Identify Causality by Difference in Differences

Why Do We Need DiD?
You may be asked to show the causal relationship between two measures. Your first attempt may be to set up randomized controlled trials: a treatment group, a controlled group, and a test. But wait! There are many reasons that randomized Controlled Trials (RCT) are not feasible. For example, it is impossible to set up a treatment-and-control experiment for a historical event. What can we do?
The Difference-in-Differences will be a good choice. Instead of trying to design an impossible randomized controlled experiment, we need to change our approach. The past historical events can be viewed as rich collections of natural experiments, in which nature does the randomization for us. We can try to find the “natural experiment” to identify the impact of a policy. For example. An unexpected policy change could be seen as a “natural experiment”. In natural experiments, we need to identify which is group affected by the policy change (“treatment”) and which group is not affected (“control”). An appropriate setting for the control group will determine the quality of the evaluation.
The DiD design is a kind of quasi-experimental design. The word quasi means seemingly, apparently but not really. A quasi-experiment design is similar to a randomized controlled trial but without the random assignments by the researcher (Cook & Campbell, 1979). In the “identify causality” series of articles, I present econometric techniques that identify causality. These articles cover the following techniques:
- Machine Learning or Econometrics? (see “Machine Learning or Economics?”
- Regression Discontinuity (see “Identify Causality by Regression Discontinuity”),
- Difference in differences (DiD)(see “Identify Causality by Difference in Differences”),
- Fixed-Effects Models (See “Identify Causality by Fixed-Effects Models”),
- Randomized Controlled Trial with Factorial Design (see “Design of Experiments for Your Change Management”).
In each article, I present the applications in various fields so you see the formation of their problems. I then offer best practices, the sample code, and how to conclude.
What Is the Difference in Differences (DiD)?
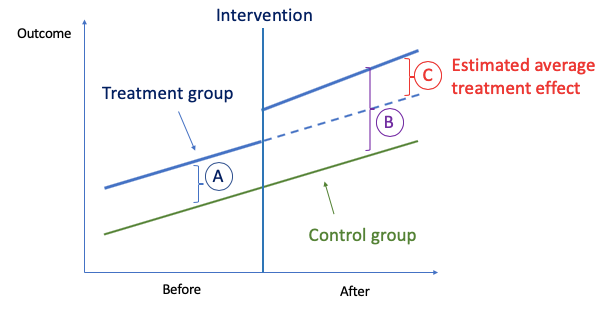
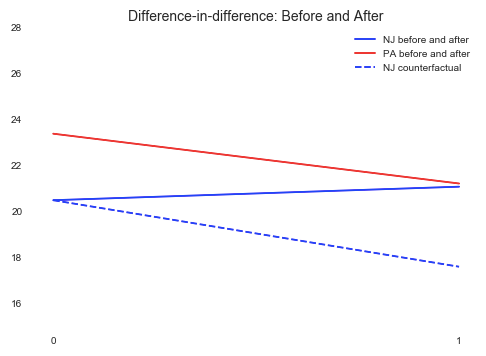
The idea behind DiD is simple. First, we compute the difference in the mean of the outcome between the two groups in the “Before” period, which is (A) in the above graph. Second, we compute the same for the “After” period, which is (B). Then we take the “second difference”, which is the difference between (A) and (B) and is labeled as (C). This second difference measures how the change in outcome differs between the two groups. The difference is attributed to the causal effect of the intervention.
The choice of the control group is critical in DiD. It behaves as the counterfactual or “what if” scenario. However, it is not so easy to find the control group and a researcher has to construct the counterfactual. Abadie et al. (2001; 2010) have proposed a method called the Synthetic Control method to guide researchers to construct the counterfactual. For the interest of readers, I have described briefly at the end of this article.
DiD Assumptions DID has implicitly required the following assumptions. When you design the treatment and control groups, consider if they meet these assumptions:
- Parallel trends: the treatment and control groups have parallel trends in the outcome. This means in the absence of the intervention, the difference between the treatment and control groups is constant over time. The best way is to plot and visually inspect if the parallel trends hold.
- No spillover effects.
- The characteristics of the treatment and control groups are stable over the study period.
Difference-in-Differences Applications in Public Health
In 2011, the Accreditation Council for Graduate Medical Education (ACGME) restricted resident duty hour requirements, which was established back in 2003. This raises concerns about the impacts on patient care and resident training. How to conduct the test to prove there is an impact or no impact? Rajaram et al. (2014, JAMA) applied the DiD method and concluded the policy change does not impact a variety of measures including death or serious morbidity, postoperative complications, and resident examination performance in the post-reform period. For more applications in public health, here is a good resource.
Difference-in-Differences Applications in Economic Policy
Will a higher minimum wage reduce employment? This question has practical policy implications. The conventional economic theory predicts a rise in the minimum wage leads employers to cut employment (George J. Stigler, 1946), but early empirical economic studies showed contradicting results (Richard A. Lester, 1960, 1964) or no impact (Krueger, 1992; Card, 1992; Stephen Machin and Alan Manning, 1994). The test for this question is hard. We can not go back to doing a randomized controlled trial.
DiD provides an unbiased solution. Card and Krueger (1993) in their well-known study conclude the rise in the minimum wage shows no indication of reducing employment. Let’s see how they applied DiD in their study.
- They analyzed 410 fast-food restaurants in New Jersey and Pennsylvania following the increase in New Jersey’s minimum wage from $4.25 to $5.05 per hour.
- They compared full-time equivalent employment in New Jersey and Pennsylvania before and after the rise of the minimum wage.
- In this “natural experiment” the restaurants in New Jersey become the “treatment” group and those in Pennsylvania the controlled group.
- Check the parallel trend assumption: the unemployment rates of New Jersey and Pennsylvania show parallel trends over time.
- They applied the standard two-groups and two-time-periods DiD.
The Standard DiD — Two Groups & Two Time Periods
The dataset and analysis are credited to Constantin Colonescu’s “Principles of Econometrics with R”. I demonstrate the analysis in Python.
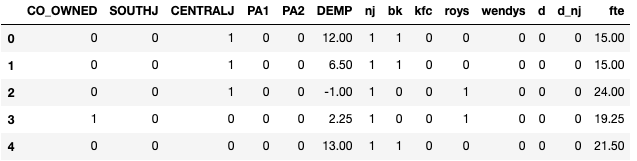

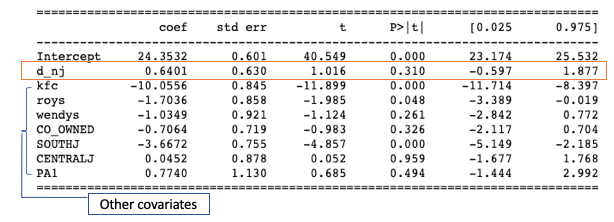
The result shows that “d_nj” is not statistically significant, meaning the minimum wage law has no impact on employment. In a DiD you can control for other covariates that may differ between the groups.
The above presents the FTE of NJ, PA, and the counterfactual as 20.4, 21.0, 23.3, 21.1, 20.4, and 17.5. We can plot the DiD like the following:
Synthetic Methods to Construct the Control (Counterfactual) Group
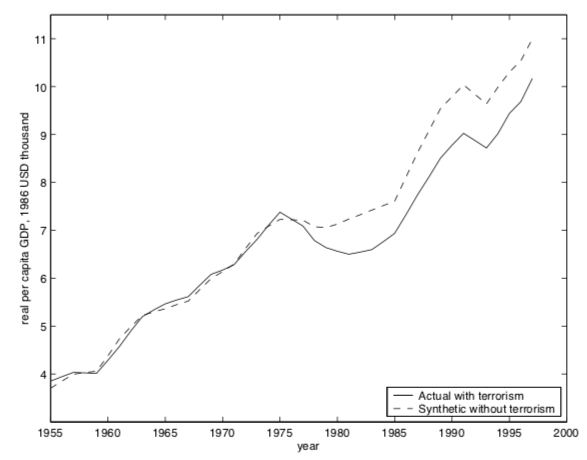
We probably all agree political turmoils devastate economic prosperity. But how to assess the economic impact? The Basque Country was one of the richest regions in Spain in the early 1970s but dropped to sixth in terms of GDP in the 1990s. To use DiD to assess the impact, we may take the Basque economy as the treatment group and the economy of the rest of Spain as the control group. However, the economy of Spain suffered an economic downturn in the 1970s and 1980s, at the peak of terrorist activity. Taking the rest of Spain as the control group is not the right control group.
What can we do? Abadie and Gardeazabal (2001) construct a combination of other Spanish regions as the “synthetic” control group. The regions of this control group resemble most of the economic characteristics of the Basque Country before the outset of the Basque political terrorism in the 1970s. The subsequent economic evolution of this “counterfactual” Basque Country without terrorism is compared to the experience of the Basque Country. They can conclude that, after the outbreak of terrorism, per capita GDP in the Basque Country declined about 10 percentage points relative to the synthetic control region. See the graph below.