
Refactoring to reduce open source code risk
One method to make safer use scripts and code you find on the Internet
One of my post that may later become a book on Secure Code. Also one of my posts on Application Security.
Free Content on Jobs in Cybersecurity | Sign up for the Email List
As I explained in a prior post in this series on software security, refactoring helps you refine code to improve upon it. You can leverage refactoring when you use some open-source code to reduce the risks associated with using that code. When you refactor the code, you can make sure you understand each line of code and all of the libraries that code includes. You may be able to reduce the number of lines you use and remove risky functions you don’t need.
I’ll walk through how I refactored a piece of code recently at the end of this post but first, some caveats. Refactoring is not always the approach to use if your goal is to reduce security risk. Sometimes refactoring open-source code increases the chance your organization will face a security incident.
Complex open source libraries that need security updates
Refactoring code may introduce security risks when using a complex library that you need to update to obtain the latest security fixes. For example, if you are using React or Angular for your front-end web development, you may need and use many of the functions those frameworks provide. Heavy refactoring makes it challenging to update to newer versions. When security vulnerabilities are discovered and fixed, and you try to upgrade, the process may fail.
Additionally, if you have custom code in your refactoring that your application depends on, it could break when you update to the next version of the open-source library that doesn’t include your custom code. As you try to reintroduce your changes to the latest version, you may introduce more security problems and bugs compared to using the library straight from the source.
A better approach if you are using complex open source libraries or frameworks such as Angular and React will likely be to use them as is. Then monitor for security vulnerabilities so you can address them quickly. Your security team probably has a methodology for doing that, but you can track CVEs in software at mitre.org.
CVEs in Angular:
CVEs in React:
The good news about those particular libraries is that they are widely used, supported, and analyzed for security vulnerabilities. Follow best practices for using them. Even secure code can cause security problems when used improperly or security mechanisms get bypassed to “fix” other problems.
Those libraries have built-in protections for common web flaws if you use them correctly. Over the past few years, these libraries have added built-in encoding to prevent some of the most prevalent OWASP Top 10 web application flaws like cross-site scripting (XSS). If you don’t know what that is I refer you to the OWASP website or one of the many web application security books out there such as Alice and Bob learn Application Security by my friend Tanya Janca or a classic: The Web Application Hacker’s Handbook.
Security code
Refactoring is definitely not recommended is when it comes to security functionality you don’t understand, and sometimes even if you think you do. You want to get that code from a trusted, vetted source. Often, the longer a library exists and is in use, the more it gets scrutinized for security flaws.
Some vulnerabilities exist even after a long period of time in widely used software, such as the recent log4j vulnerability. If and when that unknown vulnerability got exploited, other security controls a security team puts in place should have identified the system compromise on the network. In general, however, widely used programs should undergo more vetting than libraries that do not have a large user base or have not existed very long. If you choose to use open source security code, get it from a trusted source, and don’t modify it unless you are sure you know what you are doing.
One common mantra is “Don’t roll your own encryption.” Encryption is hard. Too many times in the past, developers have attempted to write their own code to encrypt data and failed. Unless you have the staff and resources to tackle this problem correctly, don’t. And when I say staff I mean you have cryptography experts on staff, not just people who are are tinkering with cryptography or took a class on the topic. Use industry-standard algorithms with appropriate key sizes.
If you are curious to learn more about other types of security controls and basic encryption concepts, I explained those in my book: Cybersecurity for Executives in the Age of Cloud.
Use open-source code from trusted sources
You may have heard about a serious security vulnerability called Heartbleed that affected an open-source OpenSSL library. One erroneous snippet of code could allow eavesdroppers to snoop on much of the data traversing the Internet. After this security event occurred, AWS decided to write their own encryption library to use within the AWS cloud environment.
Unlike many companies, AWS has an extensive security team, and some of the top security professionals in the US and the world work for them. If you use AWS, you might opt to use their libraries which undergo extensive source code reviews.
Why would you want to trust Amazon? You may or may not, but they talk about their code review process in this AWS re:Invent presentation where they explained how they came up with s2n ~ their own encryption library to replace the one that was affected by Heartbleed.
When you leverage encryption you have to use the correct algorithms and sometimes the correct encryption modes. I learned all about how to attack those things in an advanced penetration testing class. The product manager for AWS encryption told us at our meetup in Seattle how AWS writes code to implement those things properly in their SDKs so customers don’t have to worry about it.
You will still want to review and inspect the code as much as possible. Don’t blindly trust vendors as they don’t always have the most secure programming practices or well-trained staff — even at security product companies. But in the case of Amazon encryption code, they likely have better resources to vet encryption code than most other organizations. Additionally, their business depends on the security of their services and programming libraries.
Code samples are another matter. I’ve found security problems in code samples for AWS and other cloud vendors and even security vendor code. Sample code doesn’t always follow best practices. Sometimes these code snippets aren’t complete because they are only demonstrating one aspect of how to use a particular function, rather than how to write a secure piece of production code. Review any sample code carefully. Do not assume it is secure simply because you pulled it from a vendor website.
Refactoring for product code
I remember how my dad was all excited about computers when I was a kid. Although I taught myself to program, I wasn’t an over-the-top geek. One day I walked into his office in the late ’70s or early ’80s and he held up a floppy disk. It was the 5 1/4" size that could actually bend. The hard smaller disks arrived later. “Do you know what this is?” he said gleefully. It holds (some huge amount of data at the time). I was like “yeah, yeah, Dad.” I wonder what percentage of my readers don’t know what a floppy disk is or at least have never seen one in person. But that just makes me sound old, so never mind.
In 2015, long after the use of floppy disks had mostly ended (though I read they are still used to update aircraft systems) a security firm named CrowdStrike discovered a flaw in virtual machines they called VENOM. This vulnerability existed in a portion of code used to support floppy disks within some virtual machines. Some of those virtual machines could have been running in cloud environments.
Why would anyone need code to support floppy disks in most modern computers and especially in a cloud environment? The extraneous code turned out to be a security risk. Just as I explained in a prior post, every line of code is a potential bug. Some cloud vendors had to address this risk, but luckily, Amazon did not. Somewhere along the way, someone realized the code was extraneous and removed it from certain XEN virtual machine code bases.
Depending on your level of experience and use case, you might go ahead and refactor something complex to remove extraneous code. When I hosted e-commerce websites using a jetty web server back in the day (think Nginx, Apache, IIS, Tomcat, etc.) I completely modified the webserver after I had a data breach. My objective was to build a custom product, not just host websites. I also wanted to remove any unnecessary code for security and performance reasons. When creating a custom product, you may opt to embed and refactor open source code to remove the functionality you don’t need to reduce risk.
In my case, I was building a custom e-commerce web server and content publishing system that could handle any web design using XSL templates. I was also integrating security features. I stripped out any functionality within the application I did not need and incorporated a custom WAF to inspect all traffic. As jetty got updated, I would review and incorporate the code as necessary. I had many years of experience at that point, web application security experience, and a very secure network.
Over the years jetty, which started as a simple web server you could embed in other systems, got very bloated as people wanted more and more features. I didn’t need or want all those features. My use of the original code base remained a stripped-down, lightweight webserver that included only the functionality I required.
Problems with online code samples
If you are pulling a piece of code off the Internet just to solve a single problem, there’s a good chance that refactoring is a good idea. Instead of using the entire library, product, or even a class to perform one function, pull out and use the code you need. Remove unnecessary functionality. Refactoring the code will help you review it, improve upon it, and streamline it down to what you need instead of pulling in a large library that references many other libraries to perform a single function.
As I mentioned above, be careful with online code samples. Even well-intended samples could have inadvertent flaws or fail to follow best practices. Here are some examples I’ve found. Hopefully the companies have addressed these issues by now.
- I found a questionable use of AWS Cognito and Lambda@Edge with potential caching issues.
- I’ve seen developers promoting incomplete authentication solutions on YouTube getting rave reviews.
- In another blog post, I explained how a Google Cloud code example used a deprecated OAUTH flow. They may have fixed it by now.
- I’ve found sample AWS IAM roles from security vendors that grant excessive permissions that could change all your production database passwords. That may be ok depending on how you use it — or not. Just understand the risk.
- I talked about sample code from AWS that introduced a security risk at RSA. In fact, I spoke about the same functionality from a different angle at RSA in a prior year’s talk as well and how an attacker might abuse it. AWS says it’s a feature, and the functionality is as expected. I say understand the attack vectors and how it affects your use case. In the presentation you can watch by following the link, I could bypass file upload controls on a website and put any file I wanted, including malware, in an S3 bucket.
When you are trying to figure out how to use a particular API, library, or other pieces of software you may turn to code samples. I do it all the time. That’s perfectly fine. These code snippets are usually good candidates for further inspection and refactoring to incorporate security best practices.
Solving a Single Problem
I wrote in my last post about the dangers of copying and pasting code. Copying and pasting code without reviewing it may bring security vulnerabilities, bugs, or at a minimum, extraneous code into your codebase. When you are trying to find code to solve a single problem, often that is a great case where you can and should refactor code before use. That’s what I’m going to demonstrate now with some sample code that helped me solve a problem.
I don’t think the code I am going to show you is necessarily dangerous. It is simply more than I needed to perform the work I was trying to do, so I decided to slim it down to only what I required. Then I noticed some of the DRY issues I explained in my subsequent post, so I went ahead and resolved that as well. Reducing the code helped me understand what it was doing, and it reduces the risk that something I don’t understand or need in the code contains a security vulnerability.
Before I show you the code I’m going to refactor, let me explain that this code is not “bad.” In fact, it helped me tremendously, and thank you so much to the person that wrote it! Often the first time we take a crack at the code, it is not how we would write it if we had more time. In the famous words of Mark Twain, which are not actually from Mark Twain according to this website: “If I had more time, I would have written a shorter letter.” I know the feeling. Probably this blog post falls into that category.
I wrote some AWS security automation code for a security white paper. Then later, I went to use it in a security class, and I thought it was terrible upon subsequent review. Writing the initial code was complicated. I was on a deadline. I had multiple problems with the technologies I used in the white paper. It took me three months, and I had to request an extension to get it done. Hence, the code is not as wonderful as it would have been if I had more time. When I went to add it to the class, I asked the person helping me to refactor it and did some of it myself. So in no way am I knocking this code below, it’s just for demonstration purposes.
Step by step refactoring of an open source code sample
On every penetration test or cloud security assessment, I create new tools or improve on the ones I already have. Sometimes a customer will have a new kind of software or application I haven’t tested before. Sometimes there’s a new query I want to write against cloud APIs because I’m digging into a particular risk within the customer’s cloud environment. At times the cloud provider has released new products and features I want to incorporate into my tools.
During a recent engagement, I was looking over boto3 APIs and wanted to use a particular function, but I forgot how it worked. I had used this function before, but I forgot to check in the code. (Check-in often!) I took a couple of cracks at it but then decided it would be faster to just find a code sample that used it. The function is part of the AWS Python boto3 SDK and is called generate_service_last_accessed_details.

The easiest way for me to find my code example was to search for the function on GitHub so I typed this into Google:
generate_service_last_accessed_details githubThe first thing that came up was this code sample from AWS. That made me pretty happy because generally you can trust AWS code. You still want to review it but it makes you feel like at least it’s not intentionally malicious.
Note that this particular Python file is part of a larger repository. Right away, I knew I wasn’t going to use all the code. I just needed to understand how to use the particular function I was after. That reduces the code I need from this repository significantly.
I needed this function to generate a report. When I perform an assessment on a client cloud account I ask for read only permissions. However, I still don’t want to take any chances that I might inadvertently do some damage or change a configuration. I scanned this file and immediately I can see it has functionality I don’t need. It’s creating IAM Policies and I would never do that in a customer account, so I’ll remove that. Thankfully the author left good comments for me to figure out what is going on.
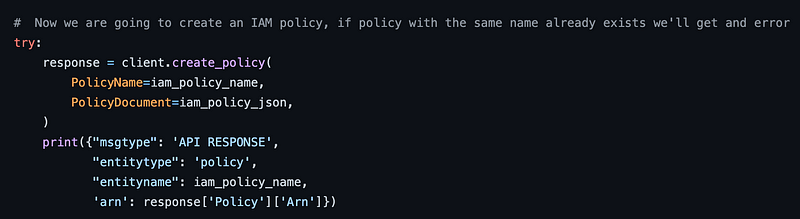
The author of this code is demonstrating how you can automatically set permission boundaries based on the permissions in use within an account. The code retrieves the report data I’m trying to obtain, and then takes action based on the findings. Whether or not this code does that well is not something I reviewed and beyond the scope of this post. I just know I didn’t need some of that code and was going to remove the related functions. I removed anything related to that, including the following:
Initially, I took out all the code I didn’t need and tried to run the code to see if it would execute. It didn’t. I could have tried to troubleshoot that error and continue to whittle down the code but at that point, I took a different approach. I wasn’t sure what some of the remaining code was doing and rather than try to read it all, I started to dissect and rebuild the code piece by piece. As I did that, I realized there was some duplicate code I could probably abstract out into a common function.
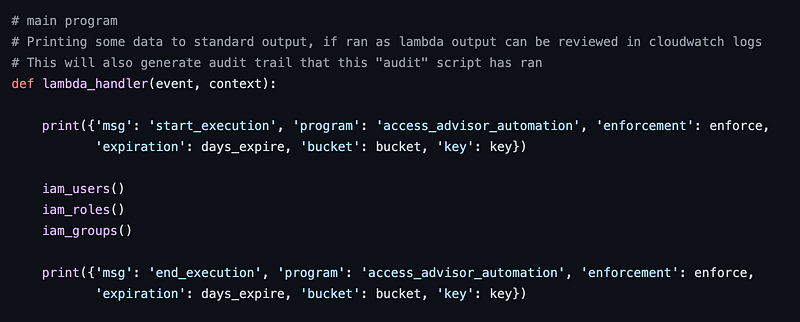
First I had to figure out where the program started. This is a lambda function so it starts in the specified lambda handler function, which in this case is lambda_handler.

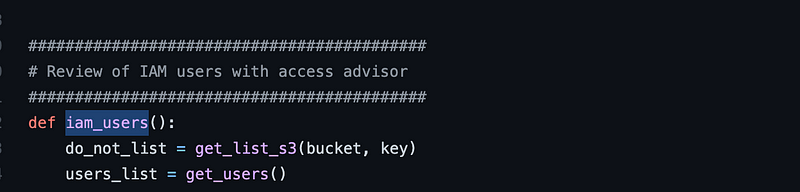
Next I look for lambda_handler. It’s right above. Ah, it says it right there. It prints out some logging statements and calls three functions. iam_users, iam_roles, and iam_groups.
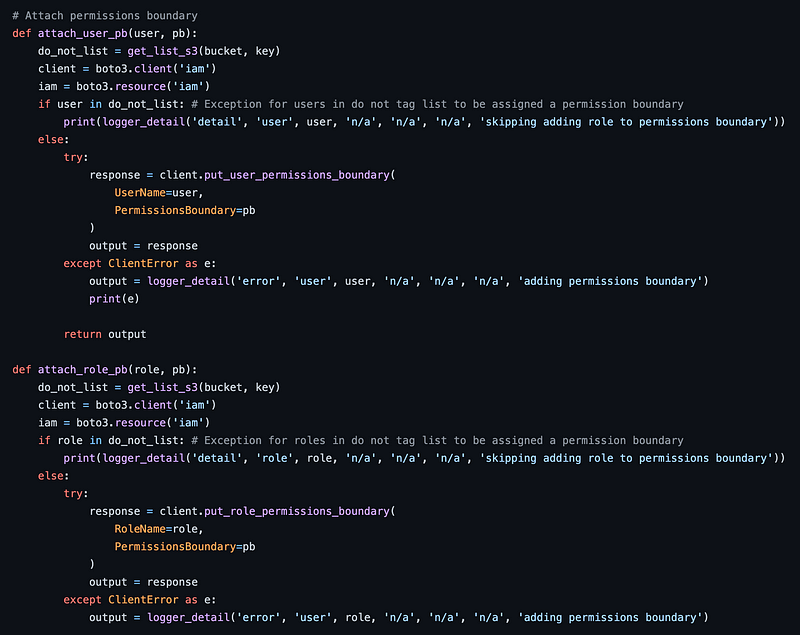
Let’s start by looking at iam_users. The first line is using an S3 bucket. I don’t want to bother with that. The author had it in there to track and skip certain users from having their policies altered. I’m just printing a report so I’m going to skip that and will need to remove any related functionality using that do_not_list variable.

I can remove this function also as a result.
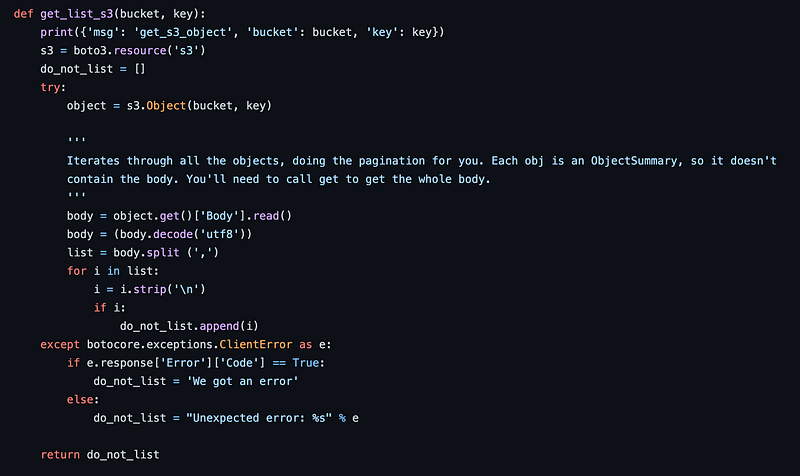
Next the program gets sets the users_list variable by calling get_users() so let’s search for and look at that.
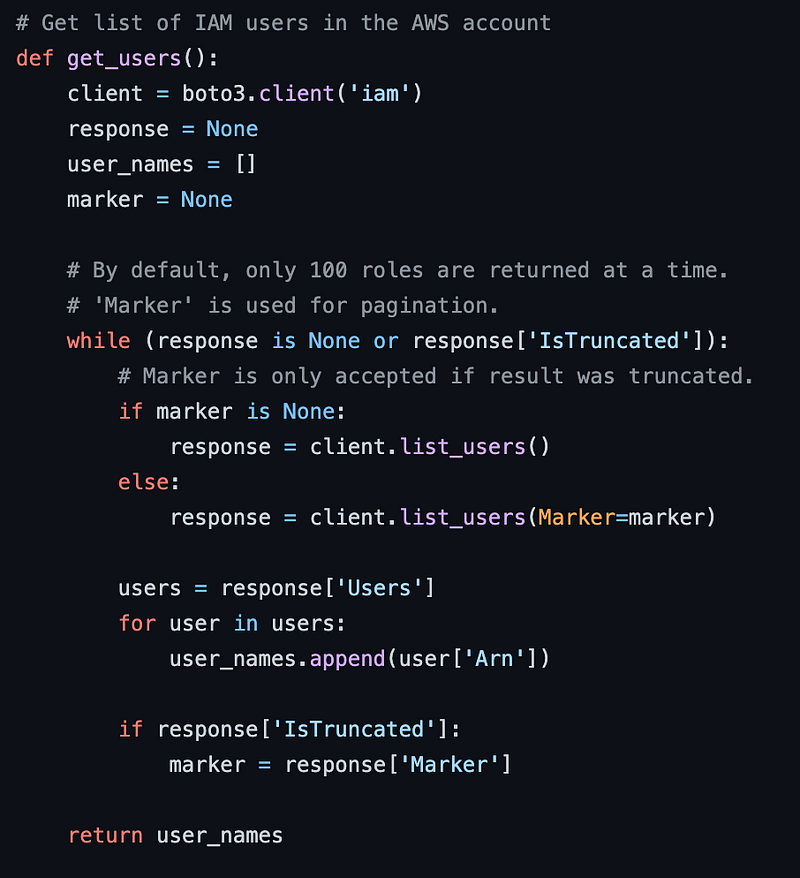
This function instantiates a boto3 client for the IAM service to request a list of users. We’ll need to do that. This function handles pagination nicely when the list of users is over a certain length. It may necessary to handle large data sets for my clients as well, so that code is useful. I don’t really see any problem with this code, and I thought likely I’d need it all at first glance.
Just like my other sample code to print out JSON data in a user-friendly format, this code requires a client to call AWS APIs. I could go head and create a client to start with. I can reuse the refresh AWS boto3 client code I showed you before in a separate blog post. Simple, I’ve already written this code.
#!/usr/bin/python3
import refreshsession as rsprofile="[your profile]"
service="iam"#using included code to refresh periodically to avoid MFA timeout
session = rs.RefreshSession(service, profile, 3000)#iam is global so region doesn't really matter
session.set_region('us-west-2')
client = session.get_client()Moving on to the next section of our iam_users() function called from the main handler, the code loops through the list of users. It sets some variables and counts. For my purposes, I ended up removing the counts as I was querying for specific risks. Initially I made a mistake regarding the jobid variable, and removed it. You need to call some code to kick off a report job. Then you use the job id to retrieve the data. Two functions below handle that: generateServiceLastAccessDetails and getServiceLastAccessDetails. Let’s look at those.
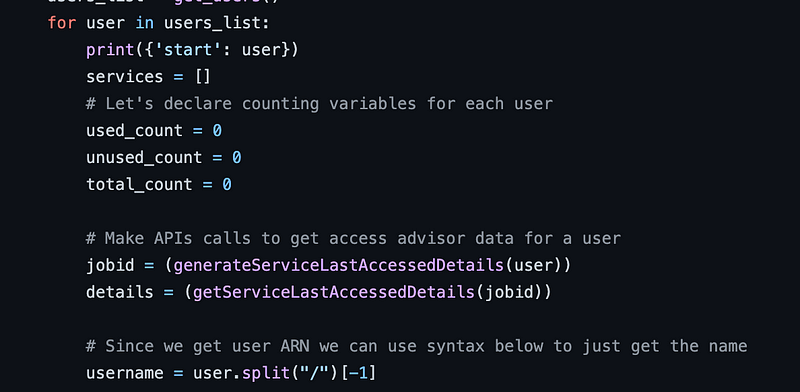
Here’s the first function. What do you notice about this function?
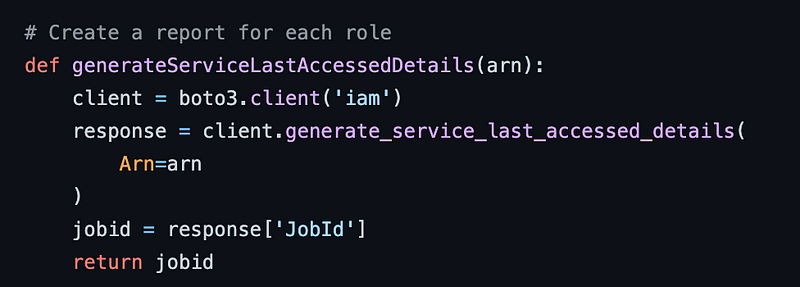
I noticed that this function creates a new boto3 client. Instead of a new client I could reuse the client I already initiated and pass it into the function.
I took a look at the next function. This function is also looping through a list of values from an API response and using a marker to determine if more than 100 items exist. The comments mention roles but I think the author meant jobs. Do you notice anything here?
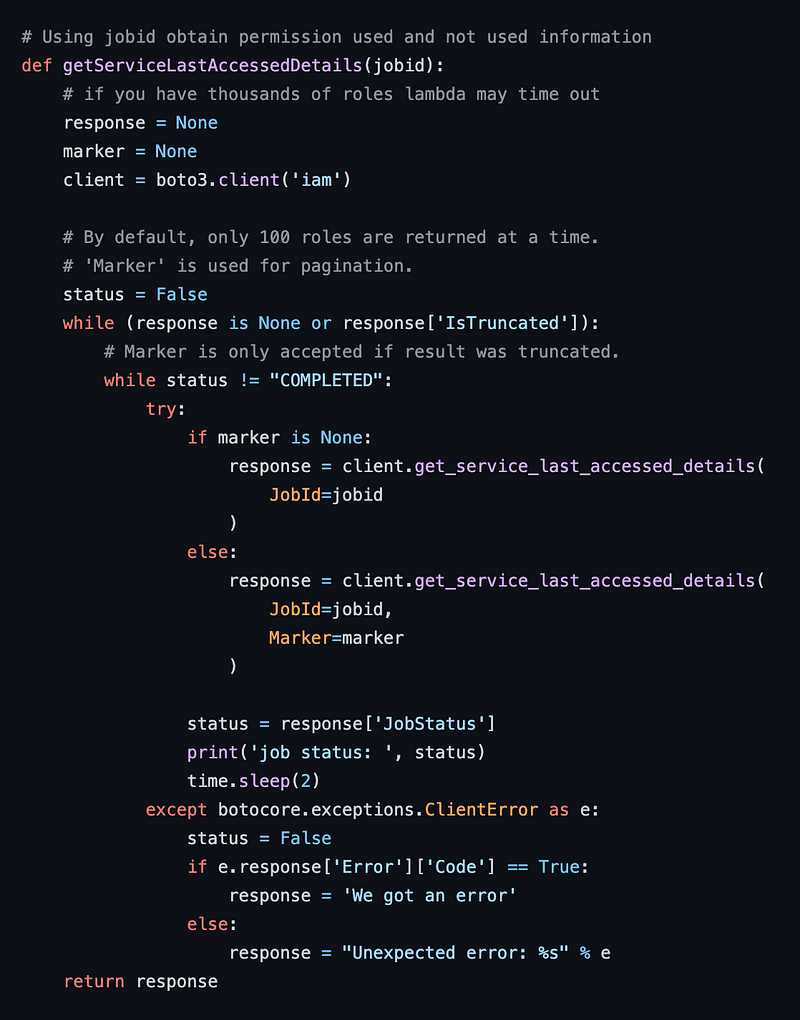
I’m seeing a similar pattern to the code that loops through users, but I’m also seeing something different. We need to check the status to see if the job is completed before continuing. Not sure if we could refactor that out. I ended up keeping two separate functions due to the differences. Maybe could have reduced the code further.
Returning to the iam_users function, you may have noticed that the code parses the user name out of the ARN (an identifier used in AWS). I used that to print out the user name.
In this code, it’s looking at all the users permissions as well as when the user last used the permission. The code leverages an expiration period to determine how long ago the person used the permission as well. I just wanted to print unused permissions. I removed all the date code. I also didn’t need the logging code because I just wanted to print out a list. The function goes on to tag users and set permission boundaries, all of which I removed. Instead of looking for services not used within a certain time period I looked for services never used at all, which was more appropriate for the particular client for whom I was creating the report.
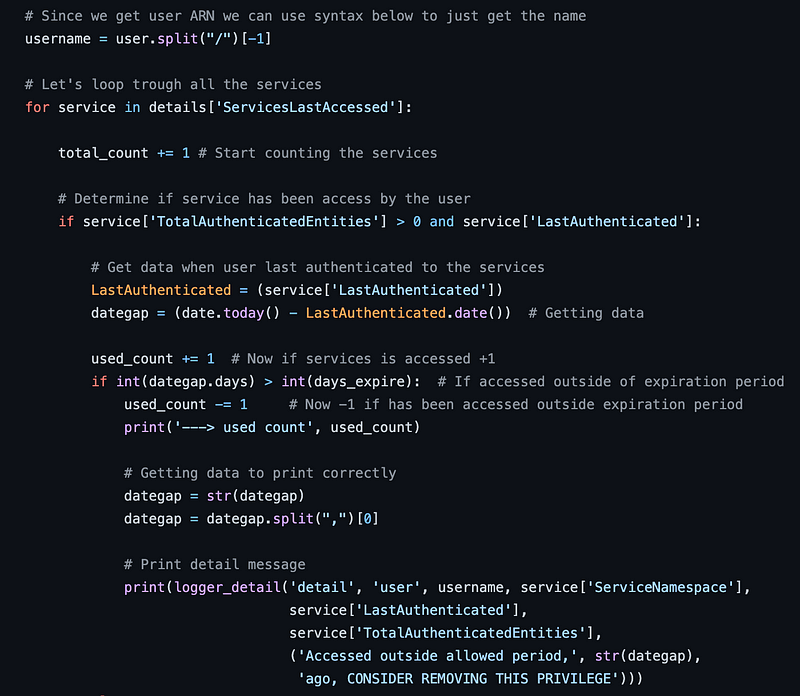
As it turned out I needed to leverage this value for each service within the report response:
if service[‘TotalAuthenticatedEntities’] == 0:in which case I would print the service name:
servicename=service[‘ServiceName’]I could do a lot more with the data but that was the objective for this particular query.
Once I got the list of unused services for a user I moved on to the next function: iam_roles(). Notice anything about this code?
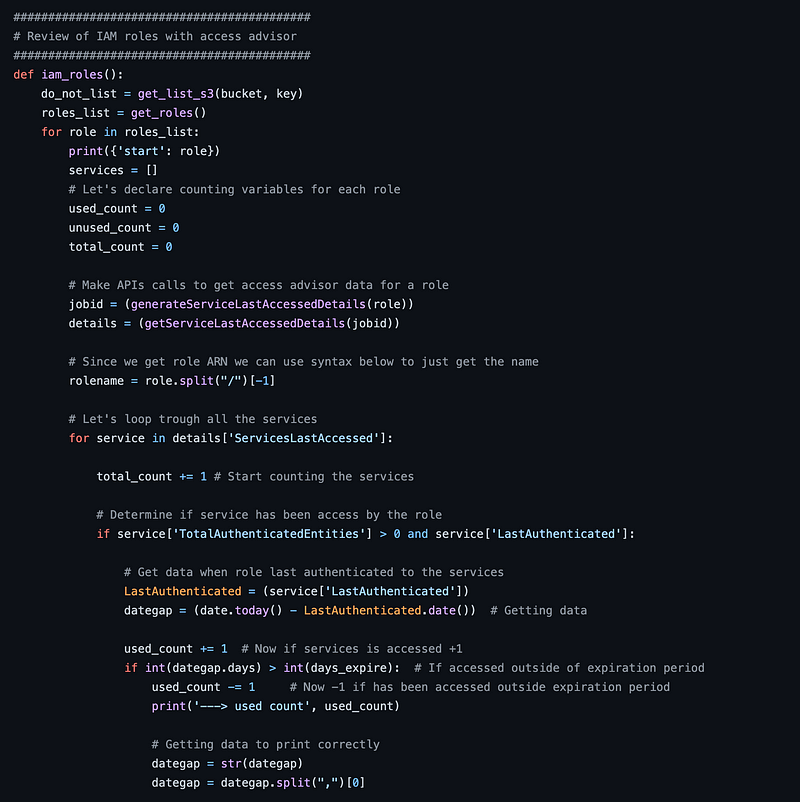
Looks pretty familiar doesn’t it? It’s pretty much a copy paste of iam_users. Nothing ‘wrong’ with it. It works. But it’s duplicative.
Let’s look at the get_roles() function.
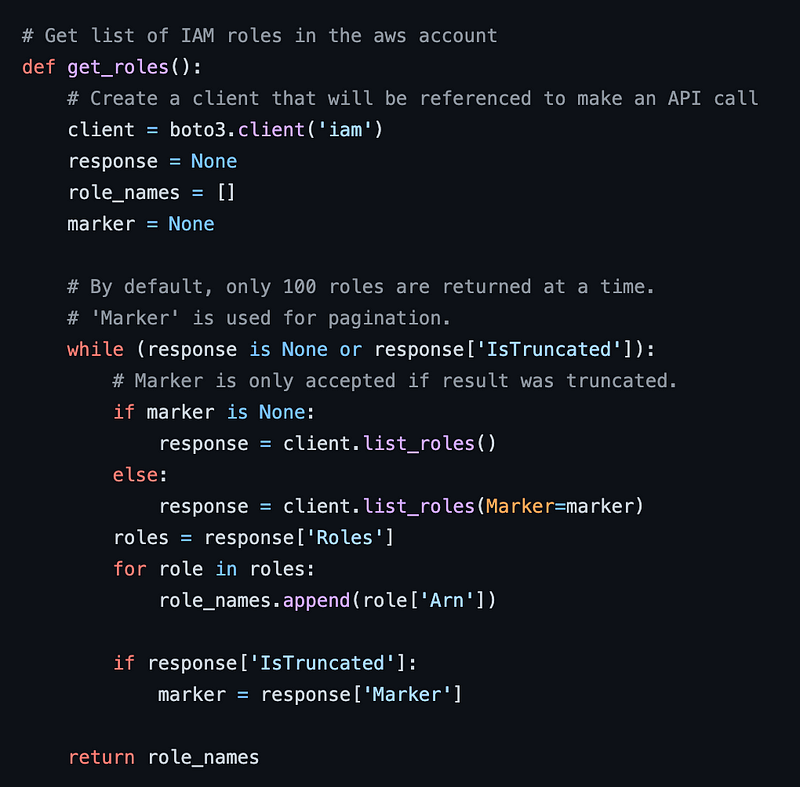
Search and replace ‘user’ in get_users with ‘role’ and you have pretty much created the get_roles function. Maybe we can streamline this a bit and abstract out the common functionality.
iam_groups was the same.
Resulting code reduction
Take a look at the original code on GitHub. Then compare to what I ended up with below. I was able to reduce the amount of lines of code quite a bit using the principle of abstraction. I took out a number of lines related to functionality I did not need. Here’s the result, plus the required included libraries not shown, which were my own or standard Python libraries.
In the end, I pulled in the generic code I wrote about in my abstraction example that prints a value from any JSON response. I wrote a single function to retrieve a list of users, roles, and groups. I had to catch an exception at which point I discovered why some users were throwing errors and skipped. I used the error handling in the function below to determine understand the problem. Then I added some code to handle those cases in the calling function.
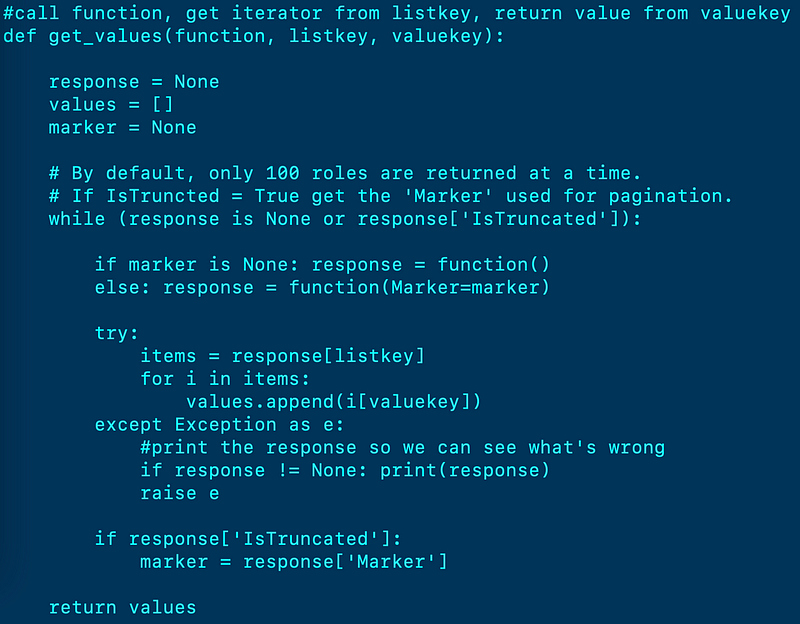
I created a single function to get the list of when services were last accessed for an entity:
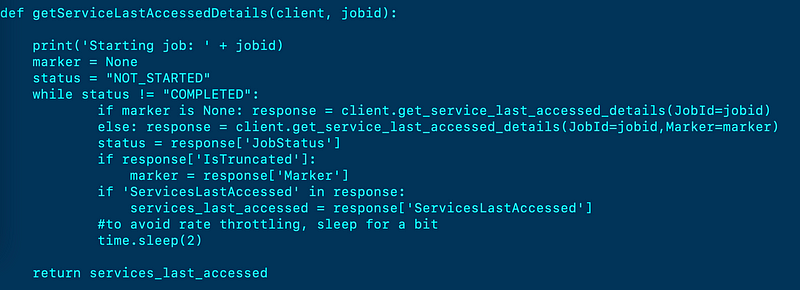
I wrote a function to generate my report:
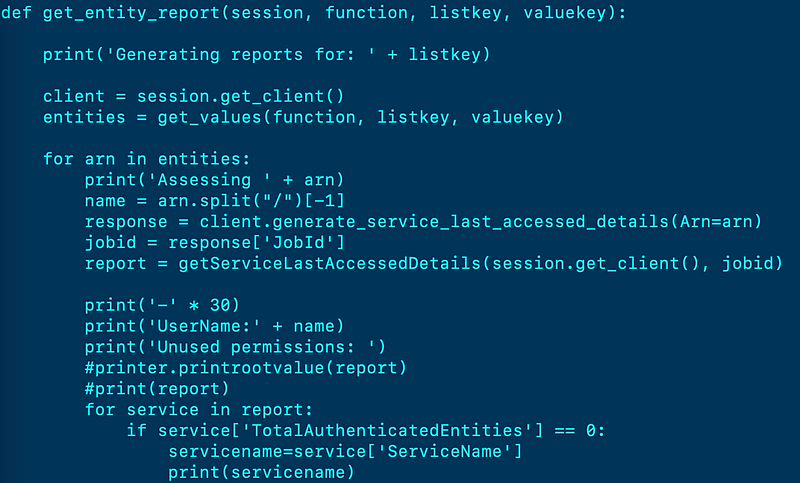
I used the commented out code above to understand what was in the response initially. I could have removed those lines in the end.
I replaced the three calls to iam_users, iam_roles, and iam_groups with three calls to my single report generating function, passing in the type of resource for which I was creating the report.

I probably could have skipped passing in the ARN if I had time to write shorter code — and would probably have less typos in this blog post if I had time to spell check it better. :-) When I turn this all into a book maybe I will have use the same editor I did last time and have more time to organize my thoughts, but hopefully you found this helpful in your journey to evaluate open source code and streamline your own.
Thank you so much again to the person that wrote the original code. I don’t know how long it would have taken to figure out how to do this without that sample as a starting point!
Next Steps
- Evaluate all code before incorporating it into your own code base.
- Check who authored any source code you use. Consider only use code as-is with automatic updates from trusted sources.
- Understand how the code you use gets reviewed before release. Determine if you should perform your own review before using or updating the code.
- Evaluate whether a particular piece of open source code you want to use should be used as-is or if you should reduce or refactor it to meet your needs.
- Ensure you monitor and can quickly update open source code you choose to use as-is.
- Evaluate code samples to understand what they are doing, add software security best practices as needed, and remove extraneous code.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2021
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab