFiT
- New neural network building block allows faster and more accurate text understanding
- Quasi-Recurrent Neural Network (QRNN) for PyTorch
- Paper Dissected: “Quasi-Recurrent Neural Networks” Explained
- New Neural Network Building Block Allows Faster and More Accurate Text Understanding
À propos de l’auteur: Pierre Guillou est consultant en Intelligence Artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.




