
NLP & fastai | GPT-2

Autres posts de la série NLP & fastai: Topic Modeling | Sentiment Classification | Language Model | Transfer Learning | ULMFiT | MultiFiT | French Language Model | Portuguese Language Model | RNN | LSTM & GRU | SentencePiece | Sequence-to-Sequence Model (seq2seq) | Attention Mechanism | Transformer Model
Autres posts de la série GPT-2 : Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)
Références fastai
Ce post concerne la vidéo 19 du cours fastai de Rachel Thomas sur NLP (A code-first introduction to NLP).
Motivation
Et si une intelligence artificielle pouvait écrire de manière conditionnée (cad en suivant des directions imposées par un humain) et réaliser également toutes sortes de tâches en langage naturel comme comprendre un texte, répondre à des questions, résumer un texte ou le traduire?
Comme l’a dit Jeremy Howard en février 2019 dans l’article “OpenAI’s new multitalented AI writes, translates, and slanders” sur The Verge, nous sommes arrivés à un moment où ce rêve (un désir? un cauchemar pour certains…) est entrain de devenir réalité avec le GPT-2 d’OpenAI qui pourrait en particulier remplir le Web de ses écrits (“I’ve been trying to warn people about this for a while. We have the technology to totally fill Twitter, email, and the web up with reasonable-sounding, context-appropriate prose, which would drown out all other speech and be impossible to filter.”).
Ce post propose de mieux comprendre ce que peut faire (GPT-2 est connu pour savoir écrire mais en fait il peut réaliser toutes sortes de tâches de NLP (Natural Language Processing) comme détection de similarité, questions/réponses, résumé, traduction, etc.) et ce que ne peut pas faire ce modèle (toujours pas de compréhension, ni de sens commun…) ou moins bien (classification de textes?) qui a tant fait parlé de lui dans les médias (lire “Finally, a Machine That Can Finish Your Sentence” publié en novembre 2018 dans le New-York Times, “New AI fake text generator may be too dangerous to release, say creators” publié sur The Guardian en février 2019 et “OpenAI has published the text-generating AI it said was too dangerous to share” publié en novembre 2019 sur The Verge).
Points-clés du modèle GPT-2
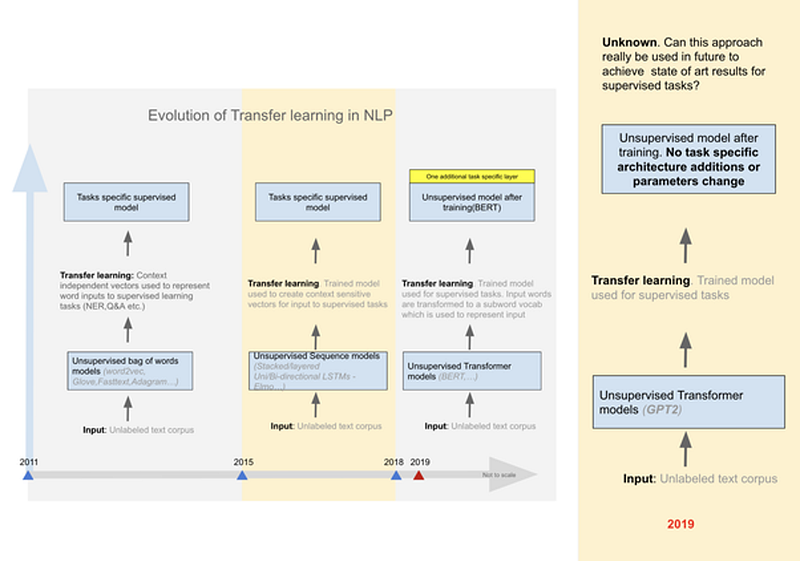
Comme nous le comprendrons ci-après, le modèle GPT-2 est le résultat d’une quête d’un modèle de langage universel autant en terme de capacités linguistiques qu’en termes de tâches de NLP.
Sur plusieurs points, GPT-2 répond présent mais avec des nuances que nous allons rappeler:
- Basé sur une architecture transformer de type decoder, il s’agit d’un modèle de langage, cad un modèle qui a appris une langue en étant entraîné a prévoir le prochain mot d’une séquence de mots.
- La taille (40 Go) et la diversité de son dataset d’entraînement font revendiquer à son créateur (OpenAI) qu’il est un modèle “zero-shot learning”, cad un modèle qui a appris une représentation universelle d’une langue, ce qui impliquerait qu’il n’y aurait pas besoin de le ré-entraîner sur un nouveau corpus afin d’obtenir une performance de haut niveau sur une tâche NLP appliquée à ce corpus (cette affirmation est certainement fausse car il faudrait un dataset bien plus grand et plus complexe pour approcher une telle réalité mais GPT-2 a cependant amélioré de manière significative ce type de modèle).
- Son architecture combinée à ce dataset grand et diversifié amène OpenAI à le qualifier de modèle “zero-shot setting”, cad qu’il n’y aurait pas besoin de spécialiser son architecture pour lui faire faire de nouvelles tâches NLP en plus de la génération de texte (en fait, même s’il est vrai qu’il n’y a pas besoin de changer son architecture pour le spécialiser — sauf peut-être pour la classification qui nécessite une couche finale fully-conected suivie par un softmax -, il faut cependant le conditionner, cad l’entraîner de nouveau, en lui apprenant à reconnaître l’implication d’une balise insérée dans la séquence d’entrée sur le texte à générer: résumé, traduction, etc.).
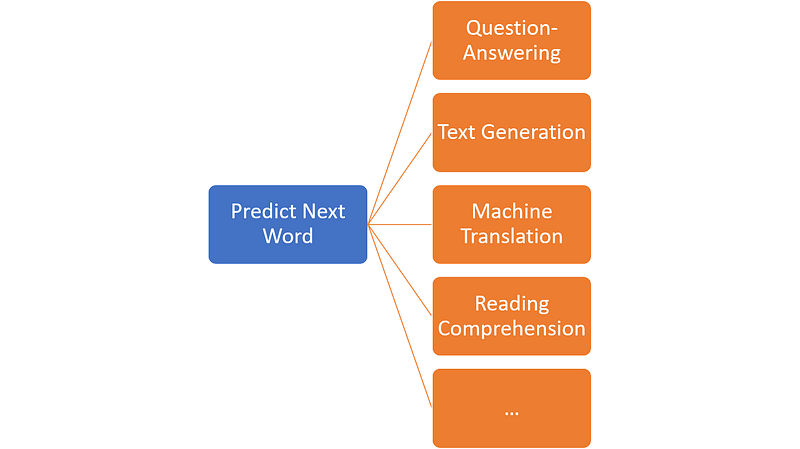
- Comme nous venons de l’écrire, le modèle GPT-2 peut réaliser toutes les tâches de NLP et pas seulement la génération d’un texte à partir d’une séquence d’entrée mais c’est dernière tâche que OpenAI a mis en avant et qui a fait son succès dans les médias (en fait toute tâche de NLP peut être ramenée à une génération d’un ou plusieurs nouveaux tokens: c’est pour cela que le modèle GPT-2 peut réaliser toutes les tâches de NLP).
- Enfin, il est important de ne pas rester ébloui par les titres des médias: quelques tests simples montrent que GPT-2 ne comprend rien de ce qu’il écrit, qu’il n’a aucun sens commun, ni aucune logique. Il n’en reste pas moins que avec ce modèle OpenAI (et bien sûr Google AI avec son modèle transformer) a ouvert la voie à une recherche active pour trouver le modèle de langage universel dont beaucoup rêve tandis que beaucoup d’autres le redoute.
Historique du modèle GPT-2 d’Open AI
Avril 2017 | Transfer Learning d’un modèle de langage pré-entraîné de manière non-supervisée
OpenAI applique pour la première fois en 2017 les enseignements du papier scientifique “Semi-supervised Sequence Learning” publié en 2015, à savoir la technique du Transfer Learning des représentations apprises d’un modèle de langage entraîné de manière non-supervisée pour effectuer d’autres tâches comme la classification de sentiments ou de textes.
OpenAI entraîne en effet le Sentiment Neuron de manière non-supervisée (RNN avec mLSTM — cf. “Multiplicative LSTM for sequence modelling” de 2016) à prévoir le caractère suivant, puis le transforme en Classificateur par l’ajout d’une couche fully-connected de sortie afin de pouvoir détecter par entraînement supervisé le sentiment d’une phrase avec une bonne performance et peu de données d’entraînement comparativement à un classificateur entraîné avec des paramètres initialisés avec des valeurs aléatoires (cf. “Unsupervised Sentiment Neuron”).
A la même période, Google AI finalise l’entraînement du premier modèle Transformer qui donnera lieu à la publication du papier scientifique “Attention Is All You Need” en juin 2017.
A lire:
- (unsupervised pre-training) Semi-supervised Sequence Learning (novembre 2015: Andrew M. Dai, Quoc V. Le)
- (sentiment neuron) Learning to Generate Reviews and Discovering Sentiment (avril 2017: Alec Radford, Rafal Jozefowicz, Ilya Sutskever) et le post sur OpenAI: Unsupervised Sentiment Neuron
- Attention Is All You Need (juin — décembre 2017: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin) et le post sur Google AI: Transformer: A Novel Neural Network Architecture for Language Understanding (août 2017: Jakob Uszkoreit — Google AI)
Juin 2018 | GPT (Generative Pre-Training), un modèle “task agnostic”, cad ne demandant qu’une légère adaptation de son architecture pour effectuer une nouvelle tâche NLP
Sur la base de son expérience avec le Sentiment Neuron et dans la continuité du chemin ouvert par Jeremy Howard (fastai) avec le ULMFiT en janvier 2018, OpenAI applique le même processus d’entraînement de manière non-supervisée d’un modèle de langage qui est ensuite spécialisé par entraînements supervisés à différentes tâches de NLP (Transfer Learning + fine-tuning) mais cette fois-ci à un modèle transformer (la partie des decoders) et afin d’effectuer 4 tâches de NLP:
- en sens commun (commonsense reasoning): reconnaissance d’implication textuelle (recognizing textual entailment/natural language inference (NLI)) et similarité sémantique (semantic similarity)
- en compréhension de lecture (reading comprehension): Question/Réponse (Question/Answering) et classification de textes (text classification)
Par utilisation d’un dataset d’entraînement relativement grand (5 Go), l’objectif est que le modèle de langage apprenne une représentation universelle de la langue du corpus d’entraînement afin de pouvoir ensuite l’utiliser pour réaliser différentes tâches en NLP avec le minimum de modification de son architecture.
Comment? A la différence de la plupart des modèles basés sur le Transfer Learning pour réaliser des tâches différentes, c’est la structure de l’entrée qui est adaptée à la tâche à réaliser (concaténation des textes et de leurs labels en une séquence de tokens comme par exemple, concaténation d’un texte et de sa réponse possible dans le cadre d’un modèle Question/Réponse) et non la sortie qui reste avec une couche fully-connected suivi par un softmax permettant ainsi une classification, cad le choix entre un oui ou un non.
Le modèle et son processus d’entraînement sont présentés dans le papier scientifique “Improving Language Understanding by Generative Pre-Training” de juin 2018. Voici quelques extraites de ce papier:
- task-specific architectures are no longer necessary and transferring many self-attention blocks is sufficient
- During transfer, we utilize task-specific input adaptations derived from traversal-style approaches, which process structured text input as a single contiguous sequence of tokens. As we demonstrate in our experiments, these adaptations enable us to fine-tune effectively with minimal changes to the architecture of the pre-trained model.
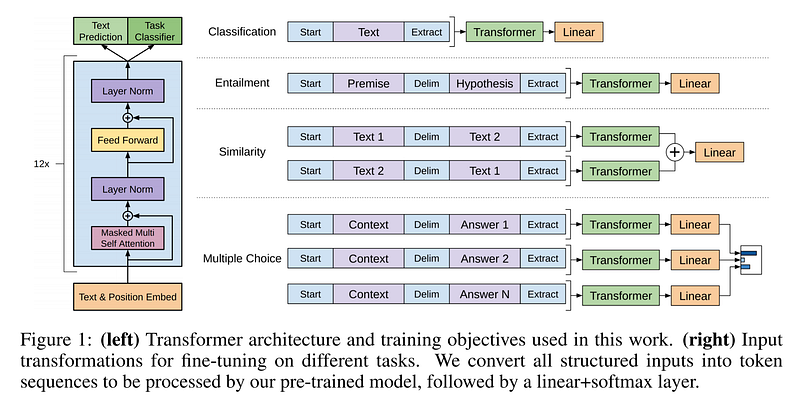
L’entraînement du pré-modèle s’est fait pendant 1 mois sur 8 GPUs NVIDIA P100. Le modèle tranformer utilisé (environ 150 millions de paramètres) avait 12 couches de type decoder (chaque couche avec une sous-couche de self-attention masquée implémentée sur 12 multi-head suivi par un réseau feed-forward avec résidual et normalisation) et l’entraînement s’est fait sur des séquences de 512 tokens. Les détails des hyperparamètres utilisés ainsi que la méthode d’entraînement sont donnés en page 5 du papier scientifique.
La taille du dataset d’entraînement était de 5 Go venant de la base de textes issus de livres BookCorpus (plus de 7 000 livres inédits uniques de divers genres, dont Adventure, Fantaisie et roman). La puissance totale de computation était donc de 0.96 Petaflop jour (pfs-day) selon la formule suivante:
8 P600 GPU's * 30 days * 12 TFLOPS/GPU * 0.33 utilization =
= .96 pfs-day
Les datasets de spécialisation à des tâches NLP étaient les suivants:
- Choice of Plausible Alternatives (COPA): COPA fournit aux chercheurs un outil pour évaluer les progrès du raisonnement causal. COPA se compose de 1 000 questions, réparties également en ensembles de développement et de test de 500 questions chacun. Chaque question est composée d’une prémisse et de deux alternatives, où la tâche est de sélectionner l’alternative qui a plus vraisemblablement une relation causale avec la prémisse (CAUSE ou CONSEQUENCE).
- RACE (Large-scale ReAding Comprehension Dataset From Examinations, 2017): Race est un ensemble de données de compréhension à grande échelle avec plus de 28 000 passages et près de 100 000 questions. L’ensemble de données est collecté à partir d’examens d’anglais en Chine, qui sont conçus pour les collégiens et lycéens. L’ensemble de données peut être utilisé comme ensemble de formation et de test pour la compréhension machine.
- ROCStories: ‘Story Cloze Test’ est un nouveau cadre de raisonnement de bon sens pour évaluer la compréhension de l’histoire, la génération de l’histoire et l’apprentissage du script. Ce test nécessite de choisir la fin correcte d’une histoire de quatre phrases. Nous proposons le test Story Cloze pour remplacer l’état de l’art pour évaluer l’apprentissage de la structure narrative, le ‘Narrative Cloze Test’ (Chambers & Jurafsky, 2008). Pour permettre le test Story Cloze, nous avons créé un nouveau corpus d’histoires à 5 phrases appelé ROCStories. Ce corpus est unique de deux manières: (1) il capture un riche ensemble de relations de sens commun causales et temporelles entre les événements quotidiens, et (2) il s’agit d’une collection de haute qualité d’histoires de la vie quotidienne qui peut également être utilisée pour la génération d’histoires.
- MultiNLI (Multi-Genre Natural Language Inference): le corpus MultiNLI est une collection provenant de 433k paires de phrases annotées avec des informations d’implication textuelles. Le corpus est calqué sur le corpus SNLI, mais diffère en ce qu’il couvre une gamme de genres de texte parlé et écrit, et prend en charge une évaluation de généralisation inter-genres distincte.
- GLUE Benchmark (General Language Understanding Evaluation): le référentiel GLUE est une collection de ressources pour la formation, l’évaluation et l’analyse des modèles de compréhension du langage naturel. GLUE se compose de: ** Un référentiel de neuf tâches de compréhension de la phrase ou de la paire de phrases construit sur des ensembles de données existants établis et sélectionnés pour couvrir une gamme variée de tailles d’ensembles de données, de genres de texte et de degrés de difficulté. ** Un ensemble de données de diagnostic conçu pour évaluer et analyser les performances du modèle par rapport à un large éventail de phénomènes linguistiques trouvés dans le langage naturel. ** Un classement public pour suivre les performances de l’indice de référence.
Note: le modèle ULMFiT consiste à entraîner de manière supervisée un classificateur de textes avec 100 données par classe pour des performances supérieures aux modèles de l’état de l’art (100 fois moins de données d’entraînement que les précédents modèles) à partir du Transfer Learning d’un modèle de langage pré-entraîné de manière non-supervisée et avec des techniques optimisées de “discriminative fine-tuning” et de régularisation. Le modèle ULMFiT est basé sur des RNNs de type LSTM (précisément AWD-LSTM ou QRNN pour la version MultiFiT de septembre 2019) qui ne sont pas suffisant selon OpenAI pour se souvenir de toutes les caractéristiques de longs textes. C’est pour cette raison que OpenAI a basé son GPT sur le modèle Transformer.
Lire:
- ULMFiT — Universal Language Model Fine-tuning for Text Classification (janvier — mai 2018: Jeremy Howard, Sebastian Ruder)
- Document generation — Generating Wikipedia by Summarizing Long Sequences (mai 2018: )
- GPT — Improving Language Understanding by Generative Pre-Training (juin 2018: Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever) et le post sur OpenAI: Improving Language Understanding with Unsupervised Learning
- Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books (juin 2015: Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler) et le site Aligning Books and Movies
- (ULMFiT et GPT) Transfer Learning in NLP for Tweet Stance Classification (janvier 2019, Prashanth Rao)
Février 2019 | GPT-2, un modèle de langage généraliste (“zero-shot learning” et “zero-shot setting”)
En février 2019, OpenAI annonce l’existence du successeur du GPT appelé GPT-2. Ce modèle, toujours basé sur une architecture transformer (la partie des decoders), annonce un changement de paradigme: au lieu de pré-entraîner un modèle de langage qui devra ensuite être entraîné de nouveau par Transfer Learning et fine-tuning sur un nouveau corpus afin de réaliser une tâche NLP spécifique, pourquoi ne pas créer un modèle de langage généraliste à la fois vis-à-vis des domaines mais aussi des tâches par l’utilisation d’un dataset d’entraînement considérablement augmenté mais aussi très diversifié?
L’hypothèse était en effet que le modèle de langage ainsi (sur)entraîné pourrait alors réaliser n’importe quelle tâche de NLP SANS devoir être entraîné de nouveau puisque il aurait déjà appris ces différentes tâches de manière sous-jacente lors de son apprentissage de la langue du corpus d’entraînement (ie, comme si apprendre une langue revenait à apprendre une série de tâches comme savoir classifier, comprendre un texte, trouver la co-référence d’un pronom, savoir résumer, etc.).
En suivant cette idée, OpenAI a ainsi créé GPT-2 qui est donc le premier modèle avec “zero-shot learning” (ou “zero-shot domain transfer”) et “zero-shot setting” (ou “zero-shot task transfer”), et qui en plus des tâches de NLP que réalisait son prédécesseur le modèle GPT, est à présent capable de générer des textes de manière conditionnée (résumé de textes, nouveau texte à partir d’une phrase, etc.).
Le modèle et son processus d’entraînement sont présentés dans le papier scientifique “Language Models are Unsupervised Multitask Learners” de février 2019. Voici quelques extraites de ce papier:
- Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText
- The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks.
- When a large language model is trained on a sufficiently large and diverse dataset it is able to perform well across many domains and datasets. GPT-2 zero-shots to state of the art performance on 7 out of 8 tested language modeling datasets. The diversity of tasks the model is able to perform in a zero-shot setting suggests that high-capacity models trained to maximize the likelihood of a sufficiently varied text corpus begin to learn how to perform a surprising amount of tasks without the need for explicit supervision.
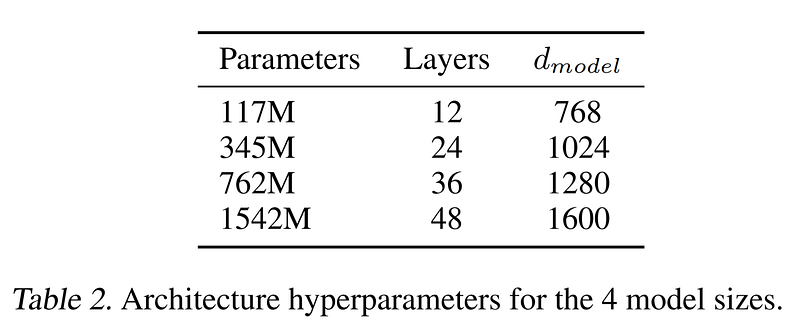
Voyant ce potentiel créatif comme un possible risque pour une société connectée aux réseaux sociaux où une information peut avoir un impact fort sur le cours de la démocratie ou sur l’économie d’une société ou d’un pays, OpenAI a alors décidé initialement de ne publier que le code et les paramètres d’une version Small du GPT-2 (117 Mo) au lieu de ceux de la version optimale (1.5 milliards de paramètres) qui ne seront publiés qu’en novembre de la même année (cf. en février 2019, les articles “OpenAI’s new multitalented AI writes, translates, and slanders” sur The Verge, “Some thoughts on zero-day threats in AI, and OpenAI’s GPT-2” de Jeremy Howard sur fast.ai et en février 2017, le rapport “The Malicious Use of Artificial Intelligence”).
A propos du dataset d’entraînement: l’objectif était d’obtenir un très grand corpus d’entraînement très diversifié (ce qui permet au modèle d’apprendre à la fois plus sur la langue et plus sur les différentes tâches NLP). Pour ce faire, OpenAI a aspiré les contenus Web pointés par le site Reddit qui avaient au moins 3 karma. L’ensemble des données résultant, WebText, contient le sous-ensemble de texte de ces 45 millions de liens avec un peu plus de 8 millions de documents pour un total de 40 Go de texte. Les textes Wikipedia, qui sont classiquement utilisés, n’ont pourtant pas été gardés afin de ne pas risquer d’entraîner le modèle avec des textes qui se retrouveraient dans des datasets de test de compétitions en ligne.
Ce dataset a été tokénisé via BPE (Byte Pair Encoding) et comme son prédécesseur, le modèle GPT, le modèle GPT-2 n’est constitué que de couches de decoders du modèle Transformer, cad avec des couches comprenant des sous-couches de self-attentions masquées (en entrée, le modèle ne dispose que des tokens précédents le token actuel et non les tokens le suivant).
Lire:
- The Natural Language Decathlon: Multitask Learning as Question Answering (juin 2018: Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher — Salesforce)
- GPT-2 — Language Models are Unsupervised Multitask Learners (février 2019: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever — OpenAI) et le post sur OpenAI: Better Language Models and Their Implications
- GPT-2 from OpenAI: Better NLP model and the ethics issues it raises (juin 2019, Data Science lab): “The innovation of GPT-2 seems to lie in the objective by the research team, to use the so-called Zero-shot learning method to evaluate the performance of the tool, and therefore to train it (Example: Recognize any object that has never been previously represented in the training database). In the case of language processing, it is a matter of entering a text that has never been learned previously by the model and assessing the consistency of the program’s response to it. The Zero-shot learning method uses class and word embedding or “word immersion”, associating a vector and thus a continuous representation in a space to a discrete variable (a class, or here a word). This allows the algorithm to recognize texts that are not represented in the test set and associate them with themes and thus with other words known to the model, which have been previously processed in the learning phase. Evaluated on different text comprehension, summary, reasoning and translation exercises, the model is ahead of the existing LMBC (Language Modeling of Broad Contexts — predicting the word following a sentence or paragraph) and CSR (Common Sense Reasoning — determining the meaning of an ambiguous pronoun) exercises. According to OpenAI, the model has not been trained in these specific areas.”
- openai/gpt-2
- huggingface/transformers et Docs on Transformers
Mai 2019
Mise en ligne de la version GPT-2 avec 355 millions de paramètres (équivalente à BERT).
Août 2019
Mise en ligne de la version GPT-2 avec 774 millions de paramètres.
A lire:
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août — novembre 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang) et le post sur OpenAI: GPT-2: 1.5B Release
Novembre 2019
Mise en ligne de la version GPT-2 avec 1.5 milliards de paramètres.
A lire:
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août — novembre 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang) et le post sur OpenAI: GPT-2: 1.5B Release
- Code du GPT-2 et dataset: openai/gpt-2 et gpt-2-output-dataset
Modèle GPT-2 expliqué
The Illustrated GPT-2 (Visualizing Transformer Language Models) de Jay Alammar en août 2019 est certainement le post le plus complet et le plus visuellement pédagogique pour comprendre le fonctionnement du GPT-2.
Implémenter GPT-2
Afin d’implémenter le modèle GPT-2, les documents suivants sont certainement les plus intéressants:
- The Annotated GPT-2 (février 2020: Aman Arora)
- How to train a new language model from scratch using Transformers and Tokenizers (février 2020, Hugging Face)
- Mikhail Grankin a adapté un script de la bibliothèque de transformers Hugging face afin de permettre d’entraîner le modèle GPT-2 à d’autres langues que l’anglais à partir du modèle anglais (l’idée derrière ce processus est qu’il vaut mieux partir de paramètres avec des valeurs non aléatoires et des paramètres qui ont déjà appris des caractéristiques linguistiques).
- OpenAI’s GPT-2: A Simple Guide to Build the World’s Most Advanced Text Generator in Python (juillet 2019, Shubham Singh)
Par ailleurs, la bibliothèque la plus utilisée pour implémenter le GPT-2 est aujourd’hui celle de Hugging Face: huggingface/transformers.
Tester en ligne GPT-2
Note: la plupart des exemples de ce paragraphe ainsi que la plupart des explications proviennent ou sont des traductions du post “Practical Applications of Open AI’s GPT-2 Deep Learning Model” de Mohit Saini (décembre 2019).
Génération de textes en anglais (la nature auto-régressive du modèle GPT-2)
- Talk to Transformer: ce site exécute le modèle GPT-2 avec 1.558 milliards de paramètres.
- AllenAI GPT-2 Explorer: cette démonstration utilise le modèle de langage public 345M OpenAI GPT-2 pour générer des phrases.
- Too powerful NLP model (GPT-2) (février 2019, Edward Ma)
Génération de textes en anglais personnalisés (fine-tuning do GPT-2 sur des corpus spécialisés)
- Neil Shepperd a créé un fork du modèle GPT-2 d’OpenAI qui contient du code supplémentaire pour permettre son fine-tuning sur des jeux de données personnalisés. Voici son notebook sur colab où vous pouvez affiner les variantes 117M et 345M de GPT-2 à l’aide de ce fork.
- GPT-2 Neural Network Poetry de Gwern Branwen
- GPT-2 Dungeons and Dragons character bios! de Janelle Shane
- Keaton Patti a partagé sur Twitter, comment il a spécialisé une IA (un modèle GPT-2) sur 1000 heures de films Batman. Il a également tweeté la première page du script du film généré par l’IA après l’entraînement.
- How To Make Custom AI-Generated Text With GPT-2 (septembre 2019, Max Woolf)
A lire:
- GPT-2 — Fine-Tuning Language Models from Human Preferences (septembre 2019 — janvier 2020: Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving — OpenAI) et le post sur OpenAI: Fine-Tuning GPT-2 from Human Preferences
Génération de textes dans une autre langue que l’anglais
Mikhail Grankin a adapté un script de la bibliothèque de transformers Hugging face afin de permettre d’entraîner le modèle GPT-2 à d’autres langues que l’anglais à partir du modèle anglais (l’idée derrière ce processus est qu’il vaut mieux partir de paramètres avec des valeurs non aléatoires et des paramètres qui ont déjà appris des caractéristiques linguistiques).
Chatbots
- Une autre excellente application de GPT-2 est l’IA conversationnelle. En effet, avec l’aide de modèles d’apprentissage et de langage de transfert comme GPT-2, nous pouvons créer de très bons chatbots en quelques jours. Thomas Wolf (de HuggingFace), dans son blog (mai 2019), a expliqué comment ils avaient fine-tune le modèle GPT-2 pour créer un chatbot en utilisant l’ensemble de données PERSONA-CHAT (cet ensemble de données contient essentiellement les conversations de personnes appariées au hasard). Demo: How to build a State-of-the-Art Conversational AI with Transfer Learning (Hugging face)
- Towards a Human-like Open-Domain Chatbot (janvier 2020: Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, Quoc V. Le — Google AI) et le post sur Google AI: Towards a Conversational Agent that Can Chat About…Anything
- How to Build a Twitter Text-Generating AI Bot With GPT-2 (janvier 2020, Max Woolf)
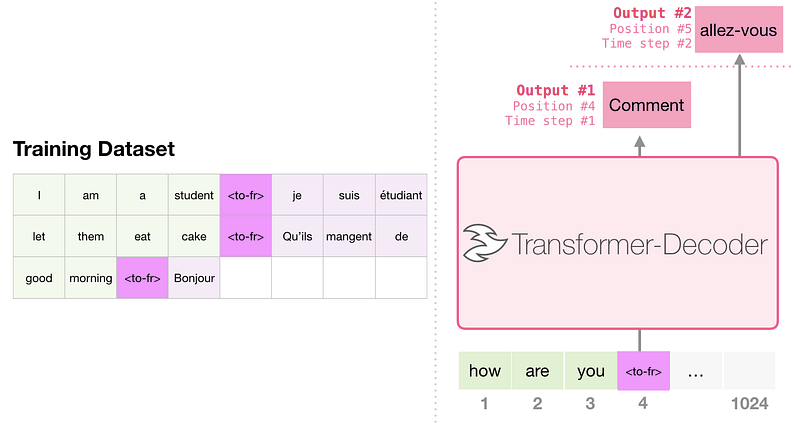
Traduction (machine translation)
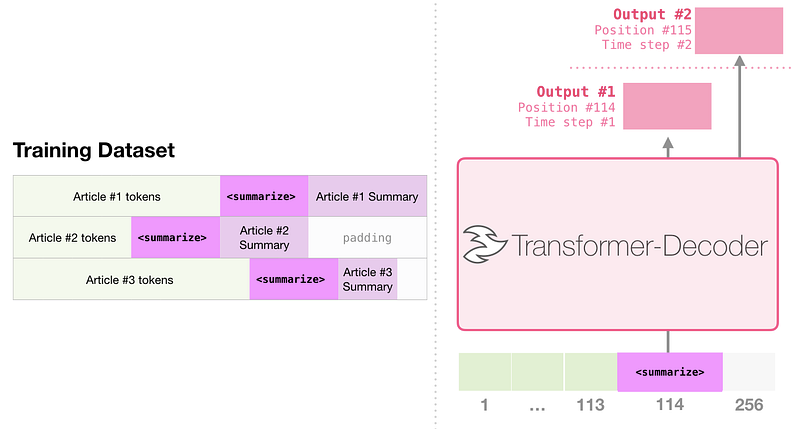
Résumé
Evaluation du GPT-2 en terme de compréhension
L’excellent article “GPT-2 and the Nature of Intelligence” (Janvier 2020: The Verge) de Gary Marcus (fondateur et PDG de Robust.AI) prouve que GPT-2 ne comprend pas ce qu’il écrit et qu’il n’a aucune notion ni de logique (il ne sait pas calculer par exemple) ni de sens commun (il ne sait pas qu’on ne peut pas ajouter des nombres à des choses ou à des personnes par exemple).
A lire:
- Deep Understanding: The Next Challenge for AI (Gary Marcus, Mohamed R. Amer, Dylan Bourgeois)
Questions éthiques
OpenAI a publié à présent tous ses modèles GPT-2 mais les questions sur l’impact de tels modèles restent encore non résolues (et surtout non anticipées juridiquement).
A lire:
- Some thoughts on zero-day threats in AI, and OpenAI’s GPT-2” (février 2019: Jeremy Howard (fastai))
Pour aller plus loin
- The Winograd Schema Challenge (2011). Extrait de Wikipedia: “The Winograd Schema Challenge (WSC) is a test of machine intelligence proposed by Hector Levesque, a computer scientist at the University of Toronto. Designed to be an improvement on the Turing test, it is a multiple-choice test that employs questions of a very specific structure: they are instances of what are called Winograd Schemas, named after Terry Winograd, of computer science at Stanford University. On the surface, Winograd Schema questions simply require the resolution of anaphora: the machine must identify the antecedent of an ambiguous pronoun in a statement. This makes it a task of natural language processing, but Levesque argues that for Winograd Schemas, the task requires the use of knowledge and commonsense reasoning.”
- TL;DR: Mining Reddit to Learn Automatic Summarization (septembre 2017: Michael Volske ¨ and Martin Potthast and Shahbaz Syed and Benno Stein)
- NLP’s ImageNet moment has arrived (juillet 2018, Sebastian Ruder)
- Natural Language Processing is Fun! (part 1/4) (juillet 2018, Adam Geitgey)
- OpenAI GPT-2: Understanding Language Generation through Visualization (mars 2019: Jesse Vig)
- Top 8 trends from ICLR 2019 (mai 2019: Chip Huyen)
- NLP Year in Review — 2019 (janvier 2020, Elvis)
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang — OpenAI) et le post sur OpenAI: GPT-2: 6-Month Follow-Up
- Hello, It’s GPT-2 — How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems (août 2019: Paweł Budzianowski, Ivan Vulić — Cambridge University, UK)
- MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism (août 2019: NVIDIA)
- GPT-2 — Fine-Tuning Language Models from Human Preferences (septembre 2019 — janvier 2020: Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving — OpenAI) et le post sur OpenAI: Fine-Tuning GPT-2 from Human Preferences
- GPT-2 — Release Strategies and the Social Impacts of Language Models (août — novembre 2019: Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, Jasmine Wang) et le post sur OpenAI: GPT-2: 1.5B Release
- DistilGPT2 à partir du processus “Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT” (août 2019: Hugging Face)
- One Language Model to Rule Them All (février 2019, Jesus Rodriguez). Extrait: “ Obviously, GPT-2 is not a magic model and still requires modifications for specific NLU tasks. Some tasks such as text classification can be achieved by simple tuning on some layers of the model while others such as question-answering require more complex modifications. In general, GPT-2 traversal-style approach, which converts structured inputs into an ordered sequence that the pre-trained model can process.”
- GPT-2 A nascent transfer learning method that could eliminate supervised learning some NLP tasks (mars 2019, Ajit Rajasekharan)
- (tableau comparatif) Generalized Language Models: BERT & OpenAI GPT-2 (avril 2019, Lilian Weng)
- Patent Claim Generation by Fine-Tuning OpenAI GPT-2 (juillet 2019, Jieh-Sheng Lee, Jieh Hsiang — Taiwan University)
À propos de l’auteur: Pierre Guillou est consultant en Intelligence Artificielle au Brésil et en France. Merci de le contacter via son profil Linkedin.



