
How Much Code Have You Eliminated Today?
ACM.441 Code generation and reduction — better without AI
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Part of my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: AWS Security | Application Security | Batch Jobs
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ In the last two posts I showed how to deploy a resource based off a configuration in an SSM parameter:
Next I showed how to deploy a stack of parameters based off a stack configuration:
Related to those changes I can get rid of a whole bunch of code both in my repositories and in my code generator:
The typical problem with AI-generated code
You may not want to use AI to generate code if you are trying to architect a well-designed system with the least and most efficient code possible that does what you need it to do.
Generative AI (or any code generation system such as the one I wrote and just altered to produce less code) has the potential to pollute your code base with unnecessary code and problems in my experience with a plethora of those types of systems if not used sparingly and in the right places.
You say “I want code to do this” and sure it spits out a bunch of “working” code. But is it good code? Is the code maintainable when you need to change it? Does the code support separation of duties when you want to allow different people to maintain different parts of the system?
Also as pointed out in prior posts, AI generated content needs review. It often misses nuances, fails to provide all the information, or is completely wrong. I provided examples.
I would think AI would have more potential in reviewing and recommending changes to improve code than writing code, but I’m not sure. Time will tell. And, for beginners, it is certainly helpful. But I would put them in a container as I’ve demonstrated in recent posts and architected systems to do just that when I worked a a security vendor.
Limiting the blast radius when your code has problems
I was just reading about how manufacturing weapons in Ukraine distributes different parts of the process so that blowing up one location doesn’t bring all production to a halt or cause insurmountable delays.
You can architect your systems the same way. But if you spit out code with AI generators does it do that for you? Or do you end up with a mountain of brittle code that falls over when the wind blows? Does an AI generator understand architectural complexities, or is it just generating “code that runs.”
It depends on how you use it. If you have an architecture such as the one I am building that allows developers freedom within bounds, then you could potentially use AI to generate code quickly and safely in individual containers. Then you could improve that code over time with human testing and review.
The other thing you need to solve problems quickly is good error handling that explains exactly what the problem is. Are AI code generators doing that? Do they provide error messages that quickly tell a human how to fix the problem?
For simple problems, maybe yes. For more complex and nuanced problems, my experience with systems designed to give me answers have not been that helpful as of yet. I’m sure they will improve.
As for me I don’t want a mountain of code here that I have to explain or sort through later.
I’m trying to reduce the code to what is necessary.
Simple as possible but not too simple as often credited to Einstein. Or as I’ve mentioned in the words of Mark Twain, “If had had more time I would have written a shorter letter [software program].”
Code I eliminated in latest revisions
The SSM parameters essentially replace all the scripts I was creating for each job. I can get rid of the entire directory of resource and stack specific scripts in my earlier iteration in favor of SSM parameters.
That means I can get rid of this file in my gen_code functionality:
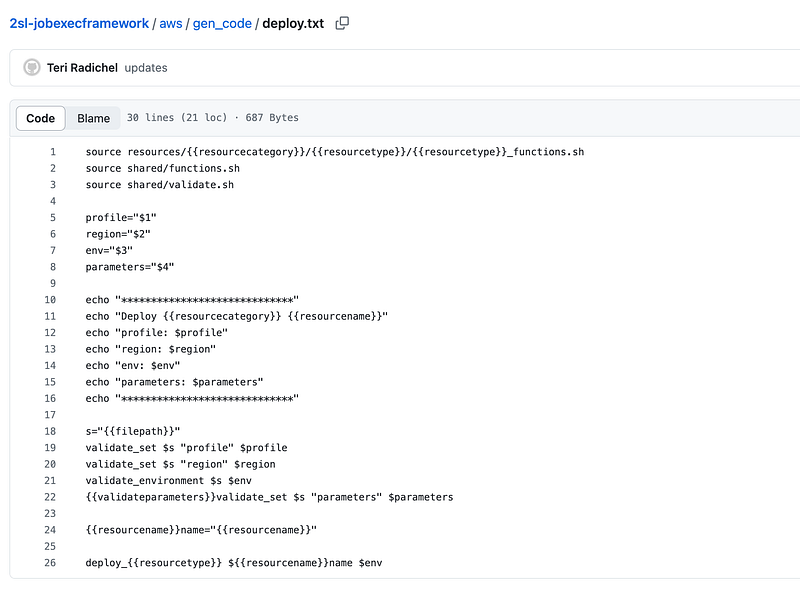
Deleted that.
This whole directory goes away:
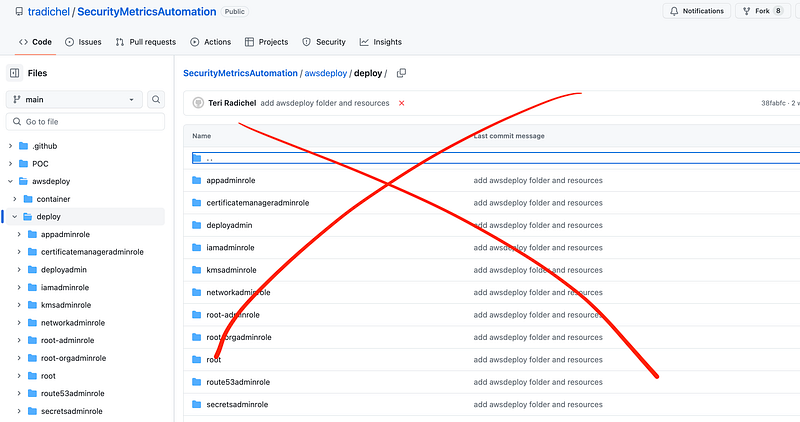
I did replace it with the parameter configuration files but that content is data not executable code. It describes what you want to deploy. The structure follows a specific format so those should have appropriate type checking and be less problematic. You can’t typically inject executable code into data if the values, when retrieved and processed, has appropriate type validation and encoding in place.
Next, I don’t need the resource specific deploy() function In my functions file as I have a generic parsing function now that can deploy pretty much any resource. Of course there may be exceptions but so far I do not have one that I haven’t been able to add to the generic parser.
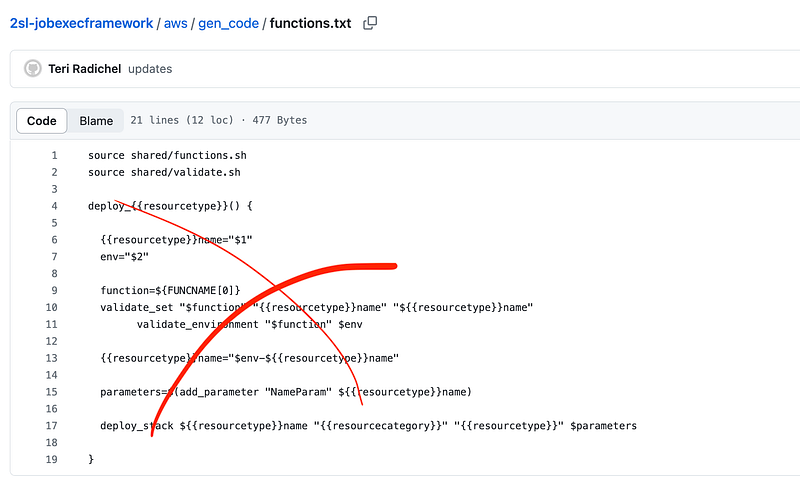
The generic parse_config.sh file that can read an SSM parameter and use the configuration in the value to deploy any resource as explained in the last two posts.
However, I will need a get_id() function for every resource. It will be resource specific so I’ll need to write different code for each resource. Now, if AWS had created a single get-id function in the AWS CLI and created IDs consistently for every resource (An ARN across the board) then we could write one generic ID getter for every type of resource. Maybe someday AWS will do that and we could get rid of this too. 😁 #awswishlist
For now I replace my template to generate a functions file with the following:
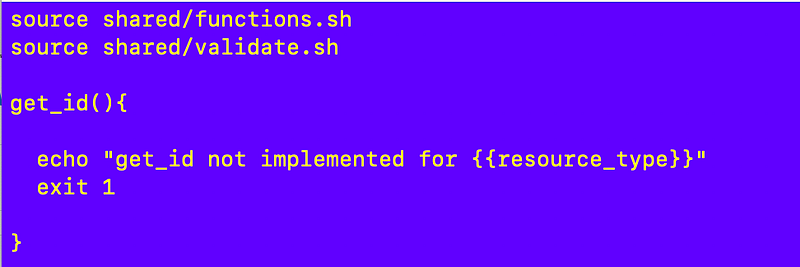
I can basically delete the deploy() function in all my [resource]_functions.sh files and add the get_id() function.
I still need the template and that will at the moment need to be written for each resource type, but I will fix the parameter name in the shell that gets written initially.
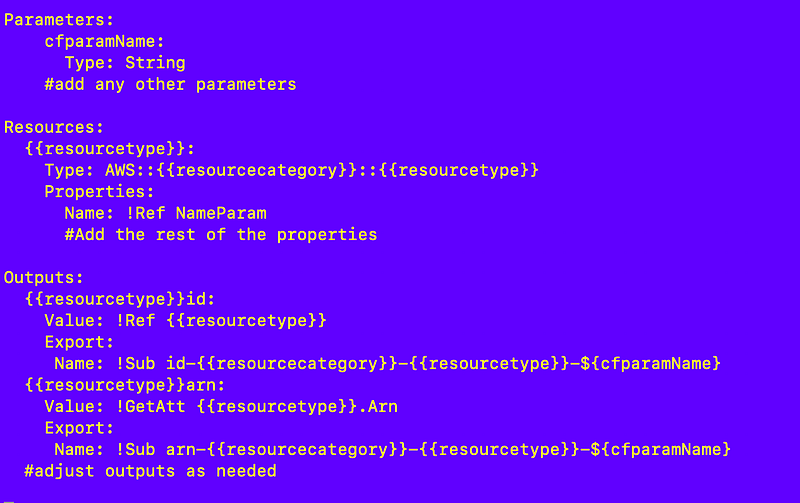
Yay. I just eliminated a bunch of time-wasting, bug-inducing code so I have less to deploy for each new resource type for which I want to add a template. If I had discovered a problem in the removed code repeated across every resource I would have changed it in many places. Now it is gone and I have a single source to maintain.
I made it easy for organizations to allow people to deploy approved templates with SSM parameters without having to give them access to alter any of the deployment code.
Once you have the framework and a Service Control Policy is in place, people deploying resources won’t see their credentials and will have to put in an MFA to deploy resources, eliminating a whole bunch of different potential security compromises explained in my IAM posts.
You could restrict non-technical or less-technical users to only deploying parameters, while still giving more technical users more leeway to change other parts of the code — other than the deployment engine. Separate what you are deploying from the engine that deploys it. And reduce a lot of repetitive code and potential bugs by using a single deployment engine.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2024
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab