
Thoughtful Error Handling
Your error handler is one of your most important security defenses
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Check out my series on Automating Cybersecurity Metrics | Code.
🔒 Related Stories: Secure Code | Application Security | Cybersecurity
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Do you write error handlers that capture errors when your application executes? All the errors? Do your applications crash miserably with the wrong inputs or fail gracefully? Can your application continue when it needs, even when an error occurs? When a crash occurs do you capture the output and deal with it appropriately or let it spill onto the screen for anyone to read? Does your error handling or logging code have a security vulnerability?
Error handling that gives up secrets
While performing a particular AWS penetration test for a customer I was tasked with testing their APIs. All I had was a Swagger file (a file that defines all the ways you can call the API and the related parameters.) I wrote a custom fuzzer that parsed the Swagger file and inserted attack values into the API calls. Fuzzing is a mechanism for testing code with a lot of attack strings quickly and I wrote more about this fuzzer for IANS Research. I don’t recommend only testing an API because that can provide limited results, but in this case, that’s all I had.
While testing the API I noticed that one of the error messages reflected the data I entered back to the screen. Sure enough, I had a cross-site scripting (XSS) attack. Even worse, I could use that cross-site scripting attack to send me the JSON web token of the user that made the crafted API call. If I could trick a user into going to a page that produced that error I could use obtain their credentials and make additional API calls using them.
If you want to see this in action, I did a demo in my talk at RSA in 2020:
Lack of error handling spills your secrets
Sometimes while performing a penetration test I can obtain helpful information from code that lacks error handling. Improper error handling has provided me with internal server IP addresses, database names, and stack traces that provide information about the libraries and code that produced the error.
A stack trace after an error shows the path the code took that led to the error. It will show that one library called a particular function and then that called a particular function and so on until you get to the function that did not handle the error. Sometimes a stack trace only shows the most recent function. Sometimes it shows all the calls back to the initial one that started the chain.
When you write some code and fail to write error handling your particular programming language or application framework may produce default error output. Sometimes that output is extremely verbose. Some web frameworks produce a custom error page that provides a user-friendly display a lot of data related to an error including IP addresses, code paths, and other useful information. The information helps developers troubleshoot the problem. That same information is useful for attackers who are attempting to reverse-engineer how your system works and break into it or steal data.
I will take a look at the stack trace or error output produced by the code and attempt to find out if the application is using any vulnerable libraries. I can learn more about the system architecture such as versions and potentially file paths to where code exists on a system. If there’s an internal IP address I may try to reach it through an open redirect, SSRF, or DNS rebinding attack. Explaining all those types of attacks is covered in other books I already mentioned and other videos, presentations, and blogs I’ve written. What I’m going to focus on now is writing error handlers that do not expose information to attackers.
Error handling libraries with vulnerabilities
One time while testing a site I was looking for cross-site scripting (XSS) vulnerabilities using that same fuzzing mechanism I mentioned before. While testing the site I was able to produce errors such as those I mentioned. The ironic thing is that one of the libraries that produced an error was the cross-site scripting protection library the company used. And … it produced a XSS error, the very thing it was supposed to prevent!
Including tricky code in your error-handling routine could produce errors of their own. If you are going to get fancy with your error handling, make sure you handle the errors in your error handler properly. When you get to an unexpected error sometimes the best thing to do is write the most minimal code possible and log it in a way that won’t create a vulnerability of its own.
When writing to logs you should usually write them to a separate location that can’t affect the running application, is not exposed to the Internet, and properly encode the data to prevent errors when you open the log files. Make the files read-only.
Never allow your error handler to reflect data from a user back to the screen in a web application without properly encoding it to prevent errors in the browser. When an unexpected error occurs, I prefer no reflection ever. That would be the safest approach. But I have tested systems that properly encode data and was not able to produce an error with the values I tried (so far). More on the topic of data inputs and encoding in a later post. For now, we want to write error handlers that properly capture and log errors.
Logging libraries with vulnerabilities
When you write error handlers, you may leverage a library to handle the logging for you. Sometimes these error handlers themselves have security vulnerabilities. An attacker will insert a carefully crafted attack string (or copy and paste one from the Internet) into your program. When that string is parsed by your error logging library, it might have a security vulnerability that allows extraction of memory, data, or access to your system.
You’ve likely heard of the Log4J vulnerability by now if you’re a programmer at the time I’m writing this book. However, future programmers may not know about it and some may not understand exactly what happened so I’ll include some information about it in my book. In the meantime, you can refer to this blog post I wrote previously if you haven’t read it already:
In certain applications, such as on a Windows operating system at times, an error will produce a dump file or “crash dump” of system memory. As I already explained in the last post attackers love to produce errors that expose memory, because one of the only places you can’t keep your secrets encrypted at all times is in memory. At some point, the application needs to have access to the value in clear text to process it (with very few exceptions as I explained previously).
Any time your system produces a crash dump you should pay attention to what caused it. Was it a legitimate system error? Or is an attacker is inserting strings to produce that crash dump? Many different types of errors, such as buffer overflows, will dump memory for an attacker. More on buffer overflows later. For now, be aware of any error handling that produces crash dumps or memory output and understand the risk. Be careful where and when it occurs, where that memory output is stored, and who can access it.
Handling errors in your code
If you are like me and every other programmer in the world, you don’t write perfect code. Additionally, sometimes the system gets inputs it doesn’t expect or can’t process. Sometimes you call another library that has a bug that bubbles up to your application. Any time your system can produce an error you should be aware of that possibility and think through what you want to happen when it does.
When you initially write code to define a variable and set a value there’s little chance it will produce a bug.
myvariable = 'This is pretty ok'However, somewhere in the future while your program executes something may change that variable. Any time a value in your application may change is a point where an error can occur. The type of error will depend on your application, programming language, libraries, and many other factors.
To catch an error write error handling code to capture it. The code you use to capture an error will vary by programming language.
In Java, it’s called a try-catch statement and looks like this, courtesy of the web page below.
try {
// Block of code to try
}
catch(Exception e) {
// Block of code to handle errors
}In JavaScript, C# (.Net), and PHP an error handler would use the same syntax.
Python error handling looks like this:
try:
print(x)
except:
print(“An exception occurred”)golang (or go code) uses an error object to track abnormal state. As you write code, you check for errors. This is an interesting approach and I may dive into it a bit deeper in the book, but for now, understand that it exists and use it!
Rust is another language that’s becoming more popular. Unlike other languages, it breaks errors into recoverable and unrecoverable errors:
Once you determine that an error exists, you may choose to dump the stack trace to show the full execution path that caused the error. You might choose to write some data to the screen if the application has a user interface (UI) that someone is looking at when the error occurred. You may choose to include other useful information in the application logs when the error occurred to help troubleshoot the problem.
Error handling is very important. All those actions will help you fix problems down the line when they occur and you aren’t actively running the code. It’s hard to troubleshoot an application when you don’t know what was happening at the time of the error.
An improperly handled error may be the source of secrets exposure, data exfiltration, or one of the most dangerous types of security vulnerabilities: remote code execution (RCE). That means an attacker can cause your system to do their bidding by finding a way to pass commands to it that it will execute.
Error handling and web applications
When I started programming websites all the technology was brand new. We went from some text on a website that could (which was actually annoying to most people) to full-blown applications in your browser. It’s entertaining now to read what Mozilla has to say about the blink tag:

When we wrote applications using things like Microsoft OLAP and OLE automation. I had to look back at my old software programming resume to remember the names of those technologies. A new technology came out called Java and was followed by JavaScript (and the mantra Java is not JavaScript). Later we moved on to Corba, SOAP, Ajax. Then came REST APIs, microservices, and containers. All of this can now run on cloud platforms which started with AWS ~ 10 years before most competitors became viable solutions. (Though, I do remember working on a system hosted on Joyent for a customer back in the day).
The exciting thing about OLE Automation when it came out was that you could make requests over the Internet. Your requests would get processed and send data back to the browser or some other application! This was crazy new at the time and very cool. However, when errors occurred sometimes you got back no information at all. I remember the person I worked with at the time complaining about how hard it was to troubleshoot. Things just failed. I’ve heard developers recently complaining about Cross-Origin Resource Sharing (CORS) errors which may produce similar responses.
JavaScript initially didn’t interact with the server much at all. At some point, I customized a web application to lower costs with brides incessantly trying every pricing option on a quote page. That page was costing me a lot of money in bandwidth (the amount of data flowing over the network related to each request). The cost of wedding invitations and printed items varied by quantity and it was not a simple formula.
Instead of making calls to the server to calculate the price for a quote I wrote some JavaScript to handle the calculations in the browser. My costs went down! The only problem was that some customers reported an error in the browser. I had not included any error handling code to send information back to the server to troubleshoot those problems when they occurred. I didn’t have access to customers’ machines. It was not going to be possible to get the brides-to-be to troubleshoot.
At that point, I had to figure out a way to capture errors and send them back to the server whenever I wrote client-side JavaScript functionality. I wrote some error handling code and used JavaScript to send requests server-side with the information I needed to troubleshoot problems. Of course, I had to also write error handling code server-side where the application received the data since something malicious or at least problematic could have gotten included in the data sent from the client to the server.
Back then almost all application logic got handled by servers. JavaScript was only used to create websites that provide simple user-friendly feedback not to process data (at least not by anyone that understood security). That started to change around that time when I wrote my client-side quote calculator.
Shortly after I used this type of request to process data a new library appeared on the scene called JQuery which made use of something called Ajax. I looked at this library and realized it was doing things similar to what I’d done with my quote page, though it was interacting with the server a bit more.
As I already mentioned, I’m cautious with open-source code so I didn’t end up using JQuery. I didn’t even start with JQuery, in that case. I wrote my own library from scratch so I could better understand AJAX requests and have more control over the requests, responses, and error handling. If you are not going to be very cautious with inputs, outputs, and error handling, that’s likely not something you want to do that was my approach to using Ajax in my e-commerce and content management system.
At the time, I was concerned that there was too much in that library for me to review completely, and was not sure how well the people that wrote it understood web vulnerabilities. There have been a few CVEs as you can see from the lists below. But over time the library has improved as more and more people use it:
JQuery was still largely used to process data server-side. It just provided a way to make requests in JavaScript instead of redirecting a browser to a new page. This could allow a web page to load portions of pages and process data without leaving the existing page. Most of the time, the real processing was still handled server-side.
Along came JavaScript-heavy frameworks like Angular and React. Now a lot more data is getting processed client-side. At the point these libraries came into existence, my concern was that developers would not understand the risk of processing data and storing secrets client-side. They also might not log errors back to the server making applications difficult to troubleshoot. I’ve had to answer calls for IANS clients on how to handle security issues in single-page applications, for example, which rely heavily on JavaScript.
No matter what language or framework you use to build your web applications, make sure you understand where errors occur and how they are handled. When you use web technologies that may get errors in the web browser, make sure you have a way to capture that data and send it back to the server. You’ll thank me later.
Error handling for APIs and microservices
A security vendor hired me to re-architect an existing network security product and move it to the cloud. The team I worked with was full of very experienced software engineers but none of them had worked on a cloud platform prior to that project. I had to explain some concepts to the team such as microservices and containers (which sometimes people mistakenly think are the same thing).
Instead of building one monolithic software application, we would build services. These services exposed application programming interfaces (APIs) that would allow one service to call another service to carry out some action in the system. Each team was responsible for a certain aspect of the system functionality (reporting, billing, machine configuration, etc.) and would write a set of APIs that got called by other teams.
Before we started writing any code, I brought the whole team together to decide on certain core principles. From the very beginning, we developed a set of standards for how we would go about writing the APIs the system exposed for teams to integrate the code into one cohesive application.
An important part of that was a definition of the format for errors we would send back and forth so they could be handled in a consistent way. We defined the components of an error message so each team could consume error messages with standardized code.
Even though we had a standard error format, once we started writing the code it became evident that we needed to provide a bit of additional guidance. Some people wrote error messages that lacked enough information to understand the problem and what to do about it. Teams discussed what error messages should include in general. They also worked together to resolve specific problematic error messages that one team wrote and another team could not understand.
When you write a single application and control all the code, it’s easy for you to run your application and insert breakpoints to see the values the system is processing at any given time. I’m presuming here that you know what breakpoints are and how to trigger them in your favorite integrated development environment (IDE).
I tend to throw errors instead of using breakpoints. I’m not recommending that and it’s not the standard way most programmers work. But for whatever reason, it’s always been easier for me to throw an error than fiddle with an IDE and breakpoints that stop code at a point you define with development tools. That is not always true. Some web applications require breakpoints that you can set in a browser using developer tools to make sense of what's going on. Now that I think about it, I dug into DOM-based XSS using exceptions in a white paper I wrote for IANS research, so I guess sometimes I throw errors in browser code as well. Multi-threaded programming is another case where I found using an IDE to be much easier to track what each thread was doing.You probably don't want to follow my example. I'm not a typical programmer. I often write code in notepad or vi or some other text editor because I’m too lazy to bother with an IDE for most code. They take so long to load. Have you ever looked at how many connections VS Code makes when you open it? Don't get me started on cloud-based editors. Regardless of my approach, you probably will want to use to learn an IDE if you don't know how already to understand the state of variables and threads as your application executes. You can stop an application at any point in time to see the state - if you are running the entire application on your own machine! Consider the case when you are calling an API and an error occurs within that API written by another developer, hosted on another server. You have no way to get into that application directly and see what is going on. You are reliant upon the person who wrote and is hosting that API to provide you with useful information. At the same time, the API should not expose sensitive information or data that might help an attacker use that system to break into the API.
One of the discussions we had in regards to API errors was what the HTTP response code should be. This can be somewhat subjective, but typically you will want to ensure your HTTP response code matches standard error categories. Mozilla lists the following HTTP categories:
Informational responses (100–199)Successful responses (200–299)Redirection messages (300–399)Client error responses (400–499)Server error responses (500–599)You can find these status codes further defined in section 10 of RFC 2616 and the updated RFC 7231. If you are not familiar with standards and RFCs that topic is also covered in Cybersecurity for Executives in the Age of Cloud.
API developers need to balance providing enough, but not too much information. E-commerce gateways have been writing APIs for a long time. They provide a good example of ways to provide useful error messages. Their documentation provides a specific error code — a number or a specific string— and a description for each type of error. In addition, there is generally a catch-all error code for something unidentified. In those cases, you need to reach out to the gateway vendor for more information.
Here’s an example of Stripe error codes and definitions:
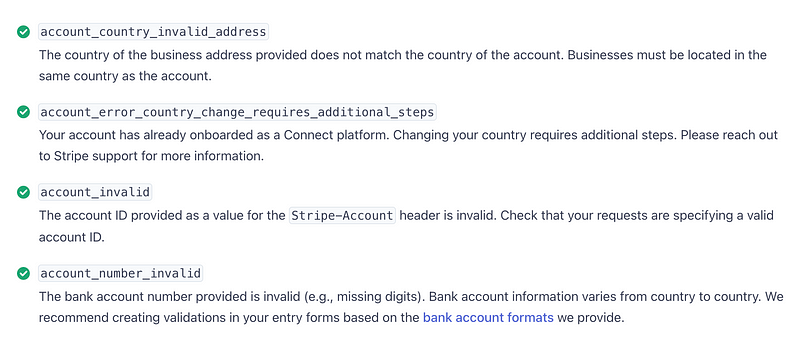
You can catch the error and provide their description or your own to the person that is trying to check out on a website. You know exactly what the error is due to the fact that the system clearly and uniquely identifies it.
When APIs provide error numbers with nonsensical error messages, the results can be painful. One time while working with APIs from a well-known firm that provides clearing and settlement of certain types of transactions we came across an error that took weeks to resolve. Part of the problem was the communication between people working on the project, but a simple adjustment to the error message returned by the API would have saved hours if not weeks on the project.
Financial systems often require the timestamps on systems generating requests and responses. In that case, the timing was off between the two systems. There was nothing wrong with the code. The QA person had simply adjusted the time on her system (apparently). By simply changing the time on the system testing the APIs we no longer had the problem that we spent something like two weeks on the phone trying to resolve. A useful error message would have saved both companies time and money.
Here's another issue with APIs to consider. That same QA person used the wrong network settings on her computer. She had moved to another team and was making calls to our test environment because she forgot to make a change to her system configuration. That completely skewed our test results. That problem is less error handling code and more about the zero-trust concept I explain in Cybersecurity for Executives in the Age of Cloud. What's great is that in a cloud environment you can give each team separate networks to test their portion of projects and eliminate such problems. However, logging the IP address that generated the error might have helped us find the problem more quickly.
Error handling in clouds and microservice architectures
Many cloud-native applications are 100% serverless, or in other words, made up of numerous APIs. A serverless function is essentially an API hosted in the cloud. You can leverage many different services that call each other to form a larger system. One of my fellow AWS Heroes and friends, Ben Kehoe, works at iRobot, and at the time of this writing, their systems are almost if not completely run via serverless cloud functions. (By the way, his blog on Medium is currently covering a lot of great security topics and I recommend reading them if you use AWS!)
Applications with many microservices hosted on Kubernetes or something similar will generate errors in different containers. Those different containers may be operated by different teams. Where are those error logs written and how do you retrieve them? Can you pinpoint an error caused by each API or is it buried in calls that don’t provide a complete stack trace that show you where the problem lies?
You may also have systems that leverage third-party APIs. Those APIs may provide error messages or error logs in different formats. How do you access or track errors from these APIs? Can you trace a piece of data derived from a third-party API as it makes its way through your network of microservices and API calls?
When you are writing your code ensure you provide enough information to pinpoint exactly what error occurred in the case of a security incident. Your security team will need to know what system or code triggered the error. You’ll need to ensure you have a copy of the logs and error messages in the event that a container shuts down. Your error messages need to clearly indicate what caused the error.
One time while working on a penetration test, I inserted a value that did something very bad to the system. Let’s just say parts of it were slightly non-functional. My contract states this can happen, which is why I suggest starting in a test environment, then moving to production after that, unless you are sure your developers have handled inputs correctly (something I’ll cover later). If I don’t test it for you, someone else will, like it or not. I wrote about that in The Unrequested Pentest. They had other companies perform pentests in the past which apparently did not uncover the problem.
The developer involved wanted me to pinpoint what I did to cause the system issue. That’s no problem and completely understandable. When I perform a penetration test I have a record of all the requests I make to systems so I could provide that data and work with the team to find the root cause. But I also posed this question back to the team to try to help them think through a potential security incident caused by a similar issue. What if an attacker did this to your system? Would you be able to pinpoint the error and resolve it if I wasn’t here to provide the exact inputs that caused the problem?
Think through your error handling to determine what you might need to troubleshoot a problem in the event of an error. Ensure you can trace an error back to the root cause.
Handle every error — with a few exceptions
I’ve read recommendations that say you should only capture known error types. What do I mean by “known error type?”
Consider the Java Integer class. As you know an integer is a whole number that is not a fraction such as 1, 2, 3…and so on. The Java Integer class has a method called decode() that will allow you to pass a string into it and get back an integer. You can see the definition below from the Java documentation. Notice that if you pass in a string that is not an integer, it throws an exception called “NumberFormatException”.

When you are writing your error handling code in Java, you can catch that particular exception and do something with it. Then you can separately catch other types of exceptions and do something different.
try{ //Something that throws the NumberFormatException error}catch (NumberFormatException e) { //Print an error message
System.out.println("Oops. That's not an integer.")}
You can also catch multiple errors in your catch block:
catch (IOException ex) {
logger.log(ex);
throw ex;
} catch (SQLException ex) {
logger.log(ex);
throw ex;
}Note that in the examples above, if an error occurs that is not one of the types of errors you’ve captured, the system might stop processing. My preference, in most cases, is to catch every type of error I can and log it while allowing the application to continue processing. There are a few exceptions where you actually want an application to exit, because it is improperly started using the incorrect input parameters, for example.
When writing system libraries, you generally want to throw errors rather than handle them within the library itself. It could depend on the type of error and what the library is doing, but generally, it is better to let the calling application handle most errors. This is once again a case for some software engineering and threat modeling to come up with the proper system design. It will depend on your specific use case. Consider the types of errors the library generates and what could go wrong. Handle those scenarios in a way that provides adequate information to troubleshoot the problem.
Do not swallow errors
Never write an error handler that captures an error and does nothing. This is one of the most dangerous things you can do when handling errors. This can lead to very tricky bugs in large and complex systems. It may also result in security problems when errors are not correctly logged by the system.
catch (Exception ex) {
//an error occurred but this code does nothing about it.
}Maybe I’ll provide more examples in the book, but that’s all I’m going to say about that right now. Don’t do it!
Ensure error handling logic produces correct results
You need to understand your error handling logic very well to prevent data processing errors. Make sure that your system processing and error handling produces correct results every time, even when an error occurs.
I used to work on back-office systems for investments and related tax records. If an error occurred and did not get handled properly, a person doesn’t get more or less money than they were supposed to get as a result. In other cases, money could end up in the wrong account. I’ll write more about the types of errors that can occur that allow people to steal money or send it to the wrong place when I write about topics like transactions, concurrency, and data types.
If you have a process that takes multiple steps to complete, skipping a step could produce inaccurate results. Consider an e-commerce transaction processing flow. What if you had a page to enter the address, a page to enter credit card information, a page to review and submit the order, and a receipt page. Perhaps an error occurs on the page where the customer submits their order. Their credit card never gets processed but somehow they end up placing the order anyway and land on the receipt page. Your error handling related to credit card processing needs to prevent order submission when an error occurs.
This is a question I often asked when interviewing candidates to work on back-office banking systems: Let’s say you have a system that makes calls across a network to update the money in a bank account. The network connection times out before you get a response from the system to which you made the request. How do you handle that? Possible answers:* Resend the transaction to make sure it went through.* Assume it went through and don’t do anything because you don’t want the person to get a double payment.What do you think? Keep reading and I'll provide more information in a future post.When errors occur in a system you need to ensure that any data in process at the time of the error ends up in a valid state. Sometimes, as I explain later, you stop processing and log the error. Sometimes you completely roll back a transaction. In any case, the most important thing to remember is to test all possible error scenarios and ensure your data ends up in a valid state. Testing error paths is often overlooked in development and QA processes. If you have a bug like this in your system, I’m going to try to find it on a penetration test and exploit it!
Displaying errors in a UI
A graphical user interface (UI) is the portion of an application someone uses when they click on buttons and type data into text boxes. These user interfaces are designed for non-programmers to interact with the system.
As I mentioned, you don’t want to provide information that could help attackers who are trying to poke at the system and cause security problems through your UI. Do not provide your server IP addresses, database names, and other backend system information that could be useful to an attacker.
However, you should consider the type of information you need to provide to users to both make their experience better and resolve issues quickly. In some cases, those issues could be security problems. When an error occurs, a user should be able to identify if it is a security problem or not.
One very helpful piece of information in web applications that helps users identify security problems includes the IP address that caused an error to occur. This may be useful in certain types of applications where the user’s account may have been compromised. For example, if I can see the IP addresses logging into my email system or bank and one of them isn’t mine, I immediately know I have a security problem.
In general, it’s a good practice to provide useful information to help people quickly resolve problems in your application. Providing an error code as mentioned previously can help pinpoint problems more quickly. You can also include identifiers that help your support team quickly find an error message related to a customer problem in your logs. That way, in the case of a security incident, you can figure out what is going on more quickly.
Generic error handling functions
Error handling can be tricky and repetitive (and boring!) Who wants to write code to handle errors. I’d rather be building something cool that people see and appreciate, right?
One way to reduce errors in your error handling code and to ensure it follows your standards and specifications within your organization is to write a generic error handling class, function, or service that people call when an error occurs. Once again we are using the principle of abstraction to remove repetitive code and reduce errors.
Write your error handling function such that it minimizes your overall codebase, prevents errors when parsing the exceptions that occur, and eliminates potential security vulnerabilities in the way you handle errors.
Next steps
- Review error handling to see if it reflects data back to users in a way that could reveal secrets or sensitive information.
- Review your code to find places where error handling is lacking or insufficient.
- Remove or update error handlers that swallow errors to prevent missing error messages.
- Ensure that you review and test error handling functions in libraries and logging systems.
- Capture all errors where appropriate.
- Ensure error handling functionality in applications, APIs, and libraries provide the appropriate amount of information to callers.
- Test all possible paths and errors in your systems to ensure proper data processing.
- Consider standardizing your error messages with an error code.
- Ensure error messages provide enough information to resolve security incidents quickly.
- Consider using the principle of abstraction to create generic error handling functions and processes.
Maybe I’ll write a sample generic error handling function for the book but this blog post is already very long! I guess I had a lot to say about errors and could probably think of more if I tried. This may need to be split up into multiple chapters when I organize and finalize the book.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2022
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab





