
Job Execution Framework Environments
ACM.437 Initializing a 2nd Sight Lab job execution environment with the minimum resources required to run jobs
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Part of my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: Governance | Application Security | Batch Jobs
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post I initialized my AWS Organization by deploying it using a container in CloudShell.
Next I want to deploy my AWS environments. I’ve written about environments before. You can find some of those posts in my list of topics on Cloud Governance:
Essentially an “environment” for the purposes of this framework is a scope in which individuals can deploy resources from a particular set of repositories in a particular set of AWS accounts. I’ll reiterate the concept here and my latest iteration after recent changes to the job execution framework and why I’m making them.
What are environments?
For the purposes of my job execution environment the key points are that all the resources deployed in the environment come from the environment repositories. The accounts in the environment don’t have access to any other repositories or resources outside their specified environment.
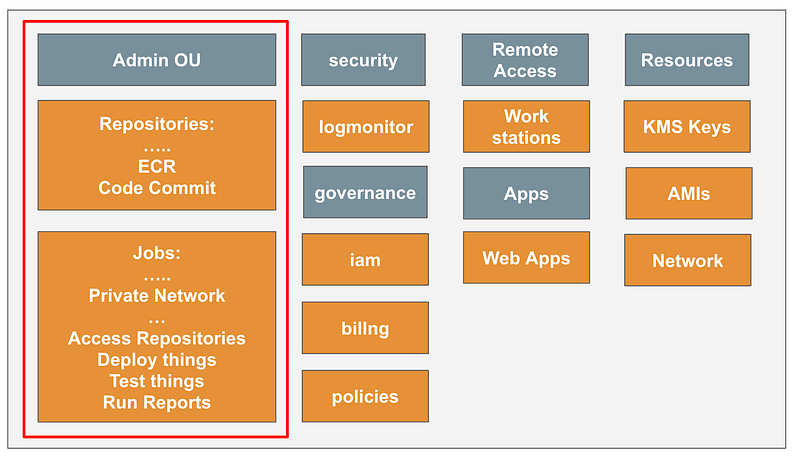
Recall that the top level job execution framework repository is here and you can read the README.md file to understand how it works.
Revisiting environment architecture — limiting the blast radius
Now the thing that’s making me think here is initially I had one governance OU that controlled everything for the entire organization, but that comes with some obvious risk. Access to that one environment provides access to the entire organization.
So here’s a thought. What if each environment had its own IAM account and related governance accounts?
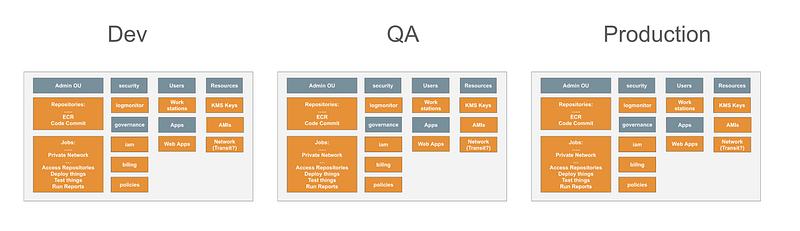
What are the implications?
You might have a developer IAM user account with credentials that you create in a non-production environment but never has access to production due to the inherent trust boundary created by containment in a separate AWS account. You can limit cross account access to accounts in the same environment (all prefixed with the same name like dev- or prod- or under a particular AWS OU).
On the flip side, you may have users like the security team that need access to all environments. They may need to log in three separate times. But if you minimize your environments it’s a lot easier to log into three IAM accounts and assume the associated roles in each environment than logging into thirty-six different accounts as shown in the above diagram.
Also, if they create jobs with my automated job framework they would basically need to enter three MFA tokens instead of one. The job could handle the role-switching as I’ve shown in prior posts to access different accounts in a single environment.
The other thing I was thinking about was that I was testing out Okta and the cool thing is that Okta gives you a production and non-production environment. So you could set up different environments to be associated with your Okta production and non-production environments if you are using that. If you have multiple non-production environments they may need to share the non-production instance but at least you can segregate prod and non-prod.
Resources that don’t allow separate instance for each environment
You might find that some things only allow you to deploy one resource across an organization. What can we do in that case?
Let’s say you want to create a delegated administrator for your organization. Can you specify more than one and have each delegated administrator create policies for different accounts? I don’t think so but I haven’t tried it. So perhaps there is only one policy account in the production environment.
So there may be certain things which you only have in the production environment, but as much as possible we can try to segregate the resources so there’s a separate management account for different policies, logging, backups, and so on in each environment.
All IAM users and secrets in one account per environment
The other thing that is bugging me is that I want to have all my users in an IAM account. If I deploy this org-admin account and put my org-admin user in it then that user is separate from all my other users in my IAM account. So really I need to create my IAM account first, add the org-admin to it, and then build out the rest.
I also have been rethinking my EC2 job role for the job framework. I really want that role to access the IAM account for all secrets and the jobs account for all parameters. That means I have to set up the IAM account before the ec2jobrole in the jobs account.
All roads lead back to the requirement to deploy the IAM account first.
Encrypting the secrets
There’s one other thing we need which pretty much precedes anything else. If we want to encrypt resources with a KMS key, we need the KMS key. So I’m going to go ahead and deploy that as well. After I initially wrote this post I realized I need to also install the KMS admin because I need to assign an administrator for the key and I want that to be the KMS admin in the KMS account.
Dev, Test, and Production Initial Resources
- dev OU
- dev-governance OU
- dev-iam account in dev-governance OU
- dev-iam-admin user, group, role, and user secret to deploy IAM resources
- dev-resources OU
- dev-kms account in the dev-resources OU
- dev-kms-admin user, group, role, and user secret to execute jobs.
- dev kms key and alias with dev-kms-admin as the administrator
- dev-iam account
- dev-org-admin user, group, role, and user secret to execute jobs.
- dev-apps OU
- dev-jobs account in the dev-apps OU for executing 2SL Job Execution Framework jobs
- dev-ec2jobrole with read only access to job secrets in the IAM account and job parameters in the job account
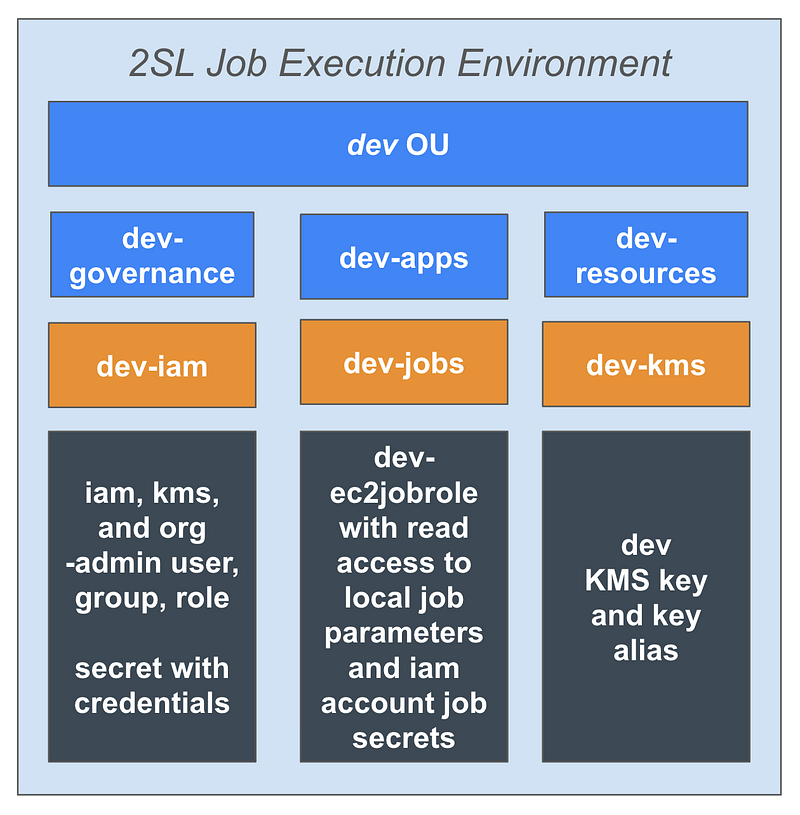
I can repeat the above for three environments: dev, test, and prod (or whatever environments you want to create).
Using 2SL Job Execution Framework (2sl-jobexecframework)
The reason I started to revamp my code to eliminate a bunch of repetitive code. I realized I need to revamp a few things in conjunction with that.
I’ve made the framework more flexible so it’s easier to add new jobs (containers) and job configurations (parameters).
Now you can deploy a new type of job by deploying a new repository with a new container image via a Dockerfile and execution.sh file (and whatever else the job needs). I demonstated use of those two components in the last post.
When I’m done you can configure a new resource deployment by adding an SSM parameter with a job configuration and executing the awsdeploy job.
I hit some complications due to the location of the credential secrets and parameters. Deploying the IAM account first allows me to put all my IAM resources in that account. Then the ec2jobrole can reference credential secrets for all users in one account.
Executing all the jobs in a job-execution account ensures that all the job configurations are in one place for a particular environment and that all jobs are running in a segregated, private network. If we have jobs that need network access we can also set up that network accordingly and separate from our private jobs.
As far as this initialization process, I am deploying the minimal resources needed so the org admin can execute jobs with the framework to deploy all other resources.
We can add EC2 instances at a later time to more fully automate and secure job executions but that will require additional resources. We have to start somewhere.
As a reminder I am not using Lambda because I couldn’t get it to work when I tried to assume a role using MFA. I haven’t gone back to see if that is fixed.
But besides that, it seems that we have more control over the network and compute configuration with an EC2 instance and we can segregate the role that retrieves the credentials and job configuration from the role that obtains the resource the job needs to complete the job task.
Now that I’ve thought that through a bit more, hopefully I can cruise through deploying it. Dare to dream!
Next post:
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2024
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab