
Using SSM Parameters to Define Jobs A User Can Run in an AWS Account
ACM.431 A naming convention to provide a list of jobs a user can execute to deploy resources in an AWS account
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Part of my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: AWS Security | Application Security | Abstraction
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post I was thinking through the architecture for parameter management.
I want to set up a way to use AWS SSM Parameters for deployments and am going to test out some options.
The idea is that I want to separate the data plane (the description of what to deploy) from the control plane (the application that deploys the resource).
You already get this with CloudFormation to some degree. You specify what to deploy and your CloudFormation template deploys it. You have no control over the deployment engine.
However, there’s a lot of complexity and possible misconfigurations in CloudFormation templates. I always tell clients to avoid security misconfigurations, come up with some approved templates people in an organization can use to quickly deploy new things in a compliant manner without an arduous approval process.
If they want to create something different they can, it just has to go through proper review and testing, whereas they can quickly spin up resources already configured in an approved manner.
So that’s what I’m doing here. I have a container that deploys some core resources in an approved manner based on a configuration a user provides.
The person providing the configuration may not be well versed in all the details of security and that is handled for them. But if they wanted to deploy something different they could propose a new configuration to add to the deployment engine.
We’ll see how this works out. I’ll probably make revisions along the way as always. This is my first cut.
A review of some existing job scripts
Let’s look at the existing scripts the root-admin role can run to see how we might further abstract and simplify this code, while meeting the requirements of the last post.

Open up the script: iam_user_orgadmin.sh (I changed the user name of root-orgadmin to org-admin and I want to deploy that.)
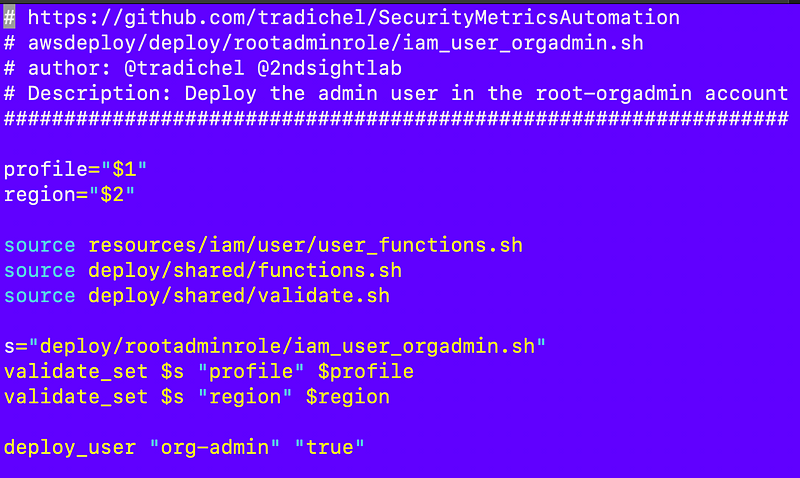
I have a lot of repetitive code in these scripts. The profile, the region, the includes which are always the same except the include to for the specific type I want to deploy. I validate the profile and region over and over. Then I call the deploy script with the particular values I want to pass to it. I revalidate all the values in the deploy script which seems a bit redundant, no?
How might I simplify that?
Well I can think of some obvious things but before I go into that let’s look at a more complicated script like the one I used to deploy a new project account. I can spot some similarities, but also some things that make it a bit complex to turn this into a single parameter to run all job types.
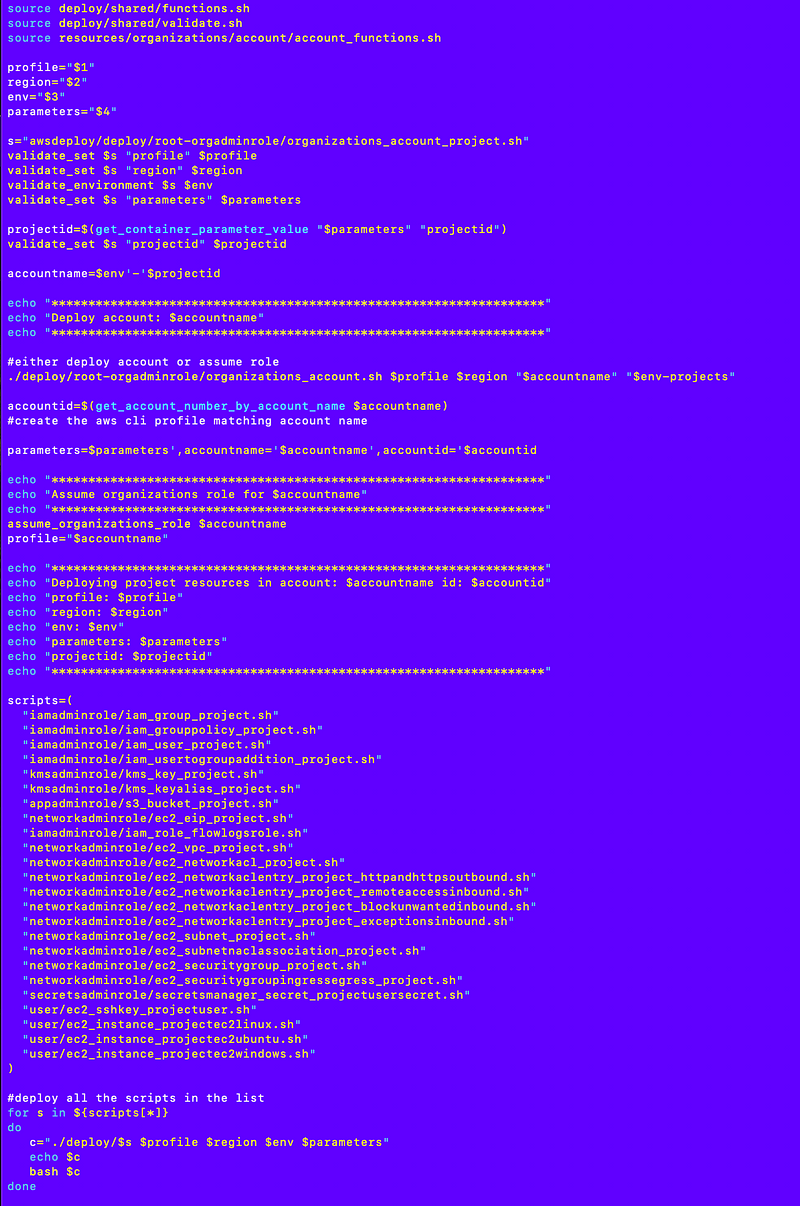
In the above script, first I deploy the account, then I assume the role to deploy resources in that account. How will I deal with assuming different roles?
Here’s an even more complicated scenario where I’m switching between the project account and the domains account to deploy a domain name to use with CloudFront which involves multiple configuration steps in different accounts. I’m sourcing a bunch of different files to call the various functions to deploy different resources. You can see I commented out the code at one point below where I want to pull in the domains to deploy from AWS SSM Parameter store where I initially hard coded them for a test.
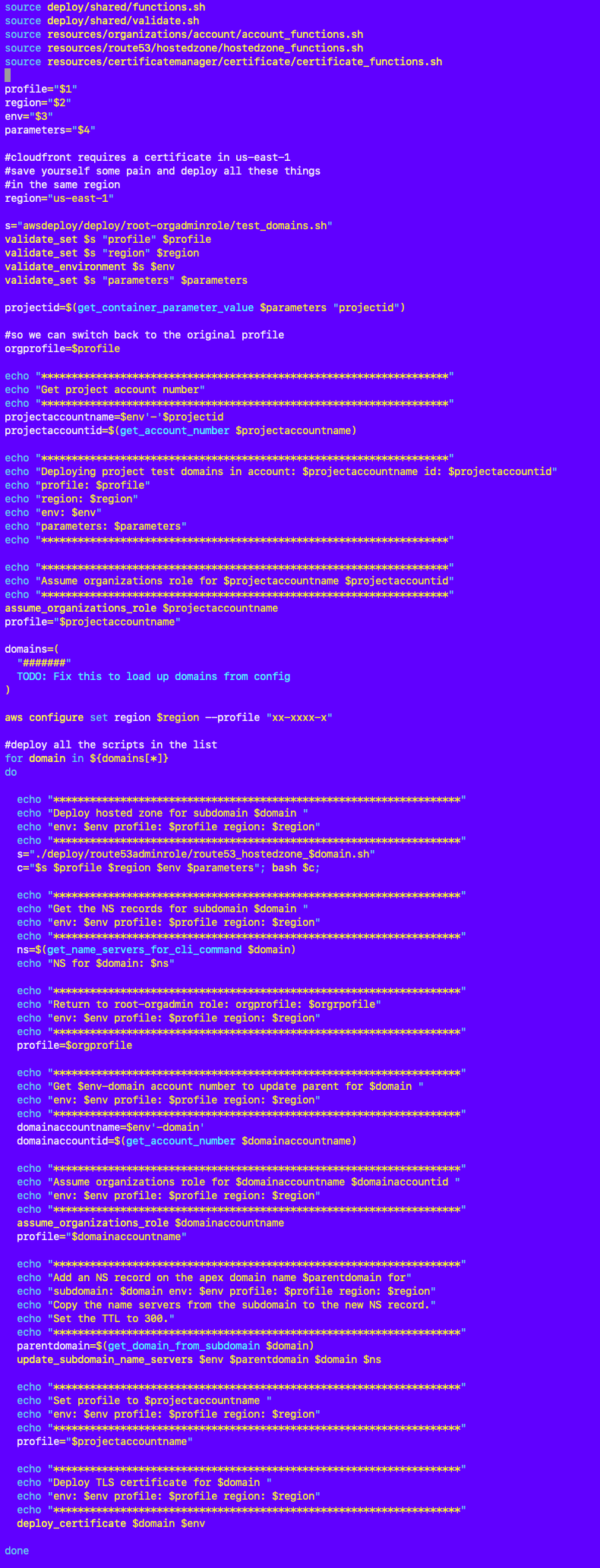
Well the full solution requires some thinking. But I can find some commonalities above to start simplifying my deployments one step at a time.
Introducing SSM Parameters to the architecture
The first thing I want to do is deploy SSM Parameters and use those parameters to store the job configuration. That buys me a few things.
- Instead of passing these parameters through multiple files, the job that needs the values can reach out to parameter store to get them.
- That leads to some obvious code reduction and less potential typos, and overall, less code to maintain.
- We can use those parameters to list the jobs you can run in a particular account which allows me to get rid of the file I’m currently manually editing to add new jobs.
- We can separate the control plane (what executes the job) from the data plane (the job configuration) as mentioned.
- You could potentially segregate duties as follows: People who can deploy new job configurations, people who can edit job configurations, people who can edit the container that runs jobs, people that test the jobs, and people that operate the jobs in production but cannot change the code or inputs to the code, and people who monitor the job logs for security problems.
- As already explained, different jobs can belong to different roles so you can allow one role to deploy KMS keys, for example, and a separate role to deploy networking. But other jobs can use the KMS keys and the networking that has been deployed.
So with those changes we can revamp our architecture diagram (sorry it’s not real pretty) like so:
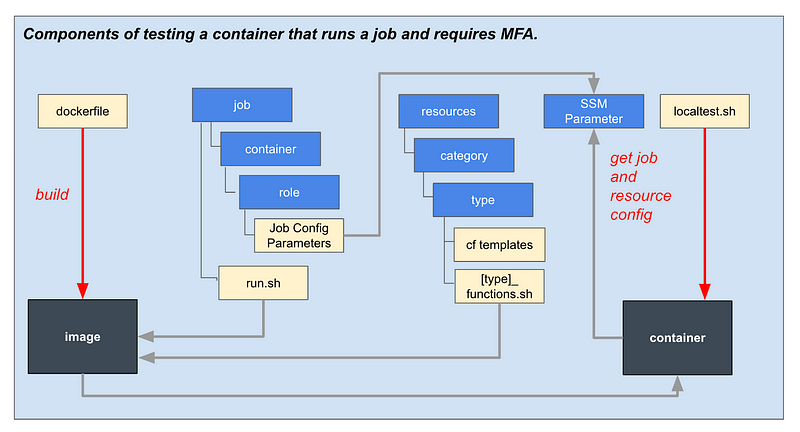
I’m also going to add a script to deploy parameters as shown below.
First question — where does the parameter get deployed?
I went around in circles on this one but the parameter will be deployed in the account where the secret exists with the user credentials and the account where the EC2 instance will be executed (eventually) to run the job.
The job execution will typically occur in an account other than the one where the resources get deployed.
Note that this changed from my original design after testing and realizing complexities with other approaches. It also makes sense due to the natural separation of duties for roles.
Getting a list of jobs that can be executed in an account
Recall that I previously named my parameter like this which matches the name of the script inside the container to run, less the file extension:
/deploy/root-orgadminrole/organizations_resourcepolicy_resourcepolicyI want to know which parameters are jobs that can be executed so I’m going to add /job at the start of my parameter names like this:
/job/deploy/root-orgadminrole/organizations_resourcepolicy_resourcepolicyThat way I can find all the “jobs” that can be run in that account because the parameter name starts with “/job”.
Specifying the container that runs the job
What if I change deploy to awsdeploy? Now the job function to run matches the name of the container that runs the job. That leads to some flexibility in the future if I want to use other containers to run different jobs.
This also allows an EC2 instance to pull down the correct container to run a particular job using this configuration name. I demonstrated how an EC2 instance pulls a container and combines that with an MFA token to run a job in prior posts.
/job/awsdeploy/org-adminrole/organizations_resourcepolicy_resourcepolicyOf course we need to think through who has access to use what containers so we don’t end up running the wrong code in our account. We can restrict policies to only adding parameters that start with /job/awsdeploy
If we start using other containers we can adjust policies accordingly to specify who has permission to run jobs using which containers.
That’s cool. Ok now we’re getting somewhere I think.
I’m writing this all on the fly as always, so subject to change.
Generating a list of jobs a role can run
We have role names in our deploy folder with the jobs an admin can run in each folder. We can derive a list of jobs an admin can run by listing out all the parameters that start with job/awsdeploy/[adminrole].
/job/awsdeploy/org-adminrole/organizations_resourcepolicy_resourcepolicyI can use that mechanism to list jobs an admin can run and eliminate my “userjobs” folder and manually updated scripts every time I add a new job script. The jobs a user can run are based on parameters names now.
The org-admin can pretty much run any job except those owned by the root user in the management account, so I can query all those jobs for the org-admin.
But let’s say I have a KMS key job like this:
/job/awsdeploy/kms-adminrole/kms_key_nonprodkeyWell the org-admin can see all the jobs but the KMS admin can only see the jobs that start with /job/awsdeploy/kms-adminrole, and those are the only deployment jobs they are allowed to run in the account.
We can also place a restriction in the KMS admin IAM Role policy that only allows that role to view, create, and edit parameters that start with /job/awsdeploy/kms-admin.
Deploying SSM Parameters for jobs
Aligned with the new naming convention, I’m going to add my job configuration parameters to my /job folder instead of the /deploy folder where my scripts currently exist.
Then I will add a parameter file for each job that role can run matching the final name I want for my parameter.
What that means is that my parameters will get copied into the container and can be used as the default parameter to deploy the job if the parameter doesn’t already exist.
However, if it does exist, the job will use the existing parameter in AWS, meaning that parameter can override the default configuration.
Let’s start with something simple. I want to rename my root-orgadmin user to org-admin and my root-orgadminrole to org-adminrole.
This user needs to be deployed in the org-admin account.
The job gets executed by the root-adminrole.
I created these files files matching the parameter name I want in AWS SSM Parameter Store:
/job/awsdeploy/root-adminrole/iam-user-org-admin
/job/awsdeploy/root-adminrole/iam-role-org-adminroleRecall the last filename matches this CloudFormation resource format:
[resource category]_[resource type]_[name]I add this to the source file for that resource:
category=iam
type=user
env=org
account=org-root
region=us-east-2
name=org-admin
console=trueOK but what if we had a resource that we needed to deploy to two regions?
category=iam
type=user
env=org
regions=us-east-2,us-east-1
name=org-admin
console=trueThinking ahead, what if we needed to deploy to two environments?
category=iam
type=user
env=org, prod
region=us-east-2
name=org-admin
console=trueWhat about a resource that needs to be deployed to specific accounts?
category=iam
type=user
env=org, prod
account=account1,account2,account3
region=us-east-2
name=org-admin
console=trueI’ll get into more details about the structure of my parameter list later but for now let’s try to deploy that parameter to AWS SSM Parameter Store.
Deploying the parameter
I’m going to add a script to the root of my awsdeploy folder (not inside the jobs folder).
configjob.shI explained that I already have functions to deploy parameters so I start by sourcing those files.
So first I source the file that has those functions and my standard functions.

I need to set the profile variable that defines which available AWS CLI role will deploy the parameter containing the job configuration. I can use code similar to my localtest.sh file to let the user enter the profile, enter L to list the profiles, or return to use the default profile.
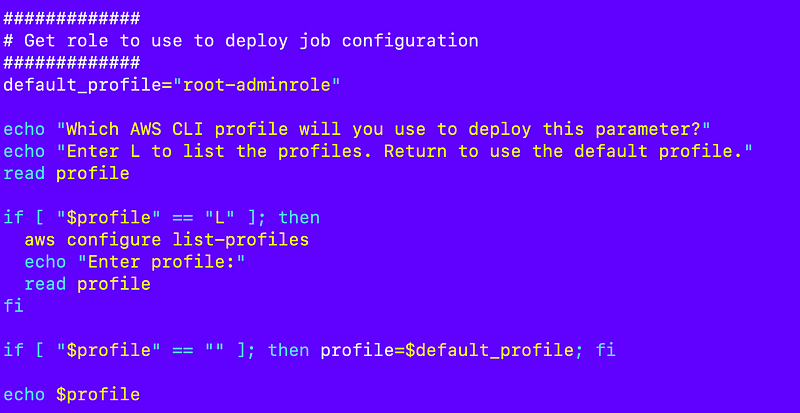
Next I can get the container that runs, the role, and the job name based on the files in the job directory.
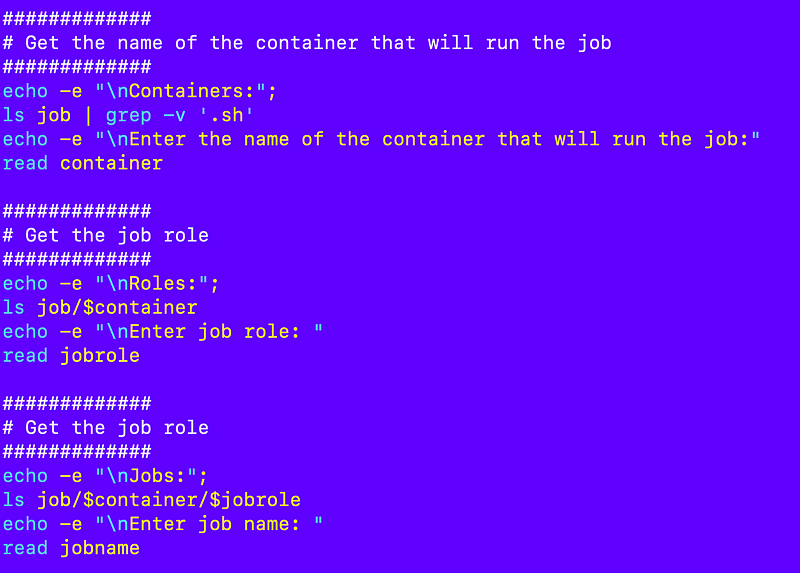
I concatenate those values to get the parameter name.

The parameter value is what’s in the file. I can check all my variables at this point like this:

Run that file to make sure what we have so far works:
./configjob.sh
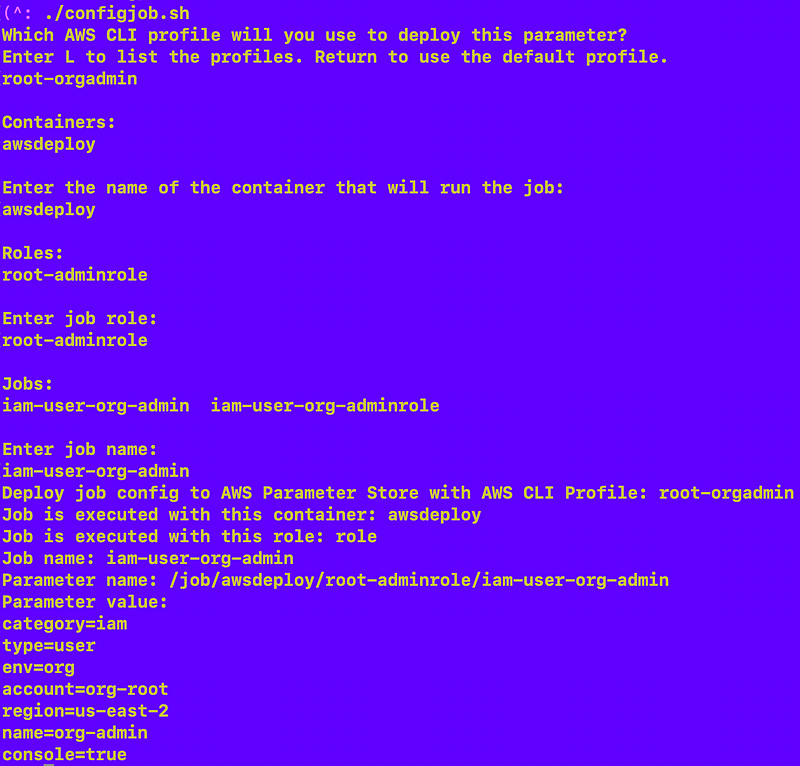
I can get fancier later and add numbers and have the user select a number instead of copying and pasting the job if I wanted but this works for now.
Ok let’s deploy the selected parameter with the selected value.
First I need to get the account and region where the parameter will be deployed. I’ll read those out of the parameter. This is a simple use case with one region and account. I’ll deal with the multi-account and multi-region deployments later. For now I get those values like this and verify they are set correctly:

That works:
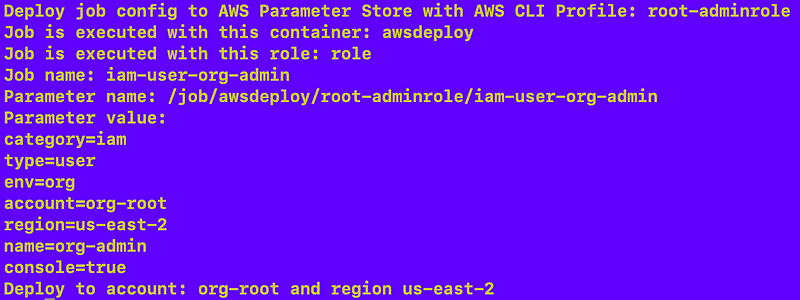
Now I need to assume the AWS Organizations role for that account and deploy the parameter. For now I’m using the role that deploys the initial user in a new account. That user can assume the AWS Organizations role in that account with no restrictions on what it can do, so it should be able to deploy the parameter. As the organization gets built out we can use roles with more limited permissions.
I already have a function to assume the organizations role based on the account name.
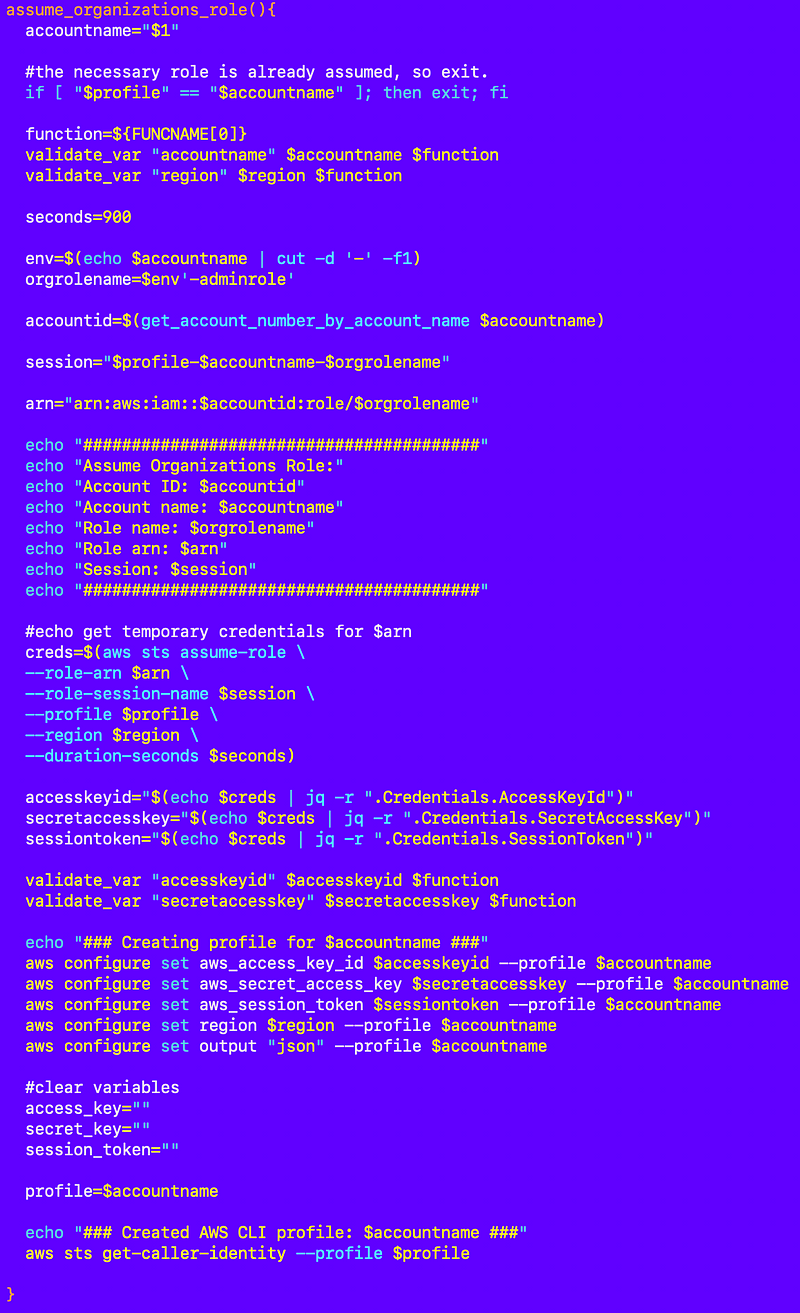
I will need to source the related file so I can call the function.

Test that the role assumption works:
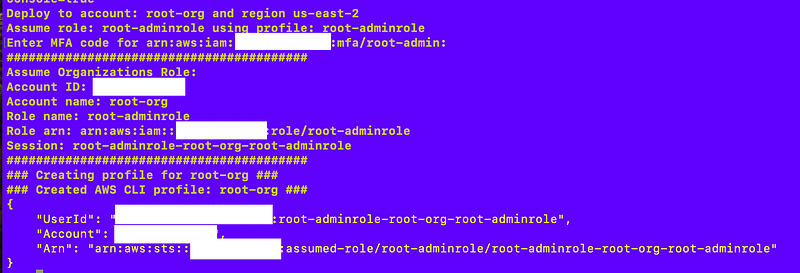
Note: It is at this point I decide I need to add a function to validate the role configuration in the ~/.aws/config file since the error messages provided by AWS IAM are severely lacking. But later.
If you have issues, always test your role profile outside of the functions with a single command and make sure your configuration works externally to all this code.
Anyway now that works so I should be able to deploy the parameter. I’m going to set the name and value, with no KMS key ID for now, with the default tier:

But I ran into an issue I think because the file contents have spaces so essentially I created a new function. Due to our consistent naming convention, I can get the contents of the file using the name of the parameter using the file:// function shown below.
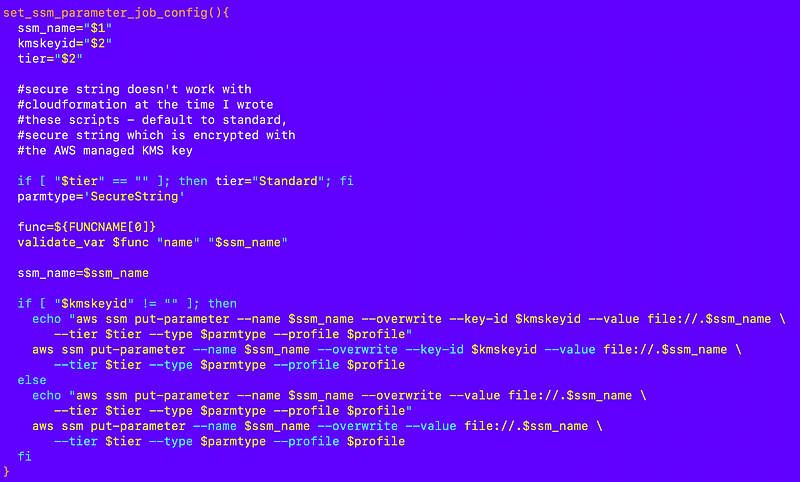
Now mind you, this has security problems. I haven’t yet changed my container to not use the root user so when this is executing someone could pass in any file name and put the contents in SSM parameter store. So we’ll need to add some additional restrictions to our container and our code. If you want further explanations follow along, schedule a call with me through IANS Research, or schedule a penetration test. For now I’m moving on because I spent too much time on this post already.
Don’t use this container in production environments.
I plan to do some pentesting on this myself later.
That appears to have worked:

Check to see the parameter exists in the account:
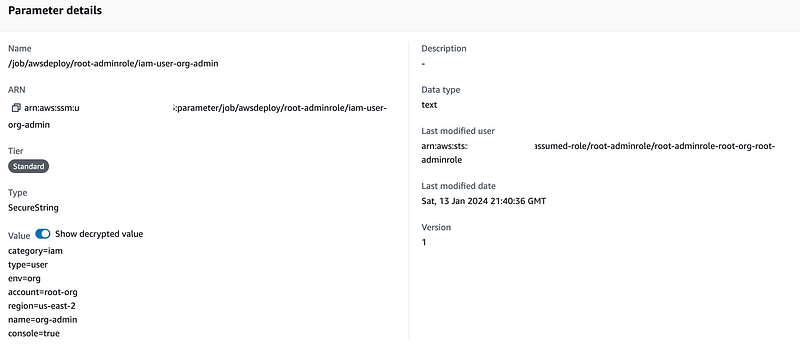
It does.
Now we have a process for deploying a new job configuration as a parameter.
Really I likely will want to remove a few things in that parameter but we have a start.
I deploy my second job configuration parameter using the same script.
Listing all the available jobs in an account
What if we want to list all the available jobs that we can run in an account?
Well now that’s pretty easy:

That command lists the configured jobs:

So now when I want to run deployment jobs, I can base the job list off those parameters, or my local job configuration files. Either way I can ditch that unwieldy userjobs script I’ve been using to list out all the available jobs.
But I’m not done. I have more code to eradicate with these new job configuration files.
Next up:
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2024
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab





