
Deploying a Stack With The 2SL Job Execution Framework
ACM.440 Deploy a 2SL Job Execution Environment — Step 3— Deploying multiple resources with a single job configuration
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Part of my series on Automating Cybersecurity Metrics. The Code.
🔒 Related Stories: AWS Security | Application Security | Batch Jobs
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post I added a job configuration to deploy a single resource — the dev OU.
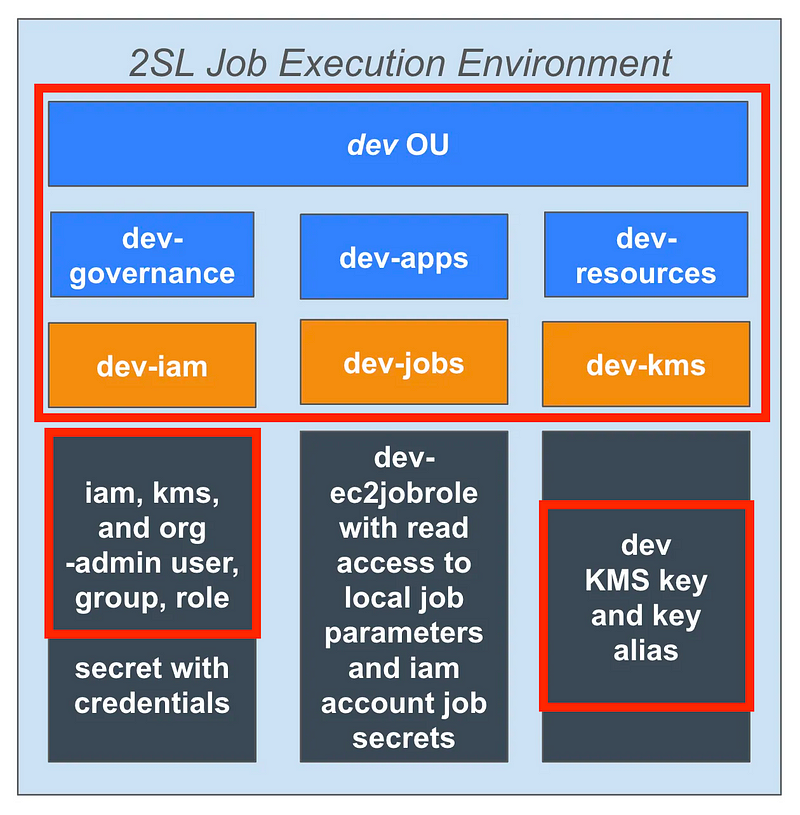
In this post I want to consider how I will deploy all the resources in our stack below. A stack of resources is just a bunch of resources you want to deploy together as a set.
TLDR;
How to deploy a stack of resources
* Add a stack configuration parameter to the config git repository
* use the standard naming convention but make the resource category stack
* use the script in the parameter repository to deploy the SSM parameter
* Run the job to deploy the stack
2nd Sight Lab Job Execution Framework Does The Rest
Stack Configuration constructs:
* :ssm: indicates to get the value from another SSM parameter
* :get_id: indicates call that get_id function for that resource type and name
* cfparam prefix for a value to pass to the CloudFormation template parameter.
* Sequential means deploy a list of resources that follow sequentially
* Parallel means deploy a list of resources that follow in parallel
Sample Stack Configuration:
Sequential:
/job/awsenvinit/dev/organizations-organizationalunit-dev
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:root
Parallel:
/job/awsenvinit/dev/organizations-organizationalunit-governance
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-apps
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-resources
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
Parallel:
/job/awsenvinit/dev/organizations-account-iam
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:governance
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:org
/job/awsenvinit/dev/organizations-account-jobs
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:apps
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:org
/job/awsenvinit/dev/organizations-account-kms
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:resources
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:org
More changes on the way to make this all easier.
Follow for updates.Heads up — more repository changes on the way
Just a note that this post is focusing on making the stack configuration work.
After using my repository format for a bit I figured out it was too cumbersome and not exactly what I want so I think I have one more set of changes coming. Hopefully it will make things simpler. But I didn’t want to include that in this post.
Also, I don’t have all the resources above configured and working correctly yet. Will do that and get it checked in as time allows. But the stack configuration properly loops through the items in the stack and passes whatever CloudFormation parameters are configured to the template.
In theory parallel and sequential processing should work, however I have to take a closer look at the AWS deploy function. I may have to pass the parallel processing through to the deploy script and spawn a separate process as multithreading in bash…not thanks. But you get the point. I plan to switch to another language long term.
Resources to deploy with existing templates
I already have templates for all of the following so should be able to deploy them fairly easily:
Option: A parameter per resource
I have three OUs below the dev OU. Each one could have a separate parameter. I would have four parameters with these names and values:
/job/awsenvinit/dev/organizations-organizationalunit-dev
Value:
env=dev
region=us-east-2
cfparamParentid=:get_id:organization:organizationalunit:root
/job/awsenvinit/dev/organizations-organizationalunit-governance
env=dev
region=us-east-2
cfparamParentid=:get_id:organization:organizationalunit:dev/job/awsenvinit/dev/organizations-organizationalunit-apps
env=dev
region=us-east-2
cfparamParentid=:get_id:organization:organizationalunit:dev/job/awsenvinit/dev/organizations-organizationalunit-resources
env=dev
region=us-east-2
cfparamParentid=:get_id:organization:organizationalunit:devWith the above approach I keep having to make requests to parameter store for each separate resource. That could work.
However, I’m trying to avoid a few things:
- A new container for every resource in a stack
- A new parameter for every resource in a stack
- Separate code for every stack (besides a parameter)
How can we avoid those things?
A stack configuration parameter
I’m going to create a new value for the resource category portion of the job SSM parameter name called stack. I’m referring to a job configuration stack here, not a CloudFormation stack.
You can put multiple resources in a CloudFormation stack, but unless there is a need otherwise I am creating one resource per CloudFormation stack:
Though I’m deploying one CloudFormation stack per resource, I’m going to configure multiple stacks in a single configuration. I just talked to someone at AWS who said people were asking to move resources between stacks. That is complicated. Creating a single stack per resource and switching your configuration around, as long as you are in the same account and region, is easy, with my approach.
I want to keep my resources in their own CloudFormation stack for reusability, governance, and ease of redeployment of a single resource. However, I still want to be able to deploy a set of resources together and some in parallel to speed up the deployment process.
So I’m going to add a new resource name that looks like this to deploy the environment resources in the diagram above:
/job/awsenvinit/root-admin/stack-environment-devThat still aligns with: resource category — resource type — resource name.
That configuration is for a stack that deploys an environment named dev.
What’s in a stack configuration parameter?
I could create a list of parameter names like this to deploy a stack:
/job/awsenvinit/dev/organizations-organizationalunit-dev
/job/awsenvinit/dev/organizations-organizationalunit-governance
/job/awsenvinit/dev/organizations-organizationalunit-apps
/job/awsenvinit/dev/organizations-organizationalunit-resourcesThen I could create a separate parameter for every single resource in SSM Parameter. It would be really easy to loop through that list and then call the function I wrote in the last post to deploy the resources. But it has a few downsides.
Let’s look at the architectural ramifications of that choice:
What is the cost of that?
It appears there is no cost for standard storage and throughput:

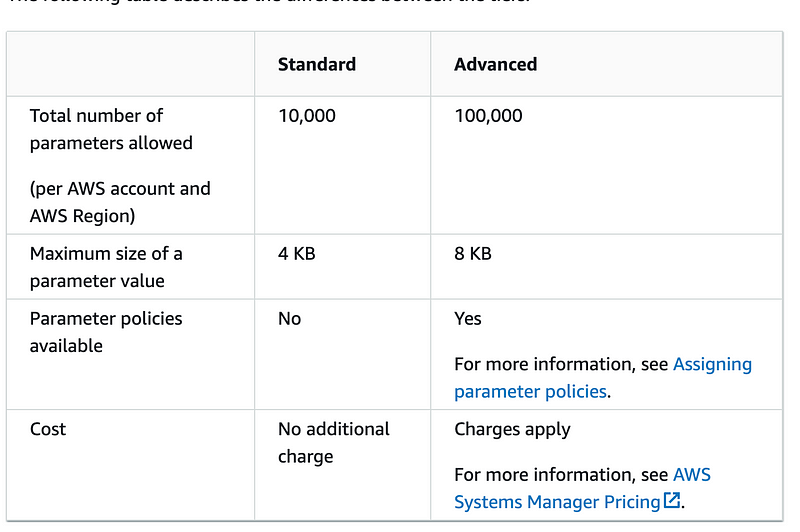
Do we need advanced?
What’s the difference between standard and advanced?
We can’t use a KMS key with a standard parameter. I’m not using a KMS key in my initial deployment in the root account anyway because anyone with access to this account will have access to the parameters and the organizational structure so this isn’t exactly secret. I’m using the default AWS encryption key. This account should have very little activity.
But in other accounts we might benefit from a KMS key. And I might add a KMS key to my initial stacks later.
If we use SSM parameter store with a KMS key, we need the advanced tier and we’d be paying for the total number of resources we create as we will have a parameter per resource. If we combine multiple resource configurations into one parameter we will pay less.
One other interesting thing to note is that if we delete the parameters when we are done we will pay less, but then we lose the parameter version history. That is an option.
Limit considerations
What sort of limits do we have and how might those influence our parameter design?
If it’s a very large and complex environment then the number of parameters could add up. Perhaps you would surpass the limits. Recall that I am deploying every single parameter — every user, role, and policy for example — using a separate template which would require a separate configuration.
Some organizations have over 10,000 users alone, so that approach is not very scalable (though most organizations will not be using IAM for users, they will be using something like Active Directory federation with roles, AWS SSO, Okta, or something like that.) But you get the point. The resources could add up to a lot of parameters.
Concatenating the parameters
Here’s the alternate approach I’m going to use. I’m going to concatenate the SSM job config parameters into a single stack configuration.
The stack configuration could look like this for the OUs and accounts above:
/job/awsenvinit/dev/organizations-organizationalunit-dev
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:root
/job/awsenvinit/dev/organizations-organizationalunit-governance
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-apps
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-resources
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-account-iam
env=dev
region=us-east-2
/job/awsenvinit/dev/organizations-account-jobs
env=dev
region=us-east-2
/job/awsenvinit/dev/organizations-account-kms
env=dev
region=us-east-2I still need to add in the parameters for the account templates above. First I had to rename all the CloudFormation template parameters to the new parameter format starting with cfparam:
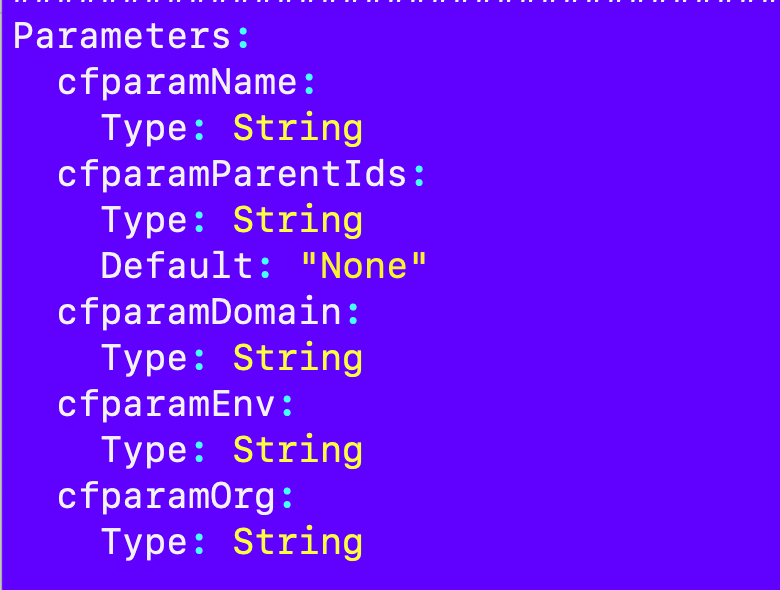
And everything in the template that references them:
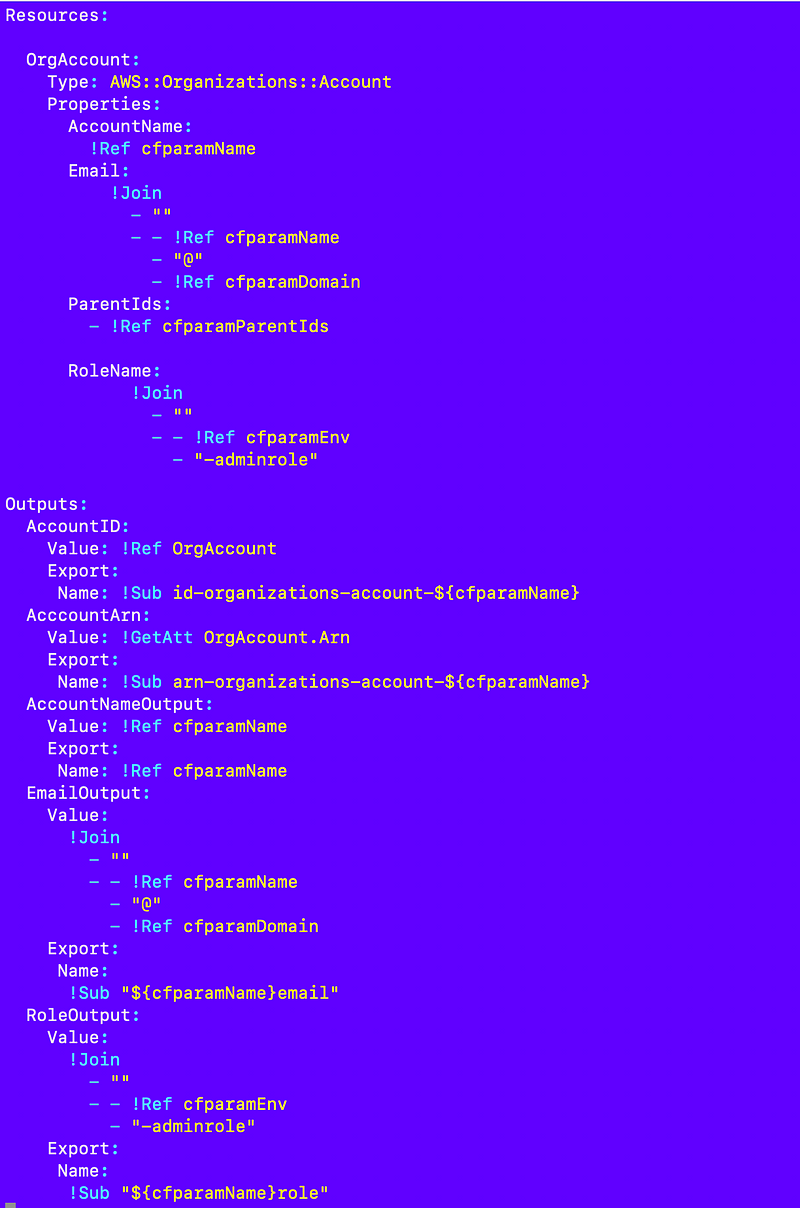
I used my sed commands to help me do that fairly quickly:
Referencing another SSM parameter in our parameter configuration
I had another challenge. In the case of the AWS account template shown above, I have an domain parameter for account email addresses and the org name used in account names. I wanted to create SSM parameters for those rather than hard coding them into my job configuration.
I had originally created one-off parameters in the root account for this purpose. I need to revisit how and where those parameters are created but for now they exist.
- The domain parameter contains the domain name used to create account email addresses.
- The org parameter is used as a prefix to account names and aliases.
How can I use those SSM parameters in my stack configuration?
I’m going to say that any value starting with :ssm: will be a reference to another SSM parameter in the same account.
If I want to get the domain name it will look like this:
cfparamDomain=:ssm:domainHere’s an account configuration after adding all the parameters:
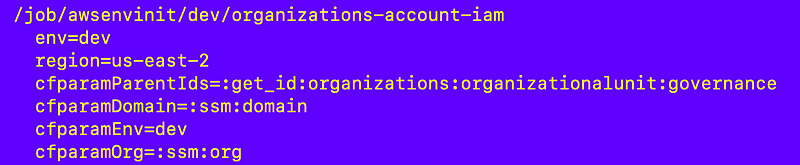
I add the following to process SSM parameters:
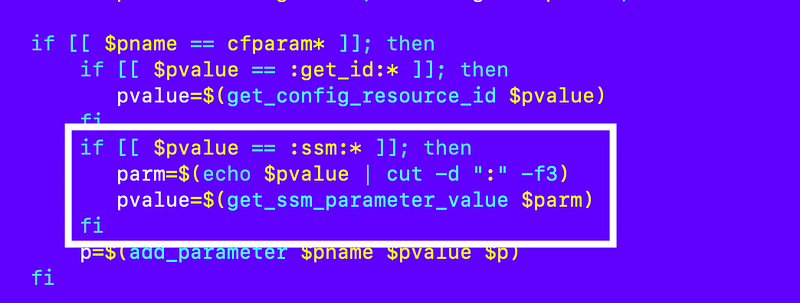
I’m already including my SSM Parameter functions at the top of the file:

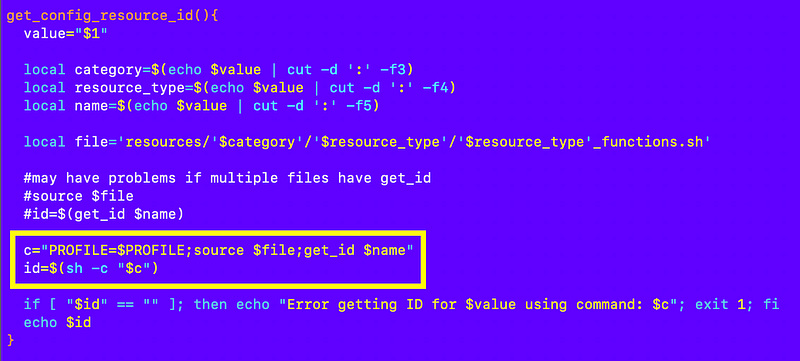
Dealing with multiple get_id functions for different resources
In order to make sure I’m calling the correct get_id function for the correct resource if I have sourced multiple files, I tweaked my function that gets ids from the configuration to get the id in a separate process:
Array challenges
I struggled with arrays for a bit as there seems to be a lot of variation in how you can process them and things that worked on Amazon Linux 2 don’t work on Amazon Linux 2023. Here are some notes if interested.
Also found some potential bugs that spit out the wrong data. Well, that’s not good…Didn’t document all of that but maybe someone at AWS should test those array functions and make sure they are not outputting something they shouldn’t.
Format considerations
Note that I could use YAML or JSON or whatever here but I’m just doing something very simple. I need a job name and a list of parameters and that’s it. I don’t need a complex structure. I also don’t want a bunch of extraneous code from parsing libraries in my container. Although I mostly recommend using industry standard syntax, this is mainly for me and anyone who cares to use it and going to keep it simple with mainly a key-value pair list and a few extra constructs.
If you are building this for yourself and want to build something with industry standard formatting, I’d probably go with YAML.
I can reuse some of the same code from the last post to process the job configurations for each resource. I need to add some code to loop through those configurations and add parallel or sequential processing.
Deploying resources in parallel
What if we want to deploy resources in parallel as I demonstrated in this post?
I’m going to add one other thing to my configuration. Resources can be deployed sequentially or in parallel.
Just add Sequential or Parallel in front of a list of resources to indicate which it is.
Sequential:
/job/awsenvinit/dev/organizations-organizationalunit-dev
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:root
Parallel:
/job/awsenvinit/dev/organizations-organizationalunit-governance
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-apps
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
/job/awsenvinit/dev/organizations-organizationalunit-resources
env=dev
region=us-east-2
cfparamParentid=:get_id:organizations:organizationalunit:dev
Parallel:
/job/awsenvinit/dev/organizations-account-iam
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:governance
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:org
/job/awsenvinit/dev/organizations-account-jobs
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:apps
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:org
/job/awsenvinit/dev/organizations-account-kms
env=dev
region=us-east-2
cfparamParentIds=:get_id:organizations:organizationalunit:resources
cfparamDomain=:ssm:domain
cfparamEnv=dev
cfparamOrg=:ssm:orgParallel stacks = separate SSM Parameters
Let’s say I wanted to deploy stacks in parallel. By design that requires separate parameters and you could initiate multiple jobs at the same time. Adding the complexity of parallel stacks is not something I want to support as it’s easy enough to deploy a container per job and that is a cleaner design.
Create a new job configuration SSM Parameter with the above
Add a new configuration file to the jobconfig repository.
I’m going to navigate to:
job/awsenvinit/root-adminAnd add the configuration file:
vi stack-environment-dev
Paste in the above configuration and save it:
:wq!Code to parse our job configuration and execute the job
Back in my job execution repository:
I navigate to this file:
aws/shared/parse_config.shLet’s add some logic to parse the code to our deploy function from the last post.
Here’s what we’re starting with from the last post that deploys a resource based on a job configuration SSM Parameter:
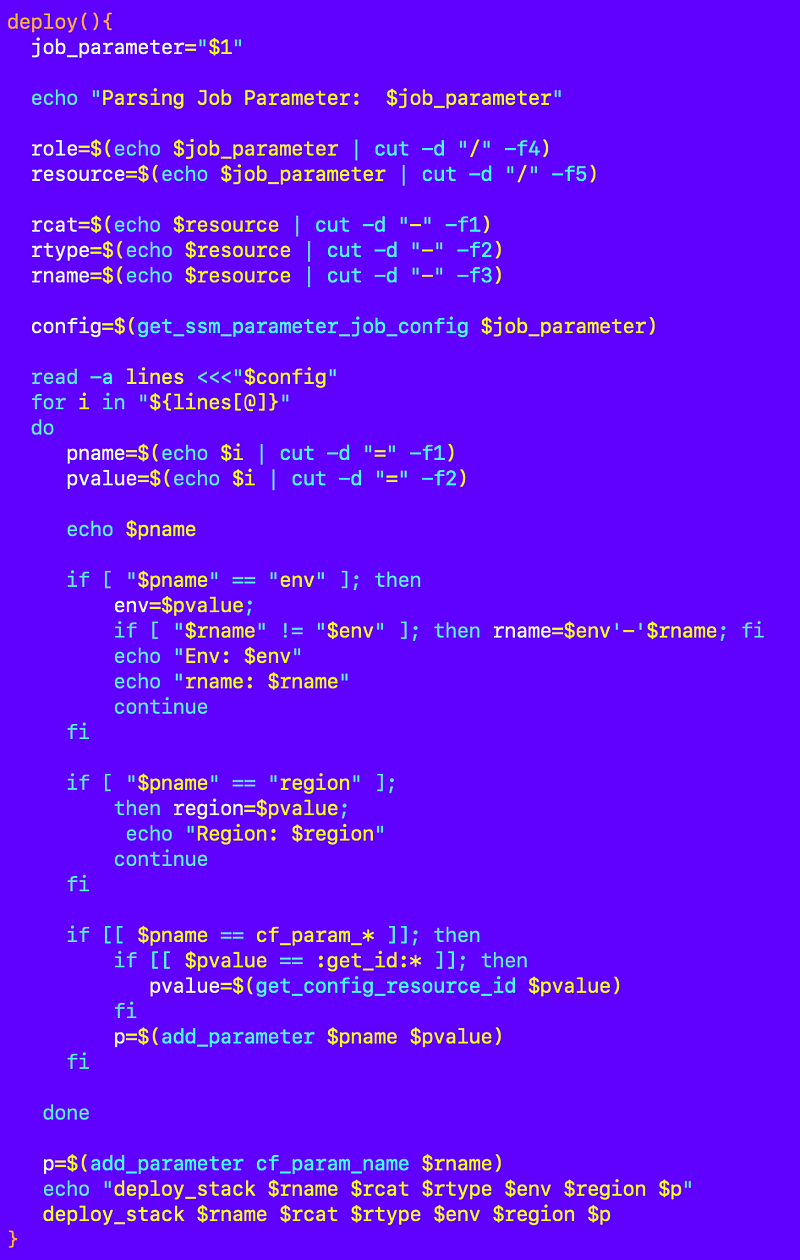
Here’s how I rearranged it.
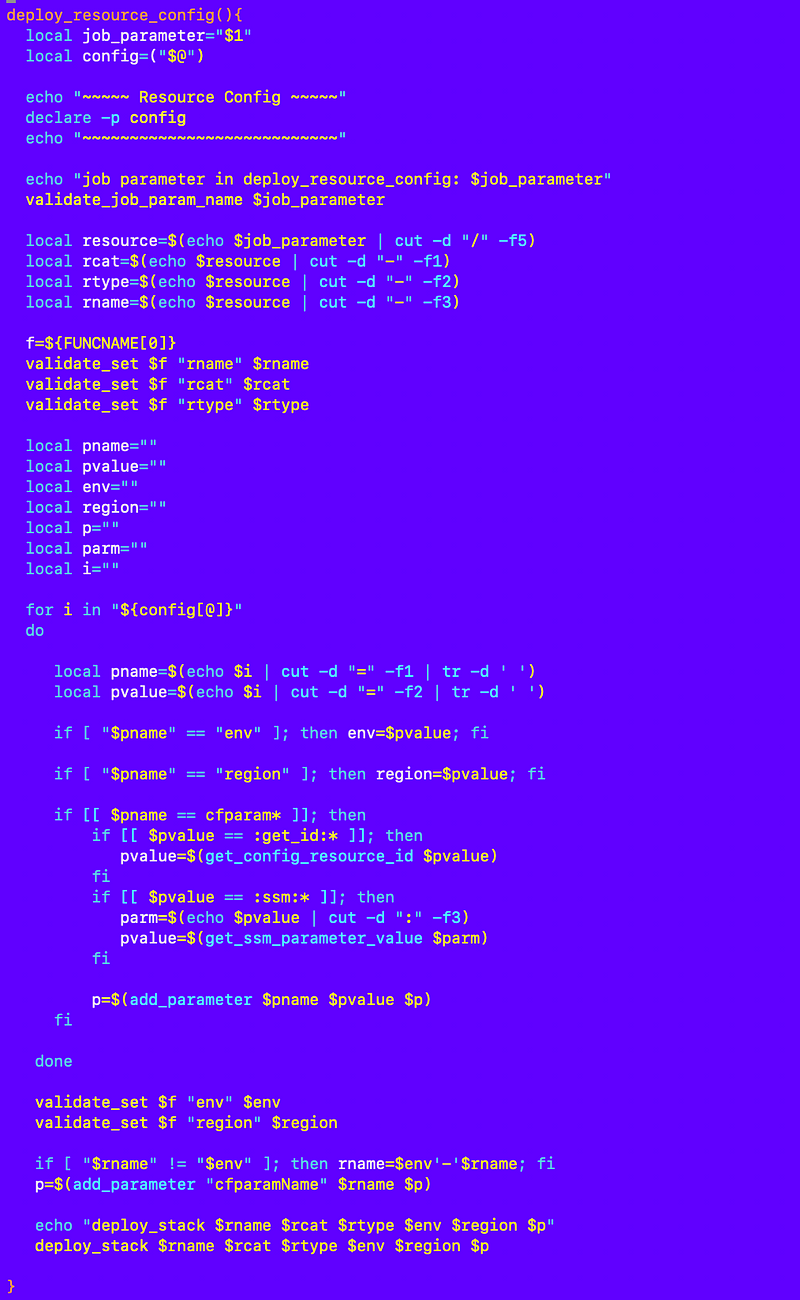
To keep things simpler, I’m going to separate my resource and stack deployment functionality into two separate functions: deploy_resource_config and deploy_stack_config.
In my deploy function, I retrieve the SSM parameter value, convert it to an array, and pass it to whichever function is appropriate based on the resource category in the parameter name (stack, or anything else).
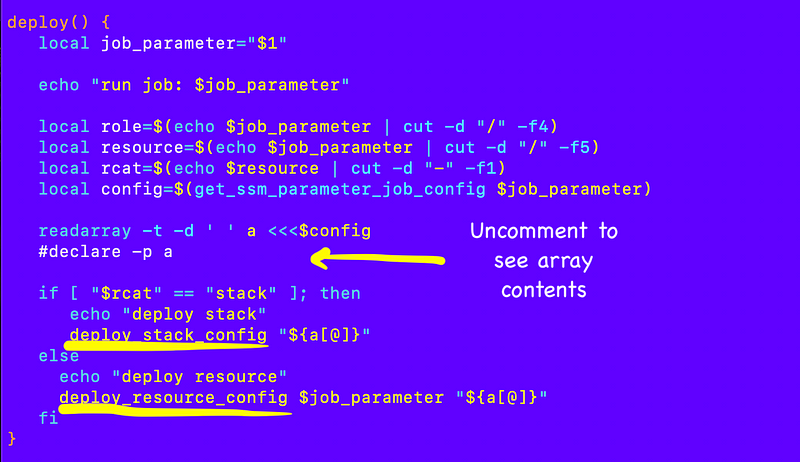
I move the code to deploy a single resource to deploy_resource_config:
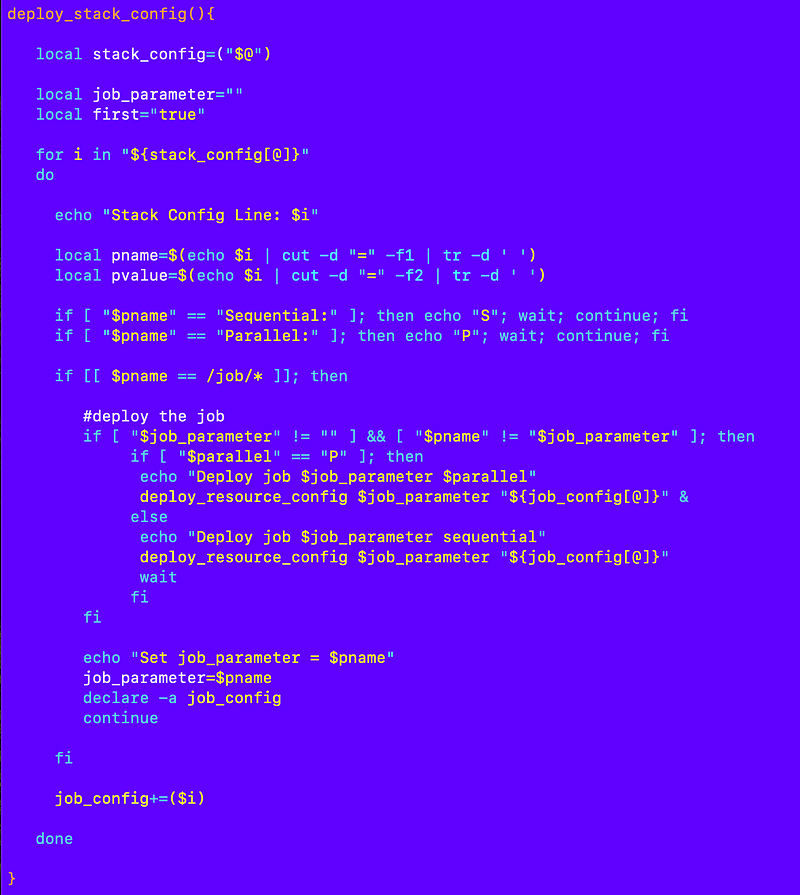
Next I need to create my deploy_stack_config function. I loop through the configuration the same way I did to deploy a single stack and take the appropriate actions on each line (skipping parallel and sequential processing for the moment):
In order to test that I have to return to init.sh in my job and modify the SSM parameter name that gets deployed from the config repository.
I change this:

To this:

I run just that portion of the init script to ensure the parameter shows up in AWS SSM Parameter Store:

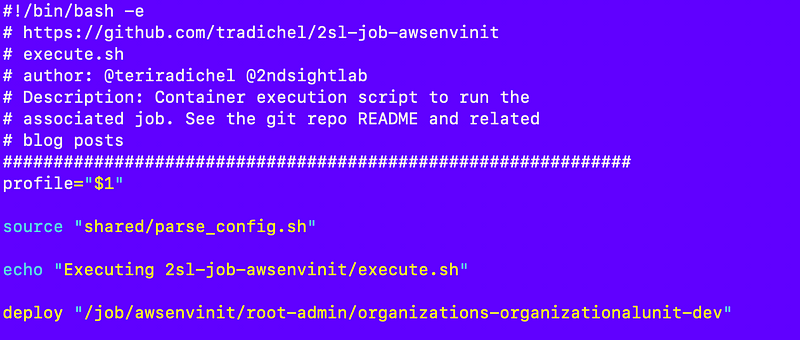
I also have to change the parameter name in execute.sh:
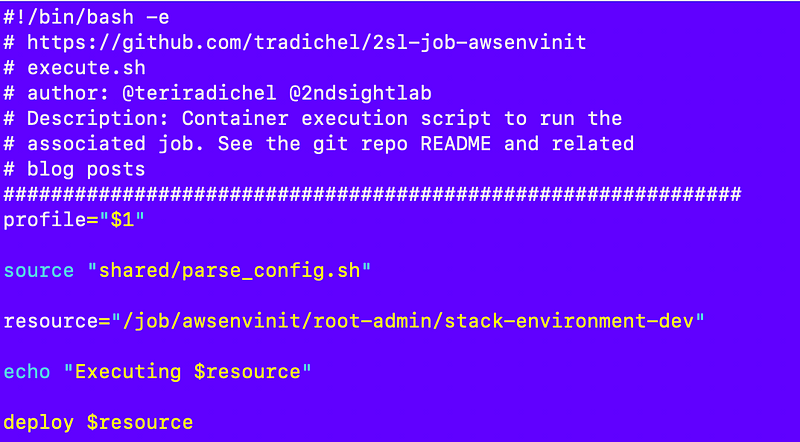
Parallel processing
I wrote about how you can deploy resources in parallel using different scripts in bash here:
In those examples I added an ampersand (&) to the end of the script to run it in parallel with other scripts. In theory I should be able to do that with functions as well and I’m doing it in the above script. However, I’m not entirely sure if it’s working because the AWS CLI seems to wait for a response. Or maybe that was my code. I don’t remember.
The concept is in place, at any rate. I’ll finish this up in future posts and get an environment deployed for the 2nd Sight Lab job execution framework and hope to simplify some things in the process.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2024
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab